目录
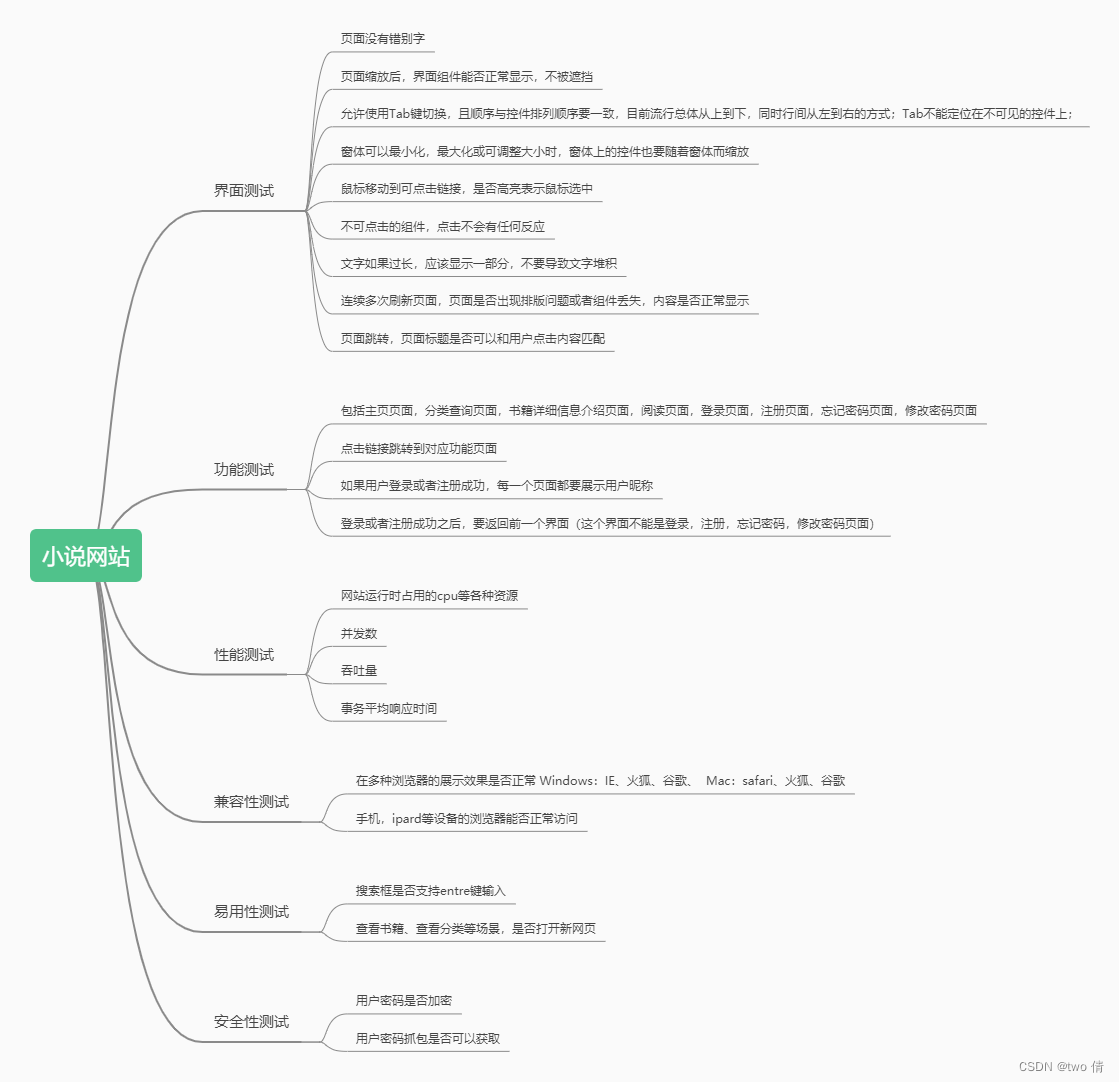
通用测试点
登录页面测试
接口测试
UI测试
注册页面
接口自动化
UI测试
忘记密码页面
接口测试
UI测试
修改密码页面
进行接口测试
UI测试
主页页面测试
分类页面测试
查询页面测试
作者页面测试
阅读小说页面测试
书架页面测试
通用测试点
登录页面测试
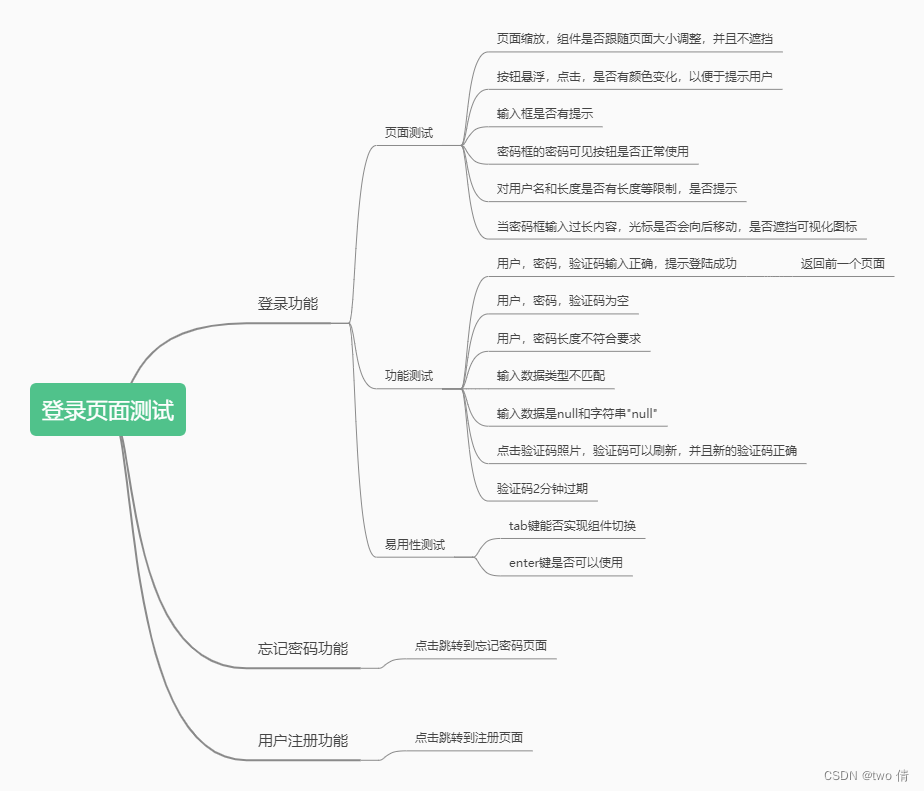
接口测试
2.1、使用接口测试,测试多种结果的返回情况
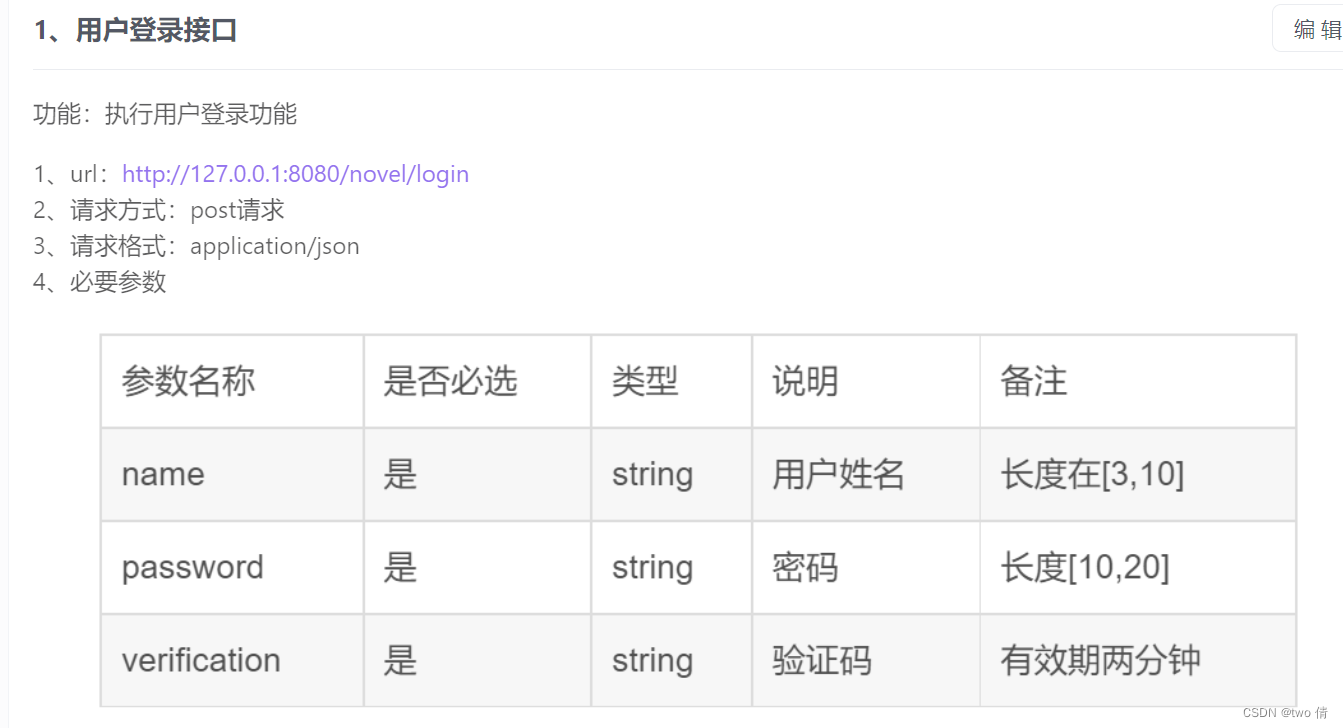

主要包括:
- 1、数据输入存在未输入情况
- 2、数据输入null值
- 3、数据输入长度不符合要求 (使用等价类,比如用户名长度[3,10],测试长度为2,3,10,11的情况)
- 4、数据输入类型不匹配
- 5、用户名不存在
- 6、验证码错误
- 7、验证码过期(两分钟)
- 8、用户名密码不匹配
- 9、用户名称,密码包括特殊字符
- 10、用户登陆成功
包含25个测试用例

UI测试
使用UI测试,检测不同情况下的页面展示情况
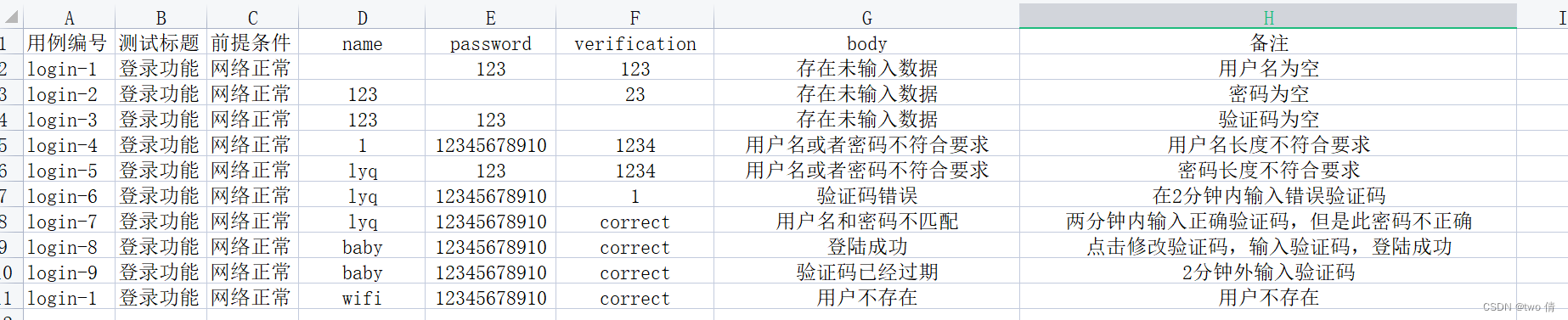
1、测试前6个数据
import time
import uuid
from selenium import webdriver
import pytest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import wait, expected_conditions
import requests
from selenium.webdriver.support.wait import WebDriverWait
class TestLogin():
@pytest.mark.parametrize(('name,password,verification,body'),
[["","123","123","存在未输入数据"],["123", "", "23", "存在未输入数据"], ["123", "123", "", "存在未输入数据"],
['1', '12345678910', '1234',"用户名或者密码不符合要求"], ['lyq', "123", "1234", "用户名或者密码不符合要求"],
["lyq","12345678910","1","验证码错误"]] )
def test_login(self,name,password,verification,body,getDriver):
getDriver.get("http://localhost:8080/novel/login.html")
Name=getDriver.find_element(By.XPATH,'//*[@id="username"]')
Password = getDriver.find_element(By.XPATH, '//*[@id="password"]')
Ver= getDriver.find_element(By.XPATH, '//*[@id="code"]')
Name.send_keys(name)
Password.send_keys(password)
Ver.send_keys(verification)
time.sleep(1)
view =getDriver.find_element(By.XPATH,'//*[@id="view"]')
view.click()
submit=getDriver.find_element(By.XPATH,'//*[@id="submit"]')
submit.click()
alert = WebDriverWait(getDriver, timeout=10).until(expected_conditions.alert_is_present())
time.sleep(2)
text=alert.text
print(text)
alert.accept()
assert text==body

2、有的数据需要涉及到验证码的输入,进行手工测试
注册页面

接口自动化



主要包括:
- 1、数据输入存在未输入情况
- 2、数据输入null值 (分为null和"null")
- 3、数据输入长度不符合要求 (使用等价类,比如用户名长度[3,10],测试长度为2,3,10,11的情况)
- 4、数据输入类型不匹配
- 5、用户名已经存在
- 6、验证码错误
- 7、验证码过期(两分钟)
- 8、邮箱格式验证(长度,10位数字,后缀验证)
- 9、邮箱已经被注册
- 10、用户名称,密码,邮箱包含特殊字符
- 11、验证码刷新,能否正确使用
- 12、用户一旦注册成功,可以检验是否可以登录

UI测试
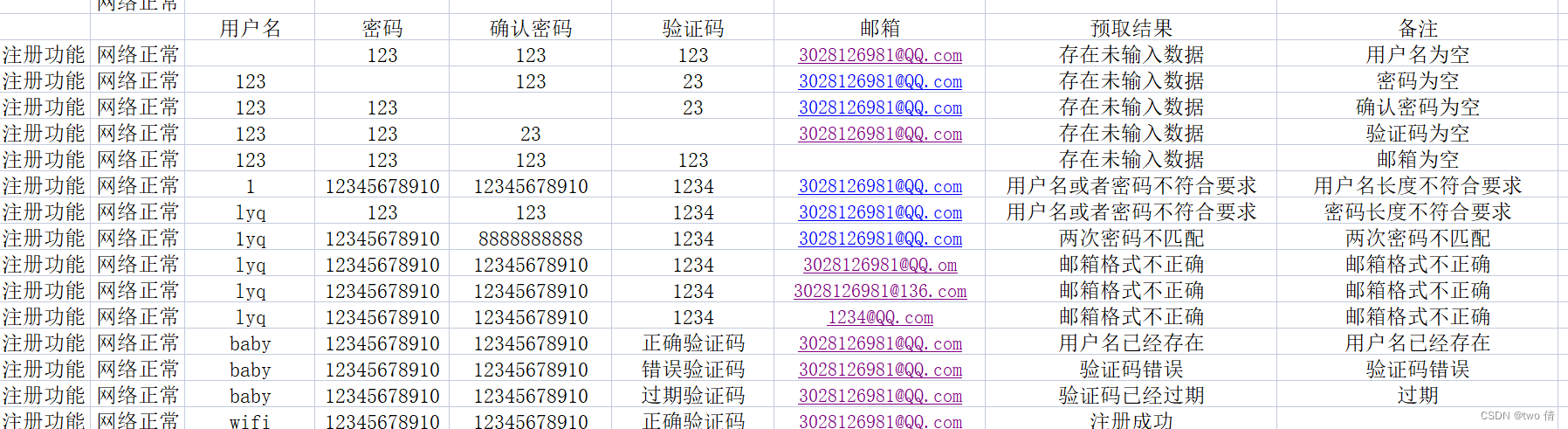
1、 提取数据验证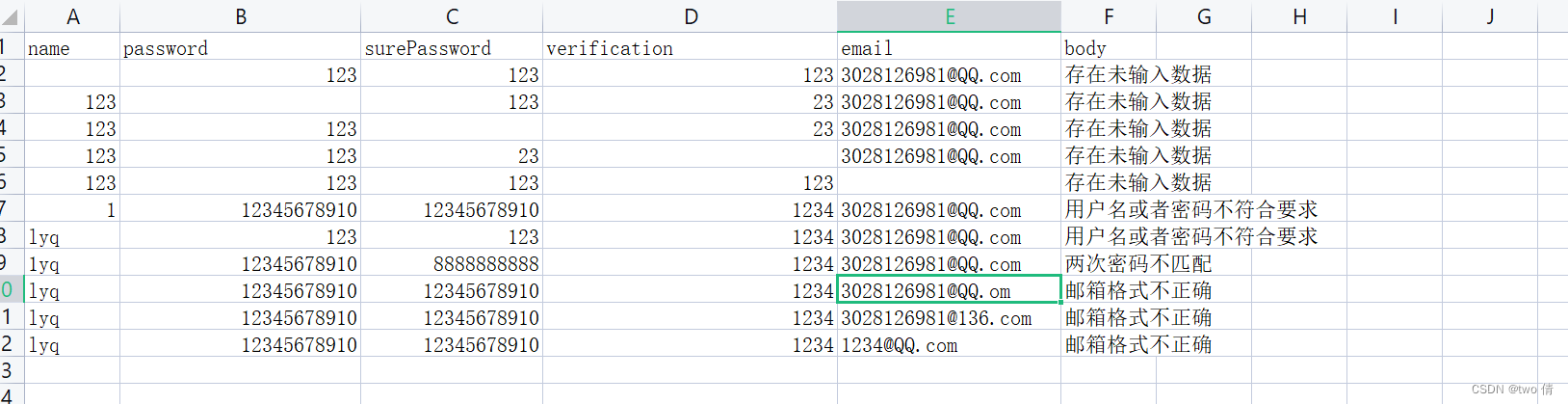
import time
import uuid
from openpyxl.reader.excel import load_workbook
from selenium import webdriver
import pytest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import wait, expected_conditions
import requests
from selenium.webdriver.support.wait import WebDriverWait
from openpyxl import workbook
from openpyxl.reader.excel import load_workbook
def read(path):
file = load_workbook(path) # 打开文件
graph = file.active # 打开默认工作表 (第一张)
# 使用迭代器 遍历每一行的数据 因为数据是从第二行开始的 所以min_row=2,values_only表示只读取数据
for data in graph.iter_rows(min_row=2, values_only=True):
yield data # 迭代返回每一行数据
# yield让函数变成生成器函数 让函数从上次的位置继续执行
class TestRegister():
@pytest.mark.parametrize("name,password,surePassword,verification,email,body",
read(r"C:\python学习\小说项目测试\界面测试\注册页面测试\data.xlsx"))
def test_login(self, name, password, surePassword, verification, email, body, getDriver):
if(name==None):
name=""
if(password==None):
password=""
if(surePassword==None):
surePassword=""
if(verification==None):
verification=""
if(email==None):
email=""
getDriver.get("http://localhost:8080/novel/register.html")
getDriver.maximize_window()
Name = getDriver.find_element(By.XPATH, '//*[@id="username"]')
Password = getDriver.find_element(By.XPATH, '//*[@id="password"]')
time.sleep(1)
view = getDriver.find_element(By.XPATH, '//*[@id="view"]')
view.click()
SurePassword = getDriver.find_element(By.XPATH, '//*[@id="password_again"]')
SureView = getDriver.find_element(By.XPATH, '//*[@id="view_again"]')
time.sleep(1)
SureView.click()
Email = getDriver.find_element(By.XPATH, '//*[@id="email"]')
Ver = getDriver.find_element(By.XPATH, '//*[@id="code"]')
Name.send_keys(name)
Password.send_keys(password)
SurePassword.send_keys(surePassword)
Email.send_keys(email)
Ver.send_keys(verification)
time.sleep(3)
submit = getDriver.find_element(By.XPATH, '//*[@id="submit"]')
submit.click()
alert = WebDriverWait(getDriver, timeout=10).until(expected_conditions.alert_is_present())
time.sleep(2)
text = alert.text
alert.accept()
assert text == body

2、对其他需要获取验证码的数据,进行手工UI测试
忘记密码页面
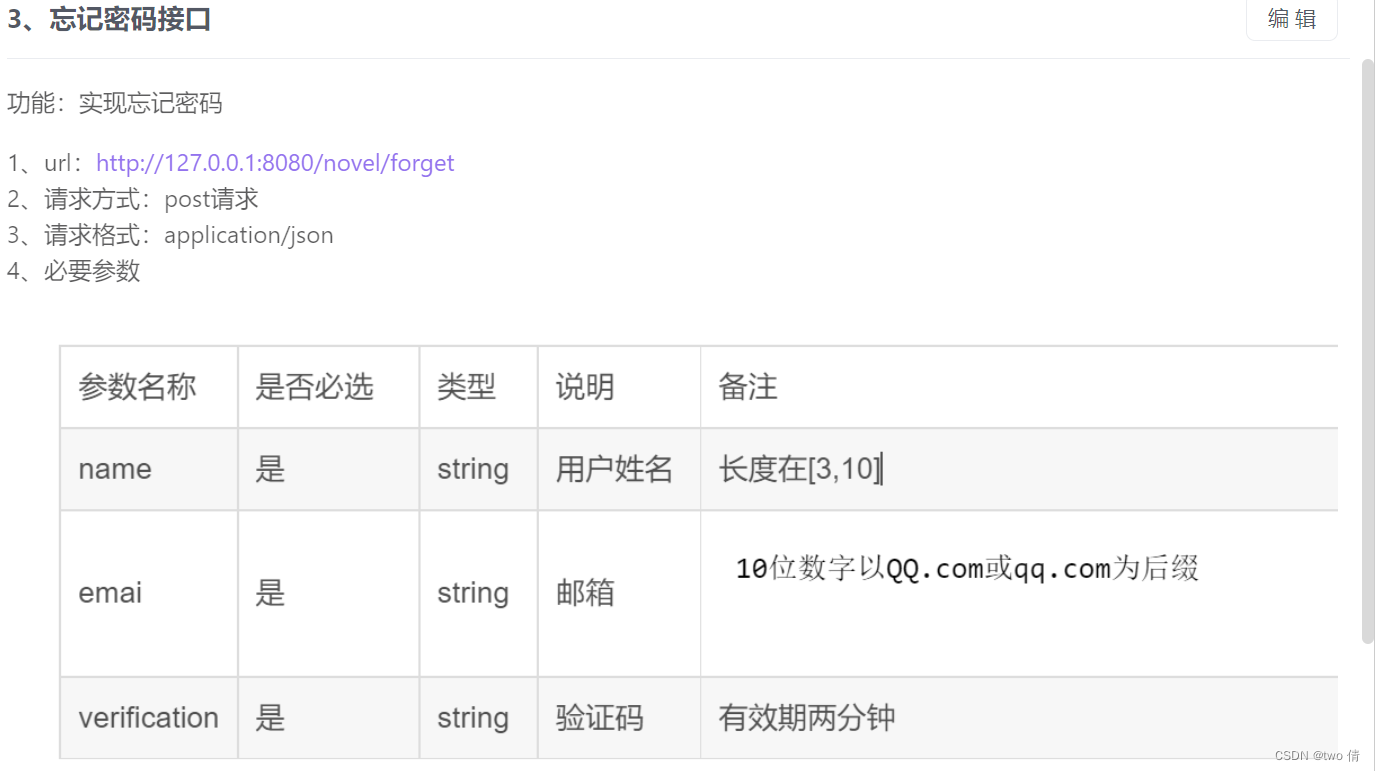

接口测试
- 1、数据输入存在未输入情况
- 2、数据输入null值 (分为null和"null")
- 3、数据输入长度不符合要求 (使用等价类,比如用户名长度[3,10],测试长度为2,3,10,11的情况)
- 4、数据输入类型不匹配
- 5、用户名和邮箱匹配(用户名称和邮箱校验,其中邮箱不论是QQ.com或者qq.com为后缀,只要前10位数字相同即可)
- 6、邮箱格式不正确
- 7、验证码错误,验证码过期
- 8、邮箱和用户名不匹配(用户名不存在,邮箱不存在,用户名和密码不匹配)
注意:这里如果测试用例中先有一个校验成功的case,会设置一个session,(如果之前的session没有过期)这里获取的是和验证码同一个session,然后session的有效期被更新设置为了5分钟。如果继续设置验证码过期的case(设置两分钟),那么验证码是不会过期的
getsession(true):当参数为true时,若存在会话,则返回该会话,否则创建一个会话

UI测试
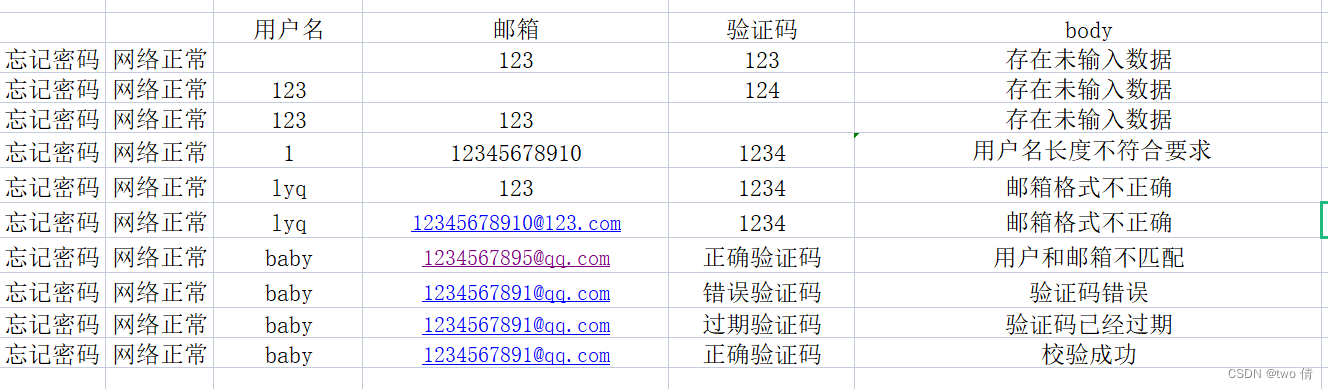
1、检测前六个数据
class TestForget():
@pytest.mark.parametrize(('name,email,verification,body'),
[["","123","123","存在未输入数据"],["123", "", "124", "存在未输入数据"], ["123", "123", "", "存在未输入数据"],
['1', '12345678910', '1234',"用户名长度不符合要求"], ['lyq', "123", "1234", "邮箱格式不正确"],
["lyq","12345678910@123.com","1234","邮箱格式不正确"]] )
def test_forget(self,name,email,verification,body,getDriver):
getDriver.get("http://localhost:8080/novel/forget.html")
Name = getDriver.find_element(By.XPATH, '//*[@id="username"]')
Email = getDriver.find_element(By.XPATH, '//*[@id="email"]')
Ver = getDriver.find_element(By.XPATH, '//*[@id="code"]')
Name.send_keys(name)
Email.send_keys(email)
Ver.send_keys(verification)
time.sleep(1)
submit = getDriver.find_element(By.XPATH, '//*[@id="submit"]')
submit.click()
alert = WebDriverWait(getDriver, timeout=10).until(expected_conditions.alert_is_present())
time.sleep(2)
text = alert.text
alert.accept()
assert text == body
 2、手工测试后面的数据
2、手工测试后面的数据
修改密码页面
1、前置要求:忘记页面页面校验成功(5分钟的session)
2、邮箱发送信息包含验证码(5分钟过期,响应头的Email中,存储了验证码数据)



进行接口测试

用户忘记密码页面登陆成功,才可以来到修改密码页面

UI测试
1、检测数据
import time
import uuid
from selenium import webdriver
import pytest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import wait, expected_conditions
import requests
from selenium.webdriver.support.wait import WebDriverWait
class TestForget():
@pytest.mark.parametrize(('email,password,surepassword,body'),
[["","123","123","存在未输入数据"],
["1123", "", "123", "存在未输入数据"],
["123", "123", "", "存在未输入数据"],
["123", "123", "1231", "两次密码不匹配"],
['123', '123', '123',"密码长度不足"]
])
def test_forget(self,email,password,surepassword,body,getDriver):
getDriver.get("http://localhost:8080/novel/change.html")
alert = WebDriverWait(getDriver, timeout=10).until(expected_conditions.alert_is_present())
alert.accept()
time.sleep(3)
#进入页面 因为此时没有发送邮件 所以弹窗内容是”邮件未发送“
Password = getDriver.find_element(By.XPATH, '//*[@id="password"]')
Email = getDriver.find_element(By.XPATH, '//*[@id="email"]')
SurePassword = getDriver.find_element(By.XPATH, '//*[@id="password_again"]')
Email.send_keys(email)
Password.send_keys(password)
SurePassword.send_keys(surepassword)
time.sleep(3)
submit = getDriver.find_element(By.XPATH, '//*[@id="submit"]')
submit.click()
alert = WebDriverWait(getDriver, timeout=10).until(expected_conditions.alert_is_present())
time.sleep(2)
text = alert.text
print(alert.text)
alert.accept()
assert text == body
2、手工测试
主页页面测试

1、点击分类表格,检测跳转页面的分类信息和页面标题,是不是和所点击分类相对应
import time
from telnetlib import EC
import pytest
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC, wait
#点击主页的分类表格,检测跳转页面的数据是不是为同一个分类的书籍
def test_demo(getDriver):
getDriver.get("http://localhost:8080/novel/homepage.html")
current=getDriver.current_window_handle
#表格的分类数据的xpath
# //*[@id="table"]/tbody/tr[1]/td[1]/a #//*[@id="table"]/tbody/tr[1]/td[2]/a
#//*[@id="table"]/tbody/tr[2]/td[1]/a
classifys = getDriver.find_elements(By.XPATH,'//*[@id="table"]/tbody/tr/td/a')
opened=[]
opened.append(current)
for classify in classifys:
value = classify.text
print(value)
time.sleep(3)
classify.click()
for page in getDriver.window_handles:
if page not in opened:
getDriver.switch_to.window(page)
opened.append(page)
# 等待页面加载到元素出现
WebDriverWait(getDriver, timeout=10).until(
lambda d: d.find_element(By.XPATH, '/html/body/span[4]/span[2]/span/p'))
# 1、检测页面的title是否正确
assert getDriver.title == value + "书籍"
# 2、检测推荐书籍页面的页面标签 是不是同样的分类书籍
# / html / body / span[2] / span[1] / div[2] / div[1] / a[1]
# / html / body / span[2] / span[1] / div[3] / div[1] / a[1]
# / html / body / span[2] / span[1] / div[4] / div[1] / a[1]
# 获取到上述所有元素
values = getDriver.find_elements(By.XPATH, '/html/body/span[2]/span[1]/div/div[1]/a[1]')
for val in values:
assert val.text == value
# 3、书籍介绍分类处
assert getDriver.find_element(By.XPATH, '/html/body/span[3]').text == value + "书籍"
# 4、榜一的数据分类
try:
ele = getDriver.find_element(By.XPATH, '/html/body/span[4]/span[2]/span/span[1]/span[1]/span/span[1]/a')
assert ele.text == value
except: # 捕捉到了异常
pass
getDriver.switch_to.window(current)
2、本周推荐的分类检测
import time
from telnetlib import EC
import pytest
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC, wait
#本周推荐的分类测试
def test_demo(getDriver):
getDriver.get("http://localhost:8080/novel/homepage.html")
current=getDriver.current_window_handle
#/html/body/span[3]/span[1]/div[2]/span/a[1]
#/html/body/span[3]/span[1]/div[3]/span/a[1]
classifys = getDriver.find_elements(By.XPATH,'/html/body/span[3]/span[1]/div/span/a[1]')
opened=[]
opened.append(current)
for classify in classifys:
value = classify.text
print(value)
classify.click()
for page in getDriver.window_handles:
if page not in opened:
getDriver.switch_to.window(page)
opened.append(page)
# 等待页面加载到元素出现
WebDriverWait(getDriver, timeout=10).until(
lambda d: d.find_element(By.XPATH, '/html/body/span[4]/span[2]/span/p'))
# 1、检测页面的title是否正确
assert getDriver.title == value + "书籍"
# 2、检测推荐书籍页面的页面标签 是不是同样的分类书籍
# / html / body / span[2] / span[1] / div[2] / div[1] / a[1]
# / html / body / span[2] / span[1] / div[3] / div[1] / a[1]
# / html / body / span[2] / span[1] / div[4] / div[1] / a[1]
# 获取到上述所有元素
values = getDriver.find_elements(By.XPATH, '/html/body/span[2]/span[1]/div/div[1]/a[1]')
for val in values:
assert val.text == value
# 3、书籍介绍分类处
assert getDriver.find_element(By.XPATH, '/html/body/span[3]').text == value + "书籍"
# 4、榜一的数据分类
try:
ele = getDriver.find_element(By.XPATH, '/html/body/span[4]/span[2]/span/span[1]/span[1]/span/span[1]/a')
assert ele.text == value
except: # 捕捉到了异常
pass
getDriver.switch_to.window(current)
3、本周推测的书籍点击(检测页面跳转的书籍信息是否和数据库匹配)
import time
from telnetlib import EC
import pytest
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC, wait
#本周推荐的分类测试
def test_demo(getDriver,getconnect):
getDriver.get("http://localhost:8080/novel/homepage.html")
current=getDriver.current_window_handle
#/html/body/span[3]/span[1]/div[2]/span/a[2]
# #/html/body/span[3]/span[1]/div[3]/span/a[2]
classifys = getDriver.find_elements(By.XPATH,'/html/body/span[3]/span[1]/div/span/a[2]')
opened=[]
opened.append(current)
for classify in classifys:
value = classify.text
classify.click()
for page in getDriver.window_handles:
if page not in opened:
getDriver.switch_to.window(page)
opened.append(page)
# 等待页面加载到元素出现
WebDriverWait(getDriver, timeout=10).until(lambda d: d.find_element(By.XPATH, '//*[@id="textarea"]'))
# 1、检测页面的title是否正确
assert getDriver.title == value
#2、检测页面书籍名称
assert getDriver.find_element(By.XPATH,'/html/body/span[1]/span[2]/span[1]/span').text==value
#3、检测书籍信息和数据库是否匹配
#创建游标对象
cur=getconnect.cursor()
sql="select * from book where book_name=('%s')"%(value)
cur.execute(sql)
result=cur.fetchone()
#验证作者信息
assert result[1]+" 著"==getDriver.find_element(By.XPATH,'//*[@id="writername"]').text
#验证书名
assert result[3]==value
#验证分类
assert result[4]==getDriver.find_element(By.XPATH,'//*[@id="style"]').text
#验证状态
assert result[8]==getDriver.find_element(By.XPATH,'//*[@id="state"]').text
getDriver.switch_to.window(current)
分类页面测试
进行接口测试
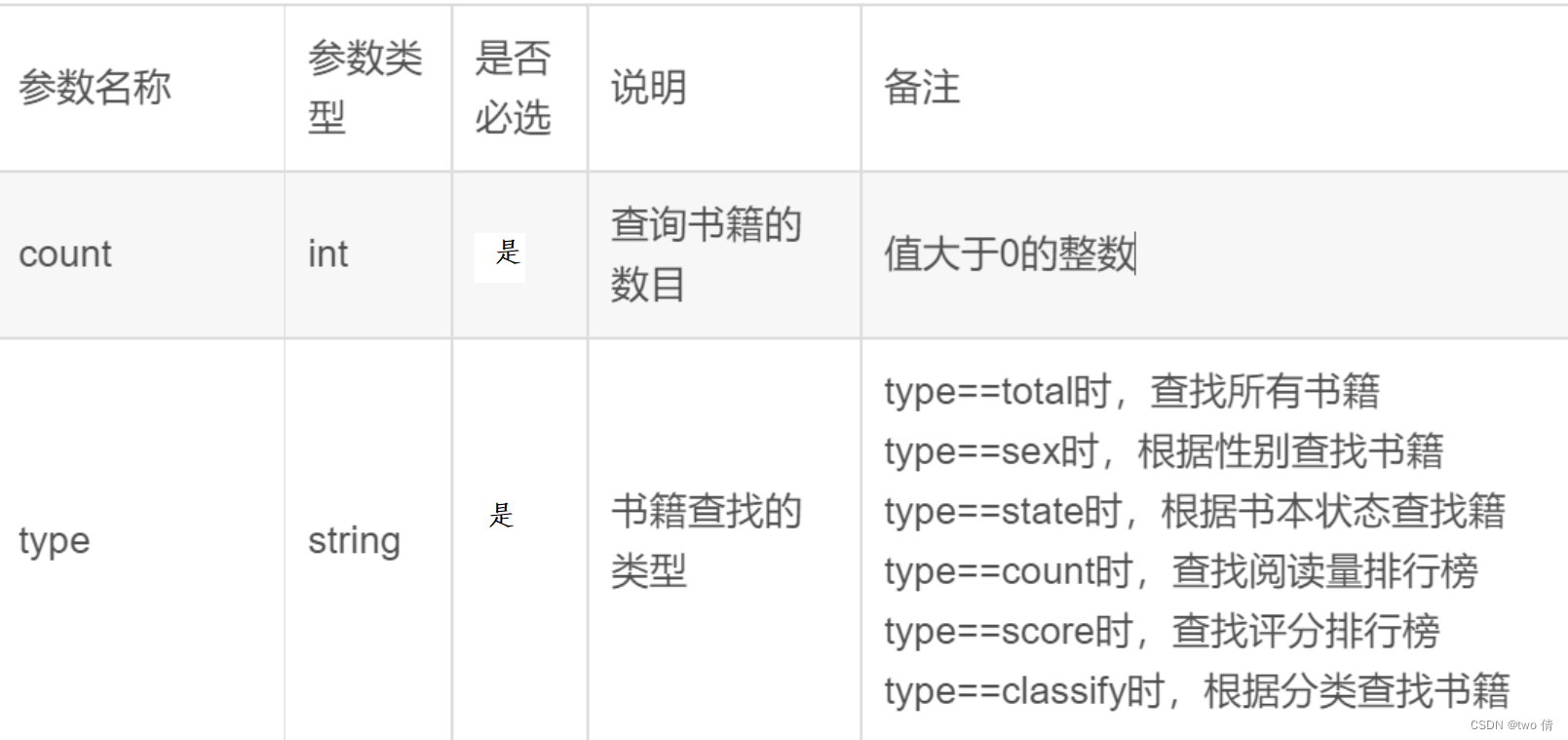
将分类查找的书籍,和数据库数据相比对
检测type不是total,sex,state时的返回结果
import pytest
import requests
import yaml
from selenium.webdriver.chrome import webdriver
from selenium.webdriver.common.by import By
import common.yaml
import debug_talk
from classify.package import Unifiedrequest
@pytest.mark.parametrize('values,sql', [('count=3&type=total', 'select * from book limit 3'),('type=total&state="完结"', 'none'),
('type=total&count=3', 'select * from book limit 3'), ('type=total&count=-1', 'none'),('type=total&count=0', 'none'),('type=total&count=null', 'none'),
(('type=null&count=null', 'none')),('type="null"&count=-1', 'none'),(('type=null&state="完结"', 'none')),('type="null"&classify_name="玄幻"', 'none'),
(('type="classify"&count=null', 'none')), ('type="classify"&classify_name="null"', 'none'),(('type="classify"&state="完结"', 'none')), ('type="classify"&classify_name="玄幻 &count=3"', 'select * from book where classify_name="玄幻" limit 3'),
(('type="state"&count=null', 'none')) , ('type="state"&sex="全部"', 'none'),('type="state"&count=-1', 'none'),(('type="state"&state="全部"&count=10', 'select * from book where state="全部" limit 10')),
(('type="sex"&count=null', 'none')), ('type="sex"&state=null', 'none'),('type="sex"&sex=null', 'none'), (('type="sex"&sex="全部"&count=10', 'select * from book where sex="全部" limit 10')),
(('type="ttgjj"&sex="全部"&count=10', 'none')),((('type="sex"&sex="hhh"&count=10', 'none')),)
])
def test_send(values, sql, getconnect):
res = requests.session().get(url='http://127.0.0.1:8080/novel/getshowbooks', params=values)
try:
results = res.json()
cur = getconnect.cursor()
count = cur.execute(sql)
books = cur.fetchall()
i = 0
for book in books:
i += 1
falg = False
for result in results:
if (int)(book[0]) == result['book_id'] and \
book[1] == result['writer_name'] and \
book[2] == result['photo'] and \
book[3] == result['book_name'] and \
book[4] == result["classify_name"] and \
book[5] == result['book_brief']:
falg = True
break
assert falg == True
assert i == count
except:
assert sql=='none'
 查询页面测试
查询页面测试
import time
from telnetlib import EC
import pytest
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC, wait
@pytest.mark.parametrize('value,method',[
('余华','author'), ('东野圭吾','author'),('曹雪芹','author'),
('红楼梦','book'),('三国演义','book'),('白夜行','book'),('三国演义','book'),
(' ','author')
]
)
#搜索功能的展示
def test_demo(value,method,getDriver,getconnect):
getDriver.get('http://localhost:8080/novel/search.html')
getDriver.find_element(By.XPATH, '//*[@id="search"]').clear()
getDriver.find_element(By.XPATH, '//*[@id="search"]').send_keys(value)
getDriver.find_element(By.XPATH, '//*[@id="searchbutton"]').click()
time.sleep(1)
cursion = getconnect.cursor()
if (method == 'author'):
sql = "select book. * from book where writer_name like concat('%s')" % (value)
booksname = [] # 书名称
rowcount = (cursion.execute(sql)) # 执行sql语句
writers = cursion.fetchall()
print(writers)
# 搜索数量的展示
books = getDriver.find_elements(By.XPATH, '/html/body/span[2]/span')
assert rowcount == len(books)
#书籍名称
#/html/body/span[2]/span[1]/span[2]/span[1]/a
#/html/body/span[2]/span[2]/span[2]/span[1]/a
web_books = getDriver.find_elements(By.XPATH, '/html/body/span[2]/span/span[2]/span[1]/a')
for book in web_books:
booksname.append(book.text)
for writer in writers:
book_id = writer[2]
# 获取book_id
sql_book = "select * from book where book_id=('%s')" % (book_id)
cursion.execute(sql_book)
result = cursion.fetchone()
assert result[3] in booksname
if (method == 'book'):
sql = "select book. * from book where book_name like concat('%s')" % (value)
rowcount = (cursion.execute(sql)) # 执行sql语句
values = []
# 搜索数量的展示
# / html / body / span[2] / span[2] / span[2] / span[1] / a
# / html / body / span[2] / span[1] / span[2] / span[1] / a
books = getDriver.find_elements(By.XPATH, '/html/body/span[2]/span')
assert rowcount == len(books)
# 数据库查找结果
rowcount = (cursion.execute(sql)) # 执行sql语句
results = cursion.fetchall()
print(results)
# 前端展示的书籍名称
web_books = getDriver.find_elements(By.XPATH, '/html/body/span[2]/span/span[2]/span[1]/a')
for name in web_books:
values.append(name.text)
flag = False
for val in values:
for i in range(0,rowcount):
if(val==results[i][3]):
flag = True
assert flag == True
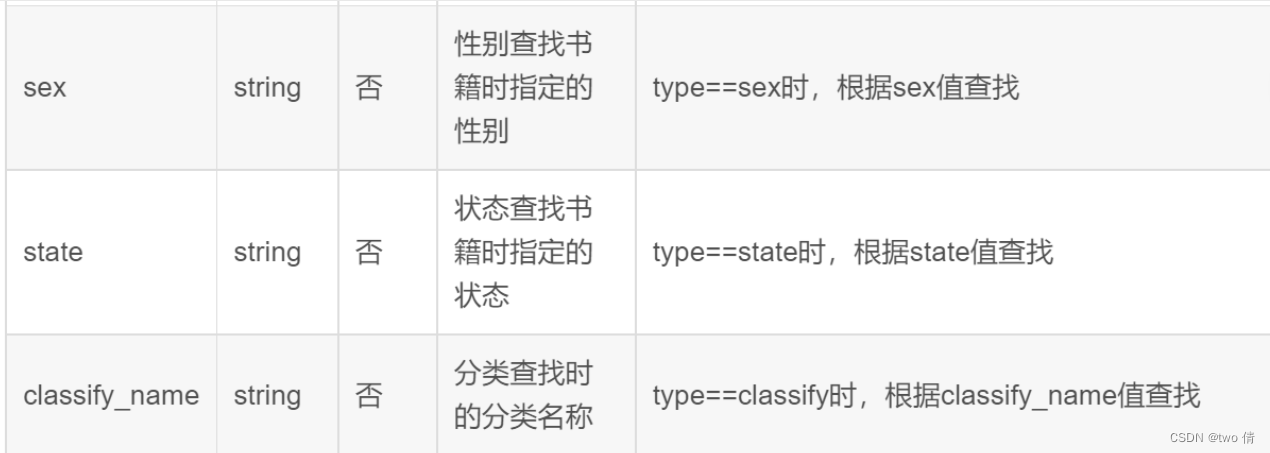
作者页面测试
查询展示的作者书籍总数,书籍信息介绍是否和数据库匹配
import time
from telnetlib import EC
import pytest
from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC, wait
def test_demo(getDriver, getconnect):
cursion = getconnect.cursor()
sql = 'select * from book'
rowcount = cursion.execute(sql) # 执行sql语句
for i in range(1,rowcount):
try:
getDriver.get("http://localhost:8080/novel/novel.html?book_id=" + str(i))
current = getDriver.current_window_handle
WebDriverWait(getDriver, timeout=10).until(lambda d: d.find_element(By.XPATH, '//*[@id="textarea"]'))
value = getDriver.find_element(By.XPATH, '//*[@id="writername"]').text
value = value.split(' ')[0]
print(value)
getDriver.find_element(By.XPATH, '//*[@id="writername"]').click()
# 等待页面加载到元素出现
for page in getDriver.window_handles:
if page != current:
getDriver.switch_to.window(page)
WebDriverWait(getDriver, timeout=10).until(
lambda d: d.find_element(By.XPATH, '/html/body/span[3]/span[1]/span[2]'))
# 1、检测页面的title是否正确
assert getDriver.title == value
# 2、连接数据库
cursion = getconnect.cursor()
sql = 'select * from writer where writer_name=("%s")' % (value)
rowcount = (str)(cursion.execute(sql)) # 执行sql语句
assert "作品总数 " + rowcount == getDriver.find_element(By.XPATH, '/html/body/span[1]/span/span[2]').text
writers = cursion.fetchall()
# 书的名称 /html/body/span[3]/span[1]/span[2]/span[1]/a
# /html/body/span[3]/span[2]/span[2]/span[1]/a
web_books = getDriver.find_elements(By.XPATH, '/html/body/span[3]/span/span[2]/span[1]/a')
print(web_books)
books = [] # 书名称
for book in web_books:
books.append(book.text)
for writer in writers:
book_id = writer[2] # 获取book_id
sql_book = "select * from book where book_id=('%s')" % (book_id)
cursion.execute(sql_book)
result = cursion.fetchone()
assert result[3] in books
except:
raise NameError("打开网址错误", "http://localhost:8080/novel/novel.html?book_id=" + str(i))
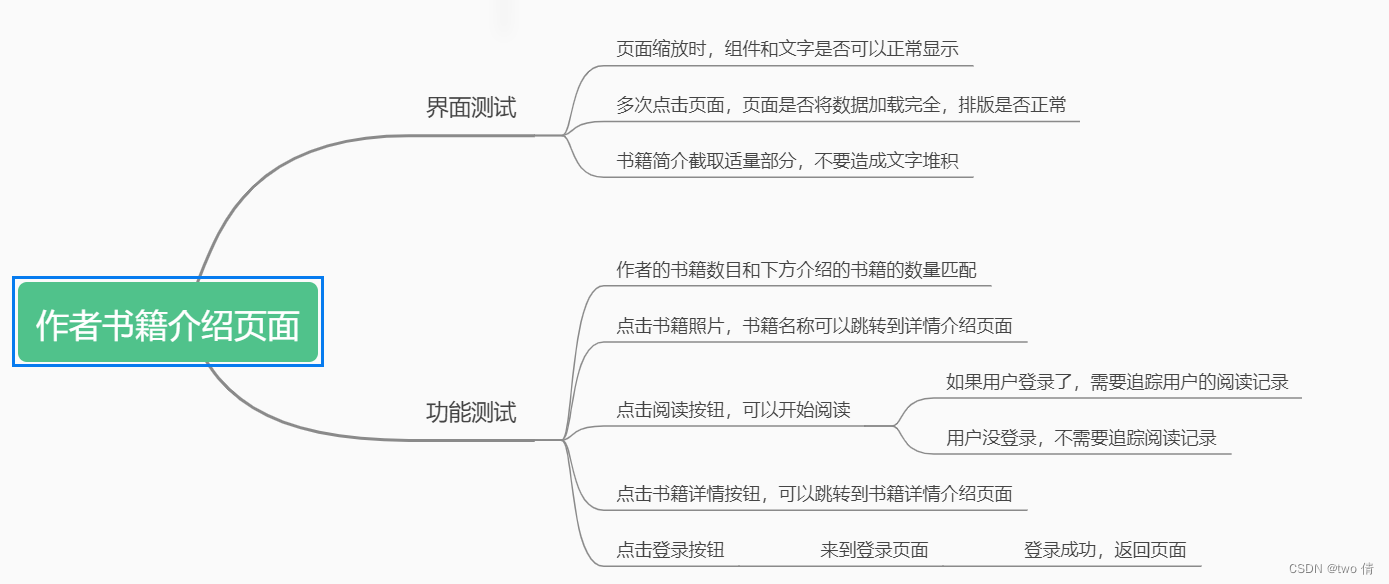
阅读小说页面测试
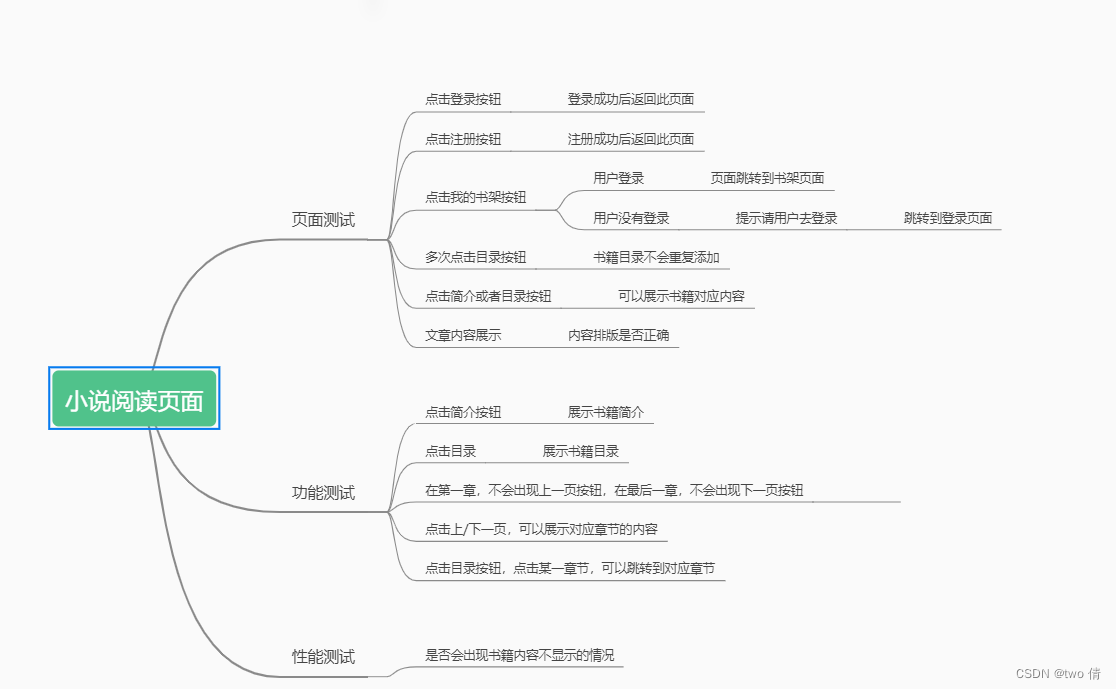
1、查看各个页面的阅读小说按钮是否正确跳转
2、在用户未登录时,不会保留用户的阅读记录
3、如果用户登录,会保留阅读记录(直接阅读,会来到上一次阅读的章节)
4、阅读的几种方式:直接点击阅读按钮,点击目录阅读,点击上下一页阅读
5、小说第一章,不会出现上一页按钮。小说最后一章,不会出现下一页按钮
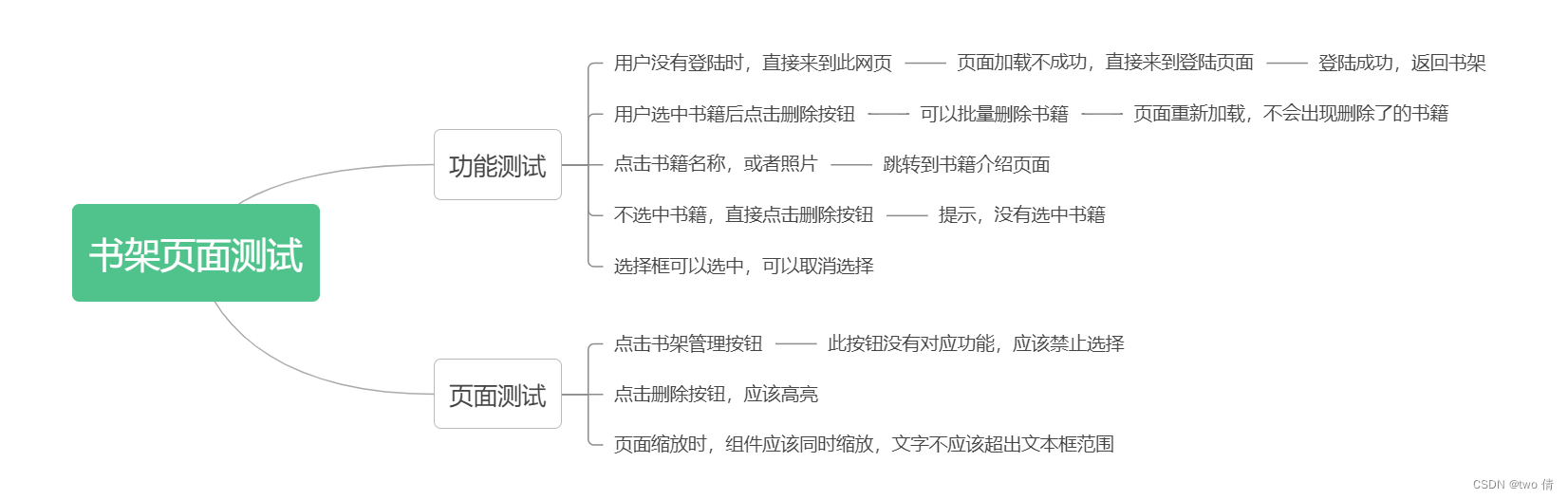
书架页面测试
Bug
1、登录页面、注册页面、修改密码页面,输入过长的密码时,可视组件被遮挡

2、各个页面在窗口缩放时,页面文字,组件会产生堆积
3、在注册页面,输入超过17位长度的邮箱数据,响应是500
(已解决,应该先限制邮箱长度==17,造成了下标越界)
4、搜索框不支持enter键确认

5、在小说阅读页面,点击阅读按钮,会出现文章内容加载不成功的现象,但是重新刷新以下,就会加载成功
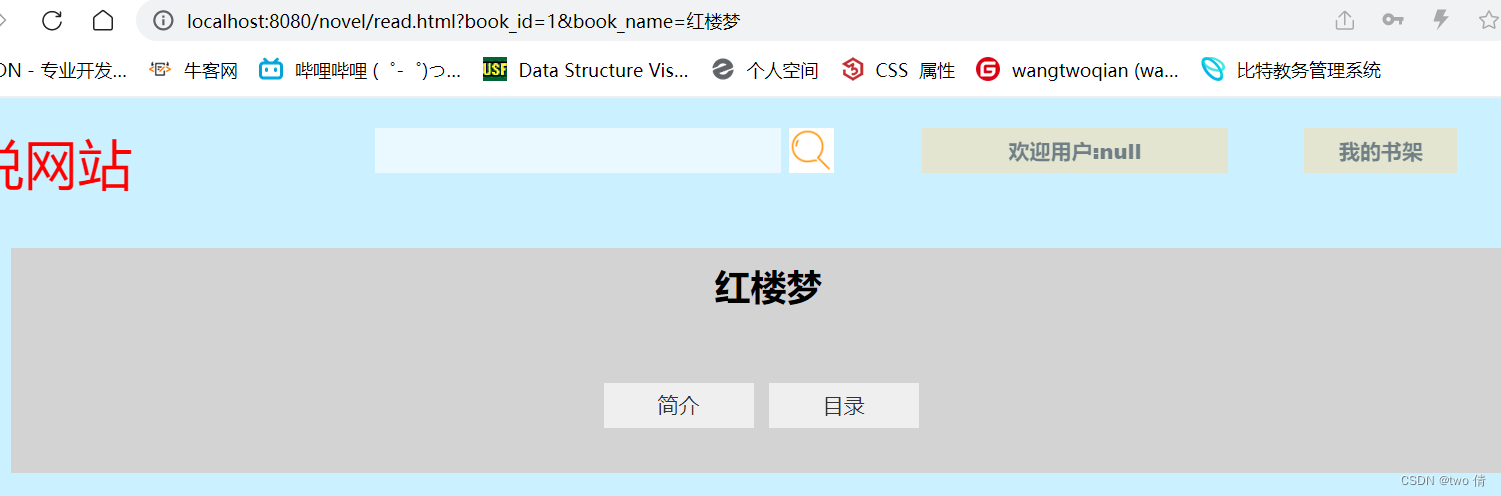
6、在前端没有处理好不存在的数据(每一个页面都会出现此类情况)
1、小说介绍页面,当数据不存在时,应该显示404
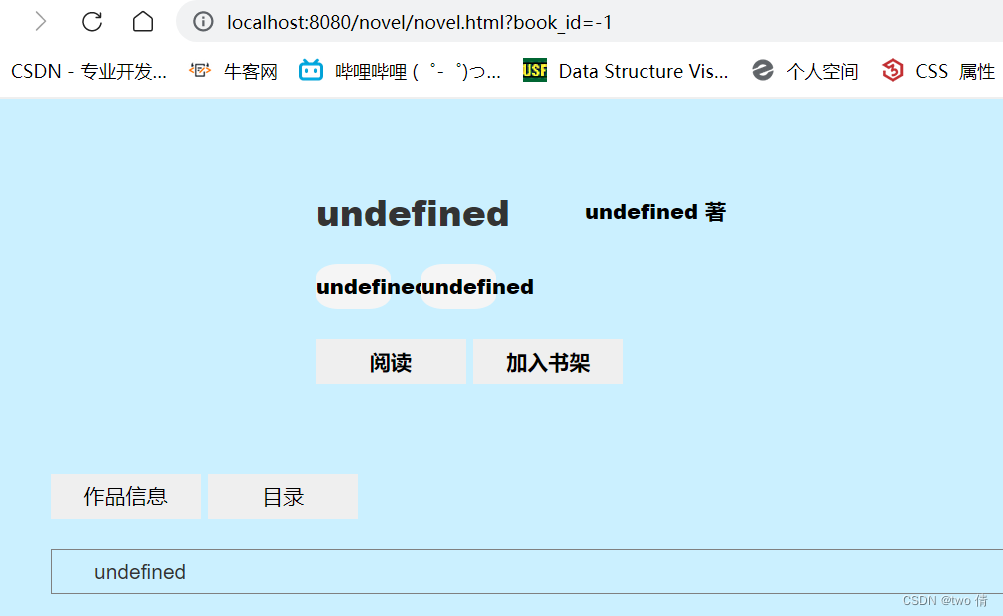
2、在小说阅读界面
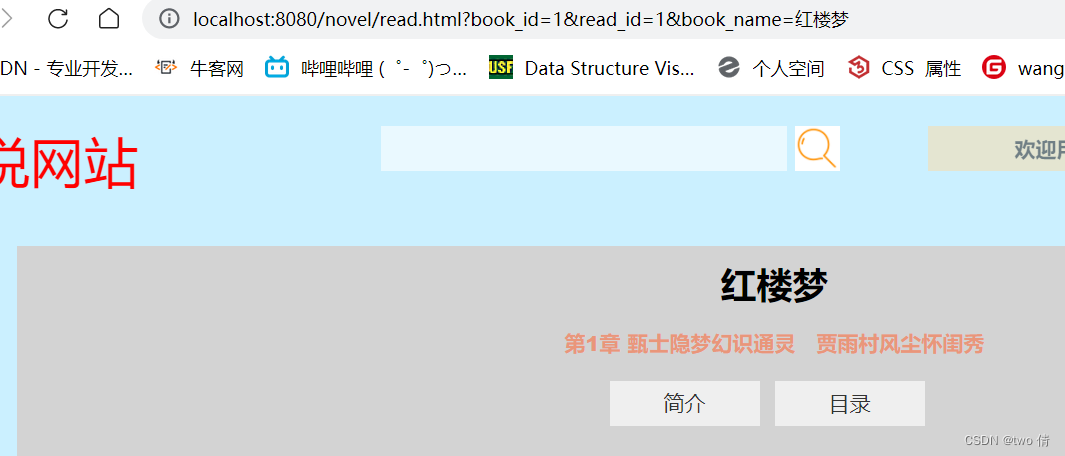
如果手动将数据更改,就会导致错误,比如将书名更改

将book_id改为-1,应该返回页面是404
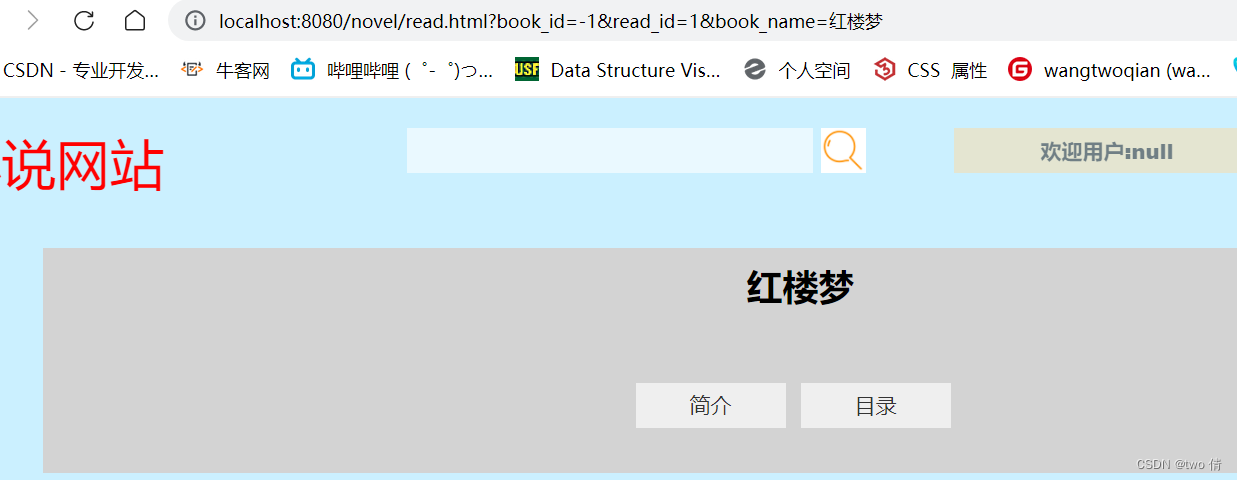
3、在分类页面
7、页面会出现排版左移的情况,比如
gitee链接:
登录 - Gitee.com










![Python蓝桥杯训练:基本数据结构 [哈希表]](https://img-blog.csdnimg.cn/img_convert/f3813003839964b99c99c75663118b99.jpeg)