背景
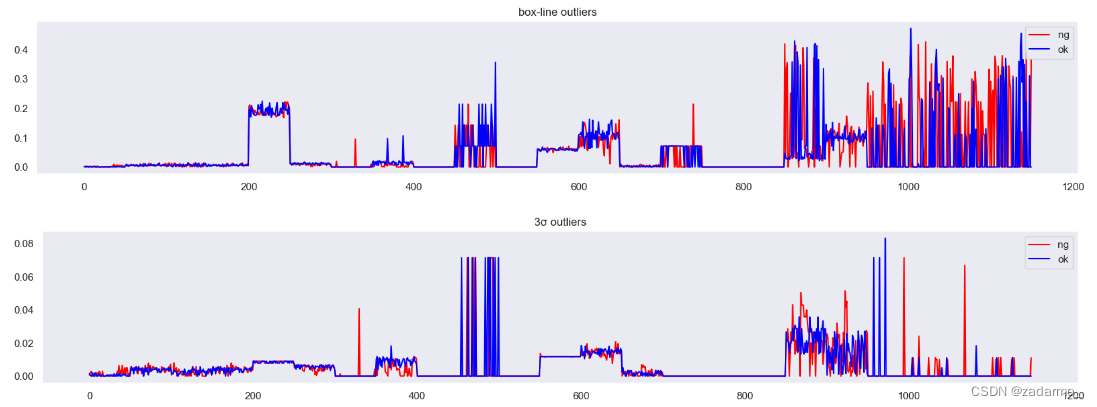
在实际的开发中,业务相关表都是通过uid或者一个可以标记业务领域的一个属性转换成的字段进行关联的,但是对于一些后续的业务,比如数据分析、下游系统使用、金融对账等业务,需要进行多表联查,之前实际生产的时候就见过对账文件使用6、7个表进行left join进行联查。而且大多数表都是千万级的表、虽然添加索引可以从一定程度上提升开发效率。但是具体如何优化,其实还是需要了解一下join具体的算法。
SQL
- left join
- right join
- inner join
- full join
join 算法
创建一个表 t1 (id,a,b) a字段创建索引,(插入100条数据) 然后创建一个相同的表B (插入1000条数据)
Simple Nested-Loop Join:SNLJ,简单嵌套循环连接
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.a = t2.b;
由于t2.b没有索引,所以会先查询t1的每一行数据,然后全标扫描t2的表进行匹配
所以执行的总行数是100 * 1000 = 10W行数据,但是实际上这个算法比较笨重,MySQL选择了另外的算法,BNLJ算法。
Index Nested-Loop Join:INLJ,索引嵌套循环连接
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.a = t2.a;

其中STRAIGHT_JOIN的作用固定SQL join的方式,因为MySQL可能会进行Join 优化,不一定按照SQL书写格式进行执行。因为t1.a和t2.a都创建的有索引,所以会走索引a
1.从t1表中获取一条数据,然后从t2中获取所有的数据进行遍历。
2.如果相等,则直接将数据放入结果集中,不想等,重新执行。
这个过程其实SNLJ算法,类似于一个双层的for循环。 Index Nested-Loop Join
流程图
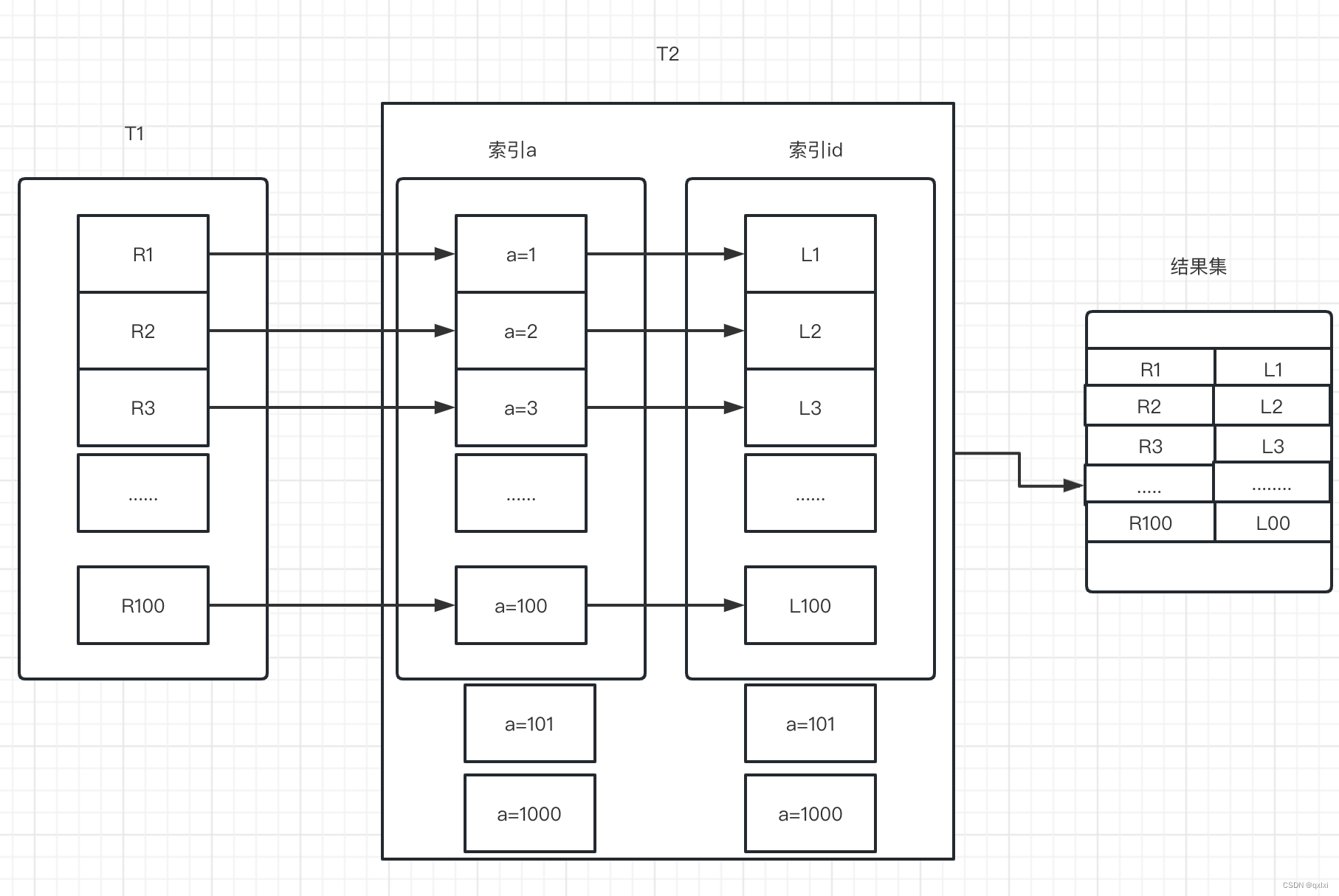
扫描行数
1.T1表100行数据 扫描100行
2.T2表1000行数据 扫描101行,一共是200行。
Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
EXPLAIN SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.a = t2.b;
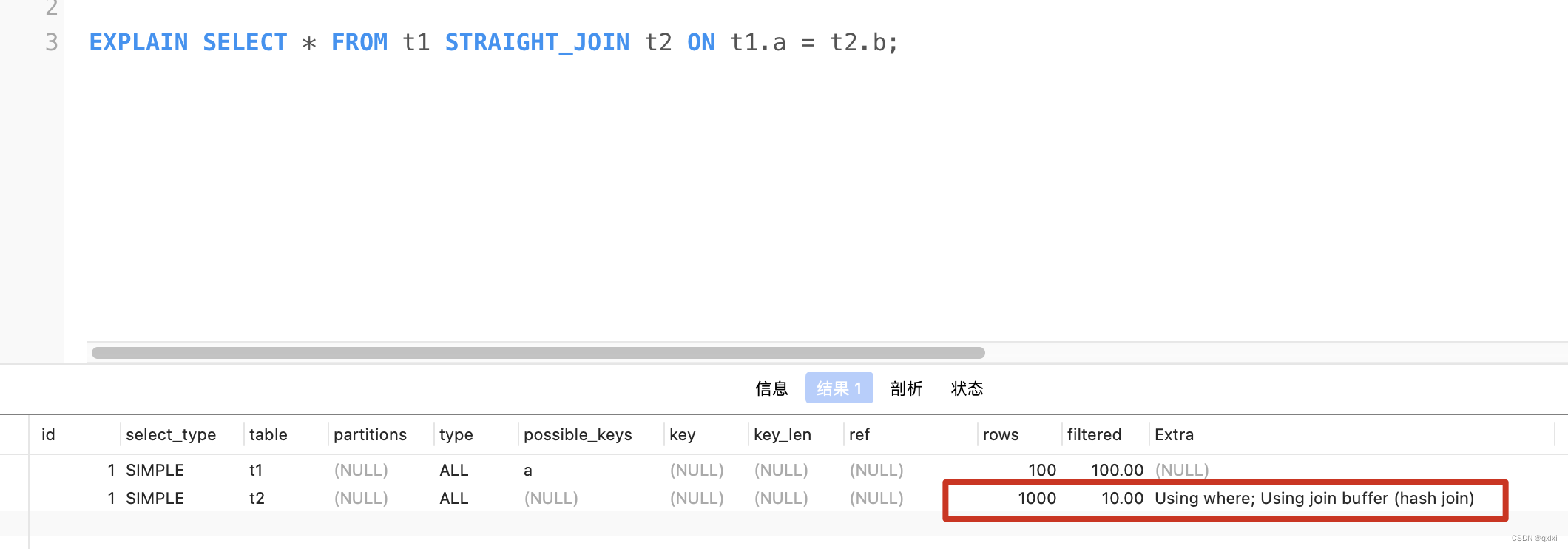
上面我们分析了,MySQL并没有走SNLJ算法,而是使用了join buffer 进行处理。那么具体的流程是什么呢
1.先将t1表中的数据拉去到join_buffer缓存中,然后获取t2的所有数据,从join_buffer缓存中获取所有数据,一条一条从t2中匹配,最后汇总结果集。
执行条数:
T1+T2 总数据1100条,因为数据在join_buffer中数据是无序的,需要在内存中进行100*1000次的判断,但是在内存的判断10W次,但是内存判断是速度是很快的。

1.join_buffer join_buffer_size 设定的,默认值是 256k,如果超过这个范围就是分段放,也就是block的名称又来。
是否可以使用join呢
1.如果可以使用 INLJ算法,说明字段都是走了索引,其实执行效率还是可以的。
2.如果BNLJ算法,大数据量下,其实建议不要使用join操作。
选择什么表做驱动表呢
如果是 Index Nested-Loop Join 算法,应该选择小表做驱动表;
如果是 Block Nested-Loop Join 算法:
在 join_buffer_size 足够大的时候,是一样的;
在 join_buffer_size 不够大的时候(这种情况更常见),应该选择小表做驱动表。