目录
- 11.SQLAlchemy
- 11.1 简介
- 11.2 安装
- 11.3 基本使用
- 11.4 连接
- 11.5 数据类型
- 11.6 执行原生sql
- 11.7 插入数据
- 11. 8 删改操作
- 11.9 查询
11.SQLAlchemy
11.1 简介
SQLAlchemy的是Python的SQL工具包和对象关系映射,给应用程序开发者提供SQL的强大功能和灵活性。它提供了一套完整的企业级的持久性模式,专为高效率和高性能的数据库访问,改编成简单的Python的领域语言。
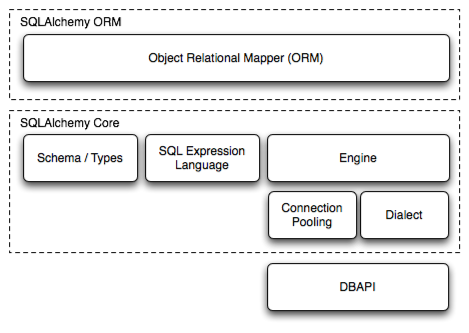
SQLAlchemy是Python界的ORM(Object Relational Mapper)框架,它两个主要的组件: SQLAlchemy ORM 和 SQLAlchemy Core 。
11.2 安装
pip install SQLAlchemy
11.3 基本使用
创建表
类使用声明式至少需要一个__tablename__属性定义数据库表名字,并至少一Column是主键
# SQLAlchemy练习
from sqlalchemy import create_engine
from sqlalchemy import Column, Integer, String, UniqueConstraint, Index
from sqlalchemy.ext.declarative import declarative_base
# declarative_base类维持了一个从类到表的关系,通常一个应用使用一个base实例,所有实体类都应该继承此类对象
Base = declarative_base()
# 类使用声明式至少需要一个__tablename__属性定义数据库表名字,并至少一Column是主键
# 创建单表
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(32))
extra = Column(String(16))
def init_db():
# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
# 创建表
Base.metadata.create_all(engine)
def drop_db():
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
# 删除表
Base.metadata.drop_all(engine)
if __name__ == "__main__":
init_db()
# drop_db()
插入数据
# SQLAlchemy练习
import models
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
se = sessionmaker(bind=engine)
session = se()
u1 = models.User(name='a1', extra='aa')
u2 = models.User(name='a2', extra='bb')
session.add(u1)
session.add(u2)
session.commit()
# session.rollback() # 回滚
session.rollback()表示回滚
11.4 连接
SQLAlchemy 把一个引擎的源表示为一个连同设定引擎选项的可选字符串参数的 URI。URI 的形式是:
dialect+driver://username:password@host:port/database
该字符串中的许多部分是可选的。如果没有指定驱动器,会选择默认的(确保在这种情况下 不 包含 + )。
Postgres:
postgresql://scott:tiger@localhost/mydatabase
MySQL:
mysql://scott:tiger@localhost/mydatabaseOracle:
oracle:
//scott:tiger@127.0.0.1:1521/sidname
SQLite (注意开头的四个斜线):
sqlite:absolute/path/to/foo.db
11.5 数据类型
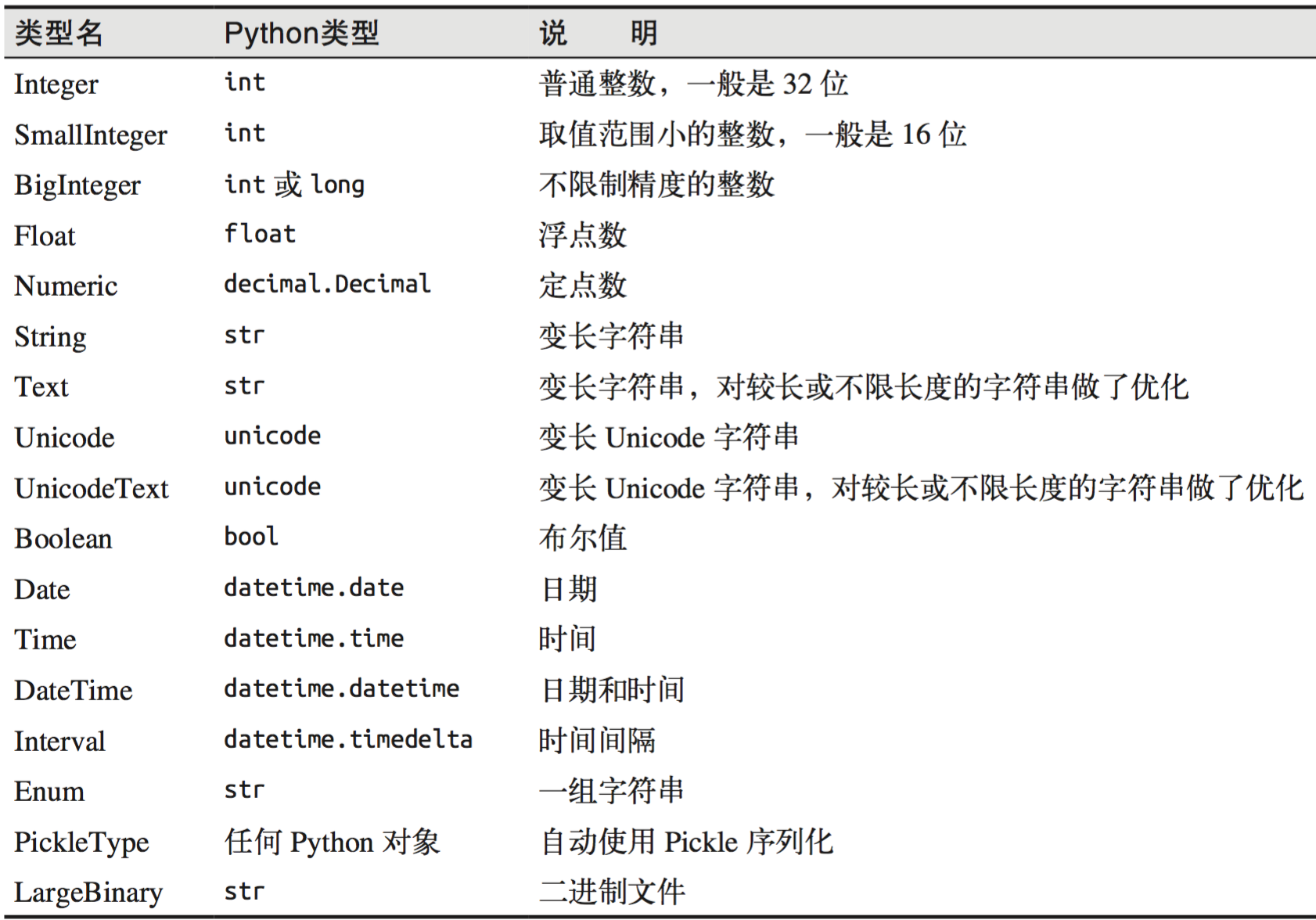
SQLAlchemy列选项:

11.6 执行原生sql
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
# 执行SQL
cur = engine.execute(
"select * from users"
)
# 获取第一行数据
re1 = cur.fetchone()
# 获取第n行数据
# re2 = cur.fetchmany(2)
# 获取所有数据
re3 = cur.fetchall()
print(re3)
# 注意:当执行fetchone()后,数据已经被去除一条了,即使fetchall(),取出的数据也是从第二条数据开始的
engine.execute默认使用了数据库连接池,也可以使用DBUtils + pymysql做连接池
11.7 插入数据
创建如下表供后面增删改查使用。
models2.py
# sqlalchemy创建多个关联表
from sqlalchemy import create_engine
from sqlalchemy import Column, Integer, String, UniqueConstraint, Index, DateTime, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
import datetime
Base = declarative_base()
class Classes(Base):
__tablename__ = 'classes'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(32), nullable=False, unique=True)
class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True, autoincrement=True)
username = Column(String(32), nullable=False, unique=True)
password = Column(String(32), nullable=False)
ctime = Column(DateTime, default=datetime.datetime.now) # 注意now后不要加()
# 外键:对应的班级
class_id = Column(Integer, ForeignKey('classes.id'))
class Hobby(Base):
__tablename__ = 'hobby'
id = Column(Integer, primary_key=True, autoincrement=True)
caption = Column(String(32), default='篮球')
# 建立多对多的关系
class Student2Hobby(Base):
__tablename__ = 'student2hobby'
id = Column(Integer, primary_key=True, autoincrement=True)
student_id = Column(Integer, ForeignKey('student.id'))
hobby_id = Column(Integer, ForeignKey('hobby.id'))
# 增加联合唯一索引
__table_args__ = (
UniqueConstraint('student_id', 'hobby_id', name='uni_student_id_hobby_id'),
)
def init_db():
# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
# 创建表
Base.metadata.create_all(engine)
def drop_db():
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
# 删除表
Base.metadata.drop_all(engine)
if __name__ == "__main__":
init_db()
# drop_db()
上面创建完表后,开始执行插入操作:
# sqlalchemy的增删改查
import models2
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
se = sessionmaker(bind=engine)
session = se()
# 单条增加
# c1 = models2.Classes(name='python入门')
# session.add(c1)
# session.commit()
# session.close()
# 多条增加
# c2 = [
# models2.Classes(name='python进阶'),
# models2.Classes(name='python高级'),
# models2.Classes(name='python web')
# ]
# session.add_all(c2)
# session.commit()
# session.close()
11. 8 删改操作
# sqlalchemy的增删改查
import models2
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
se = sessionmaker(bind=engine)
session = se()
# 删除
# session.query(models2.Classes).filter(models2.Classes.id > 2).delete()
# session.commit()
# 修改
# session.query(models2.Classes).filter(models2.Classes.id > 2).update({"name" : "099"})
session.query(models2.Classes).filter(models2.Classes.id > 2).update({models2.Classes.name: models2.Classes.name + "099"}, synchronize_session=False)
synchronize_session = False # 对字段执行字符串操作
# session.query(models2.Classes).filter(models2.Classes.id > 2).update({"num": models2.Classes.num + 1}, synchronize_session="evaluate")
# synchronize_session = 'evaluate' # 对字段执行数值型操作
session.commit()
11.9 查询
参考:Flask-SQLAlchemy - 武沛齐 - 博客园 (cnblogs.com)
1.以下的方法都是返回一个新的查询,需要配合执行器使用。
filter(): 过滤,功能比较强大,多表关联查询。
filter_by():过滤,一般用在单表查询的过滤场景。
order_by():排序。默认是升序,降序需要导包:from sqlalchemy import * 。然后引入desc方法。比如order_by(desc(“email”)).按照邮箱字母的降序排序。
group_by():分组。
2.以下都是一些常用的执行器:配合上面的过滤器使用。
get():获得id等于几的函数。
比如:查询id=1的对象。
get(1),切记:括号里没有“id=”,直接传入id的数值就ok。因为该函数的功能就是查询主键等于几的对象。
all():查询所有的数据。
first():查询第一个数据。
count():返回查询结果的数量。
paginate():分页查询,返回一个分页对象。
paginate(参数1,参数2,参数3)=>参数1:当前是第几页;参数2:每页显示几条记录;参数3:是否要返回错误。
返回的分页对象有三个属性:items:获得查询的结果,pages:获得一共有多少页,page:获得当前页。
3.常用的逻辑符:
需要导入包才能用的有:from sqlalchemy import *
not_、and_、or_ 还有上面说的排序desc。
常用的内置的有:in_:表示某个字段在什么范围之中。
4.其他关系的一些数据库查询:
endswith():以什么结尾。
startswith():以什么开头。
contains():包含
# sqlalchemy的增删改查
import models2
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import text
# 数据库链接引擎
engine = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/flask01?charset=utf8", max_overflow=5)
se = sessionmaker(bind=engine)
session = se()
# 查询
r1 = session.query(models2.Classes).all() # 返回models2.Classes对象
# label相当于sql里的as,取别名,后面结果集使用也是使用别名
r2 = session.query(models2.Classes.name.label('xx'), models2.Classes.name).all()
# 查询课程名字为python入门的课程
r3 = session.query(models2.Classes).filter(models2.Classes.name == "python入门").all()
# 也可使用filter_by,注意filter_by的传参和filter不一样
r4 = session.query(models2.Classes).filter_by(name='python入门').all()
# 查询课程名字为python入门的课程的第一个
r5 = session.query(models2.Classes).filter_by(name='python入门').first()
# 查询id<2且课程名字为python入门的课程
r6 = session.query(models2.Classes).filter(text("id<:value and name=:name")).params(value=2, name='python入门').order_by(models2.Classes.id).all()
# from_statement相当于子查询
r7 = session.query(models2.Classes).from_statement(text("SELECT * FROM Classes where name=:name")).params(name='python入门').all()
print(r7)
session.close()
# 注意:除了r2,其他结果都为models2.Classes对象
# 条件
ret = session.query(Users).filter_by(name='alex').all()
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all()
# 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()
# 限制
ret = session.query(Users)[1:2]
# 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()
# 分组
from sqlalchemy.sql import func
ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
# 默认使用外键进行连表
ret = session.query(Person).join(Favor).all() # 内连接
ret = session.query(Person).join(Favor, isouter=True).all() # 左连接
# 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
参考:
https://blog.csdn.net/u011146423/article/details/87605812
Python开发【第十九篇】:Python操作MySQL - 武沛齐 - 博客园 (cnblogs.com)
SQLAlchemy 学习笔记_JP.Zhang-CSDN博客