Goroutine
1.Goroutine 是 Golang 提供的一种轻量级线程,我们通常称之为「协程」,相比较线程,创建一个协程的成本是很低的。所以你会经常看到 Golang 开发的应用出现上千个协程并发的场景。
Goroutine 的优势:
与线程相比,Goroutines 成本很低。 它们的堆栈大小只有几 kb,堆栈可以根据应用程序的需要增长和缩小,context switch 也很快,而在线程的情况下,堆栈大小必须指定并固定。
Goroutine 被多路复用到更少数量的 OS 线程。 一个包含数千个 Goroutine 的程序中可能只有一个线程。如果该线程中的任何 Goroutine 阻塞等待用户输入,则创建另一个 OS 线程并将剩余的 Goroutine 移动到新的 OS 线程。所有这些都由运行时处理,作为开发者无需耗费心力关心,这也使得我们有很干净的 API 来支持并发。
Goroutines 使用 channel 进行通信。 channel 的设计有效防止了在使用 Goroutine 访问共享内存时发生竞争条件(race conditions) 。channel 可以被认为是 Goroutine 进行通信的管道。
何为并发?
并发指在一段时间内有多个任务(程序,线程,协程等)被同时执行。注意,不是同一时刻。在单处理机系统中,每一时刻仅能有一个任务被执行,故微观上这些任务只能是分时地交替执行。倘若在计算机系统中有多个处理机,则这些可以并发执行的任务被分配到多个处理机上同时执行,这就实现了并行。并发 (Concurrency) 和 并行 ( Parallelism) 是不同的。这里引用 Erlang 之父 Joe Armstrong 对并发与并行区别的形象描述:
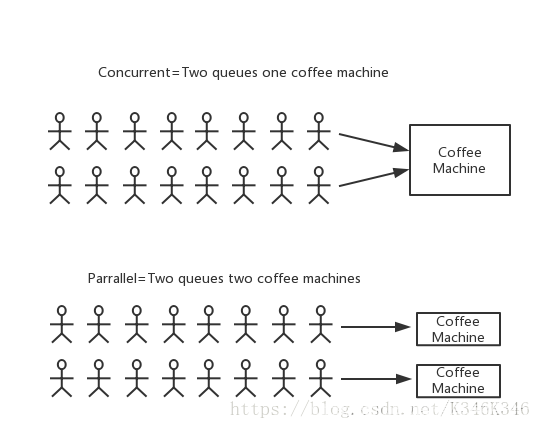
2.并发的好处
并发最直接的好处就是高效。
假如我们要做三件事情,一是吃饭,二是洗脚,三是看电视。如果串行执行,那么非常浪费时间。
如果改成并发执行,吃饭,洗脚,看电视同时进行,则非常节省时间。

3.go 如何实现并发
Go 程(goroutine)是由 Go 运行时管理的轻量级线程。通过它我们可以轻松实现并发编程。
示例:
package main
import (
"fmt"
"sync"
"time"
)
func eatFood() {
fmt.Println("eat cost 3 seconds")
time.Sleep(3 * time.Second)
}
func washFeet() {
fmt.Println("wash feet cost 3 seconds")
time.Sleep(3 * time.Second)
}
func watchTV() {
fmt.Println("watch tv cost 3 seconds")
time.Sleep(3 * time.Second)
}
func worker(task func(), wg *sync.WaitGroup) {
defer wg.Done()
task()
}
func main() {
var wg sync.WaitGroup
wg.Add(3)
// 并发执行
start := time.Now().Unix()
go worker(eatFood, &wg) // 创建一个 goroutine 执行吃饭任务
go worker(washFeet, &wg) // 创建一个 goroutine 执行洗脚任务
go worker(watchTV, &wg) // 创建一个 goroutine 执行看电视任务
wg.Wait() // 等待三个 goroutine 全部执行完成
fmt.Printf("total only cost %v seconds\n", time.Now().Unix()-start)
}
结果输出:
watch tv cost 3 seconds
wash feet cost 3 seconds
eat cost 3 seconds
total only cost 3 seconds
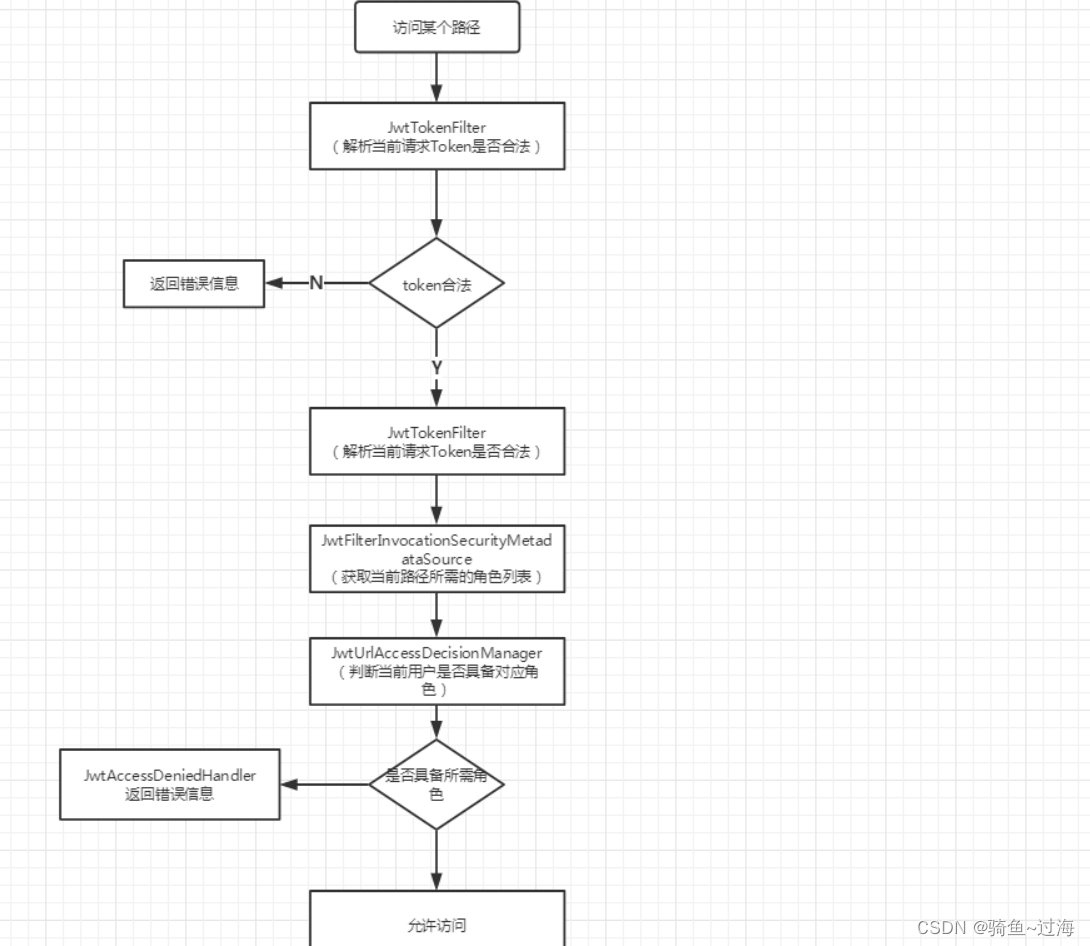
4.GPM调度模型
说到 Go 程,不得不说 Go 程的调度。Go 优秀的并发性能得益于出色的基于 G-M-P 模型的 Go 程调度器,官方宣称用 Golang 写并发程序的时候随便起个成千上万的 goroutine 毫无压力。
Go 程的调度模型是 G-P-M,通过 P(Processor,逻辑处理器)将 G(Goroutine,用户线程)与 M(Machine,系统线程)解耦,我们可以随意开启多个 G 交由调度器分配到 P,再通过 P 将 G 交由 M 来完成执行。
Go 调度器的基本模型:
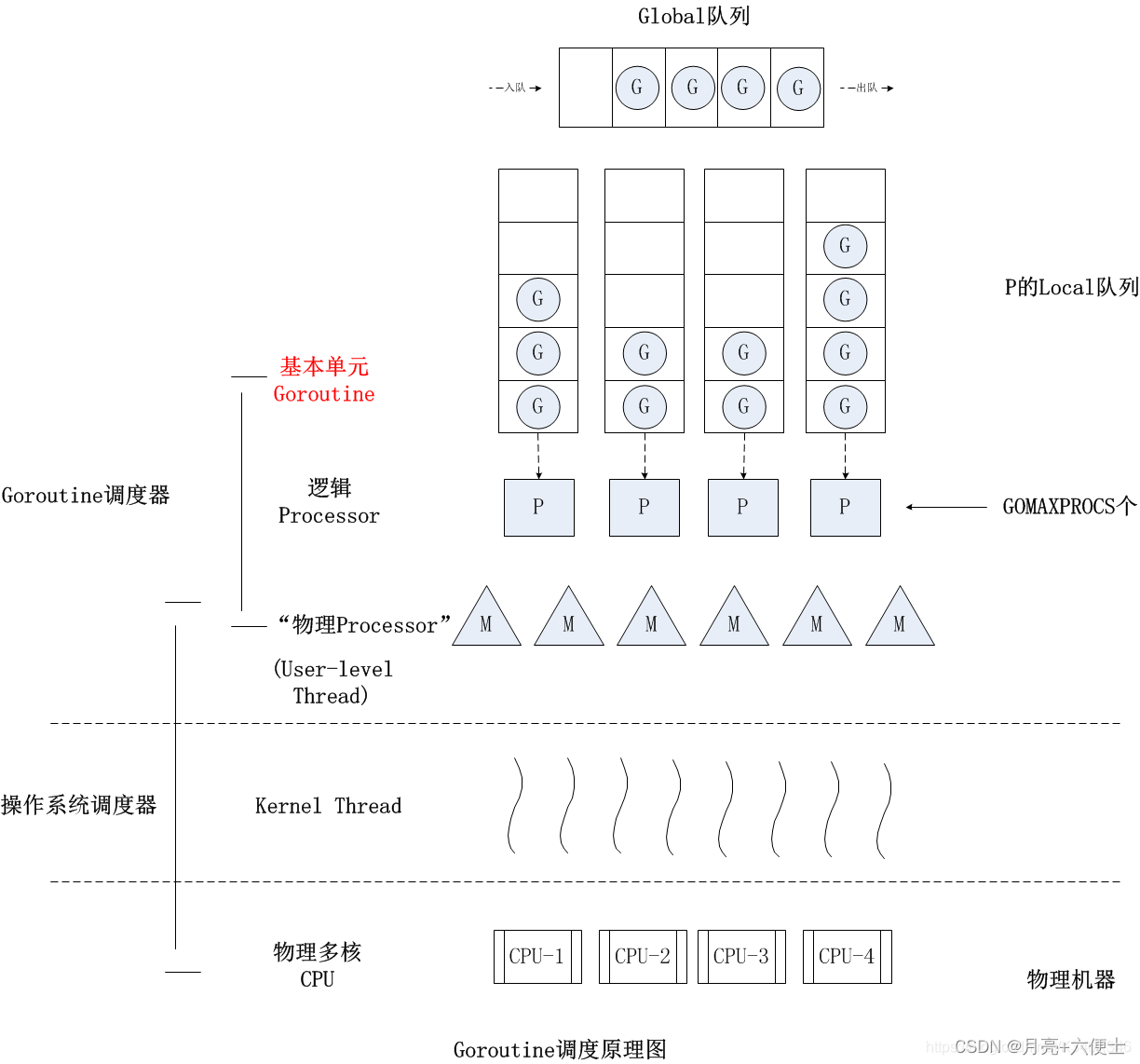
每个 P 维护一个 G 的本地队列;
当一个 G 被创建出来,或者变为可执行状态时,优先把它放到 P 的本地队列中,否则放到全局队列;
当一个 G 在 M 里执行结束后,P 会从队列中把该 G 取出;如果此时 P 的队列为空,即没有其他 G 可以执行, M 会先尝试从全局队列寻找 G 来执行,如果全局队列为空,它会随机挑选另外一个 P,从它的队列里拿走一半 G 到自己的队列中执行。
注意: P 的数量在默认情况下,会被设定为 CPU 的核数。而 M 虽然需要跟 P 绑定执行,但数量上并不与 P 相等。这是因为 M 会因为系统调用或者其他事情被阻塞,因此随着程序的执行,M 的数量可能增长,而 P 在没有用户干预的情况下,则会保持不变。
Go 协程代价
Go 程虽然轻量,但仍有开销。
Go 的开销主要是三个方面:创建(占用内存)、调度(增加调度器负担)和删除(增加 GC 压力)。
调度开销
时间上,协程调度也会有 CPU 开销。我们可以利用runntime.Gosched()让当前协程主动让出 CPU 去执行另外一个协程,下面看一下协程之间切换的耗时。
package main
import (
"fmt"
"runtime"
"time"
)
const Num = 10000
func cal() {
for i := 0; i < Num; i++ {
runtime.Gosched()
}
}
func main() {
//设置一个processor
runtime.GOMAXPROCS(1)
start := time.Now().UnixNano()
go cal()
for i := 0; i < Num; i++ {
runtime.Gosched()
}
end := time.Now().UnixNano()
fmt.Printf("total %vns per %vns\n", end-start, (end-start)/Num)
}
输出结果值:
total 515100ns per 51ns
可见一次协程的切换,耗时55ns,相对于线程的微秒级耗时切换,性能表现非常优秀,但仍有开销;
GC开销
创建Go协程到运行结束,占用的内存资源需要由GC来回收,如果无休止的创建大量Go协程到运行结束,占用内存资源需要GC来回收,如果无休止的创建大量Go协程后,势必会造成Gcyali
package main
import (
"fmt"
"runtime"
"runtime/debug"
"sync"
"time"
)
func createLargeNumGoroutine(num int, wg *sync.WaitGroup) {
wg.Add(num)
for i := 0; i < num; i++ {
go func() {
defer wg.Done()
}()
}
}
func main() {
//设置一个Processor 保证go 协程串行
runtime.GOMAXPROCS(1)
//关闭gc改为手动执行
debug.SetGCPercent(1)
var wg sync.WaitGroup
createLargeNumGoroutine(1000, &wg)
wg.Wait()
t := time.Now()
runtime.GC() //手动GC
cost := time.Since(t)
fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 1000)
createLargeNumGoroutine(10000, &wg)
wg.Wait()
t = time.Now()
runtime.GC() // 手动 GC。
cost = time.Since(t)
fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 10000)
createLargeNumGoroutine(100000, &wg)
wg.Wait()
t = time.Now()
runtime.GC() // 手动 GC。
cost = time.Since(t)
fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 100000)
}
输出:
GC cost 539.8µs when goroutine num is 1000
GC cost 0s when goroutine num is 10000
GC cost 11.2763ms when goroutine num is 100000
当创建的 Go 程数量越多,GC 耗时越大。上面的分析目的是为了尽可能地量化 goroutine 的开销。虽然官方宣称用 Golang 写并发程序的时候随便起个成千上万的 goroutine 毫无压力,但当我们起十万、百万甚至千万个 goroutine 呢?goroutine 轻量的开销将被放大。
6.协程池的作用
无休止地创建大量 goroutine,势必会因为对大量 go 程的创建、调度和销毁带来性能损耗。为了解决这个问题,可以引入协程池。使用协程池限制 Go 程的开辟个数在大型并发场景是有必要的,这也是性能优化方法中对象复用思想的一个具体应用。
7.简易协程池的设计&实现
一个简单的协程池可以这么设计。
(1)定义一个接口表示任务,每一个具体的任务实现这个接口。
(2)使用 channel 作为任务队列,当有任务需要执行时,将这个任务插入到队列中。
(3)开启固定的协程(worker)从任务队列中获取任务来执行。
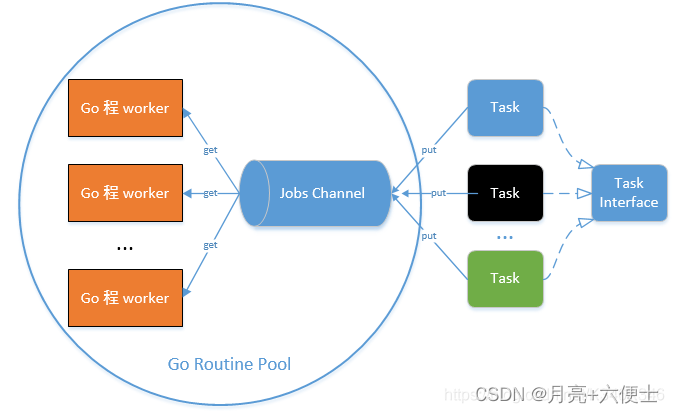
上面这个协程池的特点
(1)Go 程数量固定。可以将 worker 的数量设置为最大同时并发数 runtime.NumCPU()。
(2)Task 泛化。提供任务接口,支持多类型任务,不同业务场景下只要实现任务接口便可以提交到任务队列供 worker 调用。
(3)简单易用。设计简约,实现简单,使用方便。
一个示例:
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
// Task 任务接口
type Task interface {
Execute()
}
// pool协程池
type Pool struct {
TaskChannel chan Task //任务队列
}
// NewPool 创建一个协程池。
func NewPool(cap ...int) *Pool {
// 获取 worker 数量
var n int
if len(cap) > 0 {
n = cap[0]
}
if n == 0 {
n = runtime.NumCPU()
}
p := &Pool{
TaskChannel: make(chan Task),
}
// 创建指定数量 worker 从任务队列取出任务执行。
for i := 0; i < n; i++ {
go func() {
for task := range p.TaskChannel {
task.Execute()
}
}()
}
return p
}
// submit 提交任务
func (p *Pool) Submit(t Task) {
p.TaskChannel <- t
}
// EatFood 吃饭任务
type EatFood struct {
wg *sync.WaitGroup
}
func (e *EatFood) Execute() {
defer e.wg.Done()
fmt.Println("eat cost 3 seconds")
time.Sleep(3 * time.Second)
}
// washFeet 洗脚任务
type WashFeet struct {
wg *sync.WaitGroup
}
func (w *WashFeet) Execute() {
defer w.wg.Done()
fmt.Println("wash feet cost 3 seconds")
time.Sleep(3 * time.Second)
}
// watch TV看电视任务
type WatchTV struct {
wg *sync.WaitGroup
}
func (w *WatchTV) Execute() {
defer w.wg.Done()
fmt.Println("Watch Tv cost 3 seconds")
time.Sleep(3 * time.Second)
}
func main() {
p := NewPool()
var wg sync.WaitGroup
wg.Add(3)
task1 := &EatFood{
wg: &wg,
}
task2 := &WashFeet{
wg: &wg,
}
task3 := &WatchTV{
wg: &wg,
}
p.Submit(task1)
p.Submit(task2)
p.Submit(task3)
//等待所有任务执行完成
wg.Wait()
}
输出:
eat cost 3 seconds
Watch Tv cost 3 seconds
wash feet cost 3 seconds
设计时,我们也可以将任务队列中的任务设计为无参匿名函数,这样子使用起来可能会更简单。
// pool协程池
type Pool struct {
TaskChannel chan Task //任务队列
}
总体来说上面简易的协程池的不足:
(1)无法知道worker 与pool的状态
(2)woker数量不足无法动态扩增
(3)worker数量过多无法自动缩减
8.开源协程池的使用
一个成熟的协程池应该具备如下能力:
(1)worker & pool 状态控制;
性能测试、任务超时等都需要知道和控制任务与 Go 程池的状态。
(2)无锁化操作;
在 worker 和 pool 的状态读写时使用 atomic 原子操作,避免多次上锁带来性能损耗。
(3)动态可伸缩;
根据实际请求量的大小,动态扩缩容以避免 Go 程数量出现过少或过多的情况。
(4)资源复用。
对回收的 worker 放到 sync.Pool 进行复用,而不是直接销毁,降低 GC 压力,提高性能。
目前有很多第三方库实现了协程池,可以很方便地用来控制协程的并发数量,比较受欢迎的有:
ants 是一个高性能的 goroutine 池,实现了对大规模 goroutine 的调度管理、goroutine 复用,允许使用者在开发并发程序的时候限制 goroutine 数量,复用资源,达到更高效执行任务的效果。继续用吃饭、洗脚、看电视为例,演示ants的使用:
package main
import (
"fmt"
"sync"
"time"
"github.com/panjf2000/ants/v2"
)
func eatFood() {
fmt.Println("eat cost 3 seconds")
time.Sleep(3 * time.Second)
}
func washFeet() {
fmt.Println("wash feet cost 3 seconds")
time.Sleep(3 * time.Second)
}
func watchTV() {
fmt.Println("watch tv cost 3 seconds")
time.Sleep(3 * time.Second)
}
func main() {
var wg sync.WaitGroup
taskEatFood := func() {
defer wg.Done()
eatFood()
}
taskWashFeet := func() {
defer wg.Done()
watchTV()
}
taskWatchTV := func() {
defer wg.Done()
watchTV()
}
t := time.Now()
wg.Add(3)
//use the common pool
ants.Submit(taskEatFood)
ants.Submit(taskWashFeet)
ants.Submit(taskWatchTV)
wg.Wait()
fmt.Printf("total only cost %v\n", time.Since(t))
}
输出结果:
watch tv cost 3 seconds
watch tv cost 3 seconds
eat cost 3 seconds
total only cost 3.0051813s
小结:
资源复用是高性能编程的基本方法之一,在高并发场景,我们可以使用协程池来复用协程提高程序性能。
其他诸如:
无锁: 尽量不要加锁对某个变量读写,而应该分多个变量单独读写;
缓存: 网络IO是接口耗时的主要部分,对实时性要求不高的业务场景,可以增加本地缓存降低接口耗时;
减包: 限制请求时分页大小,减小回包大小,降低打解包对 CPU 的消耗。
- Jeffail/tunny
- panjf2000/ants