键值数据库,首先就要考虑里面可以存什么样的数据,对数据可以做什么样的操作,也就是数据模型和操作接口。它们看似简单,实际上却是我们理解 Redis 经常被用于缓存、秒杀、分布式锁等场景的重要基础。理解了数据模型,你就会明白,为什么在有些场景下,原先使用关系型数据库保存的数据,也可以用键值数据库保存。例如,用户信息(用户 ID、姓名、年龄、性别等)通常用关系型数据库保存,在这个场景下,一个用户 ID 对应一个用户信息集合,这就是键值数据库的一种数据模型,它同样能完成这一存储需求。但是,如果你只知道数据模型,而不了解操作接口的话,可能就无法理解,为什么在有些场景中,使用键值数据库又不合适了。例如,同样是在上面的场景中,如果你要对多个用户的年龄计算均值,键值数据库就无法完成了。因为它只提供简单的操作接口,无法支持复杂的聚合计算。那么,对于 Redis 来说,它到底能做什么,不能做什么呢?只有先搞懂它的数据模型和操作接口,我们才能真正把“这块好钢用在刀刃上”。
存哪些数据?
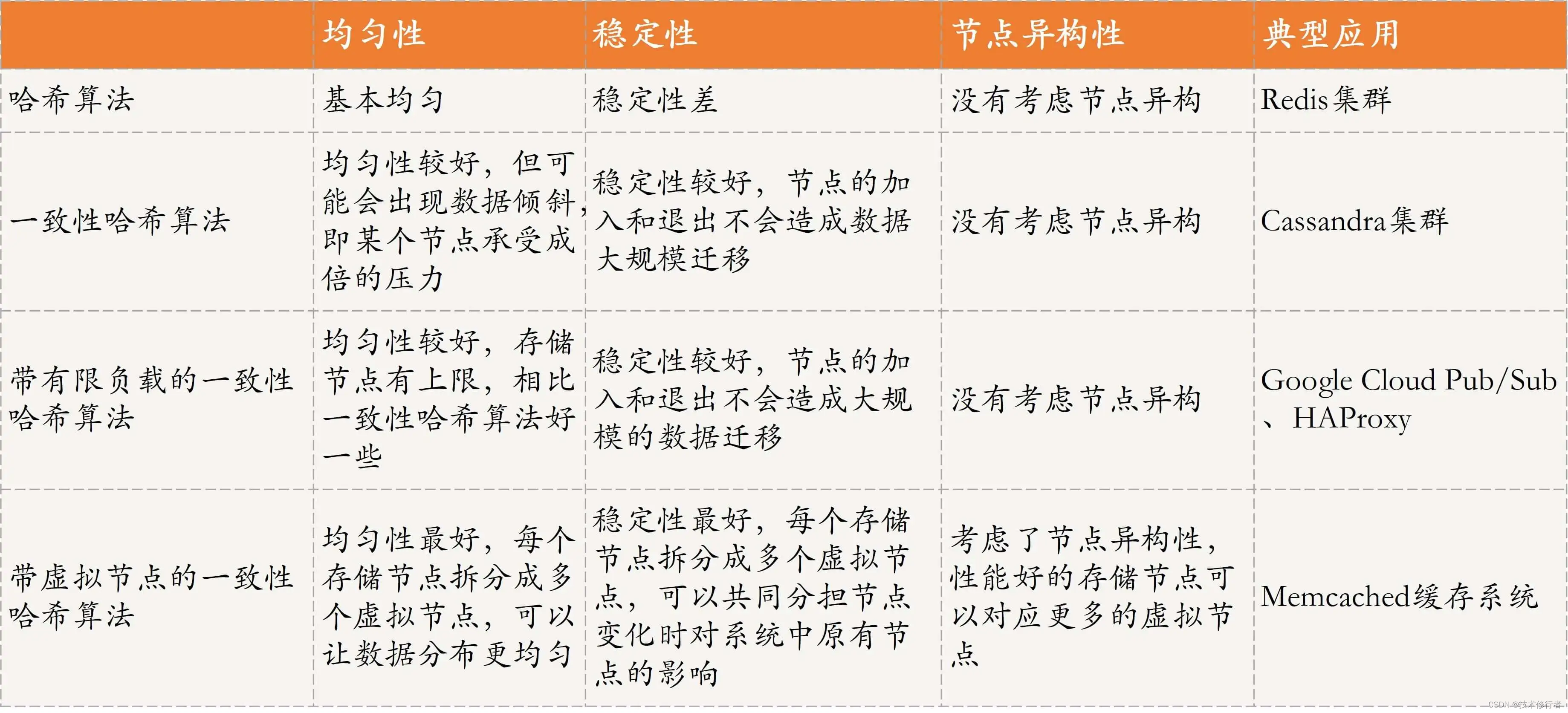
不同键值数据库支持的 key 类型一般差异不大,而 value 类型则有较大差别。我们在对键值数据库进行选型时,一个重要的考虑因素是它支持的 value 类型。例如,Memcached 支持的 value 类型仅为 String 类型,而 Redis 支持的 value 类型包括了 String、哈希表、列表、集合等。Redis 能够在实际业务场景中得到广泛的应用,就是得益于支持多样化类型的 value。
从使用的角度来说,不同 value 类型的实现,不仅可以支撑不同业务的数据需求,而且也隐含着不同数据结构在性能、空间效率等方面的差异,从而导致不同的 value 操作之间存在着差异。
操作类型
增删查改。
在实际的业务场景中,我们经常会碰到这种情况:查询一个用户在一段时间内的访问记录。这种操作在键值数据库中属于 SCAN 操作,即根据一段 key 的范围返回相应的 value 值。因此,PUT/GET/DELETE/SCAN 是一个键值数据库的基本操作集合。
存放在内存
缓存场景下的数据需要能快速访问但允许丢失,那么,用于此场景的键值数据库通常采用内存保存键值数据。Memcached 和 Redis 都是属于内存键值数据库。对于 Redis 而言,缓存是非常重要的一个应用场景。
模型组成
大体来说,一个键值数据库包括了访问框架、索引模块、操作模块和存储模块四部分。
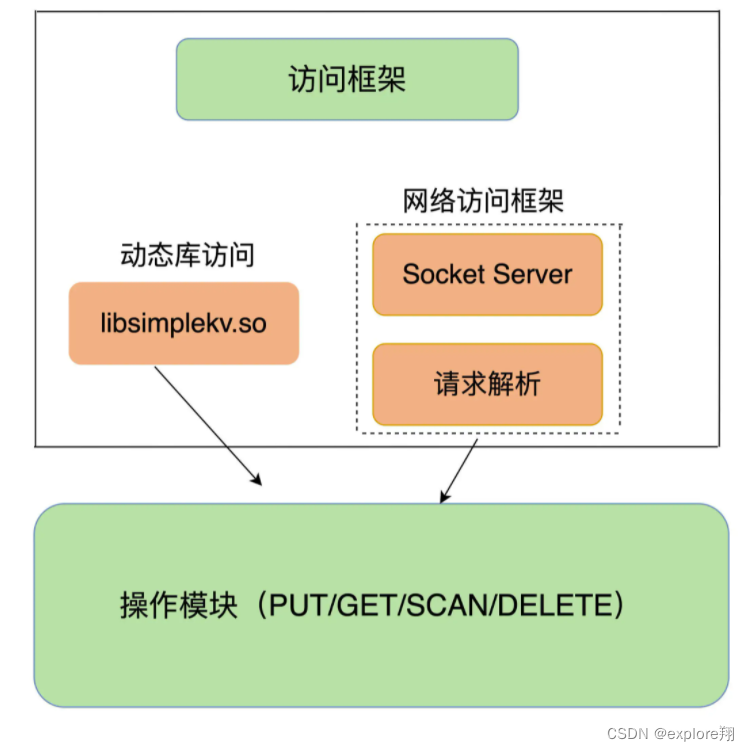
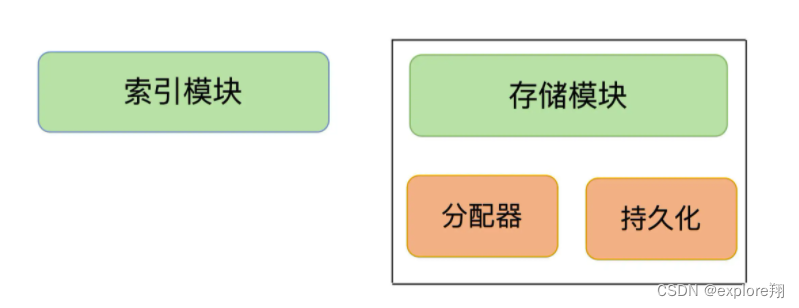
采用什么访问模式?
访问模式通常有两种:一种是通过函数库调用的方式供外部应用使用,比如,上图中的 libsimplekv.so,就是以动态链接库的形式链接到我们自己的程序中,提供键值存储功能;另一种是通过网络框架以 Socket 通信的形式对外提供键值对操作(redis)。
通过网络框架提供键值存储服务,一方面扩大了键值数据库的受用面,但另一方面,也给键值数据库的性能、运行模型提供了不同的设计选择,带来了一些潜在的问题。举个例子,当客户端发送一个如下的命令后,该命令会被封装在网络包中发送给键值数据库:PUT hello world。这其中涉及到IO模型的设计。
如何定位键值对
索引的作用是让键值数据库根据 key 找到相应 value 的存储位置,进而执行操作。
索引的类型有很多,常见的有哈希表、B+ 树、字典树等。不同的索引结构在性能、空间消耗、并发控制等方面具有不同的特征。比如mysql就是B+树作为索引。
一般而言,内存键值数据库(例如 Redis)采用哈希表作为索引,很大一部分原因在于,其键值数据基本都是保存在内存中的,而内存的高性能随机访问特性可以很好地与哈希表 O(1) 的操作复杂度相匹配。
对于 Redis 而言,很有意思的一点是,它的 value 支持多种类型,当我们通过索引找到一个 key 所对应的 value 后,仍然需要从 value 的复杂结构(例如集合和列表)中进一步找到我们实际需要的数据,这个操作的效率本身就依赖于它们的实现结构。Redis 采用一些常见的高效索引结构作为某些 value 类型的底层数据结构,这一技术路线为 Redis 实现高性能访问提供了良好的支撑。
如何为新数据分配内存?
键值数据库的键值对通常大小不一,glibc 的分配器(malloc free)在处理随机的大小内存块分配时,表现并不好。一旦保存的键值对数据规模过大,就可能会造成较严重的内存碎片问题。因此,分配器是键值数据库中的一个关键因素。对于以内存存储为主的 Redis 而言,这点尤为重要。Redis 的内存分配器提供了多种选择,分配效率也不一样。
如何重启后快速提供服务?
内存中的数据断电后是会消失的(ram)。Redis 也提供了持久化功能。不过,为了适应不同的业务场景,Redis 为持久化提供了诸多的执行机制和优化改进。


![buu [NCTF2019]babyRSA 1](https://img-blog.csdnimg.cn/a84c6d7d505e456bb29a7719367fe26e.png)