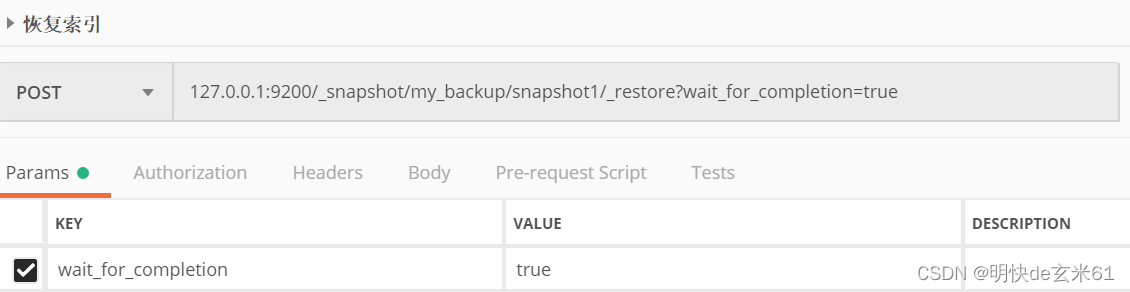
论文与代码
论文地址: https://ieeexplore.ieee.org/document/9905640/
代码地址:未开源
背景与动机
作者认为阻碍航拍场景目标检测发展的原因主要有以下两个:
航拍图像中存在大量困难目标,文中作者把困难目标总结为小目标和遮挡的目标。
分布不均匀的目标使得检测效率低下。
以上两个因素虽然占据图像的面积少,但是对最终的检测结果却有极大的影响;而其他常规区域虽然占据面积大,但是对最终检测结果的提升是有限的,这种情况符合Pareto principle(帕累托法则, 约仅有20%的因素影响80%的结果)。
PRDet
作者首先分析了现有切图方案的不足:

编辑切换为居中
添加图片注释,不超过 140 字(可选)
对于Based on dense objects这种来说只关注了小目标忽略了其他目标,相关工作如下:
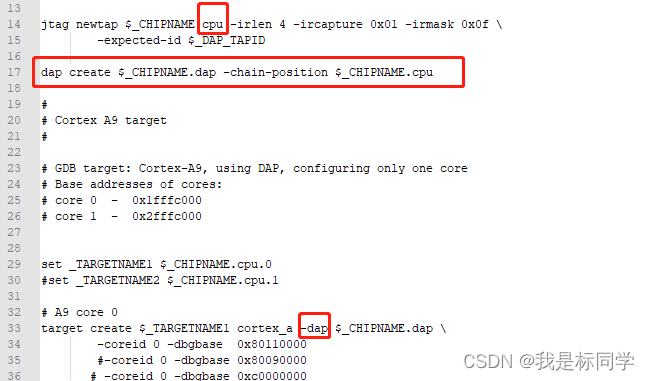
Clustered Object Detection in Aerial Images【ICCV19】
Density Map Guided Object Detection in Aerial Images【CVPRW20】
Coarse-grained Density Map Guided Object Detection in Aerial Images【ICCW20】
对于Based on low-confidence objects这种来说受检测器影响较大,相关工作如下:
How to Fully Exploit The Abilities of Aerial Image Detectors【ICCVW19】
A Global-Local Self-Adaptive Network for Drone-View Object Detection【TIP20】
Object Detection Using Clustering Algorithm Adaptive Searching Regions in Aerial Images【ECCV20
针对上述存在的问题,作者设计了一个关注"困难区域"的模型叫做PRDet,而且还能够fully exploring the valuable context in the image。大体工作流程如下:
首先对全图做一个检测
然后再对"困难区域"做一个检测
最后通过NMS,得到最终的检测结果。

编辑切换为居中
PRDet网络结构图。
PRDet的核心主要分为三部分,Challenging Region Generation,Reverse-attention Exploration Module和Region-specific Context Learning Module。
Challenging Region Generation
由于Challenging Region Generation区域是作者自定义的,因此数据集中并不存在,需要根据数据集生成。困难区域生成的算法如下:

编辑切换为全宽
添加图片注释,不超过 140 字(可选)
这一块我觉得作者写的很模糊,不是很懂,感兴趣的可以自己去看看。
Reverse-attention Exploration Module
REM模块包含两步,首先是通过CRP生成困难区域的mask,然后通过MLP生成困难区域的坐标点。这个过程是有监督的,监督信息分别是简单目标的gt和第一步生成的困难区域的gt,采用的损失函数是dice。

编辑切换为全宽
添加图片注释,不超过 140 字(可选)
CRP的输入是来自global detector,首先生成S-Mask,即简单区域,然后将其取反得到R-Mask,到这并有结束,因为R-Mask里面并不仅只包含困难区域还包含背景,因此需要细化,然后经过Fusion Block, Excavator, Decoder模块生成C-Mask,即困难区域的Mask。
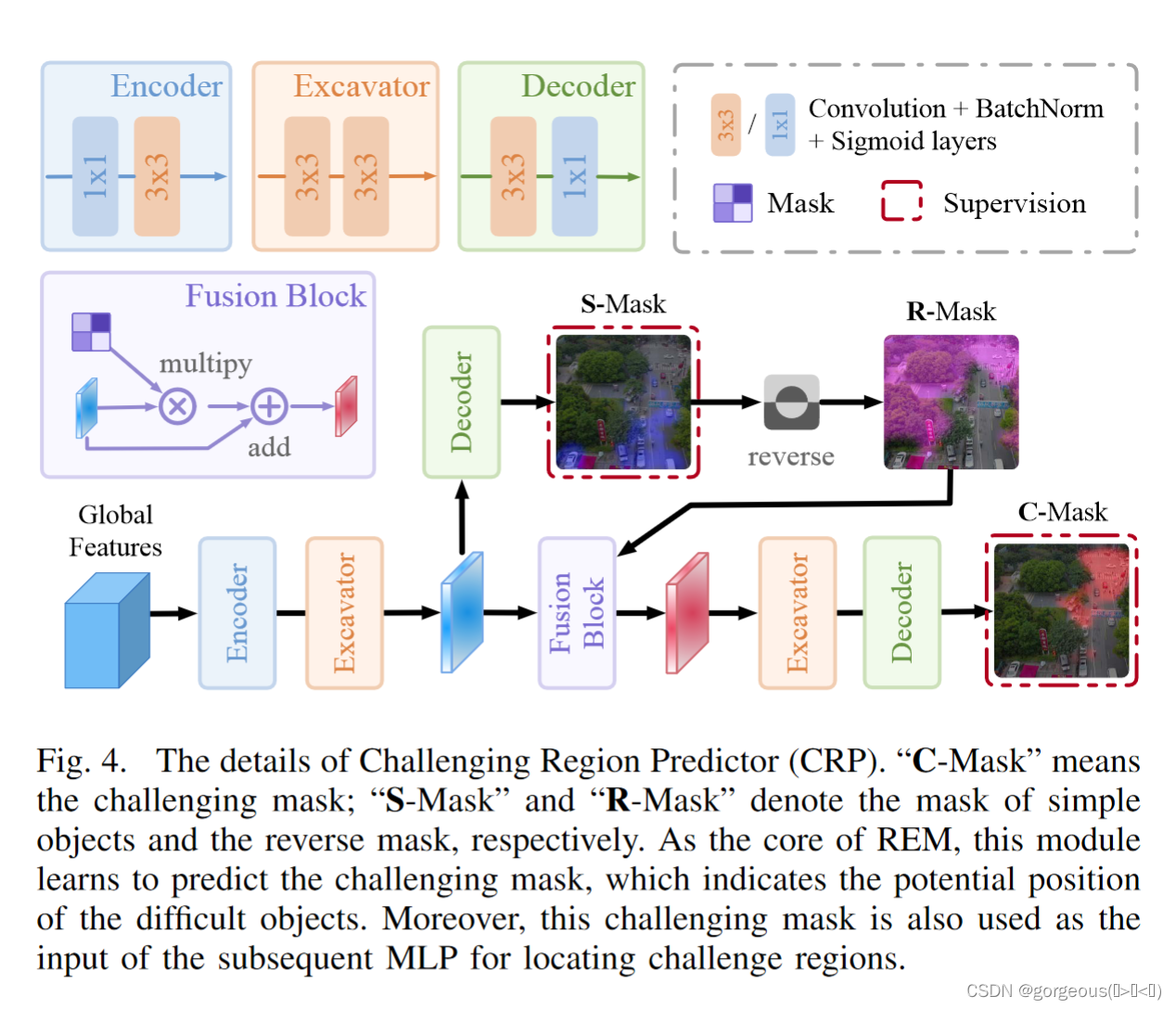
编辑切换为全宽
CRP流程
然后将C-Mask扩展成向量输入到MLP里面,与第一步生成的困难区域的目标做监督,得到预测的困难区域。最后将困难区域的坐标映射到原图,得到chips of the challenging regions。
Region-specific Context Learning Module
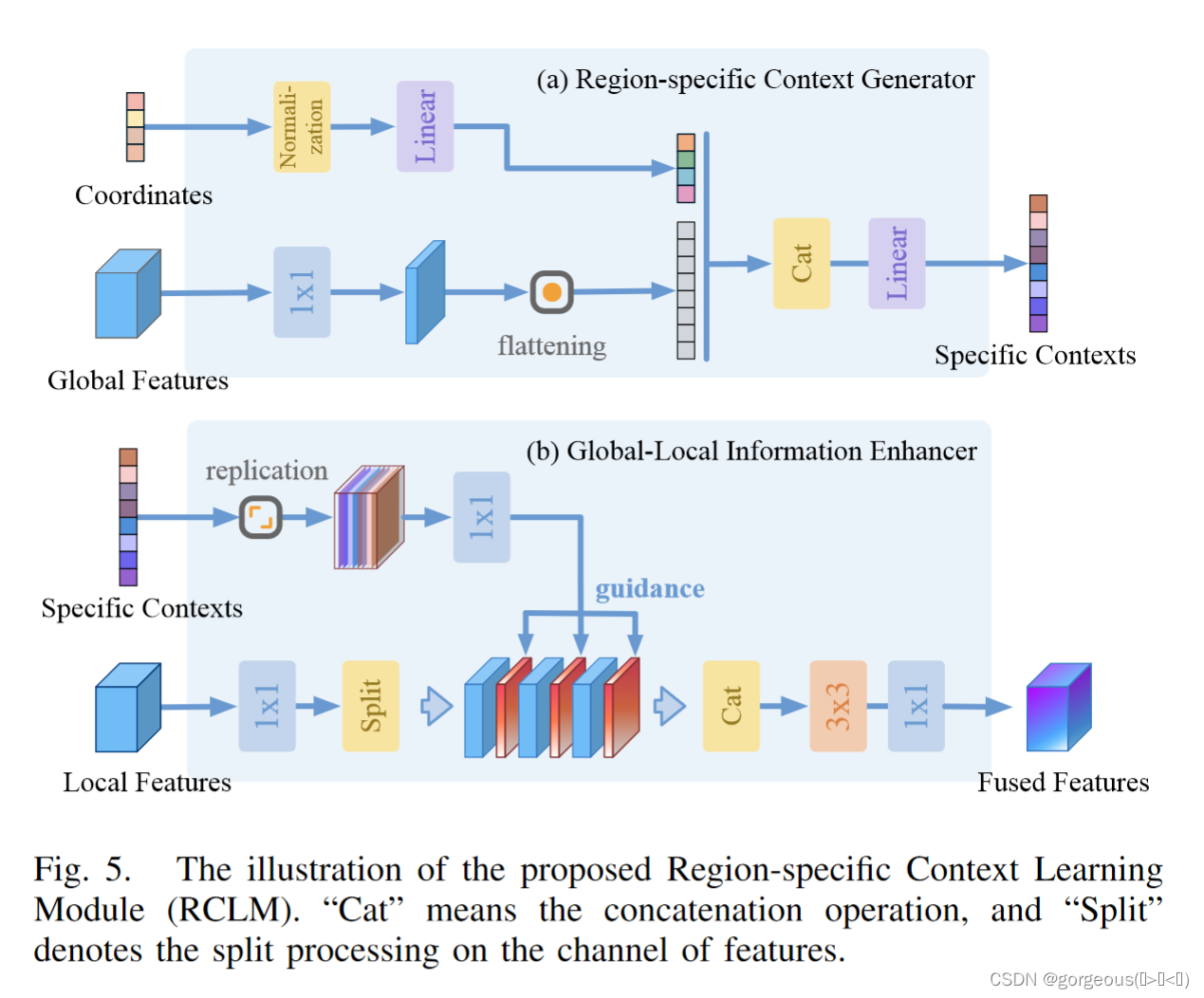
编辑切换为全宽
RCLM模块
RCLM同样包括两部分,RCG和GLIE。RCG输出的是Specific Contexts,有点像transformer中的embedding。
GLIE模块将全局的信息传递给Local Detector,使其能够更好的识别困难区域。
Final Results with Fusion
后处理采用NMS,由于Local detector得到了有价值的上下文的帮助,作者对本地检测器的结果赋予了更高的权重。
实验
实验细节
VisDrone2021-DET,UAVDT和一个工业数据集DTU-Drone。训练时输入VisDrone和UAVDT的分辨率为600x1000,DTU-Drone为512x512。测试时,三个数据集均为600x1000。
Faster-RCNN-FPN作为基线,主干网络分别为ResNet-50,ResNet-101,ResNeXt-101。除此之外,还在CenterNet v2(主干网络为ResNeXt-101)上做了测试。
结果量化
VisDrone上的对比

编辑切换为全宽
VisDrone上结果对比,基线为Faser-RCNN-FPN

编辑切换为全宽
VisDrone上结果对比,基线为Faser-RCNN-RPN,为了更加公平和其他基于区域搜索的模型对比
UAVDT

编辑切换为全宽
UAVDT上结果对比
DTU-Drone

编辑切换为全宽
DTU-Drone数据集上结果对比
消融实验
Parameter Analysis
这里是对Challenging Region Generation算法中的两个超参和 做了分析。

编辑切换为全宽
添加图片注释,不超过 140 字(可选)
其中 控制的是困难区域平均大小,一般区域越大,覆盖的目标越多。 是一张图中裁剪的个数。
Effect of reverse-attention exploration module
Effect of region-specific context learning module
编辑切换为全宽
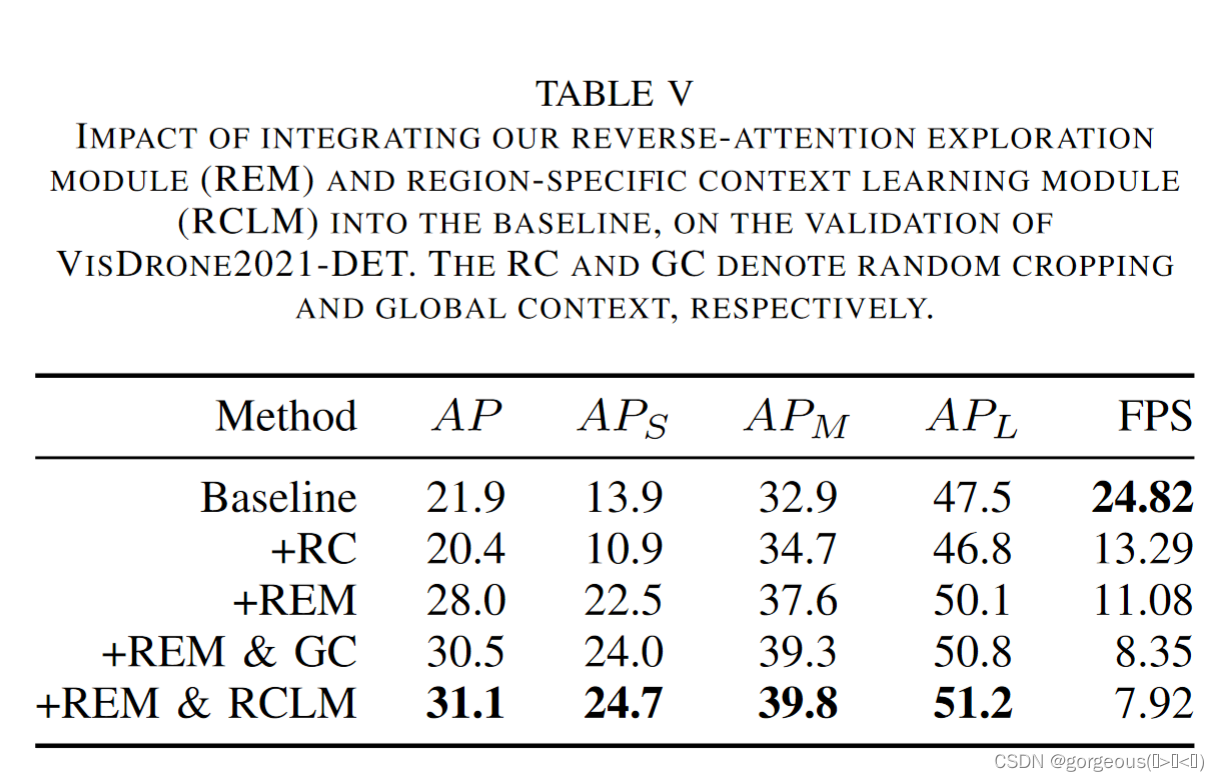
REM与RCLM消融实验
要注意的是我觉得这里作者采用random crop即上表中的RC做对比是不合理的,因为随机裁剪可能会使得样本训练不充分,导致结果下降。其他的除了FPS下降外,指标都是上升的,说明了这两个模块的优越性。
探讨
在这部分中,作者通过四个维度对比了 PRDet 与基线模型在处理航拍场景下目标检测的表现,以展示 PRDet 的优越性。这四个维度分别是每个类别的精度、混淆矩阵以及检测结果可视化和当前PRDet存在的不足。由于篇幅关系,在这就不展开了,感兴趣的可以看看原文。
思考
由于这篇文章没有代码,很多细节无法得知,作者在文中也没有说明。比如Global Features和Local Features,他们是来自NECK的哪一层以及训练流程,如果有大佬能看懂的话,可以评论告知一下小白。不过,相比之前的切图策略,作者确实提供了一个还可以的idea,通过传递global信息增强local的检测能力,但看VisDrone精度结果,其实在VisDrone上均分切图,用YOLOV5训练几乎差不多。





![洛谷 P1208 [USACO1.3]混合牛奶 Mixing Milk](https://img-blog.csdnimg.cn/3d13e122b1f340a5a841979219015e4b.png)