不想写太多代码,我想直接抄一个 TCP sack 实现,参考了 lwIP TCP,很遗憾:TCP: Implement handling received SACKs
无奈不得不自己实现 sack option 的处理。由于 tso/gso/lro/gro,在软件层面难免遇到下面的情况:

无可厚非,TCP 本来就是 stream-style,能看到一个个 mbuf,skb,seg,BUF,全拜 IP 所赐,这些是 IP 报文,而不是 TCP:Indeed,in TCP there is no significance to the packetization of the data.
但我不认为我有能力正确处理这么复杂的 split,merge,于是我决定偷个懒,除非被一个 sack block 完整覆盖的 seg,否则一律不 mark sacked:
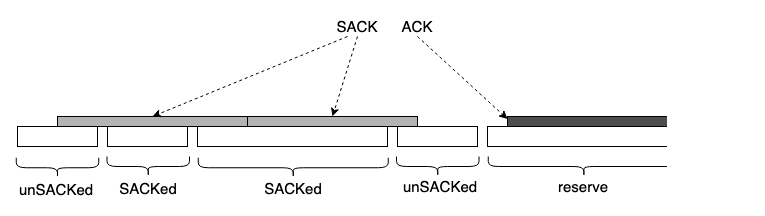
我知道 TCP 要按无边界 stream-style 处理,但为了编程方便,我选择按 seg 而不是 byte 的粒度粗糙处理。而且这样做的后果我也清楚,并且理由似乎也充分:多重传几个 partial sacked seg 的收益是少做几次 split/merge,浪费点带宽省点 cpu。
找到这个合理的妙计后,我得例行抱怨几句。
TCP 纯 byte stream 看起来更适合 hw offloading。tso/gro 本为节省 cpu,可处理 partial sack 时的 split,buddy merge 操作却给 cpu 带来了额外负担,这就和 ofo reneging一样,为释放 receiver 内存,却以 sender sacked seg 内存不能释放为代价。这只是问题转移,而非解决。
…
很不幸,现实不似你所见。开启 tso 的大吞吐场景,多是 64kB 的 tso seg,不可避免得要处理 split,merge:
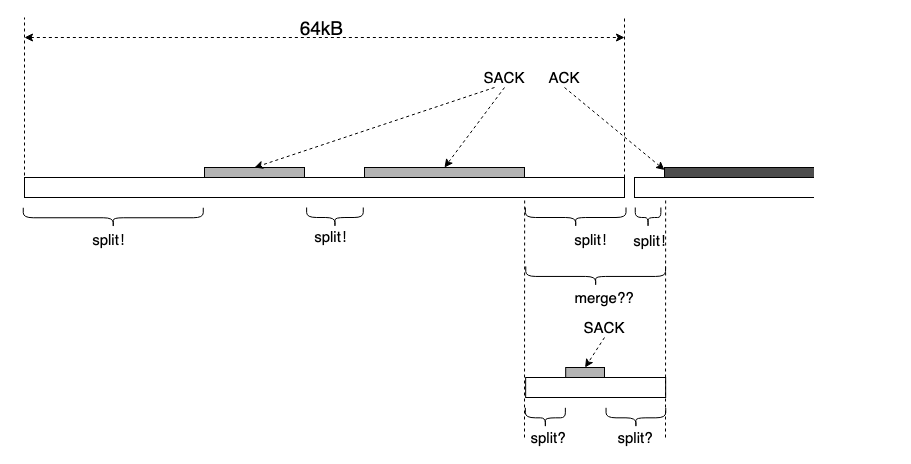
tso/gso seg 就像暴露给我一块连续大内存,我要实现 malloc/free 算法,以使 seg 最少。显然,标记一个 sack block 相当于一次 malloc,我要管理一个 buddy 系统,实现一个 buddy 算法,merge 那些连续的 sacked segs 或者 unsacked segs。
结论是,要么老老实实处理 partial sack,实现 split,merge,要么什么都不做,做了也白做,退化成标准 newreno。
…
我是不是可以在上班时间公然正当地刷几个 leetcode 题目练手或抄几个答案作为参考呢?
比如这个:区间列表的交集
或者还有这个:区间合并
…
我确实参考了几个题目。但描述算法细节不是我写本文的目的,本文是想引述一段 TCP 的演化史。
常规考虑,让 TCP 更简单的方法非常简单:一次 ack/sack 不要跨越 (re)transmit 边界:
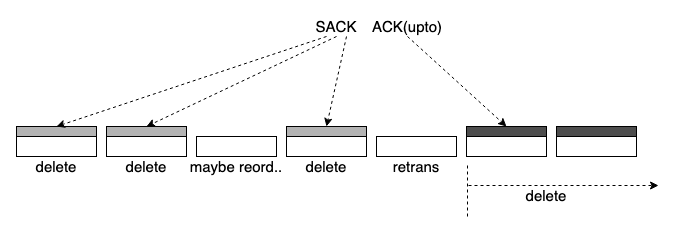
很简单,加一个封装就行,这是我唠叨了很久的话题,把 seg 打到一个以固定长度的 packet 中,以它来做 (re)transmit 和 ack/sack 的基本单元。(re)transmit 和 ack/sack 只能看到 packet,看不到 byte stream。
packet 不妨碍 tso,有了 packet 作容器,tso 更容易做,元信息给到即可。
TCP byte stream 完全以业务流为核心,byte stream 直接暴露给 (re)transmit,没有边界,协议处理复杂,开销极大。
为什么 TCP 在最开始没有考虑到这些影响?因为 RFC793 标准化 TCP 时, packetization 并非刚需。
尚未支持 sack 时,TCP 非常简单,再往前追溯到尚未支持 fast retransmit/recovery(后面称 fr) 时,TCP 只有积累 ack 和 rto,未丢包时窗口停等,丢包时单 seg 停等。分组交换网要求 packetization,可 TCP 不需要,当 IP 从 TCP 分离时,packetization 也跟着分离了,成了 IP 的 function。
但从 RFC793 单 seg 停等 retransmit 到 RACK 流水线 retransmit,直接暴露的 byte stream 逐渐变得不适合直接做 (re)transmit。(re)transmit 方式的演化是带宽,CPU,内存等资源逐渐丰盈的结果。
当 TCP 吞吐开始被关注时,人们意识到把 packet 看做 byte stream 容器统一 (re)transmit 可提高吞吐,就像集装箱可高效运输货物一样。可 TCP 偏偏没有作为集装箱的 packet(QUIC 有)。
当年 TCP,IP 分离,packetization 划给 IP 时,TCP 并没有实际的 packetization 需求。IP 要连接不同 MTU 的网络,将大报文分片是刚需,packetization 自然而然进入 IP。
失去 packetization 使 TCP 失去 1 packet 字节的容量弹性。packet 显然可以提供该弹性(rwnd = n-packet,可允许 sender 发送 n~n*mss 字节而不是 1~n 字节的数据)。但失去 packetization 的流控只能基于 byte,像 remote login 这类应用,为每个 byte(敲入的字符)进行 transmit 很浪费。可反过来也对,TCP 丢掉了 packetization,在 retransmit 时才可合并多个 byte(以及后来合并 sack) 而提高载荷率,基于 byte 的 transmit 反而成了好事。
RFC2018 引入 sack option,在 RFC1323 的基础上希望进一步优化了 TCP 的吞吐性能。这一切都直接在 byte stream 上做扩展,却与 (re)transmit 和 ack/sack 紧耦合。网络收发逻辑处理报文时,不会关注 sack block,wscale,但无疑这些直接作用于 byte stream 的 feature 让 TCP 的处理变得更加复杂。
现代工业选择集装箱运输,一切提高吞吐效率的手段直接作用集装箱而不是货物。只要不断改进集装箱配套设施,无论集装箱里装什么货,都可提高其运输效率,装卸工作只在港口进行,一旦离开港口,直到箱体抵达对端码头卸货,箱货不分离,若货轮出事故,资损赔付单位也是整个集装箱,而不可能是半箱。
TCP 允许货物以任意单位资损,任何中转站以及目的地都可以任意单位分割,接收货品。这与现代工业的集装箱思想背道而驰,显然直接对 byte stream 进行传输控制不是一个好主意,甚至在处理复杂度达到一个可预期的上限后会劣化吞吐性能。
一个生活中的例子,说明 patch 的开销随着 patch 自身而增大:
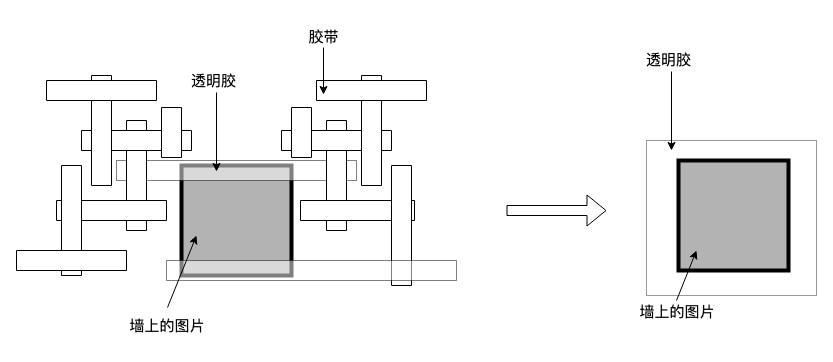
新贴的胶带只为加固已有的胶带,因为最开始那条透明胶已经在那里了。正确的做法是增加透明胶的墙面的接触面积。
pipe 越长肥,TCP send queue 越长,仅限于 4 段的 sack block 匹配巨长无比的 send queue 同时要处理复杂的 split,merge,让 CPU 不堪重负,丢包的影响本应收敛在 packet,却因 sack 直接作用于 byte stream 而不得不对 CPU 形成了反压,丢包率越高,sack 处理开销越大。
…
我曾常抱怨 TCP 的低效,直到现在我也觉得只要稍微改一点,绳结就开了。我认识到 tso 显然不是这个绳结,tso 将处理 sack 时的复杂性重新转嫁回了 CPU,站远一点,看个全局视图,只要将 byte stream 打包一下就好。
但我知道,升级 TCP 不如部署一个新协议,当我再看 arpanet 协议的哲学,重新看这一路历程,就跟我看 1970 年代的 UNIX 一样对 TCP/IP 充满敬畏。
只靠 rto 丢包恢复时,超时后,哪个 seg 丢了,几个 seg 丢了,悲观估计,乐观估计都是猜,TCP 乐观地认为只丢了一个,然后小心翼翼 go-back-n,引入 fr 是一件大事,TCP 选择通过 3 dupack “快速” “启发” 重传而不是 rto 时悲观 “启发” “过多” 的重传来平衡时空关系。如果 rto 太慢,fr 能让它快一点,但如果 rto 重传过多,无效的重传就覆水难收。
单 seg 停等的丢包恢复可确保没有无效重传,若发生无效重传,将浪费 40 年前本就稀缺的带宽和内存资源,当物质资源紧缺时,唯一充足的是时间,因此窗口停等在丢包恢复时切换到单 seg 停等,一次只重传一个 seg。
直到现在 TCP 依然保留这种谨慎,这让 TCP 的任何测量都不确保准确,但在算法上却足够精确。这种谨慎与如今的 “激进式” 优化形成对比,终极一问,回答始终一致,如杂交水稻之后,还粒粒皆辛苦吗?
fr 之后,通过引入 sack 提高了 “准确性”,又是一件大事,但协议空间限制,sack 却又不足够。有限 sack 只是多了不充分 mark lost 例程,被 mark lost 的 seg 依然只有一次 fr 机会,直到时间序 rack 带来了改变。 详见:TCP 演化史-fast retransmit/recovery
40 多年来,描述 TCP 演化历程的过程中充满了 “但”,“却”…
在这些转折的背后,接近本质的逻辑往往和最初发生的事情相关,紧接着再看本文最开始的描述了,应该也就清晰了。
浙江温州皮鞋湿,下雨进水不会胖。