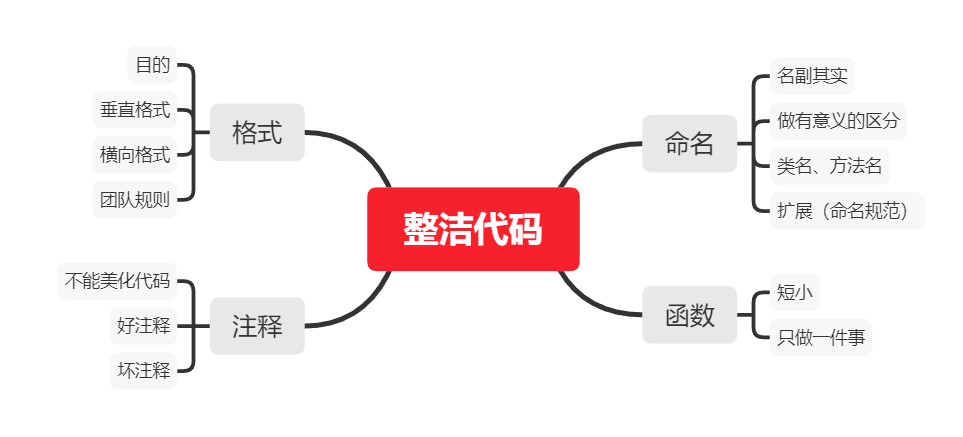
特征衍生
- 1. 单变量特征衍生
- 1.1 数据重编码
- 1.2 高阶多项式
- 2. 双变量特征衍生
- 2.1 四则运算
- 2.2 多项式衍生
- 2.2.1 导包 & 数据
- 2.2.2 二阶衍生
- 2.2.3 三阶衍生
- 3. 交叉组合
- 3.1 导包 & 数据
- 3.2 生成衍生列和名称
- 3.3 独热编码
1. 单变量特征衍生
1.1 数据重编码
- 连续变量
标准化:0-1标准化、Z-Score标准化
离散化:等距分箱、等频分箱、聚类分箱 - 离散变量
非数值->数值:自然数编码、字典编码
列->新列:独热编码、哑变量变换
1.2 高阶多项式
- 原理
X >>> X2、X3、X4 … … - 代码实现
可以手动实现,也可利用sklearn中的PolynomialFeature评估器实现。
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
x1 = np.array([1, 2, 3])
# (3,) >>> (3,1)
x1.reshape(-1, 1)
'''
array([[1],
[2],
[3]])
'''
# 1次方到5次方
PolynomialFeatures(degree=5).fit_transform(x1.reshape(-1, 1))
'''
array([[ 1., 1., 1., 1., 1., 1.],
[ 1., 2., 4., 8., 16., 32.],
[ 1., 3., 9., 27., 81., 243.]])
'''
2. 双变量特征衍生
2.1 四则运算
X1, X2 >>> X1+X2, X1-X2, X1*X2, X1/X2
2.2 多项式衍生
2.2.1 导包 & 数据
from sklearn.preprocessing import PolynomialFeatures
import pandas as pd
df = pd.DataFrame({'X1':[1,2,3], 'X2':[2,3,4]})
df
'''
X1 X2
0 1 2
1 2 3
2 3 4
'''
2.2.2 二阶衍生
'''
多项式衍生
X1,X2 >>> X1,X2 | X1^2,X1*X2,X2^2
X1,X2,X3 >>> X1,X2,X3 | X1^2,X1*X2,X1*X3,X2^2,X2*X3,X3^2
include_bias 默认True,包含特征的0次方
interaction_only 默认False,True则只创建交叉项
'''
PolynomialFeatures(degree=2, include_bias=False).fit_transform(df)
'''
array([[ 1., 2., 1., 2., 4.],
[ 2., 3., 4., 6., 9.],
[ 3., 4., 9., 12., 16.]])
'''
2.2.3 三阶衍生

'''
X1,X2 >>> X1,X2 | X1^2,X1*X2,X2^2 | X1^3,X1^2*X2,X1*X2^2,X2^3
'''
PolynomialFeatures(degree=3, include_bias=False).fit_transform(df)
'''
array([[ 1., 2., 1., 2., 4., 1., 2., 4., 8.],
[ 2., 3., 4., 6., 9., 8., 12., 18., 27.],
[ 3., 4., 9., 12., 16., 27., 36., 48., 64.]])
'''
创建特征的同时创建列名称
df = pd.DataFrame({'X1':[1,2,3]
,'X2':[2,3,4]
,'X3':[1,0,0]})
df
'''
X1 X2 X3
0 1 2 1
1 2 3 0
2 3 4 0
'''
# 选取X1、X2进行三阶衍生
colNames = ['X1', 'X2']
degree = 3
colNames_new = []
# 生成新列名
for deg in range(2, degree+1):
for i in range(deg+1):
col_temp = colNames[0] + '^' + str(deg-i) + '*' + colNames[1] + '^' + str(i)
colNames_new.append(col_temp)
colNames_new
'''
['X1^2*X2^0',
'X1^1*X2^1',
'X1^0*X2^2',
'X1^3*X2^0',
'X1^2*X2^1',
'X1^1*X2^2',
'X1^0*X2^3']
'''
3. 交叉组合

3.1 导包 & 数据
df = pd.DataFrame({'SeniorCitizen':[0,0,0,0,0]
,'Partner':['Yes','No','No','No','No']
,'Dependents':['No','No','No','No','No']})
df
'''
SeniorCitizen Partner Dependents
0 0 Yes No
1 0 No No
2 0 No No
3 0 No No
4 0 No No
'''
3.2 生成衍生列和名称
colNames = ['SeniorCitizen', 'Partner', 'Dependents']
colNames_new_l = []
features_new_l = []
for col_index, col_name in enumerate(colNames):
print(col_index, col_name)
'''
0 SeniorCitizen
1 Partner
2 Dependents
'''
# 衍生列名称
for col_index, col_name in enumerate(colNames):
for col_sub_index in range(col_index+1, len(colNames)):
newNames = col_name + ' & ' + colNames[col_sub_index]
print(newNames)
'''
SeniorCitizen & Partner
SeniorCitizen & Dependents
Partner & Dependents
'''
# 衍生列名称及特征本身
for col_index, col_name in enumerate(colNames):
for col_sub_index in range(col_index+1, len(colNames)):
newNames = col_name + '&' + colNames[col_sub_index]
colNames_new_l.append(newNames)
newDF = pd.Series(df[col_name].astype('str')
+ '&'
+ df[colNames[col_sub_index]].astype('str')
,name=newNames)
features_new_l.append(newDF)
features_new = pd.concat(features_new_l, axis=1)
features_new
'''
SeniorCitizen&Partner SeniorCitizen&Dependents Partner&Dependents
0 0&Yes 0&No Yes&No
1 0&No 0&No No&No
2 0&No 0&No No&No
3 0&No 0&No No&No
4 0&No 0&No No&No
'''