目录
- 模型部署工作
- ONNX存在的意义
- ONNX(Open Neural Network Exchange)
- ONNX示例
- 模型推理示例
- Batch调整
- 量化
- 量化方式
- 常见问题
模型部署工作
- 训练好的模型在特定软硬件平台下推理
- 针对硬件优化和加速的推理代码
训练设备平台:
CPU、GPU、DSP
ONNX存在的意义
模型与硬件之间的对应关系适配复杂度mxn的结果,导致开发复杂化、效率较低等问题
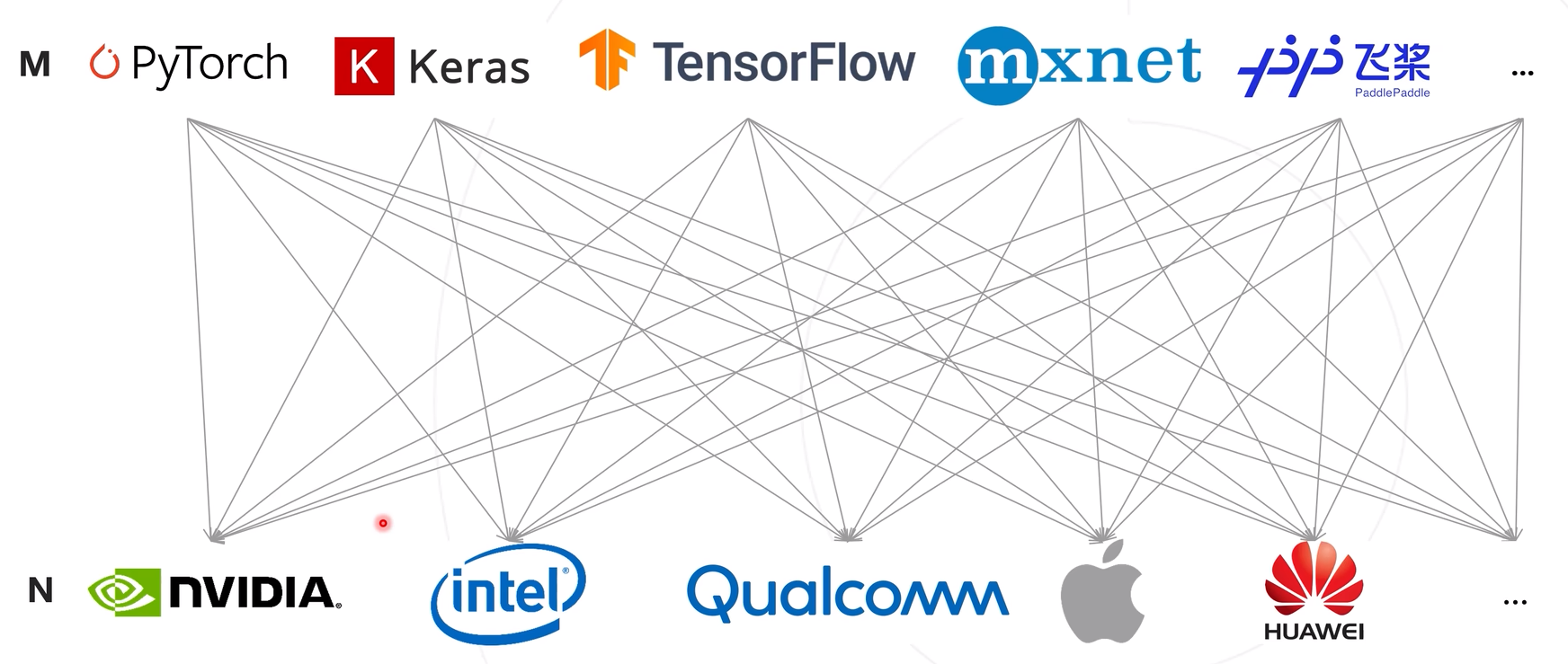
使用一种模型表达结构将训练框架的输出结构统一化,将模型部署复杂度从mxn转变为m+n
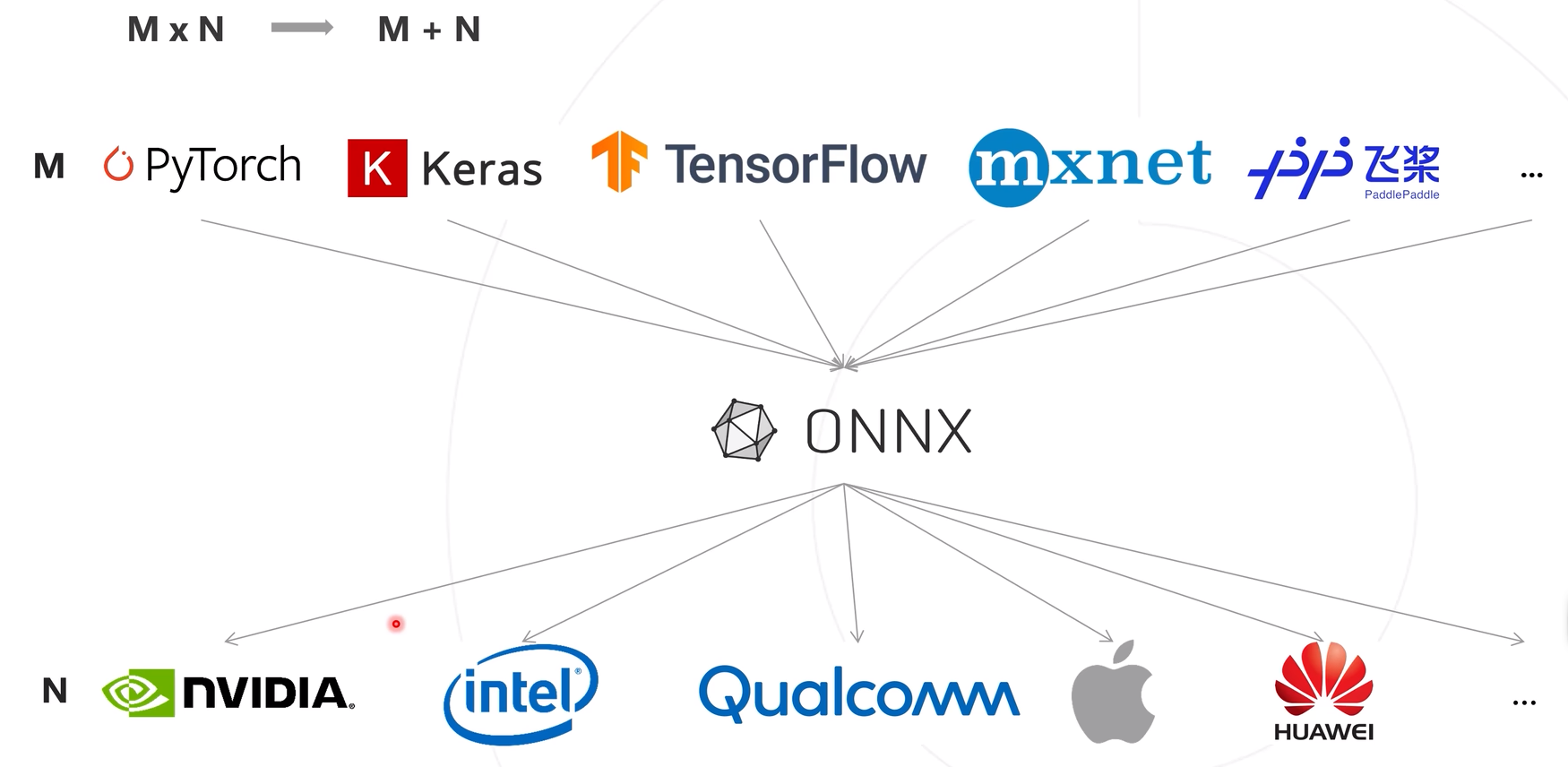
ONNX变身是一种模型格式,属于文本,不是程序,无法直接在设备上运行。因此,需要软件栈去加载ONNX模型,使其在硬件设备上高效推理。这个软件栈指的是模型的推理框架。推理框架分类硬件商自研和通用推理框架。自研推理框架底层优化较好,推理的计算效率较高,不具备普适性,无法应用到其他的芯片上。而通用推理框架是具备通用性,可应用在不同的软硬件平台下,降低开发难度,提升开发的效率,不需要用户关注底层框架,只需要将接口对应完成即可。
 整体推理过程:先使用模型框架训练完成模型后,转换为ONNX模型结构,在使用推理框架,将ONNX模型高效地运行在软硬件平台下。
整体推理过程:先使用模型框架训练完成模型后,转换为ONNX模型结构,在使用推理框架,将ONNX模型高效地运行在软硬件平台下。

ONNX(Open Neural Network Exchange)
一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。不同的训练框架可采用相同格式存储模型并交互。由微软,亚马逊,Facebook和IBM等公司共同发起。

ONNX示例
使用torch.onnx.export进行onnx模型导出。
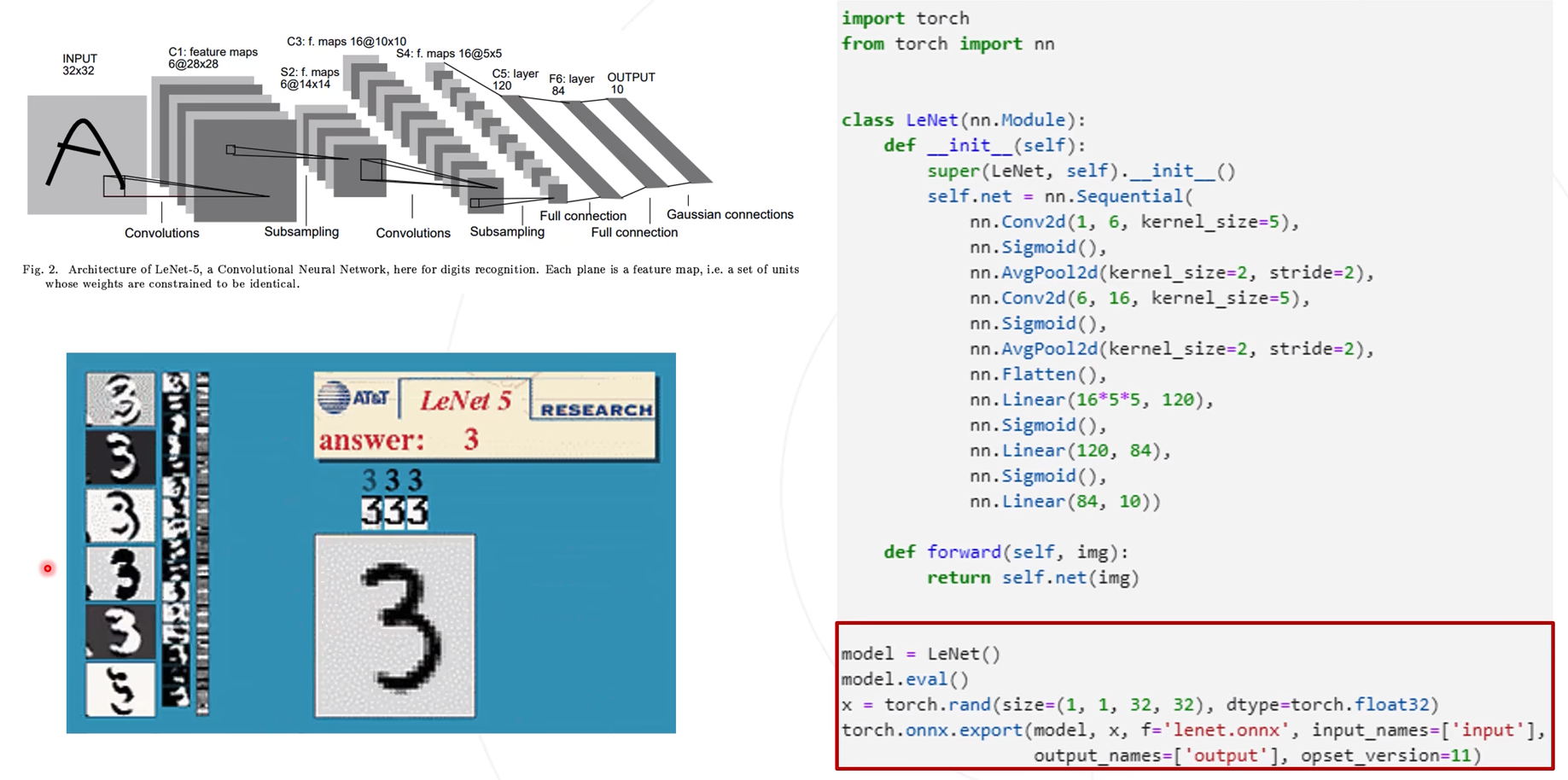
导出的onnx模型之后,进入netron.app进行模型结构可视化操作

ResNet的ONNX模型导出

参数讲解

模型推理示例
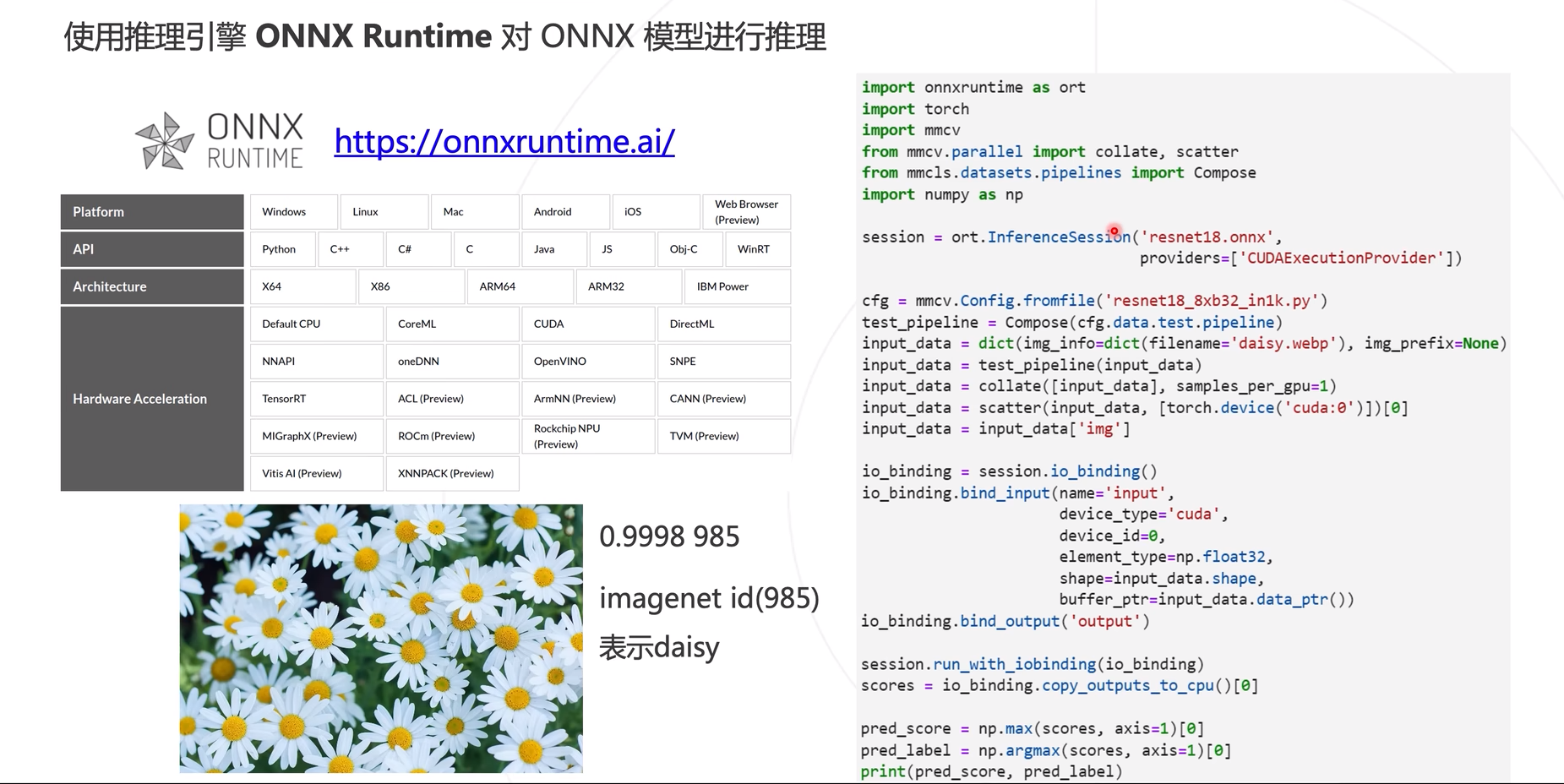
使用mmdeploy中示例,应用ONNX Runtime进行模型推理
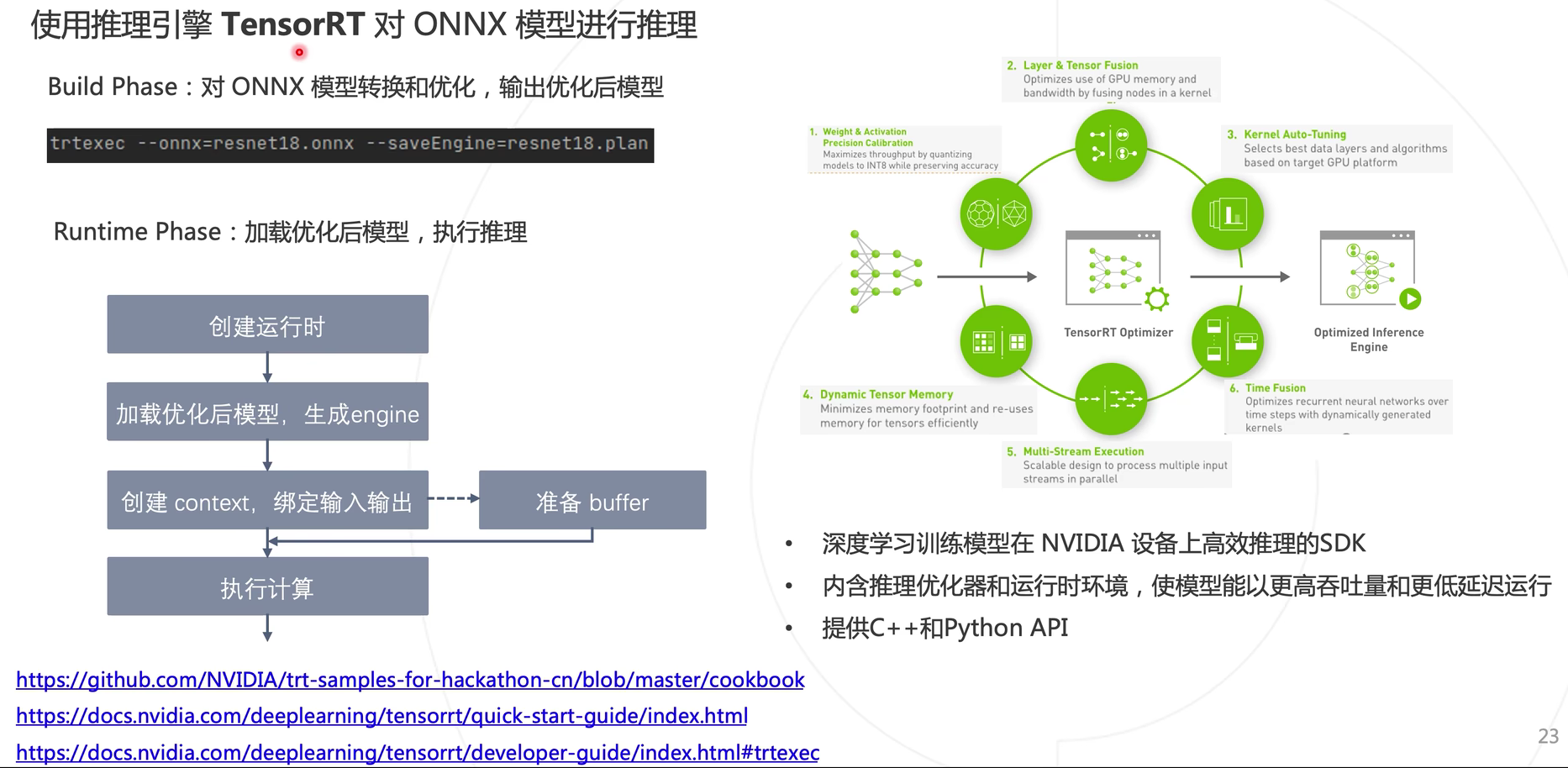
使用TensorRT对ONNX模型进行推理
Batch调整
上述生成ONNX时,是使用(1, X,X,X)图像输入是1维度,导致模型推理时也为一张图一张图的推理,效率较慢,使用多张图进行模型推理,使用dynamic_axes参数即可实现。
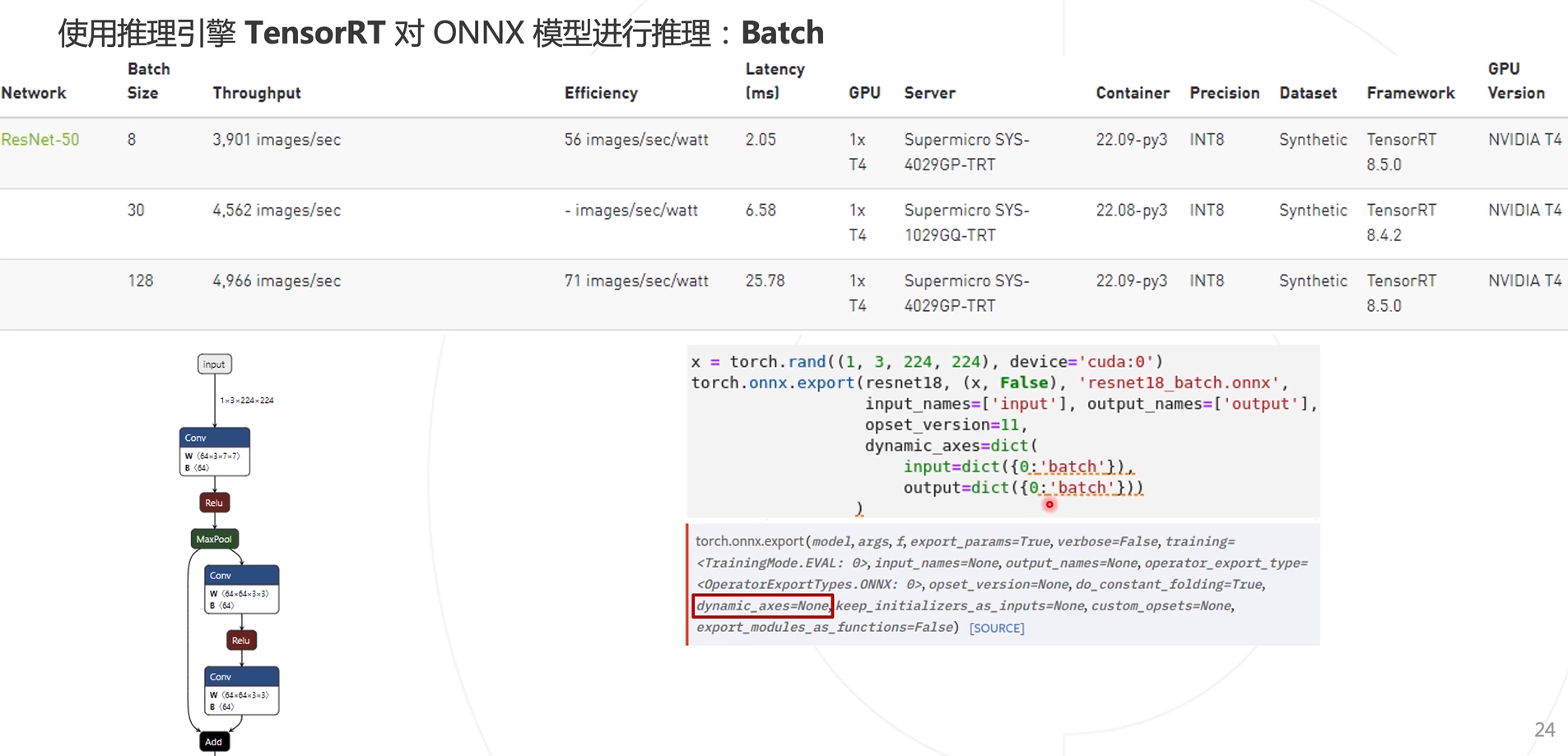
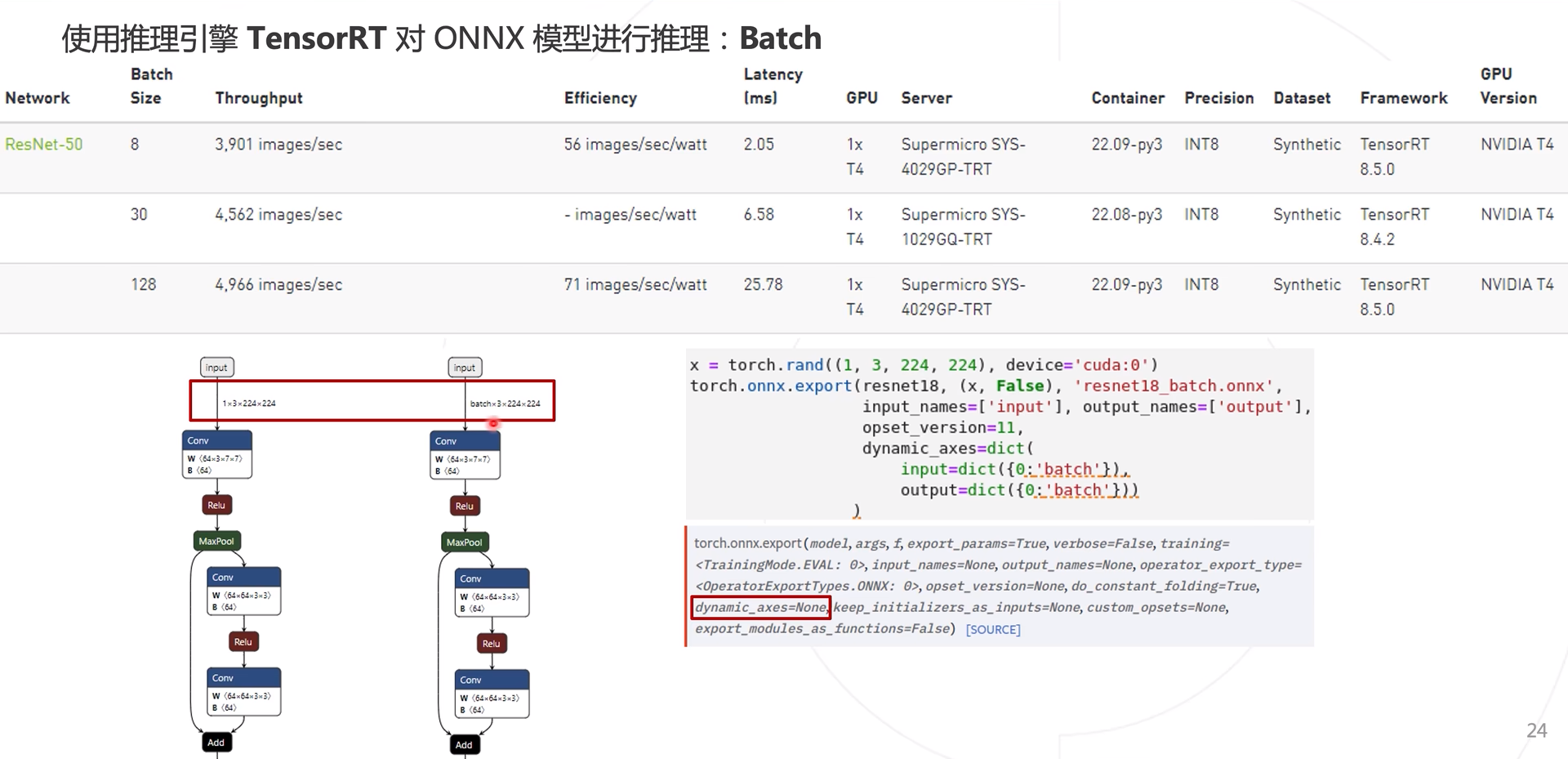
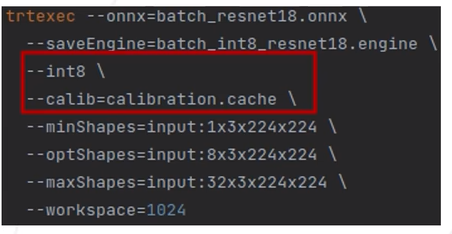
在TensorRT模型数据格式转换中进行修改,minShapes和maxShapes参数设置

量化
除了使用Batch增加模型推理速度外,还可以使用量化进行加速。一般而言,使用float16不会影响模型的精度变化,而使用int8存储格式后模型精度会略有下降。
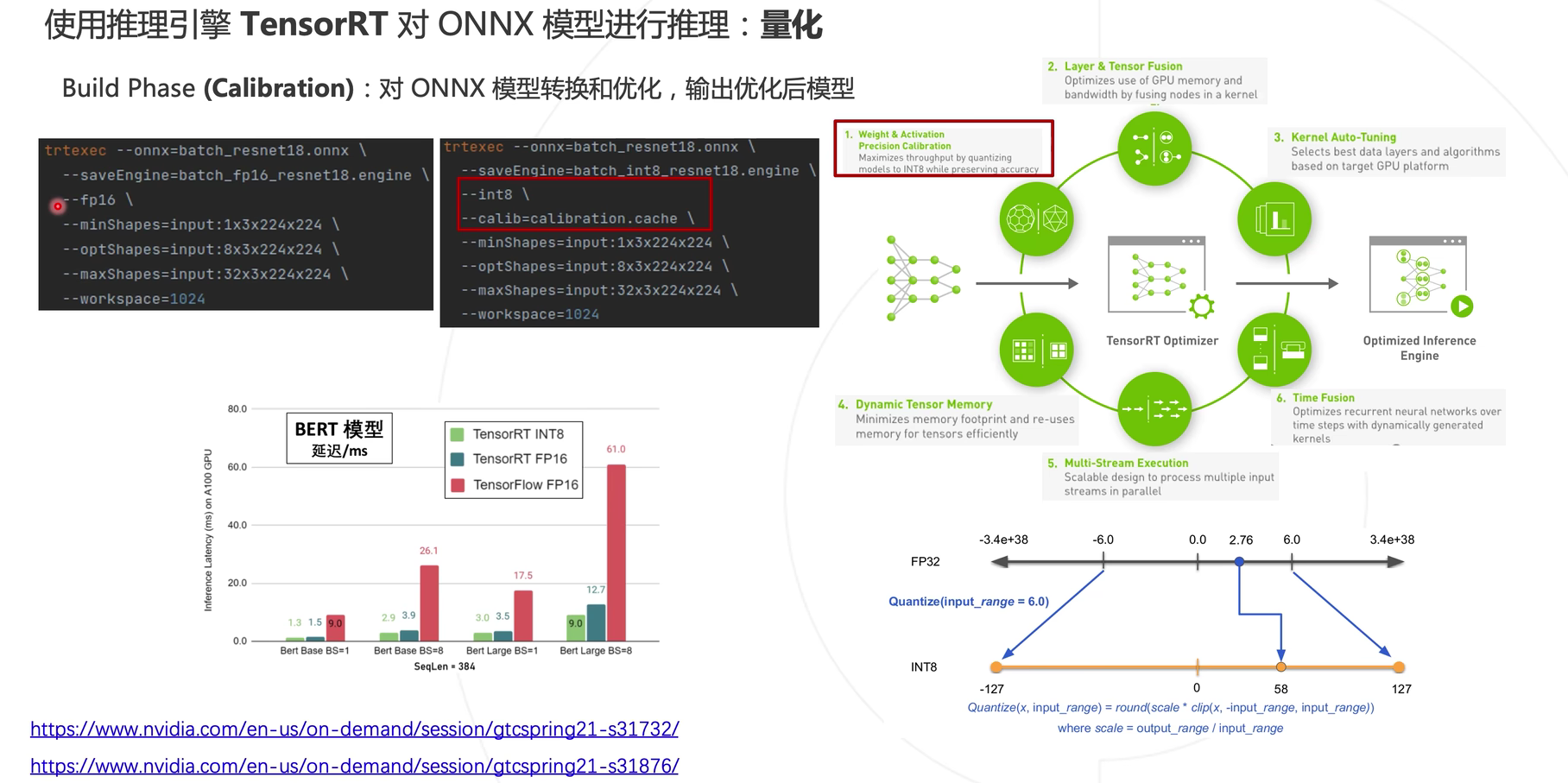
量化方式
- 训练后量化:Post-training quantization(PTQ)
- 训练时量化:Quantization-aware training(QAT)
如果使用的是QAT的话,是在模型训练过程中已经实现了模型精度的转换,使用onnx数据结构转换即可,而如果使用的是PTQ的话,需要在对应的计算平台上进行精度转换。
对称量化:取模型的数值对称区间,对应到INT8(-127,127)中,可以得到一个量化系数(简单理解为比例系数,127/6),从而将FP32中的数值与INT8进行对应。
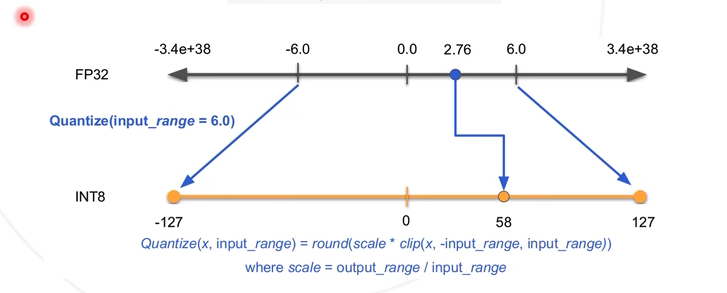
在TensorRT中被称为calibration
常见问题