写在前面
NSTransformer模型来自NIPS 2022的一篇paper《Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting》。NSTransformer的目的主要是为了解决其他方法出现过平稳化处理的问题。其通过提出序列平稳化以及去平稳化注意力机制可以使得模型面向提升预测性能的角度进行平稳化处理,相比于Transformer的变体,NSTransformer在预测性能方面实现了大幅度的提升。下面的这篇文章主要带大家了解一下NSTransformer的基本原理,并使用作者开源的NSTransformer代码,并将其用于股票价格预测当中。
1
NSTransformer模型
由于Transformer的全局范围的建模能力,使其在时间序列预测中显示出巨大的力量。然而,在联合分布随时间变化的非稳态真实世界数据上,它们的性能可能会退化得很可怕。以前的研究主要采用平稳化技术来削弱原始序列的非平稳特性,以提高预测能力。但是,被剥夺了内在非平稳性的平稳序列对于现实世界中的突发事件预测的指导意义不大。这个问题,在本文中被称为过平稳化(over-stationarization),导致Transformer对不同序列产生无差别的时序关注,阻碍了深度模型的预测能力。为了解决序列的可预测性和模型能力之间的困境,作者提出了Non-stationary Transformer (NSTransformer)作为一个通用框架,其中有两个相互依赖的模块。序列平稳化(Series Stationarization)和去平稳化注意力(De-stationary Attention)。具体来说,序列平稳化模块统一了每个输入的统计特性,并将输出转换为恢复的统计特性,以提高可预测性。为了解决过平稳化问题,去平稳化注意力被设计出来,通过近似于从原始序列中学到的可区分的注意,将内在的非平稳信息恢复为时间依赖。作者提出的NSTransformer框架在很大程度上提升了主流Transformer模型的变体的预测性能,相比于Transformer,MSE降低了49.43%,相比于Informer,降低了47.34%,相比于Reformer,降低了46.89%。
模型框架
NSTransformer遵循先前在时间序列预测中使用的Transformer架构,采用标准的编码器-解码器结构,其中编码器从过去的数据中提取信息,而解码器则通过对过去的历史信息进行过汇总来实施预测。典型的NSTransformer是通过对Transformer的输入和输出进行序列平稳化处理,并用提出的非平稳注意机制取代self-attention,这可以提高基础模型的非平稳序列的预测能力。总之,NSTransformer主要包括下面两个模块:序列平稳化模块以及去平稳注意力模块。
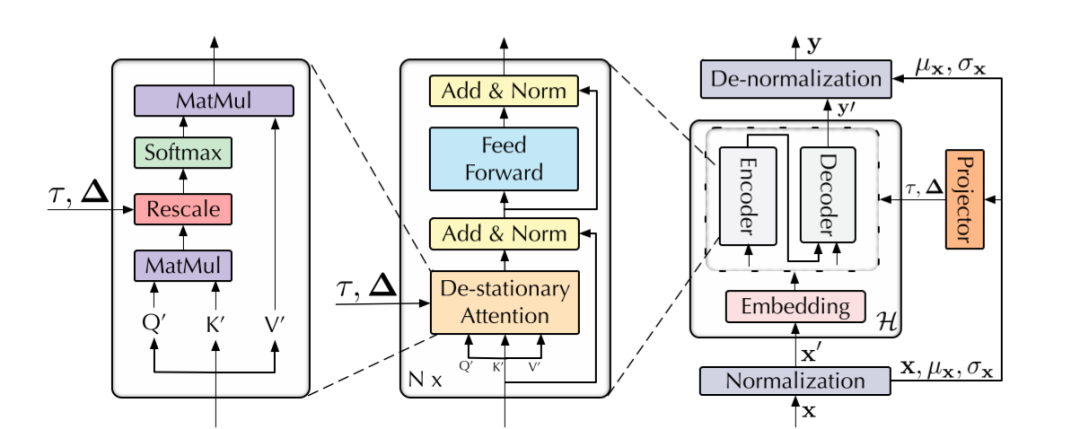
NSTransformer的基本框架
序列平稳化
序列平稳化主要模块两个模块,一个是归一化(Normalization)模块,另一个是反归一化(De-Normalization)模块。首先,归一化模块通过一个滑动窗口的形式对每一维时间序列数据进行归一化处理,这样窗口化的方式可以将每一个相邻窗口内的数据都具有相同的均值跟方差,以消除序列之间尺度上的差异性,并增加输入数据在时序上的分布稳定性。归一化的过程是:
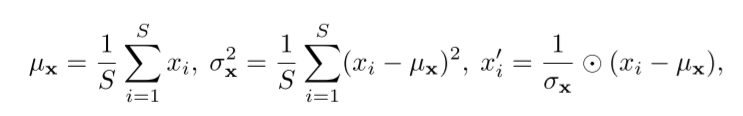
在模型预测结束之后,反归一化模块利用归一化时记录的均值跟方差信息,用来将模型的输出映射回原来的尺度,以恢复归一化时损失的信息。反归一化的过程是:
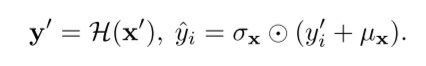
通过这两个阶段的变换,模型将接收到平稳的输入,这些输入遵循稳定的分布,更容易泛化。这样的设计还使模型对时间序列具有平移不变性和尺度不变性,从而有利于真实序列的预测。
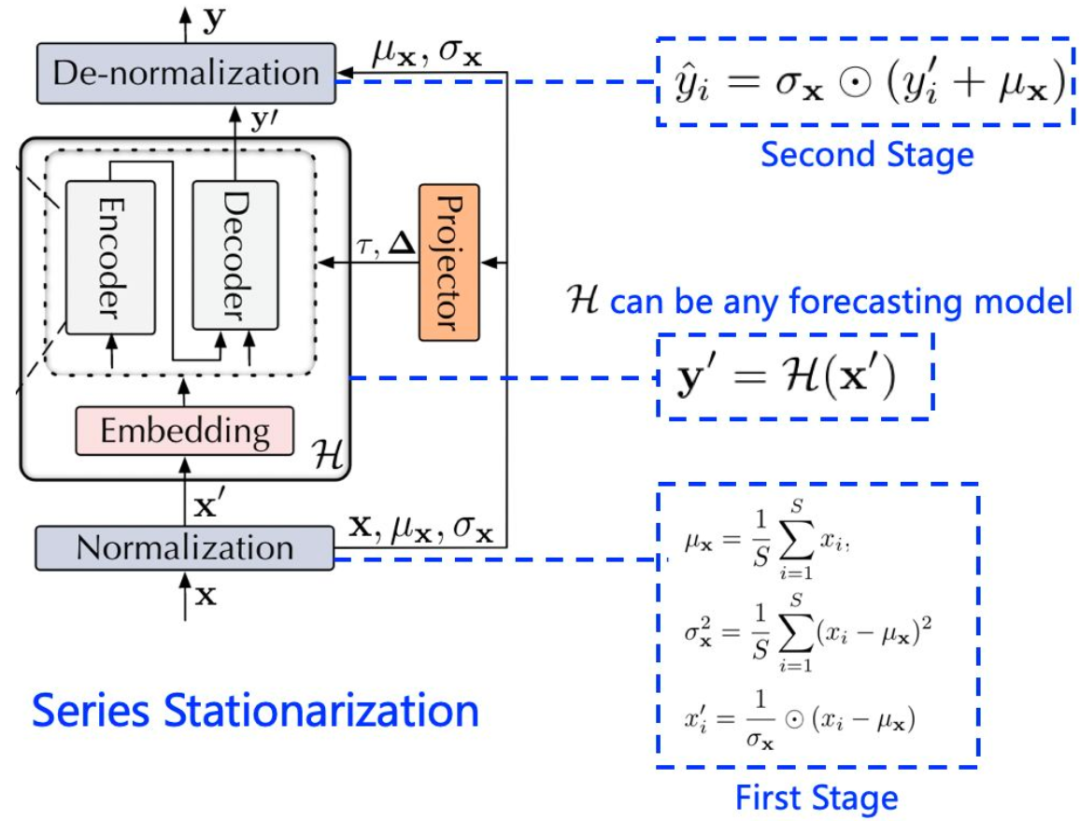
序列平稳化过程(图片来自:https://zhuanlan.zhihu.com/p/587665491)
去平稳化注意力
去平稳化注意力机制去平稳化注意力机制的过程如下图所示:
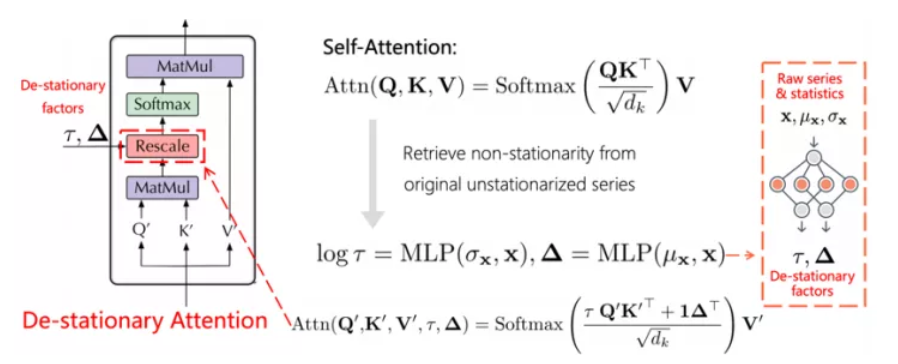
去平稳化注意力机制(图片来自:https://zhuanlan.zhihu.com/p/587665491)
如前面所提到的,过平稳化问题是由内在的非平稳信息的消失引起的,这将使模型无法捕捉到用于预测的事件性时间依赖。因此,作者试图近似从原始的非平稳序列中去学习注意力。下面是Transformer计算注意力的原始公式:
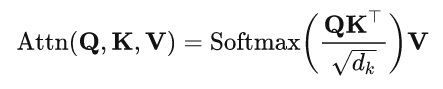
对于输入时间序列x,计算它的均值跟方差得到:
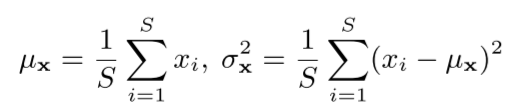
除此之外,为了简化分析这里假设了用于嵌入的前馈层在时间维度是线性的,基于线性假设可以推导出 , 与对平稳化后时间序列计算得到的 跟 的关系是:
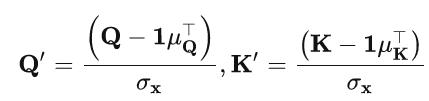
其中, 与 是 跟 在时间维度的均值。这样从原始时间序列中计算注意力机制的公式,可以被从平稳化后的时间序列中计算的 跟 替代为下面的公式,具体的推导可以参考原文的附录。
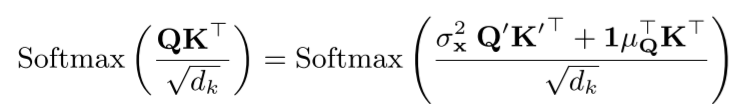
这样得到的注意力公式不仅包含了原始时间序列的信息,也包含了经过平稳化后的序列信息。之后为了恢复对非平稳序列的原始注意力,这里作者将消失的非平稳信息重新引入到非平稳序列的计算中。为了得到所需要的计算值,作者引入了去平稳因子 跟 ,它们都是通过两个多层感知器从非平稳时间序列中计算得到的。进而,去平稳化注意力的计算方式可以得到如下形式:
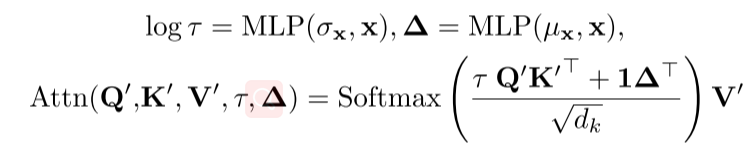
这样,它既能利用平稳序列的可预测性,又能保持原始序列固有的时间依赖性。
2
环境配置
本地环境:
Python 3.7
IDE:Pycharm库版本:
numpy 1.18.1
pandas 1.0.3
sklearn 0.22.2
matplotlib 3.2.1
torch 1.10.1NSTransformer源码Github链接:
https://github.com/thuml/Nonstationary_Transformers
3
代码实现
NSTransformer的官方代码实现借鉴了Informer的代码,因此,与之前的推文【python量化】将Informer用于股价预测类似,首先将NSTransformer的源码下载到本地,然后将我们的数据集放到某个路径下,这里仍然用到了上证指数14到17年四年的开高低收成交量数据。在将NSTransformer的代码用于我们的股票数据预测任务时,同样需要明确的是,我们的任务是基于高低收成交量来预测收盘价,这是一个多变量输入,单变量输出的预测任务。所以主要需要修改下面几个参数的设置。当需要进行不同预测任务时,如增加某些特征,预测多个目标变量等则可通过修改features,target,enc_in,dec_in以及c_out参数进行实现。NSTransformer的主要参数与Informer类似,主要包括:
model: ns_transformer,可以选择其他模型包括Informer,Transformer以及Autoformer。
data: 设置为custom,用于调用Dataset_Custom类,从而可以自定义数据集。
root_path:指定数据集存放的文件夹。
data_path:指定csv数据集的名称。
features:设置为MS,这是因为我们是用开高低收成交量来预测收盘价,所以是多变量输出来预测单变量。
target:表示预测变量,设置为Close,对应我们csv文件预测变量的列名。
freq:表示预测频率,设置为d,因为我们用到的是日线级别的数据。
seq_len:表示输入encoder的序列长度,这里设置为20。
label_len:表示输入decoder中的token的长度,这里设置为10,即通过前10个真实值来辅助decoder进行预测。
pred_len:表示预测序列的长度,这里设置为5,即表示预测后5个时刻的序列值。
enc_in:表示encoder的输入维度,这里设置为5,因为我们用到了开高低收以及成交量5个特征。
dec_in:表示decoder的输入维度,同enc_in。
c_out:表示输出序列的维度,这里设置为1,因为我们的目标变量只有收盘价。
moving_avg: 移动平均的窗口大小。
p_hidden_dims:去平稳性映射器的隐层维度。
p_hidden_layers:映射器的层数。其他参数像模型层数,维度之类的可以根据自己的电脑配置进行修改。下面是进行上证指数预测实验的参数配置:
args.is_training = 1
args.model_id = 'test'
args.model='ns_Transformer' # model name, options: [ns_Transformer, Transformer]
# data loader
args.data = 'custom' # dataset type
args.root_path ='./data/stock/' # root path of the data file
args.data_path ='SH000001.csv' # data file
args.features='MS' # forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate'
args.target='Close' # 'target feature in S or MS task'
args.freq = 'd' # freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h'
args.checkpoints ='./checkpoints/' # 'location of model checkpoints'
# forecasting task
args.seq_len = 20 # input sequence length
args.label_len = 10 # start token length
args.pred_len = 5 # prediction sequence lengthargs.
# model define
args.enc_in = 5 # encoder input size
args.dec_in = 5 # decoder input size
args.c_out = 1 # output size
args.d_model = 256 # dimension of model
args.n_heads = 4 # num of heads
args.e_layers = 2 # num of encoder layers
args.d_layers = 1 # num of decoder layers
args.d_ff = 256 # dimension of fcn
args.moving_avg = 5 # window size of moving average
args.factor = 1 # attn factor
args.distil= True # whether to use distilling in encoder, using this argument means not using distilling
args.dropout = 0.05 # dropout
args.embed = 'timeF' # time features encoding, options:[timeF, fixed, learned]
args.activation = 'gelu' # 'activation'
args.output_attention = True # help='whether to output attention in encoder
args.do_predict = True # whether to predict unseen future data
# optimization
args.num_workers = 0 # data loader num workers
args.itr = 1 # experiments times
args.train_epochs = 20 # train epochs
args.batch_size = 32 # batch size of train input data
args.patience = 3 # early stopping patience
args.learning_rate = 0.0001 # optimizer learning rate
args.des = 'test' # exp description
args.loss = 'mse' # loss function
args.lradj = 'type1' # adjust learning rate
args.use_amp = False # use automatic mixed precision training
# GPU
args.use_gpu = False # use gpu
args.gpu = 0 # gpu
args.use_multi_gpu = False
args.devices = '0,1,2,3' # device ids of multile gpus
args.seed = 2021 # random seed
# de-stationary projector params
args.p_hidden_dims = [128, 128] # hidden layer dimensions of projector (List)
args.p_hidden_layers = 2 # number of hidden layers in projector按照设置的参数,然后对模型进行训练跟测试:
Exp = Exp_Main
if args.is_training:
for ii in range(args.itr):
# setting record of experiments
setting = '{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_fc{}_eb{}_dt{}_{}_{}'.format(
args.model_id,
args.model,
args.data,
args.features,
args.seq_len,
args.label_len,
args.pred_len,
args.d_model,
args.n_heads,
args.e_layers,
args.d_layers,
args.d_ff,
args.factor,
args.embed,
args.distil,
args.des, ii)
exp = Exp(args) # set experiments
print('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))
exp.train(setting)
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting)
if args.do_predict:
print('>>>>>>>predicting : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.predict(setting, True)
torch.cuda.empty_cache()
else:
ii = 0
setting = '{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_fc{}_eb{}_dt{}_{}_{}'.format(
args.model_id,
args.model,
args.data,
args.features,
args.seq_len,
args.label_len,
args.pred_len,
args.d_model,
args.n_heads,
args.e_layers,
args.d_layers,
args.d_ff,
args.factor,
args.embed,
args.distil,
args.des, ii)
exp = Exp(args) # set experiments
print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))
exp.test(setting, test=1)
torch.cuda.empty_cache()下面是在CPU上的训练过程。经过训练,可以看出模型的训练集上的loss不断下降,由于加入了early stop机制,所以经过6个epoch模型就停止训练了。经过在测试集上的测试,NSTransformer实现了0.0027的mse跟0.0415的mae(归一化后的结果)。需要注意的是,模型经过训练跟测试之后,会在当前路径的./checkpoints中保存模型参数,在./results/{settings}/下生成pred.npy以及true.npy文件用来分别存放测试集上的预测结果跟ground truth。
Use CPU
>>>>>>>start training : test_ns_Transformer_custom_ftMS_sl20_ll10_pl5_dm256_nh4_el2_dl1_df256_fc1_ebtimeF_dtTrue_test_0>>>>>>>>>>>>>>>>>>>>>>>>>>
train 659
val 95
test 191
Epoch: 1 cost time: 1.7922062873840332
Epoch: 1, Steps: 20 | Train Loss: 0.0605105 Vali Loss: 0.0028209 Test Loss: 0.0028931
Validation loss decreased (inf --> 0.002821). Saving model ...
Updating learning rate to 0.0001
Epoch: 2 cost time: 1.569800615310669
Epoch: 2, Steps: 20 | Train Loss: 0.0374645 Vali Loss: 0.0030634 Test Loss: 0.0028165
EarlyStopping counter: 1 out of 3
Updating learning rate to 5e-05
Epoch: 3 cost time: 1.5588312149047852
Epoch: 3, Steps: 20 | Train Loss: 0.0328267 Vali Loss: 0.0024335 Test Loss: 0.0027673
Validation loss decreased (0.002821 --> 0.002434). Saving model ...
Updating learning rate to 2.5e-05
Epoch: 4 cost time: 1.5059726238250732
Epoch: 4, Steps: 20 | Train Loss: 0.0296629 Vali Loss: 0.0031771 Test Loss: 0.0028892
EarlyStopping counter: 1 out of 3
Updating learning rate to 1.25e-05
Epoch: 5 cost time: 1.6665441989898682
Epoch: 5, Steps: 20 | Train Loss: 0.0289504 Vali Loss: 0.0029475 Test Loss: 0.0027112
EarlyStopping counter: 2 out of 3
Updating learning rate to 6.25e-06
Epoch: 6 cost time: 1.5528459548950195
Epoch: 6, Steps: 20 | Train Loss: 0.0285680 Vali Loss: 0.0029404 Test Loss: 0.0027616
EarlyStopping counter: 3 out of 3
Early stopping
>>>>>>>testing : test_ns_Transformer_custom_ftMS_sl20_ll10_pl5_dm256_nh4_el2_dl1_df256_fc1_ebtimeF_dtTrue_test_0<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
test 191
test shape: (5, 32, 5, 1) (5, 32, 5, 1)
test shape: (160, 5, 1) (160, 5, 1)
mse:0.0027673370204865932, mae:0.04154161363840103调用模型的predict()方法可以直接预测所有数据后面的未知数据,因为这里预测长度为5,所以直接调用就相当于预测后5天的收盘价走势了。预测的结果会保存在./results/{settings}/下面的real_prediction.npy文件中。
exp = Exp(args)
exp.predict(setting, True)
# the prediction will be saved in ./results/{setting}/real_prediction.npy
prediction = np.load('./results/'+setting+'/real_prediction.npy')
plt.figure()
plt.plot(prediction[0,:,-1])
plt.show()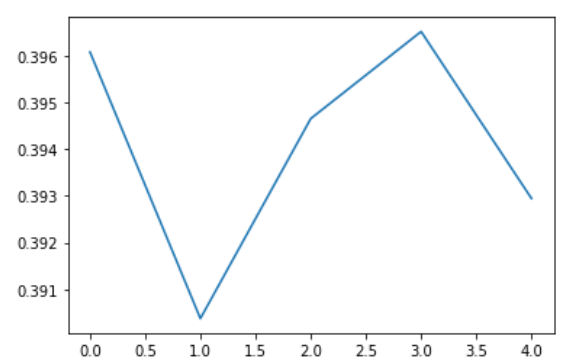
最后将完整的测试集上的预测结果进行可视化。
plt.figure()
plt.plot(trues[:,0,-1].reshape(-1), label='GroundTruth')
plt.plot(preds[:,0,-1].reshape(-1), label='Prediction')
plt.legend()
plt.show()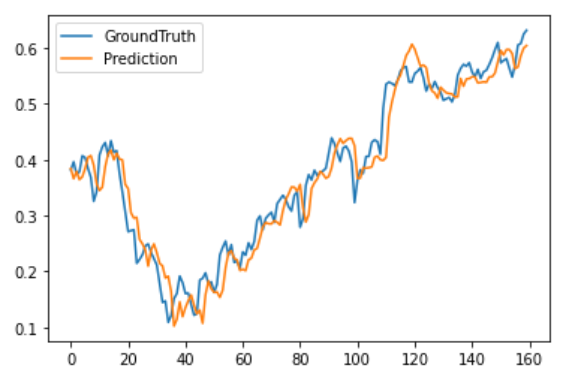
除此之外,NSTransformer的源码中也提供了Transformer、Informer以及Autoformer的实现。为了直观展示这几种模型之间的预测表现,我们采用相同的超参数对另外几种模型进行实验,并将其可视化的结果进行展示。需要注意是这里为了方便实验,每种模型的超参没有进行寻优而是统一采用了NSTransformer模型的实验配置。
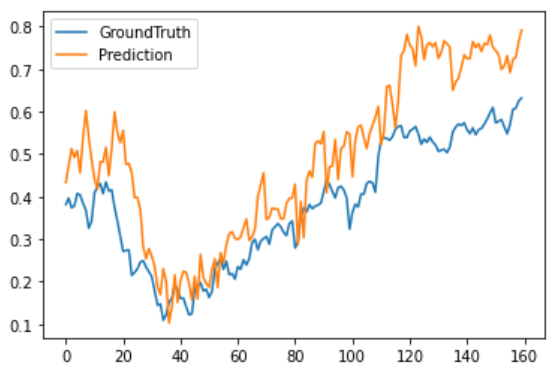
Transformer
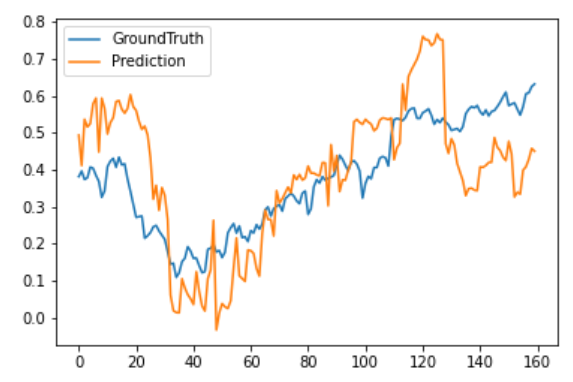
Informer
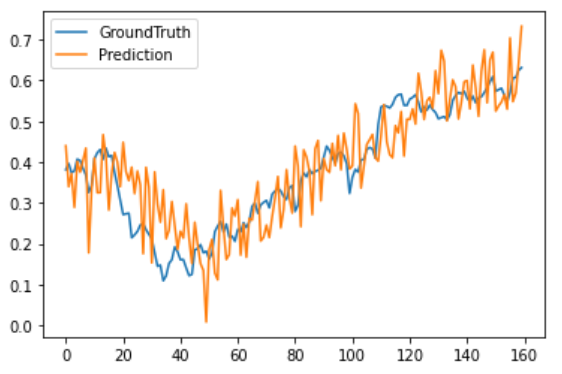
Autoformer
从可视化结果中可以看出相比于其他Transformer模型,NSTransformer实现了最好的拟合效果。最后统计这几种模型的MSE跟MAE(未反归一化),从误差上也可以看出NSTransformer实现了最低的预测误差,其次是Autoformer,Informer以及Transformer。
NSTransformer:
mse:0.0027673370204865932, mae:0.04154161363840103
Transformer:
mse:0.0147677231580019, mae:0.10331685841083527
Informer:
mse:0.01395915262401104, mae:0.09441611915826797
Autoformer:
mse:0.008317378349602222, mae:0.072861030697822574
总结
时间序列的非平稳性是现实时间序列数据中存在的重要特性,尤其是对金融时间序列来说。而现有大多数方法都会对数据做平稳化处理来提升预测性能,然而,平稳化处理的过程也会导致一部分信息的丢失。而NSTransformer通过设计的序列平稳化以及去平稳化注意力机制,使得它既能利用平稳序列的可预测性,又能保持原始序列固有的时间依赖性。文中通过将NSTransformer与其他模型包括Transformer,Informer以及Autoformer的实验对比,进一步证实了NSTransformer的预测性能。因此,在面对非平稳,高噪声的股票数据预测中,NSTransformer或许可以取得较好的预测表现。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
参考文献:
Liu, Y., Wu, H., Wang, J., & Long, M. (2022). Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting. In Advances in Neural Information Processing Systems.
NeurIPS2022 | NSTransformers: 非平稳时间序列的通用预测框架 - 游凯超的文章 - 知乎 https://zhuanlan.zhihu.com/p/587665491
获取完整代码与数据以及其他历史文章完整源码与数据可加入《人工智能量化实验室》知识星球。

《人工智能量化实验室》知识星球

加入人工智能量化实验室知识星球,您可以获得:(1)定期推送最新人工智能量化应用相关的研究成果,包括高水平期刊论文以及券商优质金融工程研究报告,便于您随时随地了解最新前沿知识;(2)公众号历史文章Python项目完整源码;(3)优质Python、机器学习、量化交易相关电子书PDF;(4)优质量化交易资料、项目代码分享;(5)跟星友一起交流,结交志同道合朋友。(6)向博主发起提问,答疑解惑。





![【项目设计】高并发内存池(二)[高并发内存池整体框架设计|threadcache]](https://img-blog.csdnimg.cn/89359aa7f9be400e841b2173d0170e1a.png)