【Acwing 周赛复盘】第90场周赛复盘(2023.2.11)
周赛复盘 ✍️
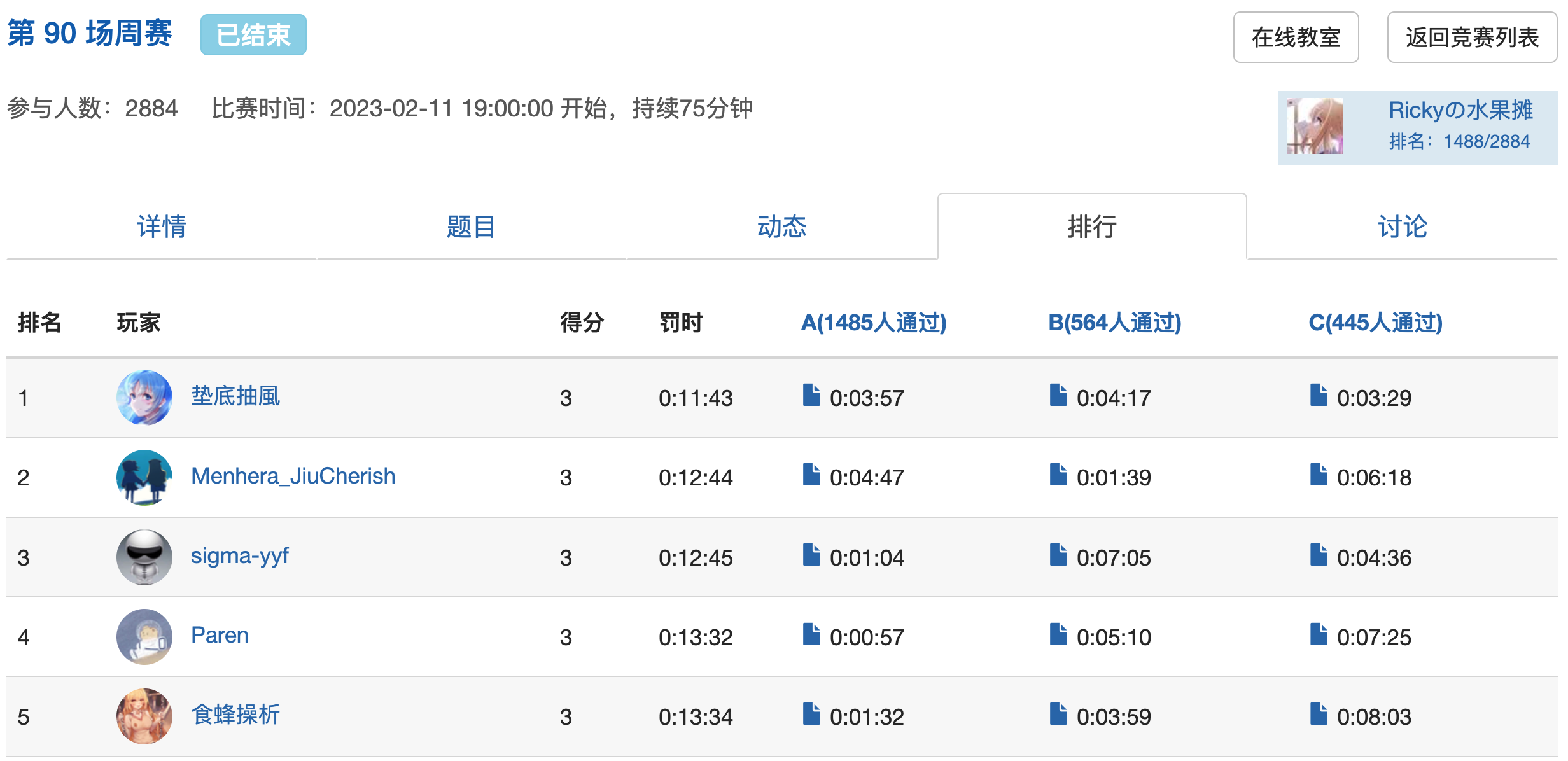
本周个人排名:1488/2884
AC情况:1/3
这是博主参加的第五次周赛,这次做题的时候,感觉题目好难 😂
但是一听y总讲解,又感觉这次题目还是比较简单的,自己为什么就没想出来呢 😭
归根结底,还是自己太菜了,仍需不断努力。💪
T1 签到题,读懂题意即可AC。✅
T2 贪心,但是贪心策略以及边界条件有一些复杂,导致自己写代码时,思路很乱。有一种哪里都能下手,但是哪里又都不能下手的感觉,现场未 AC。❌ (后来看y总讲解后,把思路理清了,就顺利写出了代码)
T3 贪心+字符串,现场经过长时间的推导,发现了贪心策略以及前后缀,但是因为一些小错误(如判断
abcdcba,由于写的是s[i] == s[n-i+1](是判断「首尾对称」的写法,而不是前后缀的判断),导致出现错误),现场未能AC ❌ (经过y总讲解后,觉得有必要学习一下 KMP 的相关内容)
周赛信息 📚
时间:2023年 2 月 11 日 19:00-20:15
竞赛链接:https://www.acwing.com/activity/content/2870/
y总直播间:http://live.bilibili.com/21871779
y总录播讲解视频:【AcWing杯 - 第 90 场周赛讲解】
题目列表 🧑🏻💻
| 题目名称 | 原题链接 | 视频讲解 | 难度 |
|---|---|---|---|
| 4806. 首字母大写 | 原题链接 | 视频链接 | 简单 🟢 |
| 4807. 找数字 | 原题链接 | 视频链接 | 中等 🟡 |
| 4808. 构造字符串 | 原题链接 | 视频链接 | 困难 🔴 |
题解 🚀
【题目A】首字母大写
【题目描述】
给定一个由大小写字母构成的单词。
如果单词的首字母为小写字母,则请你将该首字母转换为对应大写字母。
如果单词的首字母为大写字母,则不做任何变化。
输出最终的单词。
【输入】
一个由大小写字母构成的非空字符串,表示给定单词。
【输出】
输出最终的单词。
【数据范围】
前 3 3 3 个测试点满足,输入单词长度范围 [ 1 , 10 ] [1,10] [1,10]。
所有测试点满足,输入单词长度范围 [ 1 , 1000 ] [1,1000] [1,1000]。
【输入样例1】
ApPLe
【输出样例1】
ApPLe
【输入样例2】
konjac
【输出样例2】
Konjac
【原题链接】
https://www.acwing.com/problem/content/4809/
【题目分析】
签到题,使用 toupper() 函数 或者 s[i] - 32 的形式都可以。
【周赛现场 AC 代码】
#include<bits/stdc++.h>
using namespace std;
string s;
int main() {
cin >> s;
// 转换首字母
if (s[0] >= 'a' && s[0] <= 'z') s[0] = s[0] - 32;
// s[0] = toupper(s[0]);
cout << s << endl;
return 0;
}
【题目B】找数字
【题目描述】
给定一个正整数 m m m 和一个非负整数 s s s。
请你找到长度为 m m m 且各位数字之和为 s s s 的最小和最大 非负 整数。
要求所求非负整数不得包含前导零。
【输入】
共一行,两个整数 m , s m,s m,s。
【输出】
在一行内输出满足条件的最小和最大 非负 整数。
如果无解,则输出 -1 -1。
【数据范围】
前 6 6 6 个测试点满足 1 ≤ m ≤ 3 1 \le m \le 3 1≤m≤3。
所有测试点满足 1 ≤ m ≤ 100 1 \le m \le 100 1≤m≤100, 0 ≤ s ≤ 900 0 \le s \le 900 0≤s≤900。
【输入样例1】
2 15
【输出样例1】
69 96
【输入样例2】
3 0
【输出样例2】
-1 -1
【原题链接】
https://www.acwing.com/problem/content/4810/
【题目分析】
贪心
该题的贪心策略还是比较好想的,但是从 「贪心策略 → 具体代码」 的实现其实还是比较难的,需要考虑一些边界条件(如果是第一次做这种类型的题目的话)
【复盘后的优化代码】✅
#include<bits/stdc++.h>
using namespace std;
int main() {
ios::sync_with_stdio(false); //cin读入优化
cin.tie(0);
int sum, m;
cin >> m >> sum;
// m位数之和最大为 9 * m,若sum>9*m,无解
// sum为0时,m位数大于1,也无解
if (sum > 9 * m || sum == 0 && m > 1) cout << "-1 -1" << endl;
else {
// 创意长度为m,内容均为' '的字符串,下标从0开始
string a(m, ' '), b(m, ' ');
// 求最大值(高位尽可能放大的数)
int tmp = sum;
for (int i = 0; i < m; i++) {
int t = min(9, tmp);
a[i] = t + '0';
tmp = tmp - t;
}
// 求最小值(第一位起码最少是1)
// 从最后一位开始,从大数开始填
for (int i = m - 1; i > 0; i--) {
int t = min(9, sum - 1); // 可以以样例为例子来理解
b[i] = t + '0';
sum = sum - t;
}
b[0] = sum + '0';
// 输出结果
cout << b << " " << a << endl;
}
return 0;
}
【周赛现场 AC 代码】
周赛现场未 AC
【题目C】构造字符串
【题目描述】
给定一个长度为 n n n 的由小写字母构成的字符串 t t t 以及一个整数 k k k。
请你构造一个字符串 s s s,要求:
- 字符串 s s s 恰好有 k k k 个子串等于字符串 t t t。
- 字符串 s s s 的长度尽可能短。
保证一定存在唯一解。
【输入】
第一行包含两个整数 n , k n,k n,k。
第二行包含一个长度为 n n n 的由小写字母构成的字符串 t t t。
【输出】
输出满足条件的字符串 s s s。
保证一定存在唯一解。
【数据范围】
前 3 3 3 个测试点满足 1 ≤ n , k ≤ 4 1 \le n,k \le 4 1≤n,k≤4。
所有测试点满足 1 ≤ n , k ≤ 50 1 \le n,k \le 50 1≤n,k≤50。
【输入样例1】
3 4
aba
【输出样例1】
ababababa
【输入样例2】
3 2
cat
【输出样例2】
catcat
【原题链接】
https://www.acwing.com/problem/content/4811/
【题目分析】
贪心 + 前后缀
贪心策略比较容易想到,最差的情况就是把 k 个原字符串排列在一起,能够优化的情况就是相邻的两个原字符串存在重叠部分(即前缀和后缀是相同的)
前后缀 概念的举例说明:字符串
abcXXXXabc的前缀abc和后缀abc是相等,长度为3。
因此,需要找到长度最大的,相同的前缀和后缀,然后再进行输出即可。
判断 前后缀相同 的方法:
- KMP 算法
str.substr(0,cnt) == str,substr(cnt-n,cnt)判断式枚举
🍉 PS 1:前后缀长度不能为 str.length,即原字符串长度。否则会出现 「前缀 = 后缀 = 本身」的情况,这个对于任何字符串都是成立的。
🍉 PS 2:「前后缀相等」的判断不能和 「前后缀对称」 的判断搞混。比如,字符串 abcXXXcba 应该是前缀和后缀对称的情况,而非相等的情况。前者是用 KMP 算法 或者 str.substr(pos,length) 来对比,后者是用 str[i] == str[n - i + 1] 的方式来判断。
🍉 PS 3:该题在枚举长度时,不能用「二分」来做,因为不满足「二段性」。如字符串 abcXXXabc,此时长度为 3,前缀后缀均为 abc,满足条件,因此需要继续找长度更大的;但是在长度为 2 时,前缀 ab 和 后缀 bc 不同,此时既要往长度大的找(如上面长度为 3 时就满足),又要往长度小的找(因为长度更大的可能全部不满足),所以不具有二段性。
【复盘后的优化代码】✅
substr(pos,len)前后缀暴力枚举对比
#include<bits/stdc++.h>
using namespace std;
int n, k;
string str;
int main() {
cin >> n >> k;
cin >> str;
// 统计前后缀的长度
int cnt = 0;
for (int i = 1; i <= n - 1; i++) { // 前后缀长度不能为n,不然前缀=后缀=本身
if (str.substr(0, i) == str.substr(n - i, i))
cnt = i;
}
// 输出结果
// 先输出第一个字符串
for (int i = 0; i < n; i++) cout << str[i];
// 在后面拼接k-1个字符串
for (int i = 1; i <= k - 1; i++) {
for (int j = cnt; j < n; j++) {
cout << str[j];
}
}
// 上面的输出代码可以优化
// cout << str; // 先输出1个完整的str
// 再输出k-1个子串,str.substr(cnt) 表示输出从下标cnt开始的到结尾的子串
// for (int i = 1; i <= k - 1; i++) cout << str.substr(cnt);
return 0;
}
在数据范围更加大的题目中,使用 KMP 算法是更好的选择。
- KMP 算法计算前后缀(y总代码)
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 55;
int n, m;
char str[N];
int ne[N];
int main()
{
scanf("%d%d", &n, &m);
scanf("%s", str + 1);
for (int i = 2, j = 0; i <= n; i ++ )
{
while (j && str[i] != str[j + 1]) j = ne[j];
if (str[i] == str[j + 1]) j ++ ;
ne[i] = j;
}
printf("%s", str + 1);
for (int i = 0; i < m - 1; i ++ )
printf("%s", str + 1 + ne[n]);
return 0;
}