文章目录
- 1.读取对应位置的视频帧
- 2.添加时间信息
- 3.对图像进行拼接
- 4.输出拼接图像
- 5.显示效果
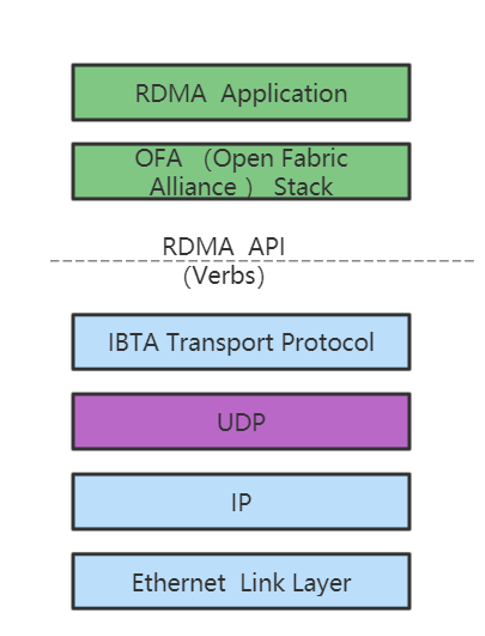
很多时候为了方便预览视频内容,我们会随机的抽取视频当中的一些帧组成一个图片作为视频的缩略图。这里介绍一下如何通过FFmpeg生成视频的缩略图。其实原理很简单,比如我们需要一个6X6的视频缩略图,也就是需要36帧。首先我们将视频按时长分成6X6+1份,这样视频中间就会出现6X6个时间节点,此时我们通过FFmpeg的seek指令跳转到对应的位置取出帧,然后将取出的帧按照顺序组合成一个图片进行输出就可以了。
1.读取对应位置的视频帧
根据视频的时长和选取帧的数量对视频进行分割,对应的实现如下:
//解码数据包
bool DecodeVideoPacket(AVPacket* pPacket, AVCodecContext* pCodecContext, AVFrame* pFrame)
{
int ret = avcodec_send_packet(pCodecContext, pPacket);
if (ret < 0)
{
return false;
}
ret = avcodec_receive_frame(pCodecContext, pFrame);
if (ret != 0)
{
return false;
}
return true;
}
//缩略图的数量
int numFrames = 16;//4*4
//分割成多少份
const int numOfDivision = numFrames + 1;
int stream_count = input_format_ctx->nb_streams;
//视频的时长
int64_t timeStampLength = input_format_ctx->duration;
//每一段的时间间隔
int64_t timeStampStepSize = (double)timeStampLength / (double)numOfDivision;
//起始位置
int64_t timeStampIter = timeStampStepSize;
//跳转到对应帧的位置(注意时间单位的转换)
av_seek_frame(input_format_ctx, videoStreamIndex, (timeStampIter / 1000000) / av_q2d(pVideoStream->time_base), AVSEEK_FLAG_BACKWARD);
bool bDecodeResult = false;
int frameCounter = numFrames;
//读取数据帧
while (av_read_frame(input_format_ctx, pPacket) >= 0)
{
static int64_t last_pts = -1;
if (pPacket->stream_index == videoStreamIndex)
{
bDecodeResult = DecodeVideoPacket(pPacket, pCodecContext, pFrame);
if (bDecodeResult)
{
pFrame->pts = pFrame->best_effort_timestamp;
//给每一帧添加时间水印
av_buffersrc_add_frame_flags(buffersrc_ctx, pFrame, AV_BUFFERSRC_FLAG_KEEP_REF);
//获取滤镜输出
int ret = av_buffersink_get_frame(buffersink_ctx, pFilterFrame);
//添加到缩略图中
maker.addSubFrame(pFilterFrame,10,10);
//编码之后输出
av_frame_unref(pFilterFrame);
if (--frameCounter <= 0) break;
}
//跳转到下一帧
timeStampIter += timeStampStepSize;
av_seek_frame(input_format_ctx, videoStreamIndex, (timeStampIter / 1000000) / av_q2d(pVideoStream->time_base), AVSEEK_FLAG_BACKWARD);
}
av_packet_unref(pPacket);
av_frame_unref(pFrame);
}
2.添加时间信息
为了对应每一帧的时间信息,我们给每一帧图片打上时间水印方便区别。对应的实现如下所示:
//初始化滤镜
int InitFilter(AVCodecContext* codecContext,AVRational time_base)
{
char args[512];
int ret = 0;
AVRational timebase = time_base;
AVRational pixel_aspect{ 1, 1 };
//缓存输入和缓存输出
const AVFilter *buffersrc = avfilter_get_by_name("buffer");
const AVFilter *buffersink = avfilter_get_by_name("buffersink");
//创建输入输出参数
AVFilterInOut *outputs = avfilter_inout_alloc();
AVFilterInOut *inputs = avfilter_inout_alloc();
//在固定的位置(100,100)绘制当前帧对应的时间
//绘制的字体颜色为白色
std::string filters_descr = "drawtext=fontfile=.//msyh.ttc:fontsize=100:text='%{pts\\:gmtime\\:0\\:%H\\\\\\:%M\\\\\\:%S}':x=100:y=100:fontcolor=0xFFFFFF";
enum AVPixelFormat pix_fmts[] = { AV_PIX_FMT_YUV420P, AV_PIX_FMT_YUV420P };
//创建滤镜容器
filter_graph = avfilter_graph_alloc();
if (!outputs || !inputs || !filter_graph)
{
ret = AVERROR(ENOMEM);
goto end;
}
//初始化数据帧的格式
sprintf_s(args, sizeof(args),
"video_size=%dx%d:pix_fmt=%d:time_base=%d/%d:pixel_aspect=%d/%d",
input_format_ctx->streams[0]->codecpar->width, codecContext->height, codecContext->pix_fmt,
timebase.num, timebase.den,
pixel_aspect.den, pixel_aspect.den);
//输入数据缓存
ret = avfilter_graph_create_filter(&buffersrc_ctx, buffersrc, "in",
args, NULL, filter_graph);
if (ret < 0) {
goto end;
}
//输出数据缓存
ret = avfilter_graph_create_filter(&buffersink_ctx, buffersink, "out",
NULL, NULL, filter_graph);
if (ret < 0)
{
av_log(NULL, AV_LOG_ERROR, "Cannot create buffer sink\n");
goto end;
}
//设置元素样式
ret = av_opt_set_int_list(buffersink_ctx, "pix_fmts", pix_fmts,
AV_PIX_FMT_YUV420P, AV_OPT_SEARCH_CHILDREN);
if (ret < 0)
{
av_log(NULL, AV_LOG_ERROR, "Cannot set output pixel format\n");
goto end;
}
//设置滤镜的端点
outputs->name = av_strdup("in");
outputs->filter_ctx = buffersrc_ctx;
outputs->pad_idx = 0;
outputs->next = NULL;
inputs->name = av_strdup("out");
inputs->filter_ctx = buffersink_ctx;
inputs->pad_idx = 0;
inputs->next = NULL;
//初始化滤镜
if ((ret = avfilter_graph_parse_ptr(filter_graph, filters_descr.c_str(),
&inputs, &outputs, NULL)) < 0)
goto end;
//滤镜生效
if ((ret = avfilter_graph_config(filter_graph, NULL)) < 0)
goto end;
end:
//释放对应的输入输出
avfilter_inout_free(&inputs);
avfilter_inout_free(&outputs);
return ret;
}
3.对图像进行拼接
根据需要抽取的视频帧的数量,我们创建主图和子图对应的内存空间:
//设置每个子图宽和高
bool AllocSubFrameBuffer(const int width, const int height)
{
if (m_sub_frame != nullptr)
{
return false;
}
int dstW = width;
int dstH = height;
//根据视频宽高来创建内存帧
AVPixelFormat dstFormat = AVPixelFormat::AV_PIX_FMT_YUV420P;
//需要指定内存对齐的大小
int dstAlignment = 32;
AVFrame* dstFrame = av_frame_alloc();
if (dstFrame == nullptr)
{
return false;
}
int ret = av_image_alloc(dstFrame->data, dstFrame->linesize, dstW, dstH, dstFormat, dstAlignment);
if (ret < 0)
{
return false;
}
dstFrame->width = dstW;
dstFrame->height = dstH;
dstFrame->format = dstFormat;
m_sub_frame = dstFrame;
}
//设置主图的宽和高
bool AllocCompFrameBuffer(const int width, const int height)
{
if (m_combine_frame != nullptr)
return false;
//创建主图的大小
int compW = width;
int compH = height;
AVPixelFormat compFormat = AVPixelFormat::AV_PIX_FMT_YUV420P;
int compAlignment = 32;
AVFrame* compFrame = av_frame_alloc();
av_image_alloc(compFrame->data, compFrame->linesize, compW, compH, compFormat, compAlignment);
compFrame->width = compW;
compFrame->height = compH;
compFrame->format = compFormat;
memset(compFrame->data[0], 0x00, compFrame->linesize[0] * compH); // Y
memset(compFrame->data[1], 0x80, compFrame->linesize[1] * compH / 2); // U
memset(compFrame->data[2], 0x80, compFrame->linesize[2] * compH / 2); // V
m_combine_frame = compFrame;
}
由于从视频中获取到的视频帧和子图的大小不一致,我们需要对视频帧进行缩放:
//将传入的帧进行尺寸变换
void MapFrametoSubFrame(AVFrame* source, AVFrame* dest)
{
int srcW = source->width;
int srcH = source->height;
AVPixelFormat srcFormat = (AVPixelFormat)source->format;
int dstW = dest->width;
int dstH = dest->height;
AVPixelFormat dstFormat = (AVPixelFormat)dest->format;
// sws filter operations.
SwsContext* swsContext = sws_getContext(srcW, srcH, srcFormat, dstW, dstH, dstFormat, SWS_BICUBLIN, NULL, NULL, NULL);
sws_scale(swsContext, source->data, source->linesize, 0, source->height, dest->data, dest->linesize);
sws_freeContext(swsContext);
}
将缩放的视频帧组合到主图里面,这时候需要考虑到内存对齐和YUV视频帧的内存数据结构,对应的实现如下:
//将输入帧按顺序组合成合成帧
//@1输入子帧
//@2组合帧
//@3子帧在组合帧中行索引
//@4子帧在组合帧中的列索引
//@5总行数 @6总列数
void MapSubFrameToCombFrame(AVFrame* source, AVFrame* dest, int rowIndex, int colIndex, int numOfRows, int numOfCols)
{
//假设输入输出都是YUV420P格式的数据
//考虑内存对齐
uint8_t* sourceY = source->data[0];
uint8_t* sourceU = source->data[1];
uint8_t* sourceV = source->data[2];
uint8_t* destY = dest->data[0];
uint8_t* destU = dest->data[1];
uint8_t* destV = dest->data[2];
//YUV数据中 YYYY + U + V
//每一行中的水平方向偏移
int offsetHorizontal = (dest->width / numOfCols) * colIndex;
//从哪一行开始计算
//dest->linesize[0]是经过内存对齐的每行的宽度
int offsetVertical = ((dest->linesize[0] * dest->height) * rowIndex) / numOfRows;
for (int i = 0; i < source->height; ++i)
{
memcpy(destY + i * dest->linesize[0] + offsetHorizontal + offsetVertical, sourceY + i * source->linesize[0], source->width);
}
//UV
offsetHorizontal = (dest->width / 2 * colIndex) / numOfCols;
offsetVertical = ((dest->linesize[1] * (dest->height / 2)) * rowIndex) / numOfRows;
for (int i = 0; i < source->height / 2; ++i) {
memcpy(destU + i * dest->linesize[1] + offsetHorizontal + offsetVertical, sourceU + i * source->linesize[1], source->width / 2);
memcpy(destV + i * dest->linesize[2] + offsetHorizontal + offsetVertical, sourceV + i * source->linesize[2], source->width / 2);
}
}
实现了对应的功能模块之后,我们就可以把视频帧抽取出来组合成一个完整的图像了。
4.输出拼接图像
视频帧抽取组合完毕之后,将拼接的图像输出成一个图片,这里输出成jpg格式的图片,对应的实现如下:
//输出组合之后的图像
bool output_thumbnail_image(std::string output_path, AVFrame* frame)
{
//创建输出上下文
AVOutputFormat* outputFormat = av_guess_format("mjpeg", NULL, NULL);
if (outputFormat == nullptr)
{
return false;
}
AVCodecParameters* parameters = avcodec_parameters_alloc();
parameters->codec_id = outputFormat->video_codec;
parameters->codec_type = AVMEDIA_TYPE_VIDEO;
parameters->format = AV_PIX_FMT_YUVJ420P; //JPEG TYPE!
parameters->width = frame->width;
parameters->height = frame->height;
AVCodec* codec = avcodec_find_encoder(parameters->codec_id);
if (!codec)
{
return false;
}
AVCodecContext* codecContext = avcodec_alloc_context3(codec);
if (!codecContext)
{
return false;
}
int ret = avcodec_parameters_to_context(codecContext, parameters);
if (ret < 0) {
return false;
}
codecContext->time_base = AVRational{ 1, 25 };
codecContext->flags |= AV_CODEC_FLAG_QSCALE;
codecContext->global_quality = FF_QP2LAMBDA * 9;
ret = avcodec_open2(codecContext, codec, NULL);
if (ret < 0)
{
return false;
}
ret = avcodec_send_frame(codecContext, frame);
if (ret < 0)
{
return false;
}
AVPacket* pPacket = av_packet_alloc();
if (!pPacket)
{
return false;
}
ret = avcodec_receive_packet(codecContext, pPacket);
if (ret < 0)
{
return false;
}
AVFormatContext* pFormatContext = avformat_alloc_context();
pFormatContext->oformat = outputFormat;
ret = avio_open(&pFormatContext->pb, output_path.c_str(), AVIO_FLAG_READ_WRITE);
if (ret < 0)
{
return false;
}
AVStream* pStream = avformat_new_stream(pFormatContext, NULL);
*(pStream->codecpar) = *parameters;
if (pStream == nullptr)
{
return false;
}
ret = avformat_write_header(pFormatContext, nullptr);
if (ret < 0)
{
return false;
}
//写图片数据
ret = av_write_frame(pFormatContext, pPacket);
if (ret < 0)
{
return false;
}
//写文件尾
av_write_trailer(pFormatContext);
//释放资源
avcodec_close(codecContext);
avio_close(pFormatContext->pb);
av_packet_unref(pPacket);
avcodec_parameters_free(¶meters);
avcodec_free_context(&codecContext);
avformat_free_context(pFormatContext);
}
5.显示效果
这里以一个视频为例,分别输出了2X2,3X3,4X4的缩略图,对应的显示效果如下:
2X2缩略图

3X3缩略图

4X4缩略图