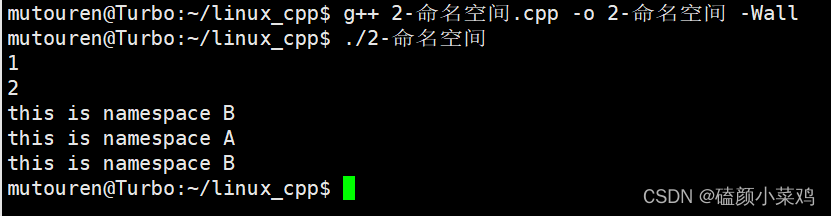
学习资料: 数据分析学习随记 | 互联网金融行业2C授信模型(芝麻信用)
1. 背景
互联网金融的本质是风控。
1.1 数据分析师的角色
数据分析师在金融行业基本上有两种角色:
1.1.1 数据建模师
偏算法,但要很懂业务。要求对算法的理解较深,相对来说对行业经验要求不是很高。
与纯互联网行业对比,金融行业的数据建模师的价值更容易得到体现,而且相对更有趣。
- 工作内容:
- 数据源
这是和其他数据分析师差别最大的地方。 互联网金融很多时候需要基于大数据去规避风险,数据源越多越好。因此数据建模师需要和其他公司进行数据合作,或者数据采购。 - 信用评分模型
模型监控、维护、优化迭代 - 其他数据挖掘建模
- 数据源
- 能力要求:
- 数据源在前期决定了模型的效果,要具备良好的沟通能力和快速反馈的能力。
- 金融行业本身比较成熟,比模型更加重要的是分析师自身的想法和验证。
- 在前期重点是围绕数据源和数据处理,模型可以用逻辑回归、决策树、GBDT、随机森林、神经网络等。
1.1.2 分控分析师
除了一定的模型理解能里,还需要大量的行业和法律法规经验。
1.2 产品对象
互联网金融与其他行业不太一样,互联网金融在产品对象上分为to B和to C,都是依赖央行信用报告。
- to B:对企业整体的信用进行评估,做整体授信
- to C:对个人整体的信用进行评估,得到个人信用分
2. 授信模型
以芝麻信用分为例,
- 能够很好地判断一个人的信用到底好不好
- 另一个潜在价值是可以结合人的行为偏好来做更准确的推荐。
芝麻信用分是以下面五个维度综合评估而来的:

- 身份特质-- 稳定性
学历的高低影响了收入的多少,这是长时间改不了的特质。 - 履约能力-- 兜底性
有无房车,个人资产能力的证明,消费后按时还款的能力。 - 信用历史 – 历史性
信用卡有无逾期,历史行为最直接的信用体现。 - 人脉关系 – 稳定性验证 + 弱价值性
支付宝好友的信用分是不是都很高,是否土豪,一个人的交际圈也代表着一定的偿还能力。 - 行为偏好-- 真正价值
喜欢买价格高的还是买价格低的,这个部分很重要,表示人本身的当前信息,对产品后续决策有非常大的价值。
3. 模型落地
授信模型的建立过程跟数据分析标准化流程非常像,模型最终的评估指标是坏账率。
3.1 数据源
每个维度用了哪些数据字段,这些就是数据源。
数据变量:
- 原始变量:直接存储在数据库中的最基础变量,比如每天的交易额。
- 衍生变量:因为金融的本质是风险,所以都要对原始变量进行加工转化,得到衍生变量。
一般有3种方式对原始变量进行扩充:
- 时间维度衍生:
- 最近一个月交易额
- 最近三个月交易额
- 函数衍生:
- 最大交易额
- 最小交易额
- 交易额方差比例
- 比例衍生:
- 最近一个月交易额除以最近三个月交易额
选择变量时,基于RFM原则:
- R(Recency,最近,最近一次消费时间间隔):指用户最近一次消费距离现在多长时间了。
- F(Frequency,频次,一段时间内的消费频次):指用户一段时间内消费了多少次。
- M(Monetary,钱,一段时间内的消费金额):指用户一段时间内消费的金额。
3.2 数据处理 => 数值化
数据处理、数据建模都是为业务服务。真实工作中,数据据处理和数据建模会慢慢迭代、优化。
所以在前期的数据处理不会很复杂,
前期的数据处理一般分为三种:
-
数值型和字符串型字段的缺失性和合理性检验,剔除无效字段。
50%以上即可去掉。 -
数值型字段的相关性验证
因为在前期,所有的字段都会拿出来,有很多的变量相关性非常强,但这个对于模型的训练没有帮助,因此把相关性强的先过滤掉。 【相关性规律待学】 -
对字符串型字段的离散化处理
一般对字符型字段采用的是专家打分法,将字符串型变量转化成数值。
相关性过滤:一般0.7以上是高度相关性,所以在后面建模的时候,只保留一个变量即可,其他3个相关性高于0.7的变量先不要放在模型训练里。
如下图,最近1年母婴消费金额与其他三个变量均有很高的相关性,因此在后续建模的时候先保留母婴消费金额.

专家打分法:是按照常识理解直接分段取值。
在模型前期,只要大的逻辑没有问题即可。比如芝麻信用分评估中的身份特质,学历是小学还是博士,这样的字段不是数字型字段而实字符串型字段。然后设定小学学历信用分段是0~20, 博士学历信用分段90~100,将字符型变量转化成数值。

3.3 数据标准化
虽然所有变量都以数值化,但在量级和量刚上相差很大。
【?】如交易额和交易次数,这就没有可以性,所以要对所有的字段进行标准化。
标准化的方法很多,选择合适的就行,这对后面的模型效果没有影响
- MAX-MIN
- Z-score
【?】数据标准化后,所有变量的取值区间都会在0~1范围,接下来就可以进行数据建模了。
3.4 数据建模
在建模之前,一定要把业务目标理清,这样才能知道能用什么模型。
芝麻信用分有5个维度,5个维度在不同时期的权重也不一样,所以每个维度都要单独建模。
建模前的思考举例:
- 业务目标:根据用户在5个维度的综合芝麻分,来给用户提供其他额外服务,比如花呗、借呗和免押金,同时保证用户不违约。
- 建模目标:根据用户的数据,算出用户违约的概率。而这个概率也可以转化为用户的分数。
- 模型选择:基于建模目标,选择逻辑回归模型比较合适。一是简单,二是非线性。

以历史信用为例,假设该模块包含的字段有最近一个月主动查询金融机构信用次数x1、最近一个月徐换代总额x2、最近一个月逾期总额x3,那么其违约概率就为:(x1、2、3为3个数值)

P值为用户违约的概率,a、b、c为拟合系数。
举例:A用户:身份特质、履约能力、信用历史、人脉关系、行为偏好分别算出的概率是0.1、0.2、0.3、0.4、0.5 。根据当前产品所处阶段,觉得历史信用和履约能力两个模块最重要,那么这两个模块的影响权重就是0.35,其他都是0.1。计算步骤:
- 那么小A 的违约概率就是: P = 0.10.1+0.350.2+0.350.3+0.10.4+0.1*0.5=275
- 分数公式:score=(1-P)*A+B,区间为[300,900],可以算出来A=600,B=300
- 所以A的芝麻综合分=0.725*600+300=735。
模型离线效果指标: 机器学习
- 混淆矩阵:查准率和查全率

-
混淆矩阵的理解:
- 100:本身是未还款,模型预测后也是未还款 - 准确
- 400:本身是已还款,模型预测后也是已还款 - 准确
- 20:本身是已还款,模型预测后是未还款 - 不准确
- 80:本身是未还款,模型预测后是已还款 - 不准确
-
查准率: 模型准确度。
- 预测准确准确的对角线100+400 = 500
- 所有样本量100+20+80+400 = 600
- 查准率 = 500 / 600 = 83%
-
查全率:预测准确的样本,在选择样本中的占比。
金融模型的主要目标是还款,所以只需看预测成功的未还款人数,在实际的总未还款人数中的占比。- 模型预测准确的未还款人是100人
- 本身未还款100 + 80 = 180人
- 查全率是100/180 = 56%
-
- ROC曲线:根据混淆矩阵做出的可视化分析,区分模型是否能较好把好坏样本分开的一个图,一般都是取ROC下面的面积AUC,来衡量模型效果,越大越好,一般至少0.6以上。
离线模型看这两个参数就够了,这块本身有点难理解,特别是ROC曲线不太好举例,如果你实在不理解参数意义,那么记住也可以,因为真实工作中,最重要的还是坏账率这个评估指标。
在产品初期,因为模型的变量太多,所以模型的迭代速度都非常快,基本上每个月都要跑一次分数,这个时候肯会出现某个用户的分数奇高,这都是正常的,而这些都需要不断调整权重和系数,慢慢优化才行,不过最重要的还是落地效果,就是用了这个模型之后坏账率怎么样,这就是模型落地了 。
3.5 模型落地
模型落地举例
-
落地前:
如根据芝麻信用分就可以申请招联金融信用额度,那么这就涉及到两个公司的产品合作了。金融行业的合作都是非常小心的,所以在正式合作前:- ①招联金融会提供一批样本给芝麻,芝麻这边数据建模师根据模型给出这批用户的违约概率;
- ②招联金融根据芝麻给出的用户违约概率,算模型的准确度;
- ③如果模型准确度还可以,双方才会正式展开合作(用户群覆盖度和模型准确度)
-
落地中:
正式落地时,招联在给每个用户评估信用时,实际上芝麻信用分只是一个参考维度而已,一般都是这样:- ①机器调用该用户的央行征信报告评估值X,这个是最重要的;
- ②借口调用用户的芝麻信用分Y;
- ③该用户在招联的信用评估情况Z;
基于X,Y,Z,内部在根据专家规则法出一套授权方案(很灵活),到这一步,基本上模型就正式使用了。
3.6 模型优化
- 落地后:
前期一般是每一周,招联金融都会和芝麻这边对一次坏账情况,只有到这个时候,模型的参数调整才是最有意义的,这个时候也是最考验数据建模师的时候,
调参方法:
- ①先找出是因为某个子模型引起还是所有模型引起;
- ②如果是子模型引起,直接调整该模型的参数即可,如果是整体模型都有问题,那就要重新进行数据处理了,如WOE分组,更换衍生变量,字符型字段重新打分等等。