const限定符
用const给字面常量起个名字(标识符),这个标识符就称为标识符常量;因为标识符常量的声明和使用形式很像变量,所以也称常变量。声明方式:
const int a = 77;
const float PI = 3.14159f;
需要注意的是,常量必须在定义时初始化,初始化常量不能重新被赋值。
关于指针,
const int * p;
const在左边,这表示我们定义了一个指针,指向的数据类型为const int,即p是一个常量。
int a = 77;
int * const p = &a;
const在*右边,表示p是一个地址常量,必须对p 进行赋值。
const定义的常量与#define定义的符号常量的区别:
1.const定义的常量有类型,而#define定义的没有类型,编译可以对前者进行类型安全检查,而后者仅仅只是做简单替换;
2.const定义的常量在编译时分配内存,而#define定义的常量是在预编译时进行替换,不分配内存。
3.作用域不同,const定义的常变量的作用域为该变量的作用域范围。而#define定义的常量作用域为它的定义点到程序结束,当然也可以在某个地方用#undef取消。
定义常量还可以用enum,高层次编程尽量用const、enum、inline替换#define定义常量。在底层编程,#define是很灵活的。
结构体内存对齐
内存对齐:编译器为每个“数据单元”按排在某个合适的位置上。C、C++语言非常灵活,它允许你干涉“内存对齐”。
为什么要对齐?性能原因:在对齐的地址上访问数据块。
如何对齐:
第一个数据成员放在offset为0的位置;
其它成员对齐至min(sizeof(member),#pragma pack所指定的值)的整数倍。#pragma pack为编译器预设的一个对齐数;
整个结构体也要对齐,结构体总大小对齐至各个成员中最大对齐数的整数倍。
举个例子:
#include <iostream>
using namespace std;
struct Test{
char a;
double b;
char c;
};
int main() {
Test test;
cout<<sizeof(test);
return 0;
}
输出为24。a在offset为0的位置。#pragma pack默认为8,double类型占8个字节,对齐数取两者最小值为8,所以b对齐至8,占offset为8~15的8个字节。c对齐至16,结构体总大小对齐至各个成员中最大对齐数的整数倍,也就是8,所以整个结构体大小为24。
下面我们将编译器默认的对齐数改为4,
#include <iostream>
using namespace std;
#pragma pack(4)
struct Test{
char a;
double b;
char c;
};
#pragma pack()
int main() {
Test test;
cout<<sizeof(test);
return 0;
}
输出结果为16。a在offset为0的位置。#pragma pack为4,double类型占8个字节,对齐数取两者最小值为4,所以b对齐至4,占offset为4~11的8个字节。c对齐至12,结构体总大小对齐至各个成员中最大对齐数的整数倍,也就是16,所以整个结构体大小为16。
域运算符
C++中增加的作用域标识符::用于对与局部变量同名的全局变量进行访问,或者用于表示类的成员。举个例子:
#include <iostream>
using namespace std;
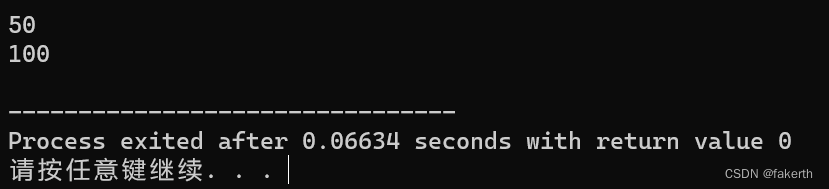
int var = 100;
int main() {
int var = 50;
cout<<var<<endl;
cout<<::var<<endl;
return 0;
}
输出结果为:
new、delete运算符
new运算符可以用于创建堆空间,成功返回首地址,失败抛出异常。声明方式:
#include <iostream>
using namespace std;
int main(){
int* p = new int;//分配一个整数空间,4字节
int* pt = new int(77);//初始化为77,分配一个整数空间,4字节
int* p2 = new int [50];//分配连续的50个整数空间,200字节
delete p;
delete pt;
delete[] p2;
return 0;
}
new一个新对象,首先进行内存分配(operator new),然后调用构造函数。delete释放一个对象,首先调用析构函数,然后进行释放内存(operator delete)。
重载
相同的作用域,如果两个函数名称相同,而参数不同,我们把它们称为重载overload。函数的重载又称为函数的多态性。
函数重载的不同形式有:
1.形参数量不同;
2.形参类型不用;
3.形参的顺序不同;
4.形参数量和形参类型都不同。
调用重载函数时,编译器通过检查实际参数的个数、类型和顺序来确定相应的被调用函数。
举个例子:
#include <iostream>
using namespace std;
void fun(int a,int b){
cout<<"int fun"<<endl;
}
void fun(double a,double b){
cout<<"double fun"<<endl;
}
int main() {
fun(3,4);
fun(3.3,4.4);
return 0;
}
如果返回类型不同而函数名相同、形参也相同,则是不合法的,编译器会报语法错误。
//合法的重载例子
int abs(int i);
long abs(long i);
double abs(double i);
//非法的重载例子
int abs(int i);
long abs(int i);
double abs(int i);
name managling
name managling这里把他翻译成名字改编。C++为了支持重载,需要进行name managling。
//合法的重载例子
int abs(int i);
long abs(long i);
double abs(double i);
比如这三个abs函数,运行时编译器会对其进行名字改编,以便对这三个abs函数进行区分。
extern “C”
extern "C"实现C与C++混合编程。
extern "C" int abs(int i);
extern "C"表示不进行名字改编,按C语言的方式来解释这个函数名,C语言不支持名字改编,也就不支持函数重载,规范使用如下:
#include <iostream>
using namespace std;
#ifdef _cplusplus
extern "C"
{
#endif
void fun(int a){
cout<<a<<endl;
}
void fun2(double a){
cout<<a<<endl;
}
#ifdef _cplusplus
}
#endif
int main() {
fun(7);
fun2(7.7);
return 0;
}
带默认形参值的函数
函数声明或者定义的时候,可以给形参赋一些默认值。调用函数时,若没有给出实参,则按指定的默认值进行工作。
函数没有声明时,在函数定义中指定形参的默认值。函数既有定义又有声明时,声明时指定后,定义就不能再指定默认值 。
默认值的定义必须遵守从右到左的顺序,如果某个形参没有默认值,则它左边的参数就不能有默认值。
void func1 (int a, double b=4.5, int c=3 ) ; //合法
void func1 (int a=1, double b, int c=3 ) ;//不合法
内联函数
当程序执行函数调用时,系统要建立栈空间,保护现场,传递参数以及控制程序执行的转移等等,这些工作需要系统时间和空间的开销。有些情况下,函数本身功能简单,代码很短,但使用频率却很高,程序频繁调用该函数所花费的时间却很多,从而使得程序执行效率降低。
为了提高效率,一个解决办法就是不使用函数,直接将函数的代码嵌入到程序中。但这个办法也有缺点,一是相同代码重复书写,二是程序可读性往往没有使用函数的效果好。
为了协调好效率和可读性之间的矛盾,C++提供了另一种方法,即定义内联函数,方法是在定义函数时用修饰词inline。
内联函数与带参数宏区别
内联函数调用时,要求实参和形参的类型一致,另外内联函数会先对实参表达式进行求值,然后传递给形参;而宏调用时只用实参简单地替换形参。
内联函数是在编译的时候、在调用的地方将代码展开的,而宏则是在预处理时进行替换的。
在C++中建议采用inline函数来替换带参数的宏。
#include <iostream>
using namespace std;
inline int max(int a,int b){
return a > b ? a : b;
}
#define MAX(a,b)((a)>(b)?(a):(b))
int main() {
int a = 1;
int b = 2;
cout<<max(a,b)<<endl;
cout<<MAX(a,b)<<endl;
return 0;
}