文章目录
- 一、论文前言
- 二、提出原因
- 三、论文的核心
- 四、论文讲解
- 4.1 论文流程
- 4.2 OVD与之前相关的setting
- 4.3 结果对比
一、论文前言
目标检测是人工智能最突出的应用之一,也是深度学习最成功的任务之一。
然而,尽管深度对象检测取得了巨大进步,例如 Faster R-CNN ,已经能取得非常不错的准确性,但训练此类模型需要昂贵且耗时的监督信号,他们都要靠人工标注获得。 特别是,需要为每个ROI的对象类别手动标注至少数千个边界框。 尽管之前很多机构已经完成了object detection上benchmark的建立,并且公开了这些有价值的数据集,例如 Open Images和 MSCOCO,这些数据集描述了一些有限的对象类别。但如果我们想吧将目标检测从 600 个类别扩展到 60000 个类别,那么我们需要 100 倍数据资源的标注,这使得把目标检测拓展到开放世界里变得遥不可及。
然而,人类通过自然监督学会毫不费力地识别和定位物体,即探索视觉世界和倾听他人描述情况。我们人类具有终生学习的能力,我们捕捉到视觉信息后,会将它们与口语联系起来,从而产生了丰富的视觉和语义词汇,这些词汇不仅可以用于检测物体,而且可以用来拓展模型的表达能力。 尽管在对象周围绘制边界框不是人类自然学习的任务,但他们可以使用少量例子快速学习它,并将其很好地泛化到所有类型的对象,而不需要每个对象类的示例。这就是open vocabulary object detection这一问题的motivation所在。
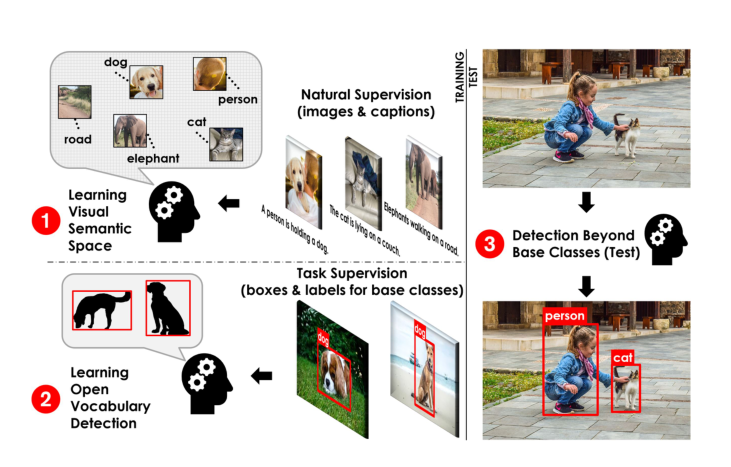
二、提出原因
人类通过自然监督,即探索视觉世界和倾听他人描述情况,学会了毫不费力地识别和定位物体。
我们人类对视觉模式的终身学习,并将其与口语词汇联系起来,从而形成了丰富的视觉和语义词汇,不仅可以用于检测物体,还可以用于其他任务,如描述物体和推理其属性和可见性。
人类的这种学习模式为我们实现开放世界的目标检测提供了一个可以学习的角度。
open-vocabulary object detection的初衷就是利用大规模的image-caption数据来改善对未知类的检测能力。基于此,OVR-CNN是该领域的第一篇工作。
三、论文的核心
Open-Vocabulary Object Detection (OVD)可以翻译为面向开放词汇下的目标检测,该任务和zero-shot object detection非常类似,核心思想都是在可见类(base class)的数据上进行训练,然后完成对不可见类(unseen/ target)数据的识别和检测,除了核心思想类似外,很多论文其实对二者也没有进行很好的区分。
然而,在本文中,并不涉及对与zero-shot、OVD、以及semi-supervised目标检测之间的区别,主要是对现阶段OVD发展的工作进行串讲和总结。
该工作的核心主要是利用image-caption数据来对视觉编码器进行pre-training。
由于caption中存在着丰富的对于图像区域等细粒度特征的描述单词和短语,能够覆盖更多的物体类别,因此经过大规模image-caption的预训练,Vision encoder便能够学习到更加泛化的视觉-语义对应空间。
因此训练好的vision encoder便可以用于替换faster-rcnn中encoder,提告检测模型的zero-shot检测能力。
四、论文讲解
4.1 论文流程
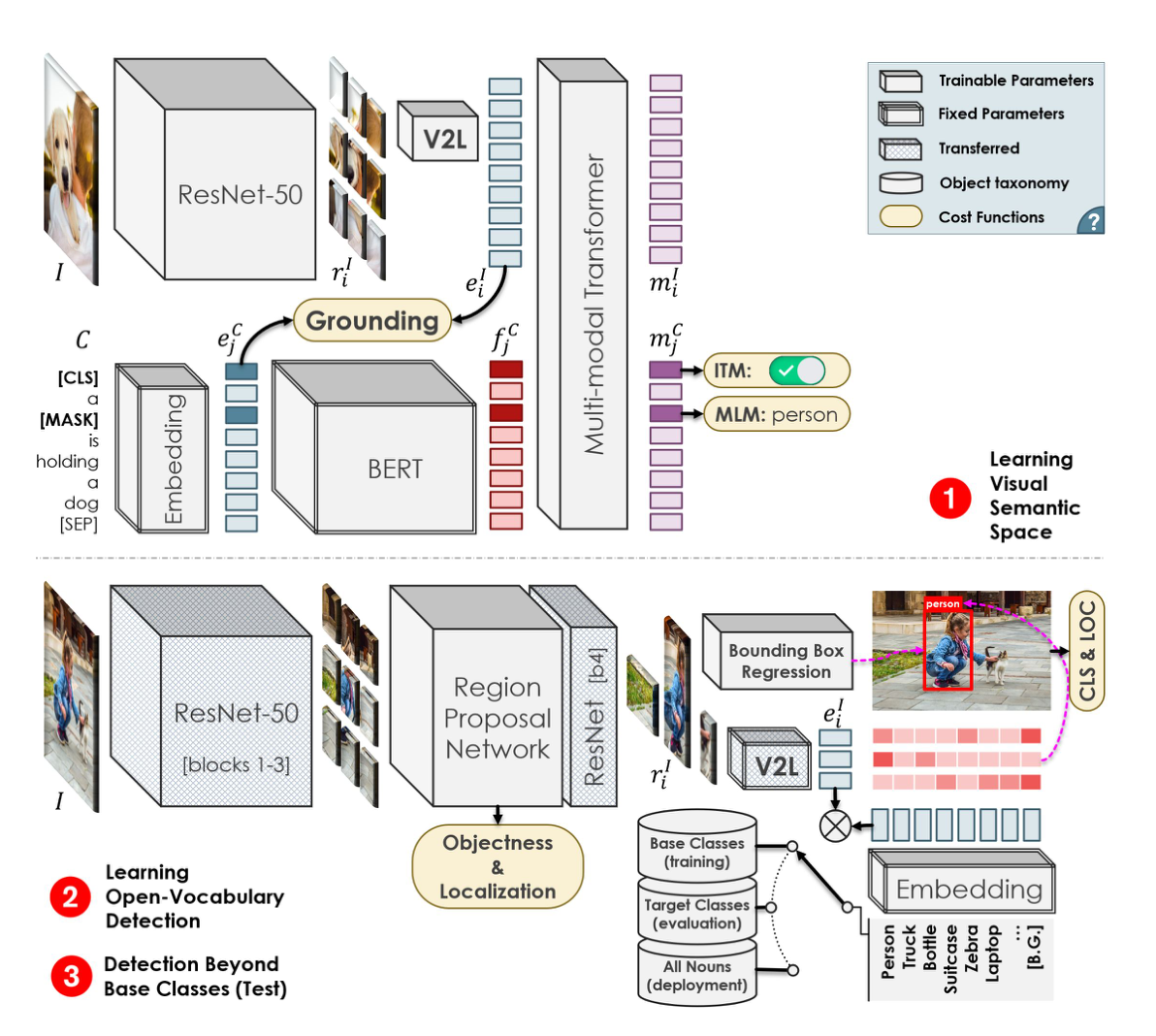
展开讨论预训练流程,整体的预训练流程有些类似于PixelBert,可参考如下:
- 分别输入image和对应的caption,视觉编码器和文本编码器将分别提取特征
- 在vision embedding和text embedding的基础上,利用V2L层对视觉embedding映射到文本embedding空间,构建grounding任务,计算对应图文对的grounding分数,然后利用对比学习拉近匹配对图文,推远非匹配对图文。这样利用word-region级别的grounding任务,实现丰富语义信息的学习
- 后续利用Transformer模型进行多模态融合,同时构建下游MLM、ITM代理任务进行预训练
即总结如下:
第一步:学习的视觉与文本的联系。通过训练一个现象变换层来把视觉空间的特征转换到文本空间,来充当一个V2L(Vision to Language)的模块,负责把视觉特征变换到文本空间去。输入的image-captioning对首先经过各自模态的encoder,图像则是细分得到每个区域的特征,然后进一步经过V2L变换。之后,两个模态的特征concat起来之后送入多模态的Transformer,得到的输出是视觉区域特征以及文本特征。损失函数则是惩罚不匹配的但是相似度高的图像-文本对。如上图文本encoder是一个预训练好的BERT,这样模型具有泛化能力,而图像encoder是常用的resnet50。
第二步:利用常规的目标检测框架:Faster R-CNN,进行模型训练。为了保证延续性,backbone采用上一阶段中训练好的resnet50,每个proposal的特征经过V2L变换之后与类别标签的文本特征计算相似度来进行分类。事实上就是把回归问题转换成了分类问题。
第三步:把要检测的新类别加入文本的特征向量中做匹配。
一旦预训练结束后,trained vision encoder和trained V2L层,便可以替换至Faster RCNN框架中,通过在base数据集上进行finetune vision encoder,使其适配ROI区域特征,固定V2L层,保持其学习到的泛化的视觉-语义空间,即可进行target类别数据的检测。
整个模型的架构跟faster-rcnn几乎完全一样,只是将最后的cls head换成了v2l(也就是换成了一个将visual feature投影到word embedding space的投影矩阵),所以其实文章的核心就是在训练这个投影矩阵
4.2 OVD与之前相关的setting
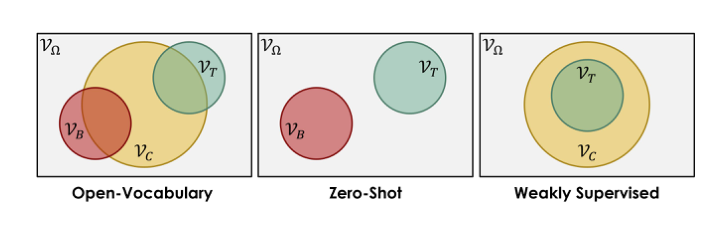
作者还特地比了一下三种setting, OVD跟ZSD的区别应该就是在训练时,OVD可能会用到target类的embedding信息,当然可能只说这些embedding信息可能包含在一堆caption中, 谁也不知道里面有没有target信息,肯定不能给target类的bbox信息。而zero-shot完全没利用到,weakly supervised就更直接了,直接利用子集来训练,从而强化泛化能力。
4.3 结果对比
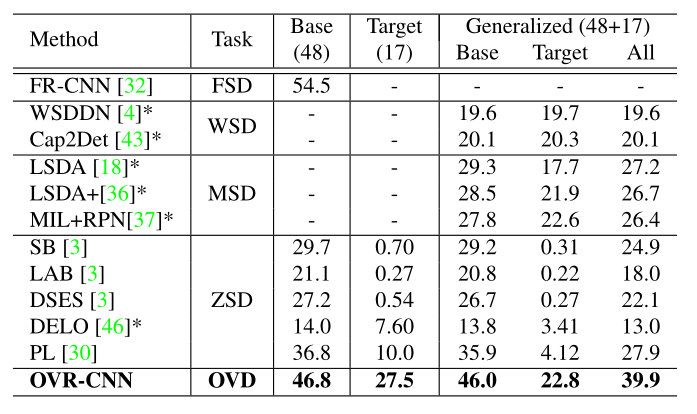
可以发现。相较于原有的zero-shot的detection,模型的泛化性能显然是更强的。
根据上表,其实我们可以发现,ZSD的检测效果差(map不高),主要原因,我认为就是对于没有任何未知类的例子经过训练,OVD 应该是会有部分未知类通过image-caption dataset 训练课得知,因此从现有基类的特征其实很难推出新类。WSD 定位效果不好, 我个人分析认为,他从没有注释的图片很难学习到特征,就很难像OVD那样通过image-caption那样,至少有图像和文本方向的特征,再通过基类的相关有注释框的图片学习,就能很好的定位。mixed supervision,其实同样存在上面的缺陷,在基类上进行训练,然后使用弱监督学习转移到目标类,这些方法通常会在基类上降低性能相反,Visual grounding和Vision-language transformers 就是来帮助解决作者的设想,通过 Vision-language transformers 可以提取 文本和图像的特征,Visual grounding 则就是根据这些特征进行定位。
同时我们也发现,利用这种用image-captioning pair模式训练出来的特征,其中每个类别的特征更加显著,如下图和zero-shot obejct detection的baseline的对比: