此文为《精通机器学习:基于R》的学习笔记,书中第九章详细介绍了无监督学习-主成分分析(PCA)的分析过程和结果解读。
PCA可以对相关变量进行归类,从而降低数据维度,提高对数据的理解。分析的主要目的一般是:1)识别数据集中的潜在变量,2)通过去除数据中的噪声和冗余来降低数据的维度,3)识别相关变量。
随着变量数量的增加,模型估计所需的样本数量呈指数增长(维数灾难)。过多的变量中,某些变量可能彼此关联,最后起到的作用是一样的。PCA分析可以对相关变量进行归类,从而得到一个更小的,但保留原来大部分信息的变量集合。这些新的变量(主成分,PC)的彼此高度不相关,可继续用于监督式学习和可视化。
本章包含一下内容:1) 数据准备;2) 执行PCA分析;3) 选择主成分;4) 使用主成分构建模型;5) 使用模型预测数据。
此文为PCA详解第一部分,只进行各种不同PCA方法的比较和主成分选择。
一、 PCA简介
PCA分析之后我们会得到主成分、主成分特征根以及变量(特征)得分,那么这些分析结果是怎么得到的呢?以及它们各自代表什么意义呢?带着这些疑问,我们可以开始学习此章节。
主成分其实是分析用变量的规范化线性组合。PC1是能够最大程度解释数据中的方差的特征线性组合。PC2是另一种特征线性组合,其在保持与PC1方向上垂直(PC1与PC2完全不相关)的情况下,最大程度解释数据中的方差。PCA分析最多可以构造与变量数相等的PC(要求样本/观测数必须大于变量数)。PC3…PCn都遵循这个规则。

图1|二维空间主成分示意图。摘自《统计学:从数据到结论》 4d[吴喜之]。标准化数据每个变量都具有1方差,变量方差和正是变量数目。PCA分析对数据量度是敏感的,所以最好对数据进行标准化处理(均值为0,方差为1)。
基于线性组合这一假设,PCA可以算作一个线性模型,因此数据应该满足两个前提:1)变量间不应该毫无相关性,否则起不到降维效果;2)数据应该服从多元正态分布。但书中也提到PCA分析对非正态分布数据具有相当强的稳健性,二值变量设置也可以一起使用。现在也有R包可以进行混合结构数据PCA分析(FAMD/MFA)。
下面使用数据,介绍PCA的分析过程,FAMD/MFA后面再写。
二、 数据准备
此数据为虚构,可用于练习,请不要作他用。
2.1 数据导入
# 1.1 设置工作路径
#knitr::opts_knit$set(root.dir="D:\\EnvStat\\PCA")# 使用Rmarkdown进行程序运行
Sys.setlocale('LC_ALL','C') # Rmarkdown全局设置
#options(stringsAsFactors=F)# R中环境变量设置,防止字符型变量转换为因子
setwd("D:\\EnvStat\\PCA")
# 数据导入
data <- read.csv("env.csv", header = T, row.names = 1)
dim(data)
## [1] 36 14
head(data) # 3个分类变量,11个数值变量。

图2|环境因子及分组信息表,env.csv。行为样品名称,列为环境因子名称和分组信息,共有11个环境变量,3个分组信息。
2.2 数据探索
library(rstatix)
library(ggplot2)
library(viridis)
library(dplyr)
library(tidyverse)
# 2.2.1 分组数据描述统计
##统计结果包括:中位数,均值,四分位数,中位数绝对偏差,标准差、标准误和置信区间等
data %>%
group_by(condition) %>%
get_summary_stats() 
图3|数据描述统计。
# 2.2.2 数据分布可视化
data[-c(1:3)] %>%
map(scale) %>% # 数据标准化
data.frame() %>%
gather(key = "features",value = "value") %>%
group_by(features) %>%
ggplot(aes(value,color=features))+
geom_density()+
theme_bw()
图4|数据分布可视化。
# 2.2.3 多元正态分布检验
data %>%
select(names(data[-c(1:3)])) %>%
mshapiro_test() %>%
p.adjust() # p<0.05,数据不满足多元正态分布。可以换其他方法,也可以继续进行PCA分析。
## statistic p.value
## 6.301624e-01 5.323599e-08# 2.2.4 pearson相关性分析
cor <- data %>%
select(names(data[-c(1:3)])) %>%
cor(.,method = "pearson")
cor
图5|pearson相关性矩阵。
# 2.2.5 Bartlett's test of sphericity(球形检验)
library(psych)
cor %>%
cortest.bartlett(.,n=nrow(data)) # p<0.05变量间相关,可用于因子或主成分分析。
## $chisq
## [1] 508.746
##
## $p.value
## [1] 1.00108e-74
##
## $df
## [1] 55# 2.2.6 Kaiser-Meyer-Olkin Measure of Sampling Adequacy(KMO采样充分性检验)
cor %>%
psych::KMO() # 根据Kaiser提出的经验原则,变量适合性处于一般到良好。
## Kaiser-Meyer-Olkin factor adequacy
## Call: psych::KMO(r = .)
## Overall MSA = 0.74
## MSA for each item =
## TN TP TK Nitrate Ammonia AHN AP AK pH OM
## 0.72 0.76 0.62 0.76 0.57 0.86 0.70 0.89 0.84 0.71
## OC
## 0.71R统计绘图-PCA分析绘图及结果解读(误差线,多边形,双Y轴图、球形检验、KMO和变量筛选等)
三、 R实现PCA分析
解相关数据矩阵的方法有多种,这里介绍两种:1)eigen(),2)svd()。相同数据,使用不同方法,解矩阵特征值结果没有差异。princomp()和principal()使用eigen()分解相关性或协方差矩阵,FactoMineR包的PCA()、vegan::rda()和prcomp则使用svd(),可以同时解对称矩阵或原始数据矩阵。
R中不同函数的PCA分析结果可能有细微的差异,可能是因为计算方差或标准差过程中除以N或除以N-1的差异、某些参数设置不同、使用不同的载荷表或结果标准化方法不同导致的。这对分析结果的整体趋势一般没什么影响。不过分析时,各参数设置还是保持一致比较好。
下面介绍R中几种常用的PCA分析函数,并比较输出结果的异同。
3.1 PCA示例-eigen()
# 3.1.1 eigen()逐步主成分分析
pca0 <- eigen(cor) # 需使用相关性矩阵或协方差矩阵。
pca0$values # eigenvalues,特征值。
head(pca0$vectors) # eigenvectors,单位特征向量,即变量与主成分的线性组合回归系数(系数权重)。
sum(pca0$vectors[,1]^2) # 每个主成分各变量的回归系数平方和为1,可用于计算样本得分。
# 3.1.2 特征值分析
## 主成分方差贡献率
eig0 <- data.frame(
eigenvalue =pca0$va,
variance.percent = pca0$va/sum(pca0$va),
cumulative.variance.percent = cumsum(pca0$va)/sum(pca0$va)
)
eig0


图6|eigen()分解相关矩阵结果。
## Scree plot(悬崖碎石图)
plot(x=1:11,y=eig0[,1],type = "b",main="Scree plot",ylab = "Eigen Value",xlab ="Component Number" )
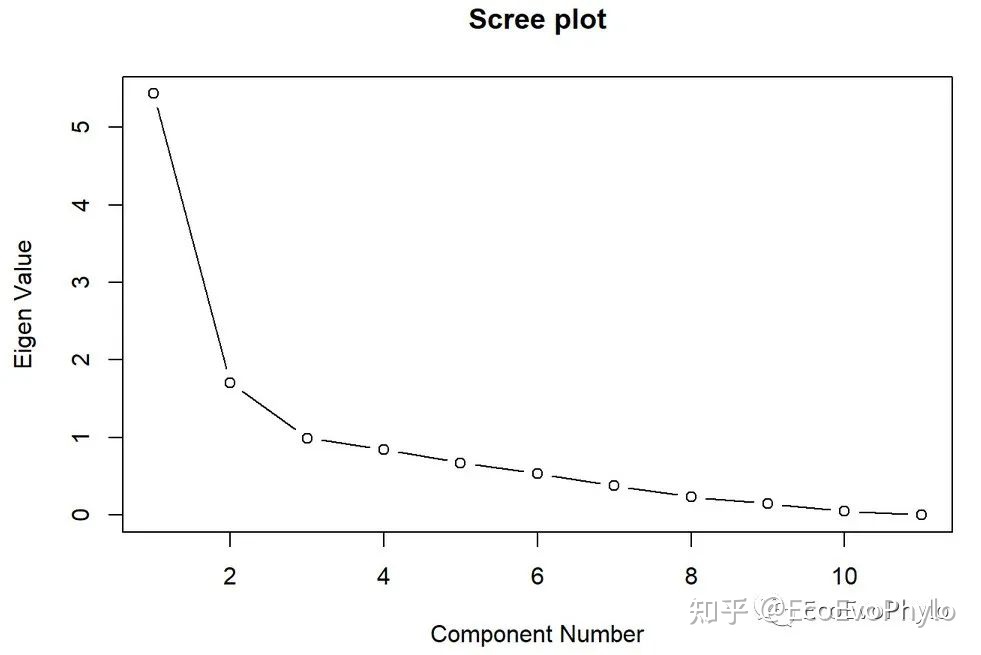
图7|特征值碎石图。前两个主成分代表了大多数方差,那么,该图开始部分很陡,其它主成分就像悬崖落下的碎石一样基本接近地面,这也表示选取主成分的一个原则。碎石图如果是一个缓斜坡,说明降维效果不好,应该剔除不能被代表的变量,重新降维。后续进行构建模型等分析时,不能降维的变量,应该使用其原始数据。对互相正交的变量进行主成分分析,得到的特征值均等于1,这意味着所有成分同等重要。在变量多的时候,容易出现不易解释主成分或因子。特征值就是每个变量的主轴长度,即相应方向的方差,表示所能代表的变量方差数量。选择越少的主成分,降维效果越好。
## 累积特征值比例图
plot(x=1:11,y=eig0[,3],type="b",main="Cumulative Eigen Value (Ratio)",
xlab="Component Number",ylab="Cumulative Eigen Value (Ratio)")
图8|累积特征值比例图。
特征值就是每个变量的主轴长度,即相应方向的方差,表示所能代表的变量方差数量。选择越少的主成分,降维效果越好。那么主成分选择的标准是什么呢?选择的主成分所代表的主轴的长度之和占了主轴长度总和的大部分(≥70%,80%以上更好)即可。但如果所有涉及的变量都不那么相关,就很难降维,不相关的变量就只有自己代表自己了。
主成分是原始变量的线性组合,那么多维变量是如何组合的呢?这里需要输出载荷表(Component Matrix),注意,不同软件输出的载荷表可能形式不同。一种使用的是变量与主成分的回归系数(单位特征向量);一种使用的是变量与主成分的相关系数(这里称为特征向量(eigenvector)以示区分)。这里的特征向量是单位特征向量乘以相应特征值的平方根,因而有了变量和主成分的相关系数的意义。本文以下将(单位)特征向量用回归系数和相关系数进行区分。
# 3.1.3 变量载荷
## 回归系数载荷表(Component Matrix)
reg.loadings <- pca0$ve
colnames(reg.loadings) <- paste("PC",1:11,sep = "")
rownames(reg.loadings) <- colnames(data[-c(1:3)])
write.csv(reg.loadings,"reg.loading.csv",quote = FALSE)
图9|回归系数载荷表(Component Matrix),reg.loading.csv。
## 计算相关系数载荷表(Component Matrix)
cor.loadings <- sweep(pca0$ve,2,sqrt(pca0$va),"*")
colnames(cor.loadings) <- paste("PC",1:11,sep = "")
rownames(cor.loadings) <- colnames(data[-c(1:3)])
cor.loadings[,1] # 变量与PC1的相关系数
## TN TP TK Nitrate Ammonia AHN AP
## 0.9055448 0.6169696 0.2585073 0.5524954 0.4485385 0.7733147 0.8658737
## AK pH OM OC
## 0.6008377 -0.7542129 0.8319618 0.8316644
write.csv(cor.loadings,"cor.loading.csv",quote = FALSE)
图10|相关系数载荷表(Component Matrix),cor.loading.csv。
pdf("Component.pdf",family = "Times",width = 12,height = 6)
## 回归系数载荷图:同一PC的回归系数的平方和为1。
par(mfrow=c(1,2))
plot(pca0$ve[,1:2],type = "n",main = "Loading Plot",
xlab = "PC1",ylab = "PC2")
abline(h=0);abline(v=0);text(pca0$ve[,1:2],names(data[-c(1:3)]))
## 相关系数载荷图用于直观的显示主成分如何代表原来的变量。
plot(cor.loadings[,1:2],type = "n",main = "Loading Plot",
xlab = "PC1",ylab = "PC2")
abline(h=0);abline(v=0);text(cor.loadings[,1:2],names(data[-c(1:3)]))
dev.off()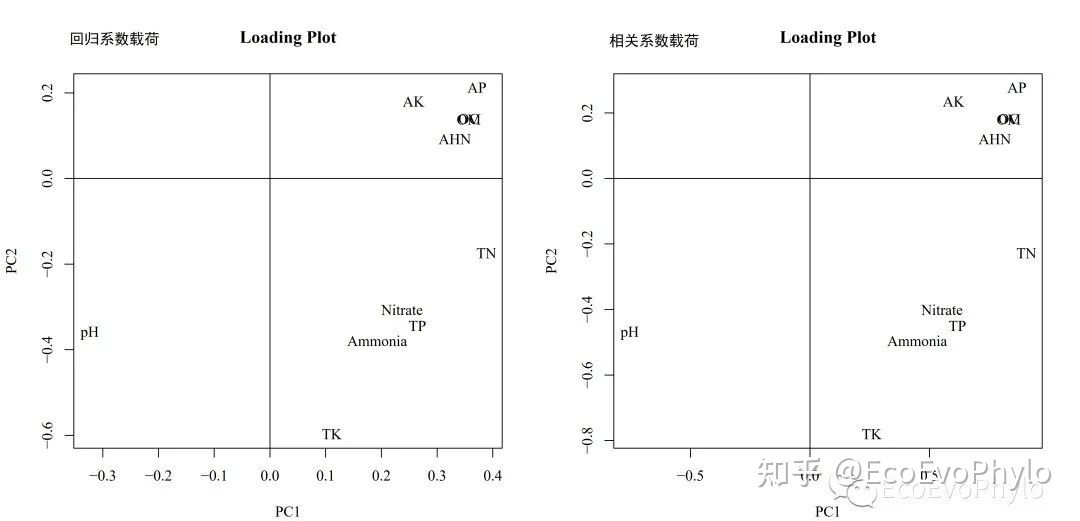
图11|变量载荷图(Component Matrix),Component.pdf。除了坐标范围变化为,变量相对位置是没有变化的,特征向量乘以一个常数都还是特征向量,结果不会有差别。AHN、TN和AP等与PC1正相关,即第一主成分越大(正值大),则TN含量越大,可以认为这是高营养的象征。PC1与pH负相关,即第一主成分小(负值绝对值大),则pH越高,这是高pH象征。也就是第一主成分正方向越大,土壤可能综合肥力越高。[以上只是载荷图解读示例,不代表真实情况]。
主成分(即新变量)是数据中变量的线性组合,载荷表中数据即为主成分载荷(loading),作为系数与变量观测值相乘,得到样本得分(score)。

注意,不同软件或函数计算样本得分的方法可能不同,结果可能会有差异,但大趋势应该是一样的。由计算公式可以看出,导致样本得分差异的主要是变量载荷(α)和原始数据(Xi),有些变量载荷使用的是回归系数,有些使用的是相关系数。两者的绘图结果显示,除了坐标范围变化外,变量相对位置是没有变化的,特征向量乘以一个常数还是特征向量,结果不会有差别。这种区别对分析结果不会造成不同,但是单位特征向量不是相关系数。原始数据也可能不一样,有些使用的是标准化后数据,有些使用的只是中心化后的数据,想要知道具体的计算过程,请查看函数的说明文档或代码。
即,使用回归系数载荷,第一个样本的PC1观测值计算公式:

此处使用变量载荷线性组合形成主成分(新变量)时,使用的是标准化后的变量数据,非标准化数据,计算时变量需要减去其均值。-0.3235044表示pH与PC1的回归系数。一般情况下,使用最多的是回归系数,它虽不能代表真正的相关系数值,但是两者是等比的,回归系数载荷的绝对值越大,其与主成分越相关,主成分越能代表该变量。
# 3.1.4 样本得分,使用标准化原始数据,用于查看各样本在载荷图中的位置:
d.scale <- as.matrix(scale(data[-c(1:3)])) # 标准化原始变量
head(d.scale)
## 回归系数样本得分
### %*%表示计算内积,crossprod(t(d.scale),pca0$ve)。
sa0.reg <- d.scale%*%reg.loadings
head(sa0.reg)
write.csv(sa0.reg,"sa0.reg.csv",quote = FALSE)
## 相关系数样本得分
sa0.cor <- d.scale%*%cor.loadings
head(sa0.cor)
write.csv(sa0.cor,"sa0.cor.csv",quote = FALSE)
pdf("scores.pdf",family = "Times",height = 6,width = 12)
par(mfrow=c(1,2))
## 回归系数样本得分图
plot(sa0.reg[,1:2],type="n",main="Sample Score",
xlab = "PC1",ylab="PC2")
text(sa0.reg[,1:2],row.names(d.scale),cex=0.5)
## 相关系数样本得分图
plot(sa0.cor[,1:2],type="n",main="Sample Score",
xlab = "PC1",ylab="PC2")
text(sa0.cor[,1:2],row.names(d.scale),cex=0.5)
dev.off()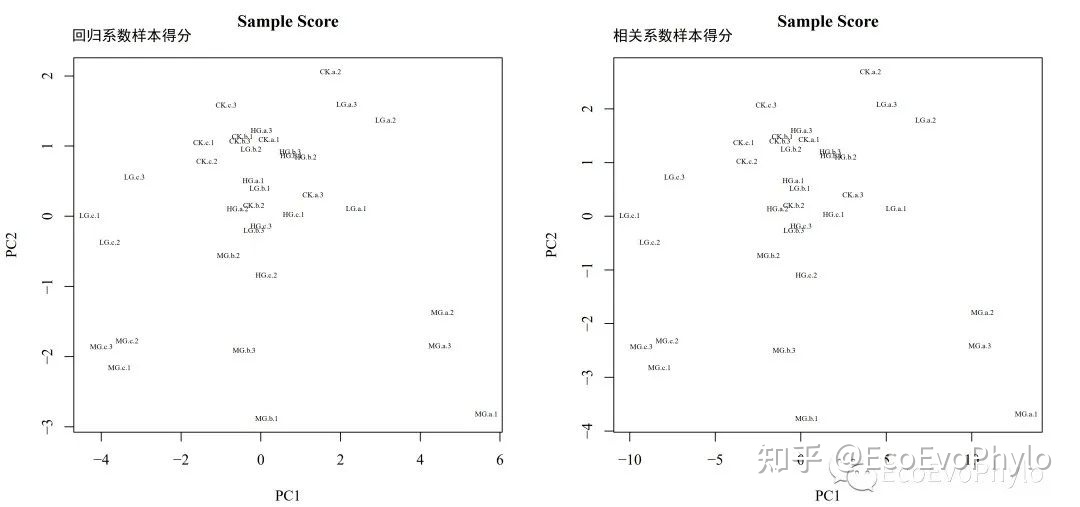
图12|样本得分图,scores.pdf。使用回归系数或相关系数计算样本得分,只是每个PC的样本得分都乘以了一个常数,结果趋势没有差别。计算完样本得分,就可以根据主成分大小对样本进行分析,并利用主成分的意义来解释。由图可见,沿PC1,MG中样本具有明显分层(depth),PC1可以代表土壤深度的环境因子差异。结合载荷图分析,越靠近右边的土壤样本的肥力可能越高,而越靠近左边的肥力可能较低[仅示例解读,无现实意义]。
3.2 PCA分析-princomp()
使用princomp()进行PCA分析,factoextra包可用于提取FactoMineR::PCA(); stats::prcomp()、stats::princomp( ); ade4::dudi()、ade4::spca(); ExPosition::expOutput/epPCA()的PCA分析结果信息,与上面的逐步PCA分析结果进行比较查看。配套的FactoInvestigate包(http://factominer.free.fr/reporting/index.html)可以自动输出FactoMineR中PCA,MCA和CA分析的结果解释。
# 3.2.1 PCA分析
library(factoextra)
pca1 <- princomp(
data[-c(1:3)], # 不能直接使用相关系数矩阵。
cor = TRUE, # 数据进行中心化和标准化
fix_sign = FALSE # 默认是TRUE,表示需要保持第一个变量或样本的所有主成分载荷都为正值,第一个样本的PC1得分为正值。设置为FALSE结果才能完全与eigen()运行结果一致。
)
pca1$loadings
# 3.2.2 提取分析结果
## 特征值-variances are computed with the usual divisor N.
eig1 <- get_eigenvalue(pca1)
eig1
pca1$loadings # 回归系数载荷,乘以相应特征值的平方根后,就为相关系数载荷,既可表示变量与主成分的相关系数。
#sweep(pca1$loadings[,1:11],2,pca1$sdev,"*") # 乘以相应特征值平方根得相关系数。
pca1$scores # 样本得分
pca1$sdev # 特征值的平方根
## 变量得分
var1 <- get_pca_var(pca1)
var1$coord # 变量的坐标是变量与主成分的相关系数,即相关系数载荷。
##若分析时fix_sign = TRUE,则部分PC的相关系数载荷的正负性会与eigen()的结果正好相反。
##所以使用不同函数进行相同分析时,要注意一下它们计算过程和结果可能不一样。
##因为变量载荷与样本得分的正负性是一起变化的,因此这些PC的变量坐标的正负性对整体趋势没有影响。
var1$cor # 变量与主成分相关系数,与坐标值一样。
var1$cos2 # 每个主成分代表变量质量的比例,相关系数的平方。
sum(var1$cos2[1,]) # 每个变量的所有主成分代表比例和为1。
var1$contrib # 变量对主成分的贡献度。
sum(var1$contrib[,1]) #所有变量对每个主成分的贡献度之和为100。
## 样本得分
ind1 <- get_pca_ind(pca1)
ind1$coord # factoextra提取的样本得分应该使用的是回归系数载荷,结果与eigen()存在些微差别。应该是计算方差或称中除以N或N-1或取小数点造成的。
ind1$cos2 # 每个主成分代表样本质量的比例。
sum(ind1$cos2[1,]) # 每个样本的所有主成分代表比例和为1。
ind1$contrib # 样本对主成分的贡献度。
sum(ind1$contrib[,1]) #所有样本对每个主成分的贡献度之和为100。

图13|princomp()提取的样本得分,ind1$coord。更多输出结果见PCA.html文件。
3.3 PCA分析-principal()
principal()可进行主成分和因子分析(会进行主成分旋转,允许因子之间存在相关性),一般默认进行因子分析,只输出最佳因子数量。其使用特征值平方根对特征向量进行缩放,以产生在因子分析中更典型的成分载荷。此函数还可填补缺失数据,以进行pca分析。
# 3.3.1 使用principal()进行PCA分析,输入数据可以是原始数据矩阵或者相关性系数矩阵。
#page(principal) #查看函数代码
library(psych)
pca2 = principal(data[-c(1:3)],
#r = cor, #也可使用变量相关性矩阵,但是样本得分需要自己计算。
cor="cor",
scores = TRUE,
residuals = TRUE, # 输出结果中包含残差。
nfactors = 11,# nfactors设置主成分数目
rotate="none" # 设置主成分旋转方法
)
pca2
# 3.3.2 提取分析结果
## 特征值
eig2 <- pca2$values
## 变量载荷
var2 <-
pca2$loadings[1:11,1:11] # RC1-RC11,这里的变量载荷,表示变量与主成分的相关系数。
sum(pca2$loadings[1,1:11]^2)
## 样本得分,表示样本与主成分的相关程度。与其他分析方法的样本得分计算方式不同。
##getAnywhere(fa.stats)#查看样本得分计算过程
##beta权重:pca2$weights = solve(cor,var2),求cor %*% x = var2中的x矩阵。
##scale(data[-c(1:3)]) %*% solve(cor,var2)
ind2 <- pca2$scores
ind2
图14|principal()提取的样本得分,ind2。更多输出结果见PCA.html文件。
3.4 PCA分析-SVD分解数据矩阵
vegan::rda()等使用svd()分解数据矩阵,经过此过程的计算,帮助认识vegan::rda()的各种缩放数据。
# 3.4.1 svd逐步分解数据矩阵
pca3 <- svd(d.scale) # 解奇异值(singular-value ),
pca3$d # 数据矩阵的奇异值(正交系数),与eigen()解的特征值不同。
svd(cor) # 才能得到与eigen()一样的特征值。
pca3$u # 左奇异值(正交系数(orthonormal coefficients)),每个主成分乘以对应奇异值就得到样本得分。
pca3$v # 右奇异值,回归系数变量载荷,绝对值大小与eigen()结果一样,但是部分载荷的正负可能不同。
# 3.4.2 使用分析结果重新计算出原始标准化后数据
D <- diag(pca3$d)
pca3$u %*% D %*% t(pca3$v) # 可重新计算出原始数据。
# 3.4.3 变量得分-相关系数
var3 <- data.frame(sweep(pca3$v,2,sqrt(eig0[,1]),"*"),
row.names = names(data[-c(1:3)]) )
colnames(var3) <- paste("PC",1:11,sep = "")
var3
# 3.4.4 样本得分
ind3 <- data.frame(sweep(pca3$u,2,pca3$d,"*"),
row.names = rownames(data) )
colnames(ind3) <- paste("PC",1:11,sep = "")
ind3

图15|svd()样本得分,ind3。更多输出结果见PCA.html文件。
3.5 PCA分析-prcomp()
prcomp()进行PCA分析,此函数使用svd()解数据矩阵。
# 3.5.1 PCA分析
pca4 <- prcomp(
data[-c(1:3)], # 不能直接使用相关性或协方差矩阵。
scale. = TRUE # 数据进行中心化和标准化。
)
# 3.5.2 提取分析结果
## 特征值-variances are computed with the usual divisor N-1.
eig4 <- get_eigenvalue(pca4)
eig4
pca4$rotation # 回归系数载荷,与eigen()结果差异:部分主成分的载荷值正负性相反,对结果没有影响。个人理解在多元变量形成的椭球中寻找某个椭圆方差最大的长轴时,定那个方向为正,对最后空间中点的距离并没有影响。
pca4$x # 样本得分
pca4$sdev # 主成分的标准差,特征值(方差)的平方根
#sweep(pca4$rotation[,1:11],2,pca4$sdev,"*") # 单位特征向量乘以相应特征值平方根得相关系数。
## 变量得分
var4 <- get_pca_var(pca4)
var4$coord # 变量的坐标是变量与主成分的相关系数。部分PC的相关系数载荷的正负性与eigen()的结果正好相反。
var4$cor # 变量与主成分相关系数,与坐标值一样。
var4$cos2 # 余弦值平方。每个主成分代表变量质量的比例。
sum(var4$cos2[1,]) # 每个变量的所有主成分代表比例和为1。
var4$contrib # 变量对主成分的贡献度。
sum(var4$contrib[,1]) #所有变量对每个主成分的贡献度之和为100。
## 样本得分
ind4 <- get_pca_ind(pca4)
ind4$coord # factoextra提取的样本得分使用的单位特征向量。
ind4$cos2 # 每个主成分代表样本质量的比例。
sum(ind4$cos2[1,]) # 每个样本的所有主成分代表比例和为1。
ind4$contrib # 样本对主成分的贡献度。
sum(ind4$contrib[,1]) #所有样本对每个主成分的贡献度之和为100。
##PC1的样本得分与标准化之后的变量的相关系数,就是相关性载荷。所以方向是相对的,不同函数结算出的载荷的正负性不同,对结果没有差异。
cor(ind4$coord[,2],d.scale[,1])
var4$coord[1,2]
图16|prcomp()提取的样本得分,ind4$coord 。更多输出结果见PCA.html文件。
3.6 PCA分析-vegan::rda()
使用vegan::rda()进行PCA分析,并查看不同数据缩放方法的结果异同。

表1|样本、变量得分的的不同标准化方法。PCA分析对数据量度敏感,vegan包为了消除结果随着量度的变化而变化,会对结果进行标准化。用于绘制样本-变量双序图。摘自http://127.0.0.1:13837/library/vegan/doc/decision-vegan.pdf。

表2|标准化常数。不同包绘制双序图时采用不同的标准化常数(scaling constant)以对输出结果按照特征值比例进行缩放。摘自http://127.0.0.1:13837/library/vegan/doc/decision-vegan.pdf。
# 3.6.1 PCA分析
library(vegan)
pca5 <- rda(
data[-c(1:3)],
scale = TRUE # 数据进行中心化和标准化
)
# 3.6.2 提取分析结果
## 原始未缩放数据-svd()分解的左奇异值。
res0 <- summary(pca5,scaling =0,
axes = 11, # 提取11个主成分的结果
display = c("wa","sp"),
correlation = TRUE)
## 根据特征值按样本缩放数据-样方是物种的质心(centroids)
## 适用于解释样本近似度和发现样方梯度或分组。
##线性模型RDA和PCA的特征值对数据量度是敏感的,原始数据的数值越大,由特征值产生的得分,将会比正交系数的离散度大,因此缩放样本得分时使用的是每个主成分特征值占特征值之和的比例。缩放分数见表1.
##样本得分与变量载荷都会乘以一个缩放常数:可通过const=c()设置,第一个用于变量,第二个用于样本。默认使用值见表2
##正交系数(左奇异值)乘以(sqrt(eigenvals(pca5)/pca5$tot.chi))*(sqrt(sqrt((ncol(data) - 1) * pca5$tot.chi)))
##变量载荷(右奇异值)乘以(sqrt(sqrt((ncol(data) - 1) * pca5$tot.chi)))
res1 <- summary(pca5,caling = 1,
display = c("wa","sp"),
axes = 11
)
## 根据特征值按变量缩放数据-biplot()绘制样本-物种是样方的质心,变量双序图中的使用此数据
## 适用于寻找物种群或者可替代物种。
##左奇异值乘以(sqrt(sqrt((ncol(data) - 1) * pca5$tot.chi)))
##右奇异值乘以(sqrt(eigenvals(pca5)/pca5$tot.chi))*(sqrt(sqrt((ncol(data) - 1) * pca5$tot.chi)))
res2 <- summary(pca5,caling = 2,
display = c("wa","sp"),
axes = 11)
##两种缩放方式中出现双序图原点的物种的解释需要谨慎。
## 根据特征值的平方根对称缩放
##左奇异值乘以(sqrt((sqrt(sqrt((ncol(data) - 1) * pca5$tot.chi)))))* pca5$tot.chi)))
##右奇异值乘以(sqrt((sqrt(sqrt((ncol(data) - 1) * pca5$tot.chi)))))* pca5$tot.chi)))
res3 <- summary(pca5,scaling =3,
display = c("wa","sp"),
axes = 11)
# 3.6.3 结果比较
## 特征值都相同,差别只在取小数点的差别。提取特征根也有不同的方法,vegan也是采用的eigen。
res0$cont # 特征值
res1$cont # 特征值
res2$cont # 特征值
res3$cont # 特征值
### 变量得分
##getAnywhere(scores.rda),查看vegan缩放数据方式。
head(res0$species) # pca3$CA$v,右奇异值(正交系数),与回归系数(单位特征向量)一致。
head(res1$species) # 处理方式参考表1和2。
head(res2$species) # 处理方式参考表1和2。
head(res3$species) # 处理方式参考表1和2。
## 样本得分
head(res0$sites) # pca3$CA$u,左奇异值(正交系数)。
head(res1$sites) # 处理方式参考表1和2。
head(res2$sites) # 处理方式参考表1和2。
head(res3$sites) # 处理方式参考表1和2。注:更多输出结果见PCA.html文件。
四、样本-变量双序图
综上,不同的函数有关变量与样本得分的输出都有些许差异,那么这对最后的分析结果有什么影响吗?下面对上面各函数结果进行绘图,讨论它们的结果差异。
如果要绘制样本-变量双序图,则需要对样本和变量得分进行缩放,未进行缩放的分析结果,biplot()会为样本与变量得分分别生成坐标轴。factoextra包中的绘图函数fviz_pca_biplot()可以用于绘制部分函数的PCA双序图。各函数也都有默认的biplot()用于直接绘制双序图。
# biplots
pdf("biplot.pdf",family = "Times",height = 12,width = 12)
par(mfrow=c(2,2))
#fviz_pca_biplot(pca1)
# ?biplot.princomp # 可以查看双序图的数据缩放方法。
#biplot(pca1,scale = 0) # 样本缩放,变量不缩放。
biplot(pca1,scale = 1) # 变量缩放,样本不缩放# The variables are scaled by lambda ^ scale and the observations are scaled by lambda ^ (1-scale).
biplot.psych(pca2,choose=c(1,2), rownames(data),
cuts=0) # cuts=0,重叠的标签也显示出来。
#fviz_pca_biplot(pca4)
biplot(pca4)
biplot(pca5)
dev.off()
图17|样本-变量双序图,biplot.pdf。如果要绘制样本-变量双序图,则需要对样本和变量得分进行缩放,未进行缩放的分析结果,biplot()会为样本与变量得分分别生成坐标轴。vegan::rda()对结果进行了缩放所以样本和变量可以共用一个坐标轴。princomp()因为没有设置 fix_sign = TRUE,所以与其他函数的绘图结果方向刚好相反,但是样本距离、样本与主成分相关性、变量与主成分相关性、变量间相关性时没有变化的。只是样本与变量的坐标正负性方向正好相反。
更多结果解读及绘图,参考R统计绘图-PCA分析绘图及结果解读(误差线,多边形,双Y轴图、球形检验、KMO和变量筛选等)
数据表和代码可以QQ交流群文件夹中下载,或EcoEvoPhylo公众号后台发送“PCA详解1”获取。
原文链接:R统计绘图-PCA详解1(princomp/principal/prcomp/rda等) (qq.com)
参考资料
R统计绘图-PCA分析绘图及结果解读(误差线,多边形,双Y轴图、球形检验、KMO和变量筛选等)
principal()使用参考]:(R语言用principal和princomp怎么实现 主成分分析和因子分析啊? - 知乎)
统计学:从数据到结论 4d[吴喜之]
《精通机器学习:基于R》
Borcard, Daniel, François Gillet and Pierre Legendre. Numerical Ecology with R. Use R! Cham: Springer International Publishing, 2018. https://doi.org/10.1007/978-3-319-71404-2.
推荐阅读
R绘图-物种、环境因子相关性网络图(简单图、提取子图、修改图布局参数、物种-环境因子分别成环径向网络图)
R统计绘图-分子生态相关性网络分析(拓扑属性计算,ggraph绘图)
R统计绘图-变量分组相关性网络图(igraph)
机器学习-分类随机森林分析(randomForest模型构建、参数调优、特征变量筛选、模型评估和基础理论等)
R统计绘图-随机森林分类分析及物种丰度差异检验组合图
机器学习-多元分类/回归决策树模型(tree包)
R统计绘图-环境因子相关性+mantel检验组合图(linkET包介绍1)
R统计绘图-NMDS、环境因子拟合(线性和非线性)、多元统计(adonis2和ANOSIM)及绘图(双因素自定义图例)
R统计绘图-RDA分析、Mantel检验及绘图
R绘图-RDA排序分析R统计绘图-VPA(方差分解分析)
R统计绘图-PCA详解1(princomp/principal/rcomp/rda等)
R统计-PCA/PCoA/db-RDA/NMDS/CA/CCA/DCA等排序分析教程
R统计绘图-PCA分析绘图及结果解读(误差线,多边形,双Y轴图、球形检验、KMO和变量筛选等)
R统计-微生物群落结构差异分析及结果解读
R统计绘图-PCA分析及绘制双坐标轴双序图
R中进行单因素方差分析并绘图
R统计-多变量单因素参数、非参数检验及多重比较
R绘图-相关性分析及绘图
R绘图-相关性系数图
R统计绘图-环境因子相关性热图
R统计绘图-corrplot绘制热图及颜色、字体等细节修改
R统计绘图-corrplot热图绘制细节调整2(更改变量可视化顺序、非相关性热图绘制、添加矩形框等)
R数据可视化之美-节点链接图
R统计绘图-rgbif包下载GBIF数据及绘制分布图
R统计绘图 | 物种组成堆叠柱形图(绝对/相对丰度)
R统计绘图 | 物种组成冲积图(绝对/相对丰度,ggalluvial)
R统计绘图 | 物种组成堆叠面积图(绝对/相对丰度,ggalluvial)
R统计-单因素ANOVA/Kruskal-Wallis置换检验
R统计-正态性分布检验[Translation]
R统计-数据正态分布转换[Translation]
R统计-方差齐性检验[Translation]
R统计-Mauchly球形检验[Translation]
R统计绘图-单、双、三因素重复测量方差分析[Translation]
R统计绘图-混合方差分析[Translation]
R统计绘图-协方差分析[Translation]
R统计绘图-One-Way MANOVA