论文地址:https://arxiv.org/abs/2103.12040
一、论文简介
LaneAF是一个语义分割+聚类后处理的一种方法。相对于之前的用聚类算法对embedding分支聚类的方法,该论文提出了水平和垂直两个向量场,用来取缔之前的普通聚类。根据向量场就可以完成聚类问题。
二、网络结构
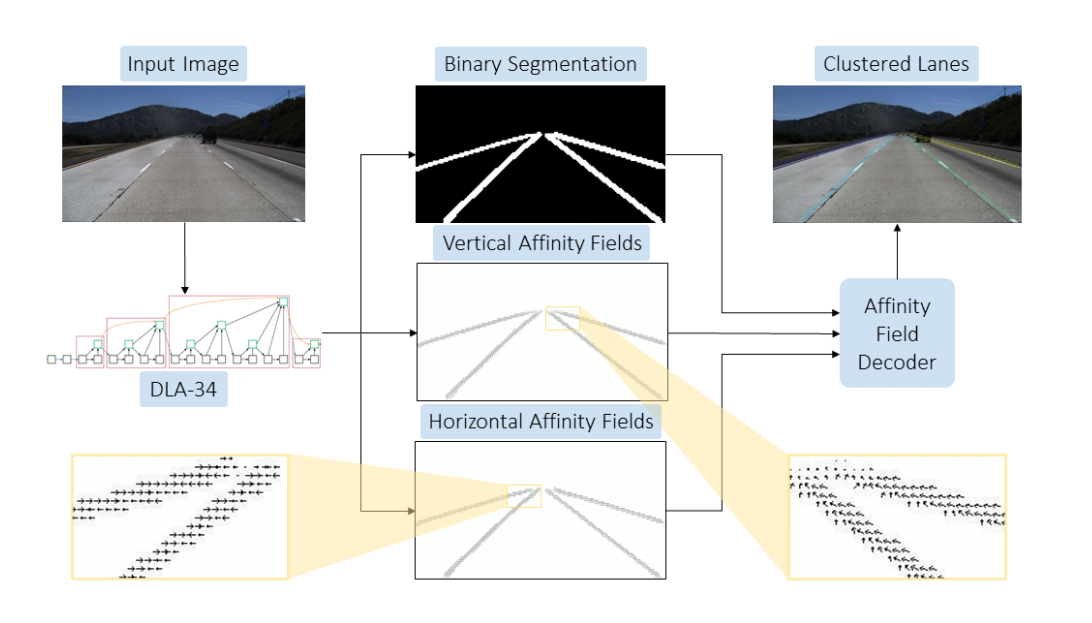
使用了DLA-34作为骨干网络,然后经过DLAUP和IDAUP的上采样处理,然后接三个预测分支。
具体的网络结构如下所示:
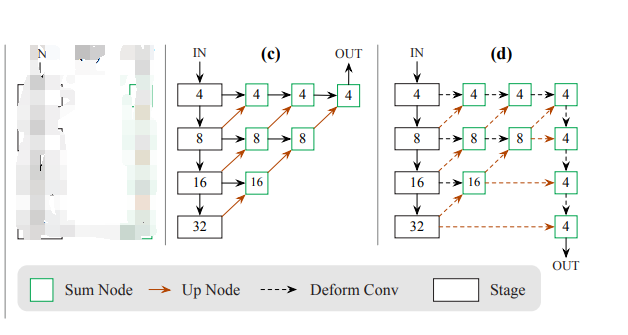
c是DLA的架构,d是论文里改进的。相当于加了更多的跨层连接。
后面的分支一个是二值分割网络channel=1,一个channel=2的VAF,一个channel=1的HAF.
(hm): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
)
(vaf): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))
)
(haf): Sequential(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(256, 1, kernel_size=(1, 1), stride=(1, 1))
)损失函数:分割使用的加权交叉熵损失和IOU损失,两个向量场分支只对前景点使用L1loss。
三、网络中的VAF和HAF的生成与推理
1、VAF和HAF的生成
GT的生成,自底向上逐行扫描,对每一行属于当前车道线实例的的像素点根据公式计算其VAF和HAF。公式如下:
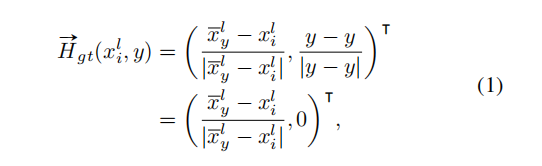
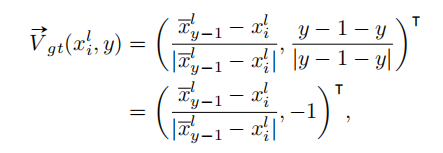
首先对每一行计算HAF。其中表示当前行属于该车道线实例的像素中心(一行属于一个车道线的像素有好几个,求平均就是中心值)。这样每行的HAF,要么指向左,要么指向右,要么为0.
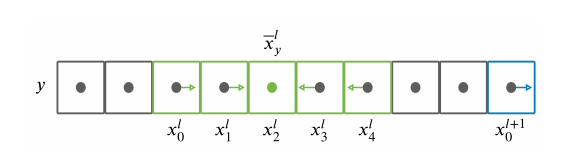
再来看看VAF的计算公式,对于属于车道线实例l的像素i,其VAF表示指向上一行车道线实例中心像素的单位向量。这样HAF把每一行的像素分成一个一个实例,然后VAF再把他们串起来成为车道线实例。
2、VAF和HAF的解码
预测完VAF和HAF之后,对于每个前景点,需要对这两个向量解码来实现车道线实例分割。自底向上,先根据HAF对每一行进行聚类,然后再根据VAF对不同行进行关联。行聚类的判断标准是:只有前面像素指向左并且当前像素指向右时,才会为当前像素重新分配一个cluster,这样就可以完成了行聚类,那么不同行之间怎么关联?本行的一簇像素与上一行的簇中心计算平均距离,然后取最小的进行匹配。具体的看下面的代码讲解。
四、代码分析
heads = {'hm': 1, 'vaf': 2, 'haf': 1}
model = get_pose_net(num_layers=34, heads=heads, head_conv=256, down_ratio=4)
def get_pose_net(num_layers, heads, head_conv=256, down_ratio=4):
model = DLASeg('dla{}'.format(num_layers), heads,
pretrained=True,
down_ratio=down_ratio,
final_kernel=1,
last_level=5,
head_conv=head_conv)
return model
class DLASeg(nn.Module):
def __init__(self, base_name, heads, pretrained, down_ratio, final_kernel,
last_level, head_conv, out_channel=0):
super(DLASeg, self).__init__()
assert down_ratio in [2, 4, 8, 16] # 4
self.first_level = int(np.log2(down_ratio)) # 2
self.last_level = last_level # 5
self.base = globals()[base_name](pretrained=pretrained) # DLA-34
channels = self.base.channels # [16, 32, 64, 128, 256, 512]
scales = [2 ** i for i in range(len(channels[self.first_level:]))] # [1, 2, 4, 8]
self.dla_up = DLAUp(self.first_level, channels[self.first_level:], scales)
if out_channel == 0:
out_channel = channels[self.first_level] # 64
self.ida_up = IDAUp(out_channel, channels[self.first_level:self.last_level],
[2 ** i for i in range(self.last_level - self.first_level)])
self.heads = heads
for head in self.heads:
classes = self.heads[head]
if head_conv > 0:
fc = nn.Sequential(
nn.Conv2d(channels[self.first_level], head_conv,
kernel_size=3, padding=1, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(head_conv, classes,
kernel_size=final_kernel, stride=1,
padding=final_kernel // 2, bias=True))
if 'hm' in head:
fc[-1].bias.data.fill_(-2.19)
else:
fill_fc_weights(fc)
else:
fc = nn.Conv2d(channels[self.first_level], classes,
kernel_size=final_kernel, stride=1,
padding=final_kernel // 2, bias=True)
if 'hm' in head:
fc.bias.data.fill_(-2.19)
else:
fill_fc_weights(fc)
self.__setattr__(head, fc)
def forward(self, x):
x = self.base(x) # DLA-34 backbone
x = self.dla_up(x)
y = []
for i in range(self.last_level - self.first_level):
y.append(x[i].clone())
self.ida_up(y, 0, len(y))
z = {}
for head in self.heads:
z[head] = self.__getattr__(head)(y[-1])
return [z]def generateAFs(label, viz=False):
# creating AF arrays
num_lanes = np.amax(label)
VAF = np.zeros((label.shape[0], label.shape[1], 2))
HAF = np.zeros((label.shape[0], label.shape[1], 2))
# loop over each lane
for l in range(1, num_lanes+1):
# initialize previous row/cols
prev_cols = np.array([], dtype=np.int64)
prev_row = label.shape[0]
# parse row by row, from second last to first
for row in range(label.shape[0]-1, -1, -1):
cols = np.where(label[row, :] == l)[0] # get fg cols
# get horizontal vector
for c in cols:
if c < np.mean(cols):
HAF[row, c, 0] = 1.0 # point to right
elif c > np.mean(cols):
HAF[row, c, 0] = -1.0 # point to left
else:
HAF[row, c, 0] = 0.0 # point to left
# check if both previous cols and current cols are non-empty
if prev_cols.size == 0: # if no previous row/cols, update and continue
prev_cols = cols
prev_row = row
continue
if cols.size == 0: # if no current cols, continue
continue
col = np.mean(cols) # calculate mean
# get vertical vector
for c in prev_cols:
# calculate location direction vector
vec = np.array([col - c, row - prev_row], dtype=np.float32)
# unit normalize
vec = vec / np.linalg.norm(vec)
VAF[prev_row, c, 0] = vec[0]
VAF[prev_row, c, 1] = vec[1]
# update previous row/cols with current row/cols
prev_cols = cols
prev_row = row
if viz: # visualization
down_rate = 1 # downsample visualization by this factor
fig, (ax1, ax2) = plt.subplots(1, 2)
# visualize VAF
q = ax1.quiver(np.arange(0, label.shape[1], down_rate), -np.arange(0, label.shape[0], down_rate),
VAF[::down_rate, ::down_rate, 0], -VAF[::down_rate, ::down_rate, 1], scale=120)
# visualize HAF
q = ax2.quiver(np.arange(0, label.shape[1], down_rate), -np.arange(0, label.shape[0], down_rate),
HAF[::down_rate, ::down_rate, 0], -HAF[::down_rate, ::down_rate, 1], scale=120)
plt.show()
return VAF, HAFdef decodeAFs(BW, VAF, HAF, fg_thresh=128, err_thresh=5, viz=False):
output = np.zeros_like(BW, dtype=np.uint8) # initialize output array
lane_end_pts = [] # keep track of latest lane points
next_lane_id = 1 # next available lane ID
if viz:
im_color = cv2.applyColorMap(BW, cv2.COLORMAP_JET)
cv2.imshow('BW', im_color)
ret = cv2.waitKey(0)
# start decoding from last row to first
for row in range(BW.shape[0]-1, -1, -1):
cols = np.where(BW[row, :] > fg_thresh)[0] # get fg cols
clusters = [[]]
if cols.size > 0:
prev_col = cols[0]
# parse horizontally
for col in cols:
if col - prev_col > err_thresh: # if too far away from last point
clusters.append([])
clusters[-1].append(col)
prev_col = col
continue
if HAF[row, prev_col] >= 0 and HAF[row, col] >= 0: # keep moving to the right
clusters[-1].append(col)
prev_col = col
continue
elif HAF[row, prev_col] >= 0 and HAF[row, col] < 0: # found lane center, process VAF
clusters[-1].append(col)
prev_col = col
elif HAF[row, prev_col] < 0 and HAF[row, col] >= 0: # found lane end, spawn new lane
clusters.append([])
clusters[-1].append(col)
prev_col = col
continue
elif HAF[row, prev_col] < 0 and HAF[row, col] < 0: # keep moving to the right
clusters[-1].append(col)
prev_col = col
continue
# if col - prev_col > err_thresh: # if too far away from last point
# clusters.append([])
# clusters[-1].append(col)
# prev_col = col
# continue
# if HAF[row, prev_col] < 0 and HAF[row, col] >= 0: # found lane end, spawn new lane
# clusters.append([])
# clusters[-1].append(col)
# prev_col = col
# else: # keep moving to the right
# clusters[-1].append(col)
# prev_col = col
# parse vertically
# assign existing lanes
assigned = [False for _ in clusters]
C = np.Inf*np.ones((len(lane_end_pts), len(clusters)), dtype=np.float64)
for r, pts in enumerate(lane_end_pts): # for each end point in an active lane
for c, cluster in enumerate(clusters):
if len(cluster) == 0:
continue
# mean of current cluster
cluster_mean = np.array([[np.mean(cluster), row]], dtype=np.float32)
# get vafs from lane end points
vafs = np.array([VAF[int(round(x[1])), int(round(x[0])), :] for x in pts], dtype=np.float32)
vafs = vafs / np.linalg.norm(vafs, axis=1, keepdims=True)
# get predicted cluster center by adding vafs
pred_points = pts + vafs*np.linalg.norm(pts - cluster_mean, axis=1, keepdims=True)
# get error between prediceted cluster center and actual cluster center
error = np.mean(np.linalg.norm(pred_points - cluster_mean, axis=1))
C[r, c] = error
# assign clusters to lane (in acsending order of error)
row_ind, col_ind = np.unravel_index(np.argsort(C, axis=None), C.shape)
for r, c in zip(row_ind, col_ind):
if C[r, c] >= err_thresh:
break # 升序,后面的肯定都不满足阈值要求,直接跳出循环
if assigned[c]:
continue
assigned[c] = True
# update best lane match with current pixel
output[row, clusters[c]] = r+1
lane_end_pts[r] = np.stack((np.array(clusters[c], dtype=np.float32), row*np.ones_like(clusters[c])), axis=1)
# initialize unassigned clusters to new lanes
for c, cluster in enumerate(clusters):
if len(cluster) == 0:
continue
if not assigned[c]:
output[row, cluster] = next_lane_id
lane_end_pts.append(np.stack((np.array(cluster, dtype=np.float32), row*np.ones_like(cluster)), axis=1))
next_lane_id += 1
if viz:
im_color = cv2.applyColorMap(40*output, cv2.COLORMAP_JET)
cv2.imshow('Output', im_color)
ret = cv2.waitKey(0)
return output
五、Reference
[Paper Reading]LaneAF: Robust Multi-Lane Detection with Affinity Fields - 知乎 (zhihu.com)