文章目录
- 一、Flink简介
- 1. Fink的引入
- 2.Flink简介
- 3.支持的编程语言
- 4.Flink的特性
- 5.Flink四大基石
- 6.批处理和流处理
- 二、Flink的架构
- 1.Flink的角色
- 2.编程模型

一、Flink简介
1. Fink的引入
大数据的计算引擎,发展过程有四个阶段
- 第一代:Hadoop的MapReduce,批处理,中间结果放在HDFS上也就是硬盘上,速度很慢,效率很低
- 第二代:支持DAG(有向无环图),Tez和Oozie,批处理
- 第三代:内存计算,Spark,支持批处理和流(实时)处理,比MR快100倍以上
- 第四代:Flink,真正的流批一体,比Spark更快
2.Flink简介
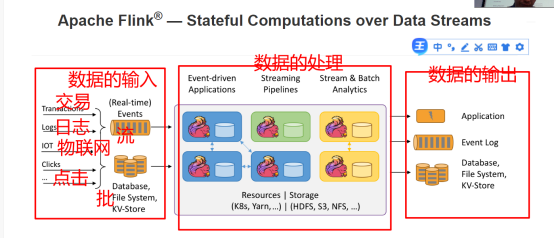
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行。
Flink的官网:https://flink.apache.org/

基于数据流的状态计算
3.支持的编程语言
Flink对java、scala、python都提供支持,但是Flink使用java开发,最适合java,课程以java语言为例。
4.Flink的特性

Flink是一个计算框架和分布式的计算处理引擎,基于对流(实时、无界)和批(离散、有界)数据进行有状态的计算,它可以通过集群以内存进行任意规模的数据计算。
- 高吞吐、低延迟、高性能
- 支持带有事件的窗口(window)操作
- 支持有状态的计算
- 内存计算
- 迭代计算
5.Flink四大基石
- 校验点Checkpoint
- 状态State
- Time时间
- 窗口Window
6.批处理和流处理
- 批处理:有界、持久、大量,处理引擎:MR、SparkSQL、Flink DataSet现在合并为DataStream
- 流处理:无界、实时、持续,处理引擎:Spark Streaming,Flink DataSteam
二、Flink的架构
1.Flink的角色
-
JobManager
也叫做Master,用于协调分布式执行、调度任务(task)、协调校验点、协调失败时的恢复,可以配置为高可用(HA),当配置高可用时,只有一台是active,其他的为standby
-
TaskManager
也叫做worker,用于执行计算任务,进行数据缓存和交换,至少得有一个worker
2.编程模型

-
ProcessFunction

-
DataStream API

-
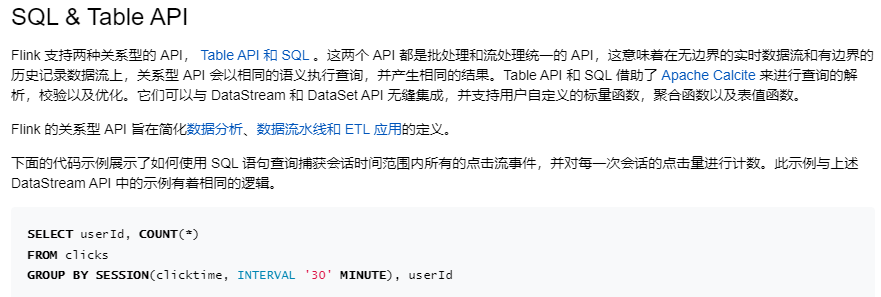
SQL & Table API
参考文章:
Flink-百度百科
Flink官网