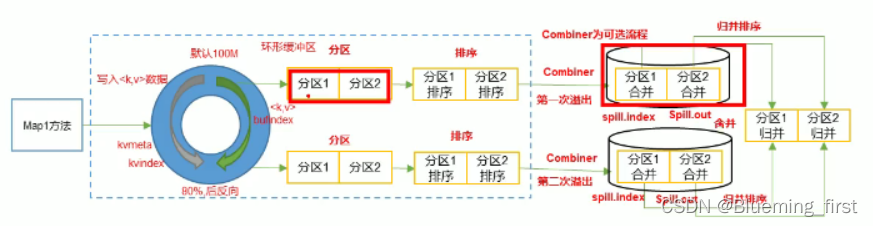
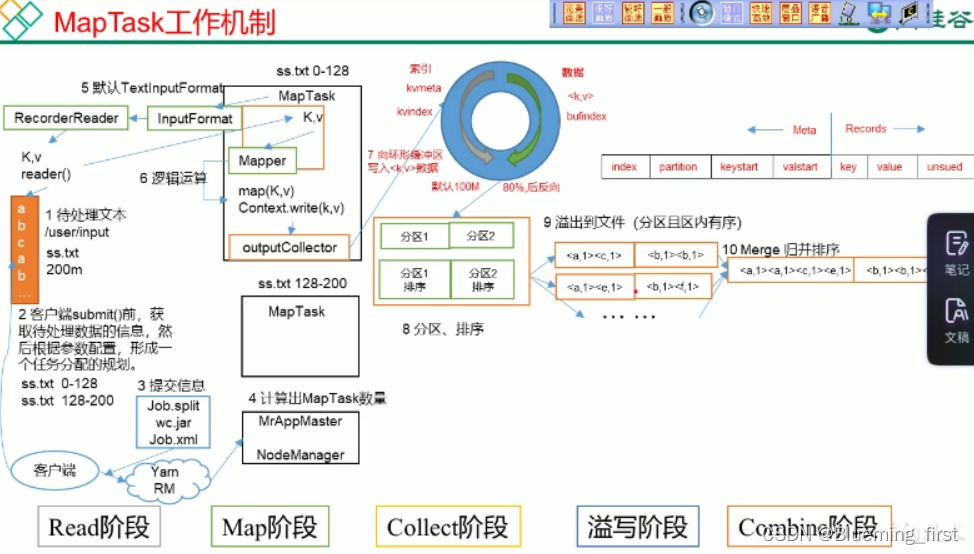
一、Combiner合并
- Combiner是MR程序中Mapper和Reducer之外的一种组件。
2)Combiner组件的父类就是Reducer
3)Combiner和Reducer的区别在与运行的位置;Combiner是在每一个MapTask所在的节点运行;Reducer是接收全局所有Mapper的输出结果
4)Combiner的意义就是对每一个MapTask的输出进行局部汇总,以减小网络传输量。
5)Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reducer的输入kv类型要对应起来。
三、OutputFormat接口实现类
OutputFormat是MapReduce输出的基类,所有实现MapReduce输出都实现了OutputFormat接口。
常见的OutputFormat实现类:
- 文本输出TextOutputFormat
默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方法把它们转换为字符串。 - SequenceFileOutputFormat
将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这便是一种好的输出格式,因为它的格式紧凑,很容易被压缩。(将小文件合并,节省namenode存储空间)。 - 自定义OutputFormat
根据用户需求,自定义实现输出。
自定义OutputFormat 使用场景及步骤
1.使用场景
为了实现控制最终文件的输出路径和输出格式,可以自定义OutputFormat。
2. 自定义OutputFormat步骤
1)自定义一个类继承FileOutputFormat
2)改写RecordWriter,具体改写输出数据的方法write()。
四、Join多种应用
-
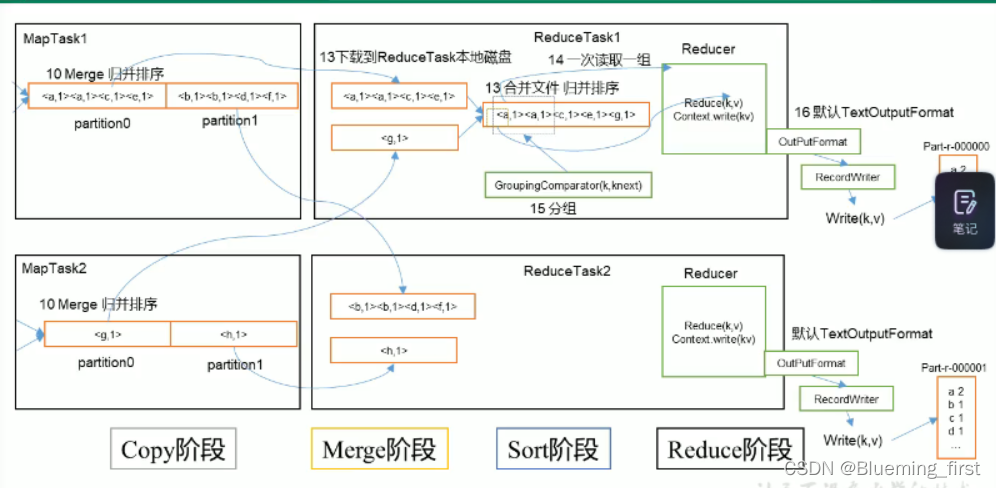
Reduce Join工作原理
map端的主要作用:为来自不同的表或文件的key/value对,打标签以区别不同的来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
reduce端的主要作用:在reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源不同的文件的记录(在Map阶段已经打标志)分开,最后进行合并就ok了。 -
案例

4.1 Map Join分析
- 使用场景
Map Join 适用于一张表十分小、一张表十分大的场景(数据倾斜)。 - 优点
reduce端处理过多的表,非常容易导致数据倾斜。于是,在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少reduce端数据的压力,尽可能的减少数据倾斜。 - 具体办法:采用DistributedCache(分布式缓存)
1)在Mapper的setup阶段,将文件读取到缓存集合中
2)在驱动函数中加载缓存
(也就是将小文件写入缓存中,这样reduce阶段直接从缓存读,不需要重新再磁盘读一遍了)
job.addCacheFile(new URI(“”));
Map端表合并案例分析:

五、计数器
hadoop为每个作业维护若干内置计数器,以描述多项指标。例如,某些计数器记录已处理的字节数和记录数,使用户可监控已处理的输入数据量和已产生的输出数据量。
- 计数器API
1)采用枚举的方式统计技术

2)采用计数器组、计数器名称的方式统计

3)计数结果在程序运行后的控制台上查看。



![[牛客Hot101]链表篇](https://img-blog.csdnimg.cn/b27bb1f9a13343c69c017c28a9e60fb3.png#pic_center)
![Buuctf reverse [FlareOn4]IgniteMe 题解](https://img-blog.csdnimg.cn/927082542f914b86b1a9fe4f33ba439f.png)