系统背景介绍

 ``
``
数据提供企业决策能力
网站日志的数据分析------》受欢迎程度
如何评价你这个网站的受欢迎程度 用数据 下载的人多了 观看的人多了
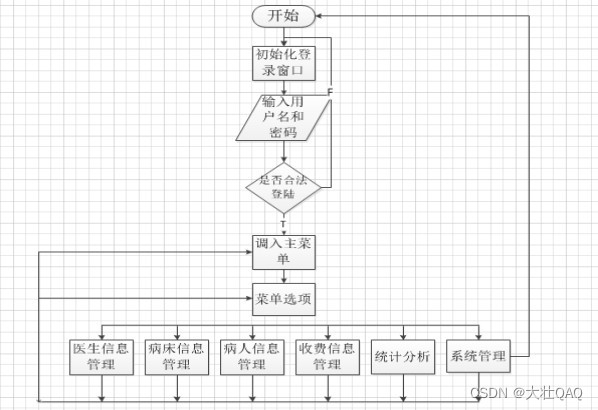
通过Hadoop 对某个网站产生的日志数据流量进行统计分析 得出该网站的访问流量
继而做出决策
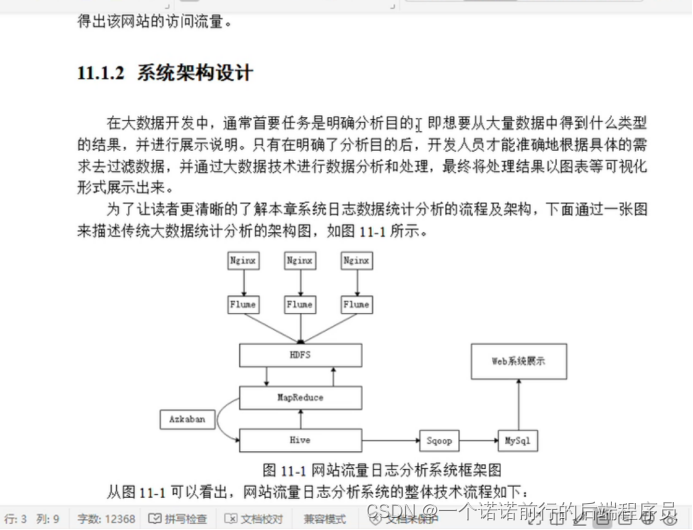
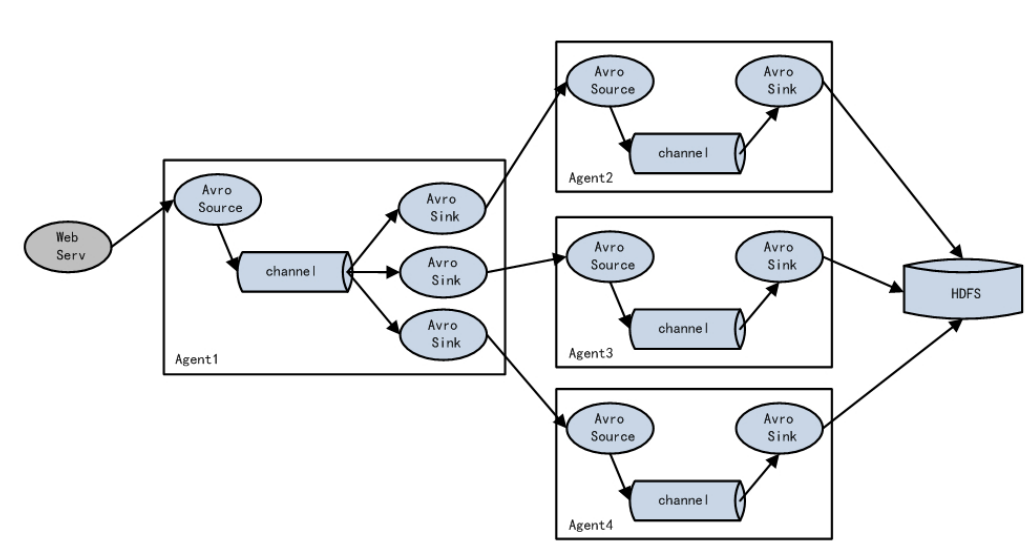
我们可以采用flume收集nginx的success文件日志
nginx--->flume------>hdfs---->hive数据分析------>sqoop到mysql中
flume采集数据到hdfs(),
数仓
mr对数据进行预处理(原始目录 现有目录)
hive(数仓分层 分析 将目录的数据导入到表中)
放在hdfs上
接下来我们可以写mapreduce程序对我们采集后的日志进行预处理
因为从服务器采集过来的数据可能格式并不满足我的需求
数仓
因为这些日志数据可能有一些脏数据我们要通过mr 程序给这些数据进行一个清洗
把他们变成结构化的文件
预处理---------》hive 在这里我们可以对我们的数据进行一个数据分析
数据分析也是我们大数据处理之后最为重要的环节
经过数据分析之后可以得到一个结果 使用sqoop 导出到mysql
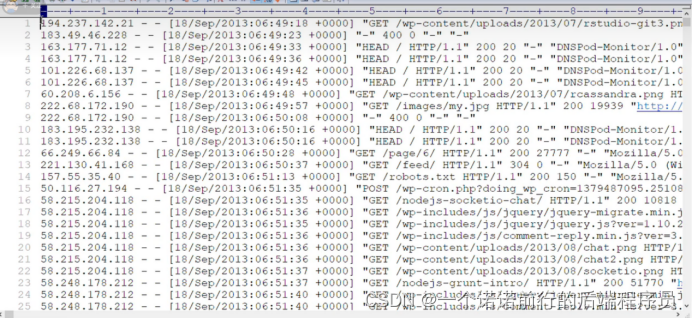
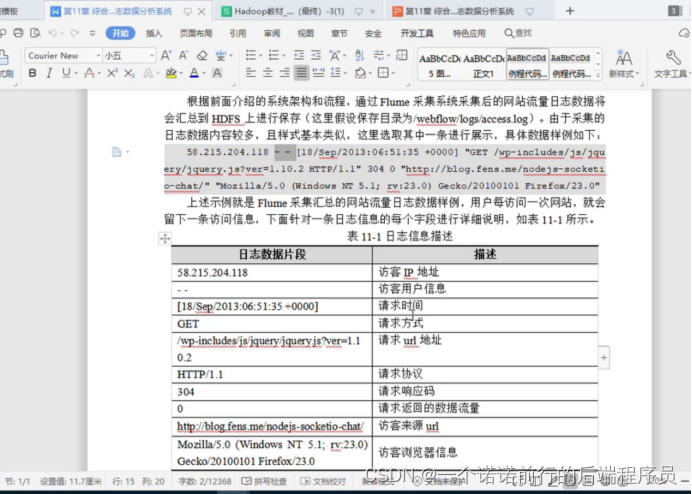
1.flume采集日志 flume的source channel sink 的配置
我们需要通过flume采集日志信息数据
采集之后存储在hdfs
采集nginx.access.log
access.log
这时就涉及到模块开发了
接下来我们来看数据的预处理阶段,我们要分析预处理的数据.我们要把不合法的数据丢失了 要过滤掉
数据预处理的流程
首先我们拿到原始数据 然后对数据进行清洗

预处理阶段可以使用mr来实现 使用mr来实现清理和筛选 不合法的数据我添加一个标识,不让他物理删除
我们此时的数据清洗只需要使用mapTaks就可以完成我们的任务
分析预处理的数据
在这里我们需要对flume收集后的数据使用mr进行预处理,通过预处理将我们的日志数据变成方便分析的一种格式
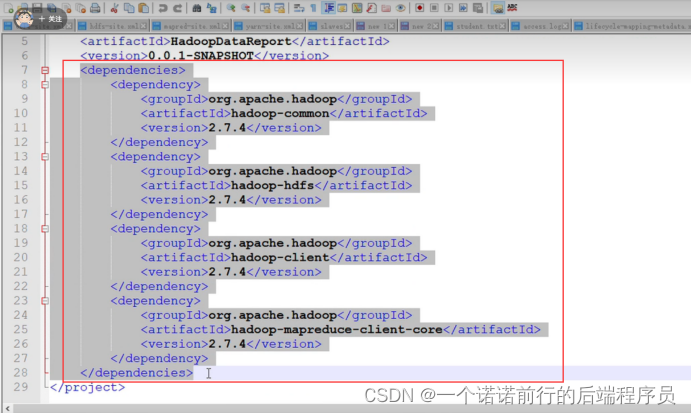
Hadoop添加我们的Jar的依赖
封装Javabean对象
我们要编写mr程序来做预处理 也就是说哦我们呢数据真正的处理是要通过mr来做的
mr的程序 我们要写3个类 一个mapper 一个reducer 一个main
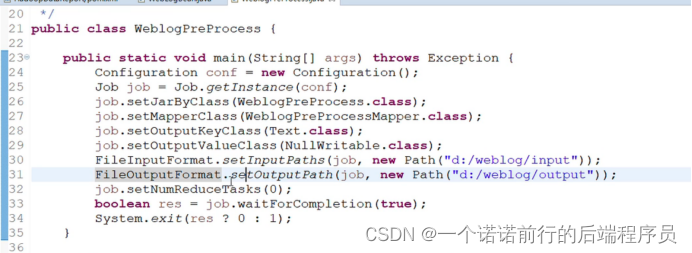
1.获取job对象
2.源文件输入路径 输出到哪里
3.设置reduce为0
把我们的任务提交到Job
mapper类 map方法是核心处理数据的
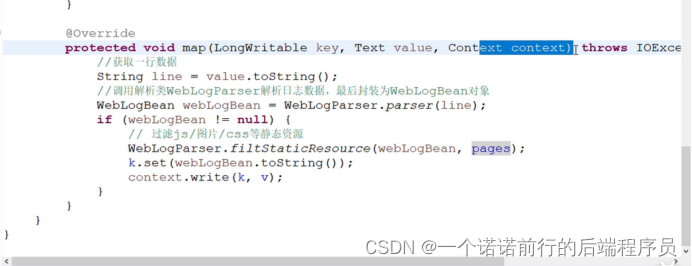
一行文本数据封装javabean对象 WebLogBean
我要过滤掉静态资源因为我在进行分析的时候我不用分析css
经过过滤之后保证我们wbeLogbean是我们的想要的数据
Context.write(k2,v2).. 将K2和v2写在上下文中
mapTask 一行一行读取 封装javaBean ,
过滤css
False 代表有问题的 这一行的数据是否合法
True就代表没有问题
我们进行完毕数据预处理之后 接下来我们就可以吧mr输出结果上传到hdfs中
并且可以使用hive建立表的结构和我们输出结果的映射关系
hive可以将文件数据和表进行映射
建设数仓
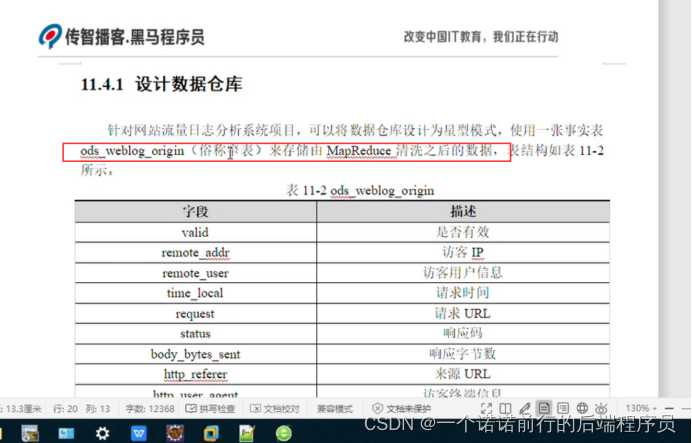
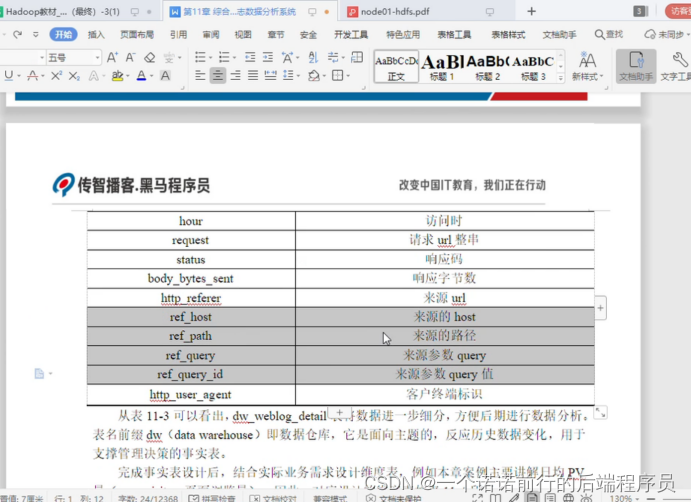
1. 数仓分层 ods表
------>mr输出处理之后的日志数据的字段
2. 设置宽表 将原先的窄表分解成了宽表

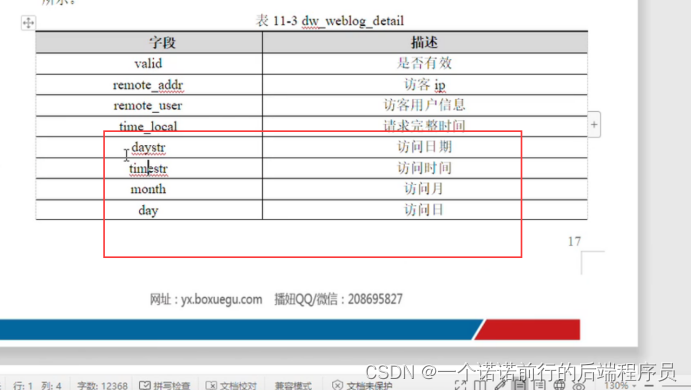
针对这个字段进一步拆分 比如说月 天小时
在窄表的基础上进行拆分 我们拆分的就是这个time_local 日期在表达的时候更加清晰
我们的宽表就是基于窄表的loca_time ,http_referer进一步进行拆分
第三步
我们的实时表就是这个宽表,写完事实表之后 我们要根据业务需求设计维度表,我们此时只是日均pv量
其实就是页面的访问量

我们可以根据自己的需求定义维度表,来进行多角度的数据分析
启动hive服务 创建hive数仓
1、mr的数据导入到base表 2. 建立大宽表 3. 基于业务建立维度表
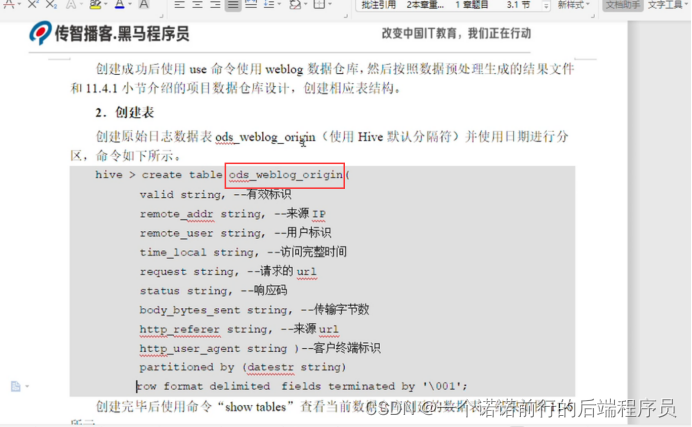
可以将mr 处理后的数据文件导入到数仓中 是一个分区表 按照 xxx分区 按照天来进行分区
我们需要将mr清洗之后的结果文件导入到ods
Load表
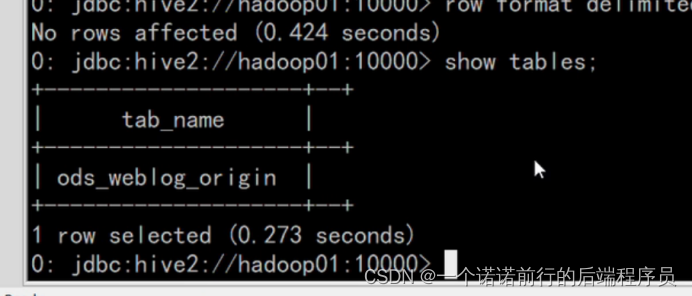
数据加载成功Load到hive中
生成数据的宽表
从ods(原始数据层)中整理出来一些中间表
将非结构化的数据进行抽取 形成明细表
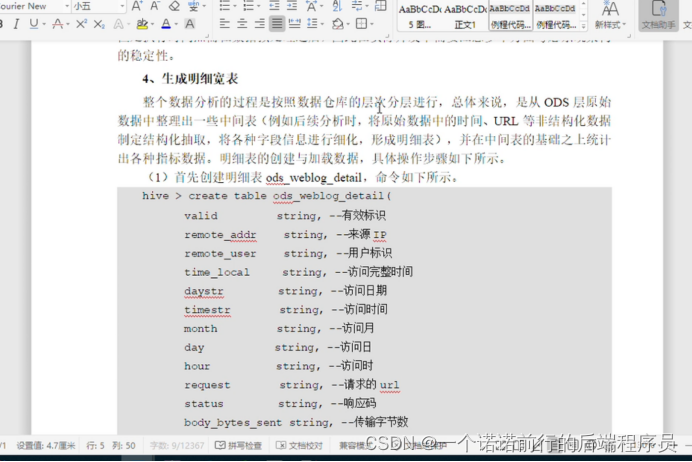
我们就可以将原来宽表的数据进行再一次的拆分 拆分出年月日
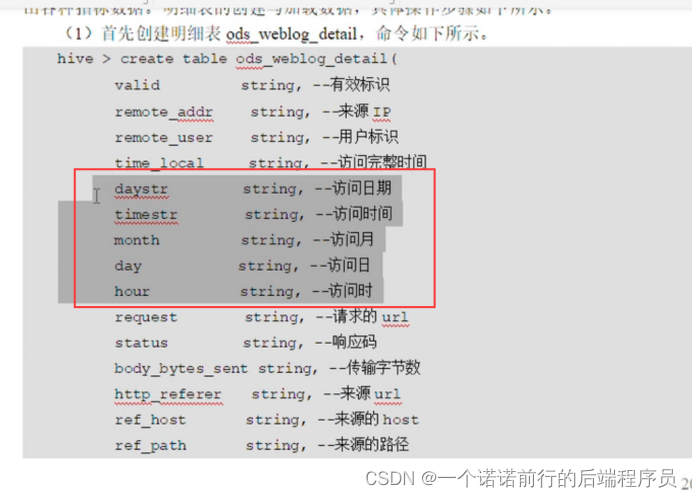
宽表的数据 基于url再进行拆分
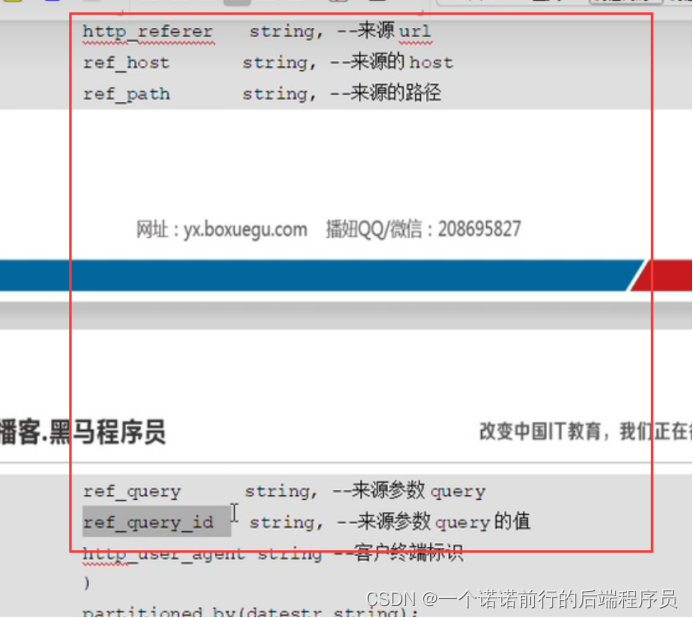
分区字段
表的数据怎么处理
除了创建宽表之外 我们还要创建几个中间临时表
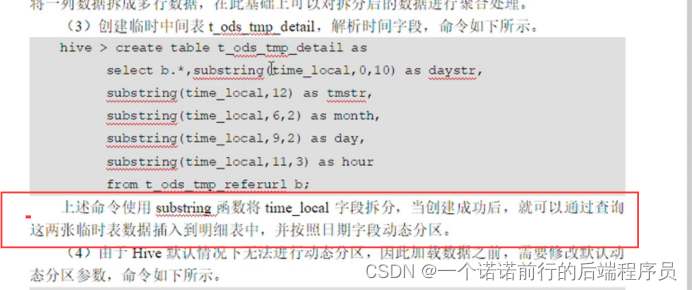
创建临时表
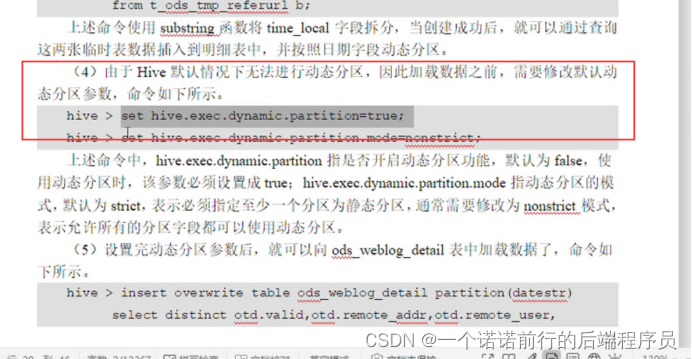
hive的自动分区?????
================================================》》》》》》》》》
向宽表中加数据??????????、怎么做
先拆小的 然后再组合成大宽表
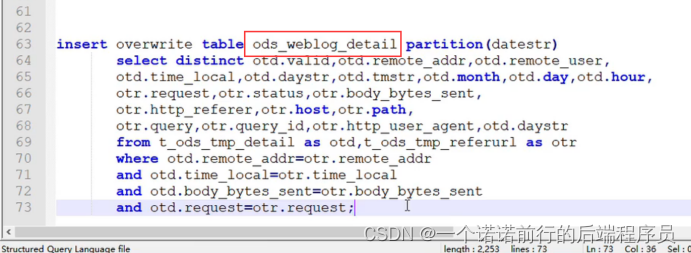
先拆小的 然后再组合成大宽表
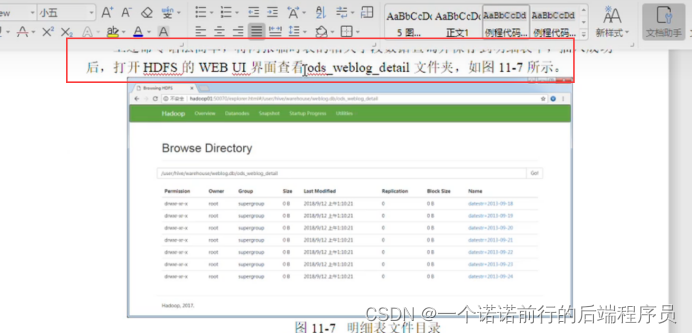
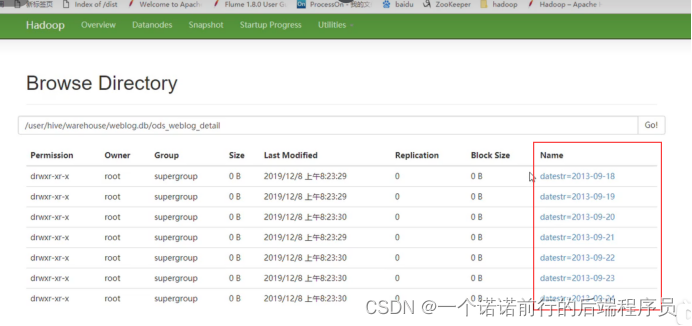
分区 按照时间进行分区
这个时候我们的宽表已经成功被我们加载数据了
如何去实现和加载我们的数仓
2. 我们先看下我们的分析指标
1.流量分析
2.PV

数仓怎么去加工
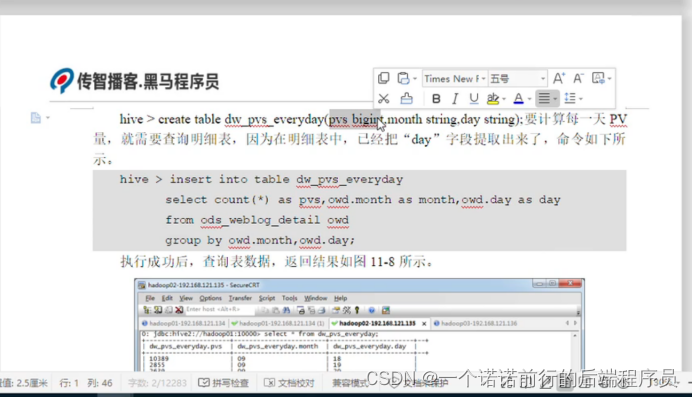
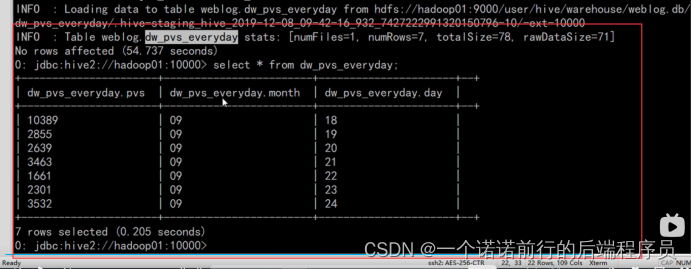
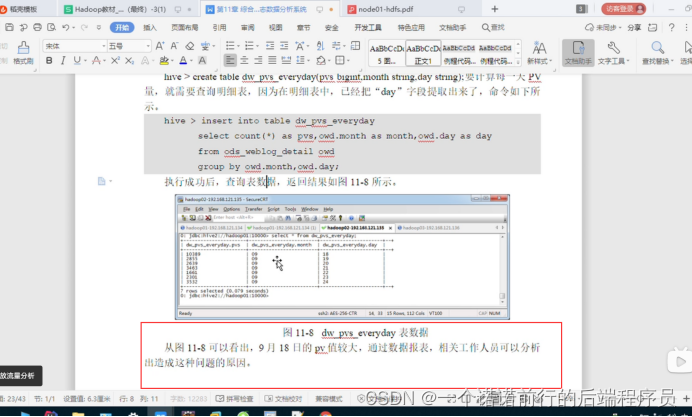
在这个月的这一天的 他的pv量是多少
通过这个表我们就可以描述一天的pv量
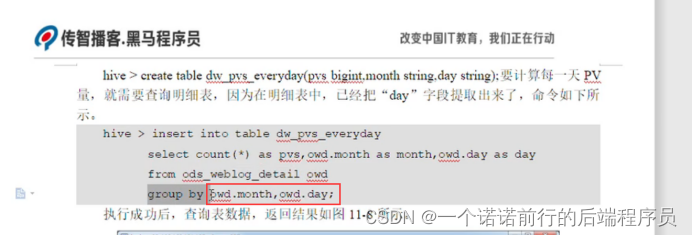
分组 我们需要对sql 很了解
对数据很了解
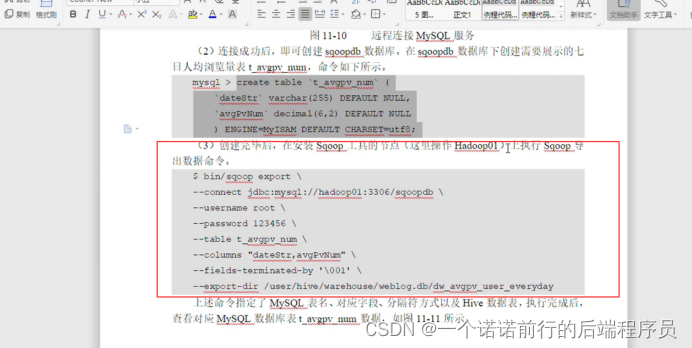
我们创建各种维度表,然后再用sqoop从hdfs导出到我们的mysql的那个表
日志分析系统 报表展示
我们已经完成了我们的项目分析 并且已经吧项目分析的结果导出到我们关系型数据库也就是我们的mysql
接下来我们使用web技术 将我们分析的结果 图形化展示出来
DataV Echars BI应用
大致流程就是这样
nginx----->Flume----->linux------->load到hdfs
----->hive键表
-------->hdfs---->base表中----------》拆分表(中间层表)-------->(大宽表)=======》维度表(计算日均pv)---------->sqoop(mysql)----->quickBi进行展示
nginx------->filebeat----->logstash----->es------->kibana(展示)
我们可以通过logstash来进行过滤 然后通过kibana展示
然后写es的查询条件也可以支持各种业务的查询