参考链接:
https://mp.weixin.qq.com/s?__biz=Mzg2NzUxNTU1OA==&mid=2247528395&idx=1&sn=6c9290dd7fd926f11cbaca312fbe99a2&chksm=ceb84202f9cfcb1410353c805b122e8df2e2b79bd4031ddc5d8678f8b11c356a25f55f488907&scene=126&sessionid=1677323905&subscene=227&key=9a02e99e10746e62edc61b510f8aa435c893767b6ec76041a96a2d39cb0923b7ca8ddd1ab0097ac2e6217b606b417eb69a086da9ed974160452df9b6c6c0f5b027a4213626c2f423451e45483b8fc46475378a84bb89041d614925d5f73fe5542db4d35ef46699463ff782427b1092450fc1016047edc1c1010d6ca92b0f3836&ascene=0&uin=Mzc0NTg4MzkyNw%3D%3D&devicetype=Windows+10+x64&version=6309001c&lang=zh_CN&countrycode=CN&exportkey=n_ChQIAhIQgje2UUM5NqDpia5oVB%2FXHxLgAQIE97dBBAEAAAAAAOyyL7mK2bcAAAAOpnltbLcz9gKNyK89dVj0vLNeFk65c8P6inPTXZ29QjOPVkYra5AJxJtX0E7z%2FLVP2Au7HyYmR0X%2FEoIPgPw0AzQU8TGtSVDX9vrkMIx5sfgjFmZqInx7EblixofRc%2FrDV%2Bu5sk7jAB8d2Cr7kIBRKAg3gq715LqS3CLOY%2F5VQ4KqrEmUp1JRmnCeCgqEx1MTKStBV6ihSUhaLgwMJKHFS0YmMD7PoFQpMRJYoMqMTWjz9CDfCYMmKWAJPdFqjnI6HeBGWKqtrPNl&acctmode=0&pass_ticket=dVWGS3Iox01jACb0GxzkNrJO8A4pK0njBNgvyRFW67nVbm6C5y5zRZm1SRwVDFUn5iynKL7FMHFZJLb6BlUuGQ%3D%3D&wx_header=1&fontgear=2
阅读心得:
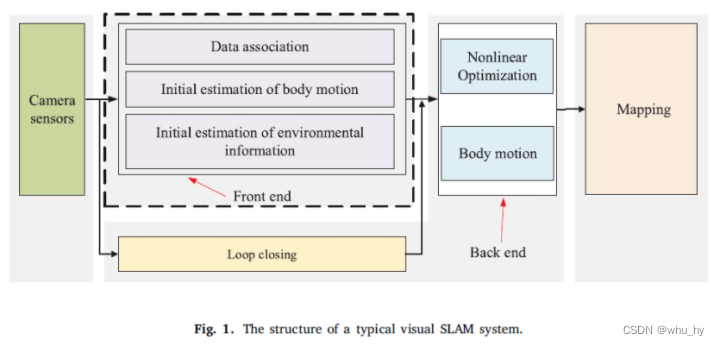
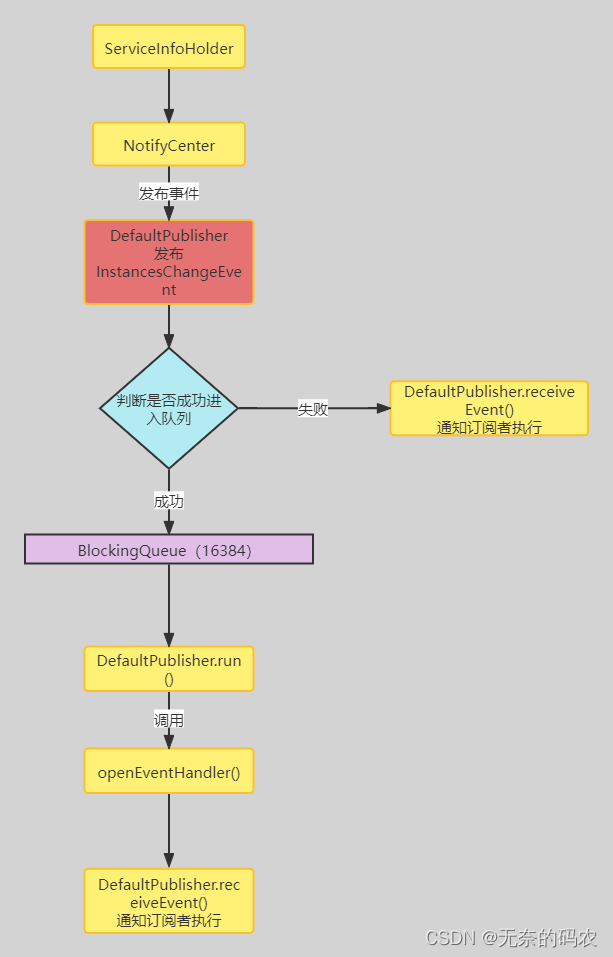
视觉SLAM系统的经典结构可分为五个部分:相机传感器模块、前端模块、后端模块、回环模块和建图模块。如图1所示,相机传感器模块负责收集图像数据,前端模块负责跟踪两个相邻帧之间的图像特征,以实现初始相机运动估计和局部建图,后端模块负责前端的数值优化和进一步的运动估计,回环模块负责通过计算大规模环境中的图像相似度来消除累积误差,建图模块负责重建周围环境(Gao等人,2017)。
编辑切换为居中
添加图片注释,不超过 140 字(可选)

编辑切换为居中
添加图片注释,不超过 140 字(可选)
视觉SLAM的前端被称为视觉里程计(VO)。它负责基于相邻帧的信息粗略地估计相机运动和特征方向。为了获得具有快速响应速度的精确姿态,需要有效的VO。目前,前端主要可分为两类:基于特征的方法和直接方法(包括半直接方法)(Zou等人,2020)。本节主要回顾VO的基于特征的方法。关于半直接和直接方法在后文。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
后端的话没啥创新的地方,能明白这里面的原理就行了。这个地方的创新点还是不足的,但是类似与GTSAM这种工程性质的代码,感觉没个100人,想要重构这个代码是有些些困难的。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
回环部分现在是可以加深度学习的,这个还不太了解。但是激光SLAM那边的回环检测是已经用了很成熟的深度学习框架在运行了。

编辑切换为居中
添加图片注释,不超过 140 字(可选)
度量地图描述了地图元素之间的相对位置关系,拓扑地图则强调了地图元素间的连接关系。同时度量地图又可以分为稀疏地图和密集地图,简单来说稀疏地图就是用特征点(关键点)来进行地图的构建,而密集地图则是用所有点(特征点)来进行地图的构建。
根据传感器的类型,视觉SLAM可以分为单目、双目、RGB-D和基于事件相机的方法。根据地图的密度,可分为稀疏、密集和半密集SLAM。总的来说,反正就是SLAM的分类有很多种,看你到底按照什么来进行分类了。
2017年,Tong等人(2017)提出了VINS-Mono,它被视为一种优秀的单目VI-SLAM系统,前端采用光流方法,后端采用基于滑动窗口的非线性优化算法(Cheng等人,2021b)。此外,VINS-Mono的初始化方法值得注意,它采用了不相交方法(以及VI-ORBSLAM Mur Artal和Tards,2017),该方法首先初始化纯视觉子系统,然后估计IMU(加速度计和陀螺仪)的偏差、重力、比例和速度。通过KITTI和EuRoC数据集的测试,VINS Mono已被证明具有与OKVIS相当的定位精度,在初始化和环路闭合阶段具有更完整和鲁棒性。2019年,VINS-Mono团队提出了双目版本,并整合了GPS信息,VINS-Fusion(Tong等人,2019)。如图6(c)所示,由于增加了GPS测量,它在户外环境中实现了良好的定位和建图效果,并且被认为是自动驾驶车辆领域的一个良好应用。
上面这一段介绍了vins,是一个非常值得学习的vio系统,这个正在学习和整理阶段,md,最近实在是没时间整理了,过几天就开始搞这个的ppt了。
基于LIDAR-IMU融合的方案分为两类:松耦合和紧耦合方案。典型的松耦合方案是LOAM,(图16(a))和LeGO-LOMA(Shan和Englot,2018),其中IMU测量信息未用于优化步骤。与松耦合方案相比,紧耦合方案处于开发阶段,这通常大大提高了系统的准确性和鲁棒性。在当前公开的紧密耦合系统中,LIO-Mapping(Ye等人,2019)使用VINS-Mono中的优化过程来最小化IMU残差和LIDAR测量误差。由于LIO建图旨在优化所有测量值,因此系统的实时效果较差。Zou等人提出了LIC融合,如图16(b)所示。它融合了点云中提取的LiDAR特征和稀疏视觉特征,蓝色和红色的LiDARR点分别是平面和边缘特征,估计的轨迹用绿色标记。为了节省计算资源,LIO-SAM(图16(c))引入了滑动窗口优化算法,使用因子图方法联合优化IMU和LIDAR的测量约束。LINS(图16(e)),专门为地面车辆设计,使用基于误差状态的卡尔曼滤波器迭代修正待估计的状态量。Zhang和Singh(2018)提出了一种紧密耦合的LVIO(激光雷达视觉惯性里程表)系统,该系统使用从粗到精的状态估计方法,从IMU预测开始进行粗略估计,然后由VIO和LIO进一步细化。目前,LVIO算法是KITTI数据集上测试精度最高的算法。Zoo等人(2019)基于MSCKF框架实现了时空多传感器的在线校准。不幸的是,Zhang和Singh(2018)和Zoo等人(2019)实施的代码目前不是开源的。Shan等人(2021)于2021发布了最新的可视化LIDAR-IMU紧耦合方案:LVI-SAM(图16(d))。为了提高系统的实时性能,它使用了平滑和建图算法。作者将视觉IMU和激光雷达IMU视为两个独立的子系统。当检测到足够多的特征点时,这两个子系统将链接在一起。当其中一个子系统检测不到时,这两个子系统可以独立分离,因为不会相互影响。表5总结了近年来视觉-惯性SLAM框架中的主要算法。
未来发展趋势:由于视觉SLAM的复杂模块(例如前端、后端、回环和建图等)增加了硬件平台的计算负担,高性能移动计算平台通常限制了上述视觉SLAM算法在自动驾驶中的应用。基于多代理的视觉SLAM技术似乎能够克服这个问题。目前,基于多智能体的可视化SLAM通常用于无人机,如果它安装在自动驾驶汽车上进行移动计算,移动计算机平台只负责处理前端数据,而后端优化和建图的过程则由远程服务器通过5G/6G通信网络来处理,我们相信,这将大大加快视觉SLAM在未来自动驾驶车辆中的应用;
(这个未来发展趋势我认为是可以的,后端的计算需要昂贵的计算资源,但是我们可以通过极快的网速将数据传入到服务器内进行计算,然后将结果再通过网络输出出去,那么这样可以大大减少车载计算资源的使用,使其能够在路上行驶的时候做其他保障车内人员安全的事情)







![洛谷 P1208 [USACO1.3]混合牛奶 Mixing Milk](https://img-blog.csdnimg.cn/3d13e122b1f340a5a841979219015e4b.png)