目录
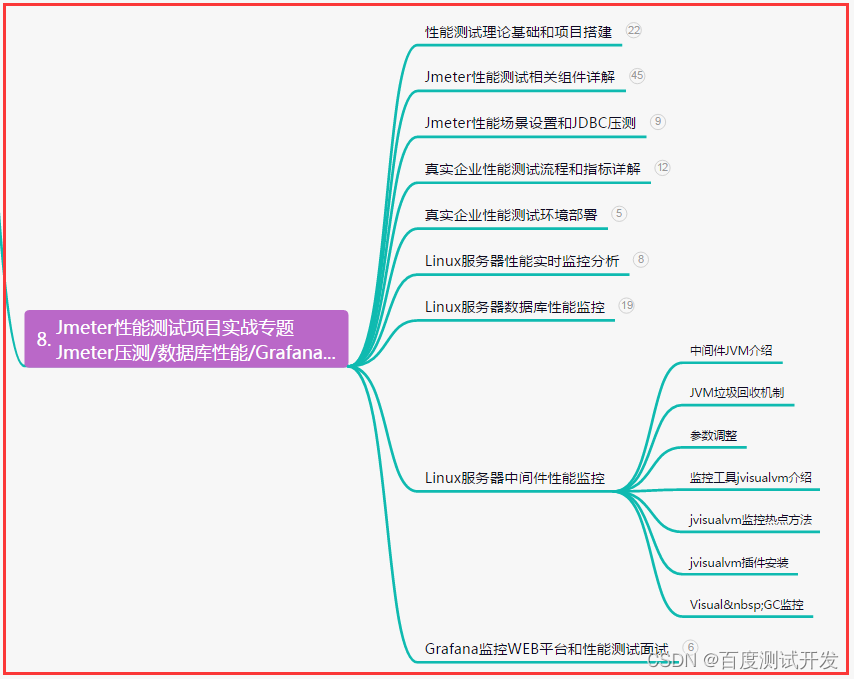
CTE和嵌套查询
嵌套查询
关联查询(join)
MapJoin
MapJoin操作在Map端完成
开启MapJoin操作
MAPJOIN不支持的操作
union
数据交换(import/export)
数据排序
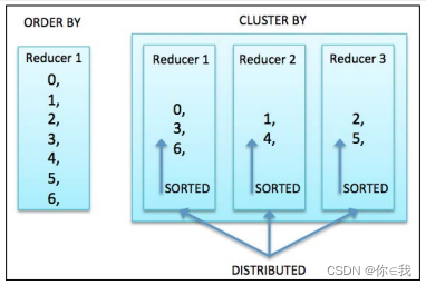
order by
sort by
distribute by
cluster by
CTE和嵌套查询
-- CTE语法
WITH t1 AS (SELECT …) SELECT * FROM t1;
-- CTE演示
with tab1 as (select id,name,age from people)
select * from tab1;
嵌套查询
-- 嵌套查询示例
SELECT * FROM (SELECT * FROM employee) ;
关联查询(join)
指对多表进行联合查询
JOIN用于将两个或多个表中的行组合在一起查询
类似于SQL JOIN,但是Hive仅支持等值连接
JOIN发生在WHERE子句之前
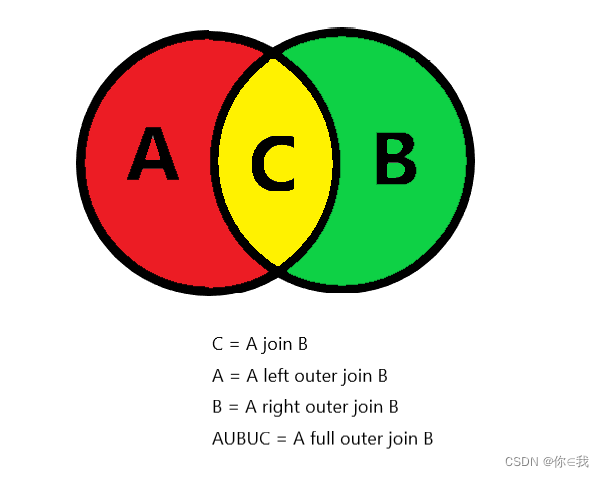
内连接:inner join
外连接:outer join
right join, left join, full outer join
交叉连接:cross join
隐式连接:Implicit join
MapJoin
MapJoin操作在Map端完成
- 小表关联大表
- 可进行不等值连接
开启MapJoin操作
set hive.auto.convert.join = true(默认值)
运行时自动将连接转换为MapJoin
MAPJOIN不支持的操作
在union all, lateral view, group by/join/sort by/cluster by/distribute by等操作后面
在union, join以及其他 MapJoin之前
union
- 所有子集数据必须具有相同的名称和类型
UNION ALL:合并后保留重复项
UNION:合并后删除重复项
- 可以在顶层查询中使用 order by, sort by , cluster by, distribute by 和limit适用于合并后的整个结果
- 集合其他操作可以使用 join、outer join来实现 (差集、交集)
数据交换(import/export)
import 和 export用于数据导入和导出
除数据库,可导入导出所有数据和元数据
导出数据(export)
export table employee to '/tmp/output3';
export table employee_partitioned partition (year=2014, month=11) to '/tmp/output5';导入数据(import)
import table employee from '/tmp/output3';
import table employee_partitioned partition (year=2014, month=11) from '/tmp/output5';数据排序
order by
order by (asc|desc)类似于标准SQL
只使用一个Reducer执行全局数据排序
速度慢,应提前做好数据过滤 支
持使用case when或表达式
支持按位置编号排序
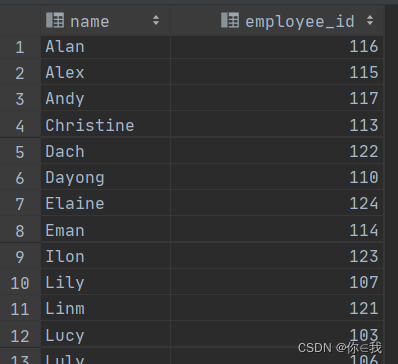
select employee_id,name
from employee_id
order by employee_id;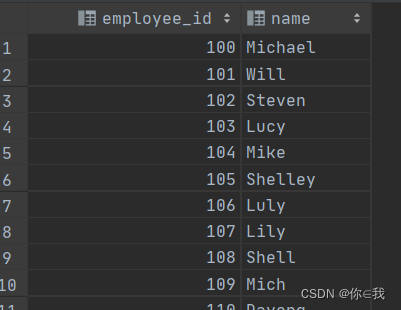
sort by
sort by对每个Reducer中的数据进行排序
当Reducer数量设置为1时,等于order by
排序列必须出现在select column列表中
distribute by
distribute by类似于标准SQL中的group by
根据相应列以及对应reduce的个数进行分发
- 默认是采用hash算法
- 根据分区字段的hash码与reduce的个数进行模除
通常使用在SORT BY语句之前
select name,skills_score,depart_title
from employee_id
distribute by depart_title sort by skills_score desc;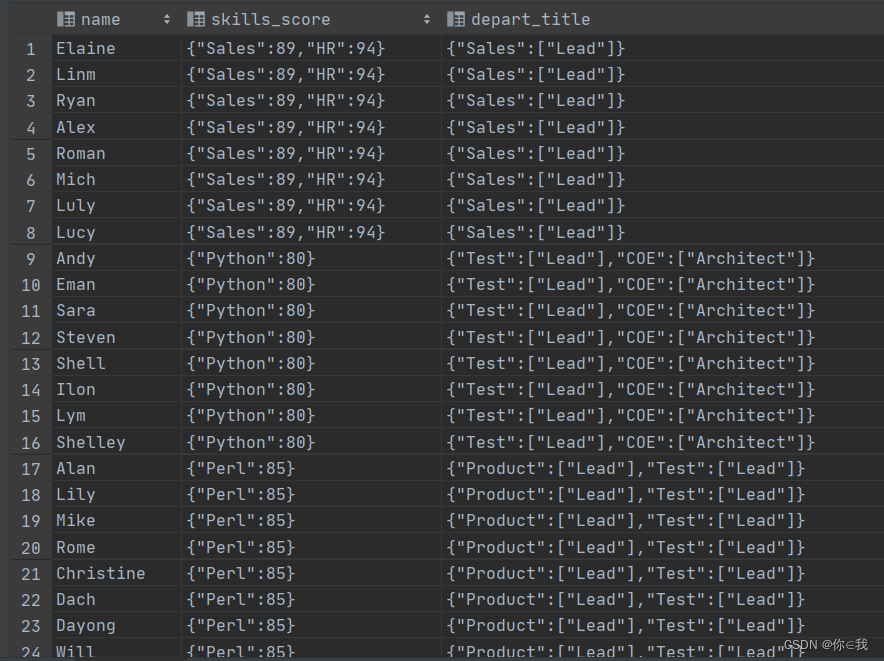
cluster by
cluster by=distribute by+sort by
不支持asc|desc
排序列必须出现在select column列表中
为了充分利用所有的Reducer来执行全局排序,可以先使用cluster by,然后使用order by
SELECT name, employee_id
FROM employee_id CLUSTER BY name;