1. 大小端介绍
-
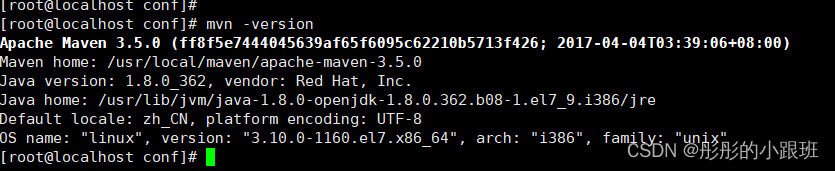
大端(Big Endian)和小端(Little Endian)是两种CPU或者计算机系统存储数据的方式。
-
在大端系统中,数据的高位字节(MSB)存储在内存地址的低位,低位字节(LSB)存储在内存地址的高位,这种存储方式类似于阅读习惯,从左到右。
-
在小端系统中,数据的低位字节存储在内存地址的低位,高位字节存储在内存地址的高位,这种存储方式和我们平时阅读数字的顺序是一致的,从右到左。假如我们有一个十六进制数
0x12345678占用四个字节,如果它是大端存储将是以下画面:
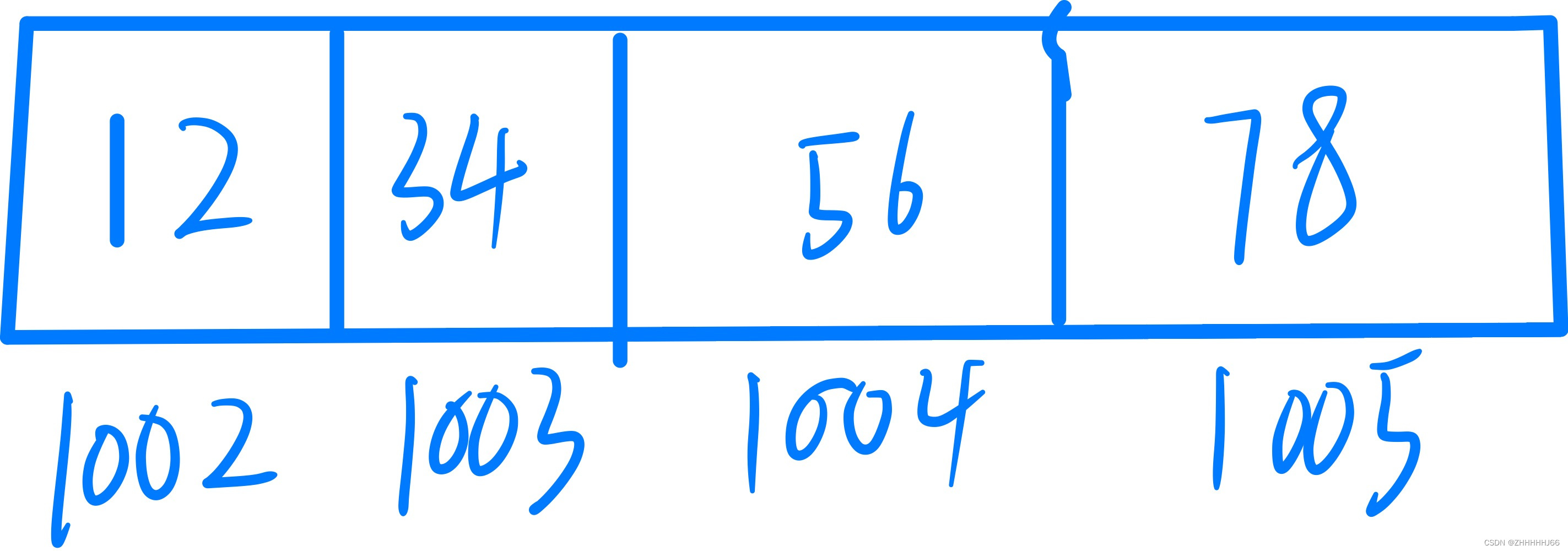
因为
12是十六进制数0x12345678的高位,它存在低地址位中,因此是高位字节存储在低内存地址,因此是大端存储,这也看起来符合人的思维
如果它小端存储则是以下画面
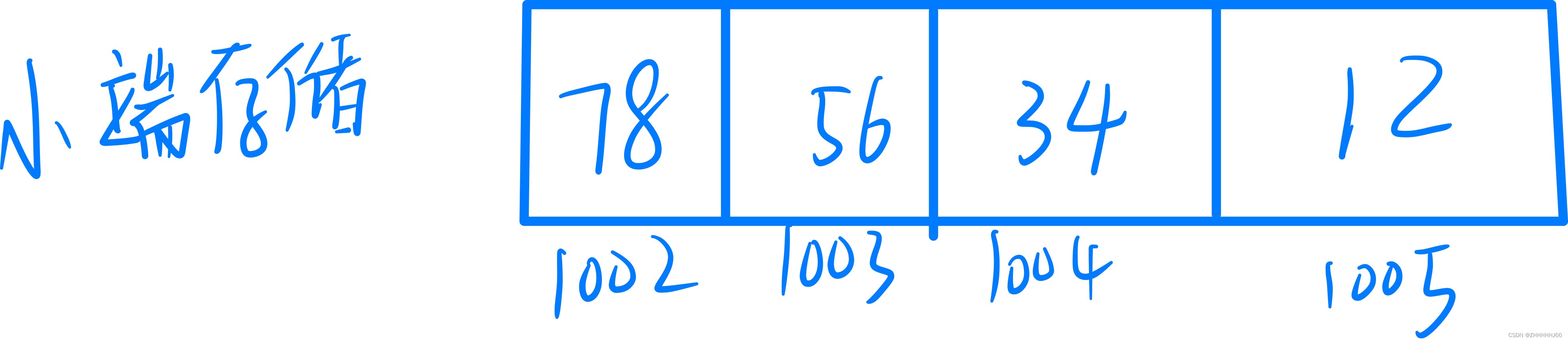
这看起来就很反人类阿,低字节的
78存在了左边,但是字面上却合顺,即低字节存在地址低字节。这就是小端存储。
2. 使用union判断大小端
2.1 union内存处理方式
union内存特点主要有如下:
- 联合体的所有成员相对于基地址的偏移量为0
- 联合的内存大小等于其中最大成员的大小。
- 联合的所有成员共享同一块内存区域,即它们的存储位置是相同的。
- 其对其方式要适合于联合体中所有类型的成员
用人话讲就是:
- 联合体要大于等于最长的一个结构变量的空间
- 联合体变量的各个成员都是从低字节开始公用的(这是最重要的)
2.2 使用union判断大小端
#include <stdio.h>
int check_ending()
{
union{
int a;
char b;
}c;
c.a = 1;
return c.b == 1;
}
int main()
{
if (check_ending()) printf("the little end!");
else printf(" the big end");
}
代码中使用了一个联合体c来测试CPU字节序。联合体中包含了一个int类型的成员a和一个char类型的成员b。因为int类型占据了4个字节,而char类型只占据了一个字节,所以当联合体中的整型变量a被设置为1时,如果该CPU是小端序,它在内存中的存储顺序将会是0x01 00 00 00,而char类型变量b所占据的第一个字节的值应该为1。如果是大端序,它在内存中的存储顺序将会是0x00 00 00 01,而char类型变量b所占据的第一个字节的值应该为0。
最后,在main函数中根据checkCPU()的返回值输出对应的信息,告知当前CPU的字节序。如果checkCPU()返回true,则表示当前CPU是小端序,输出"The endian of cpu is little \n";如果checkCPU()返回false,则表示当前CPU是大端序,输出"The endian of cpu is big \n"。
画图讲解:
c
+-------+
a | | 0x00000001
+-------+
b | 01 | 0x01
+-------+
小端序:
c.a = 0x00000001,在内存中的存储顺序为:
+----+----+----+----+
| 01 | 00 | 00 | 00 |
+----+----+----+----+
c.b 的值为0x01,低地址存放低字节,因此判断为小端序,由于b也是从低字节开始存储数据,因此b的数值和a一样。
大端序:
c.a = 0x00000001,在内存中的存储顺序为:
+----+----+----+----+
| 00 | 00 | 00 | 01 |
+----+----+----+----+
c.b 的值为0x00,低地址存放高字节,因此判断为大端序,a的低字节位1存在了内存的高地址上,b却仍然从低地址位读数据,因此是0