一: 数据集下载
链接:(后续添加)
二: 处理标注文件
先处理标注文件,UA-DETRAC提供的标注文件格式是VOC格式,需要先转为XML格式,然后再将每个XML文件转为YOLO文件。
下面提供两个代码,只需要修改文件放置目录
1. 将VOC转为XML格式
import xml.etree.ElementTree as ET
from xml.dom.minidom import Document
import os
import cv2
import time
def ConvertVOCXml(file_path="", file_name=""):
tree = ET.parse(file_name)
root = tree.getroot()
# print(root.tag)
num = 0 # 计数
# 读xml操作
frame_lists = []
output_file_name = ""
for child in root:
if (child.tag == "frame"):
# 创建dom文档
doc = Document()
# 创建根节点
annotation = doc.createElement('annotation')
# 根节点插入dom树
doc.appendChild(annotation)
# print(child.tag, child.attrib["num"])
pic_id = child.attrib["num"].zfill(5)
# print(pic_id)
output_file_name = root.attrib["name"] + "__img" + pic_id + ".xml"
# print(output_file_name)
folder = doc.createElement("folder")
folder.appendChild(doc.createTextNode("VOC2007"))
annotation.appendChild(folder)
filename = doc.createElement("filename")
pic_name = "img" + pic_id + ".jpg"
filename.appendChild(doc.createTextNode(pic_name))
annotation.appendChild(filename)
sizeimage = doc.createElement("size")
imagewidth = doc.createElement("width")
imageheight = doc.createElement("height")
imagedepth = doc.createElement("depth")
imagewidth.appendChild(doc.createTextNode("960"))
imageheight.appendChild(doc.createTextNode("540"))
imagedepth.appendChild(doc.createTextNode("3"))
sizeimage.appendChild(imagedepth)
sizeimage.appendChild(imagewidth)
sizeimage.appendChild(imageheight)
annotation.appendChild(sizeimage)
target_list = child.getchildren()[0] # 获取target_list
# print(target_list.tag)
object = None
for target in target_list:
if (target.tag == "target"):
# print(target.tag)
object = doc.createElement('object')
bndbox = doc.createElement("bndbox")
for target_child in target:
if (target_child.tag == "box"):
xmin = doc.createElement("xmin")
ymin = doc.createElement("ymin")
xmax = doc.createElement("xmax")
ymax = doc.createElement("ymax")
xmin_value = int(float(target_child.attrib["left"]))
ymin_value = int(float(target_child.attrib["top"]))
box_width_value = int(float(target_child.attrib["width"]))
box_height_value = int(float(target_child.attrib["height"]))
xmin.appendChild(doc.createTextNode(str(xmin_value)))
ymin.appendChild(doc.createTextNode(str(ymin_value)))
if (xmin_value + box_width_value > 960):
xmax.appendChild(doc.createTextNode(str(960)))
else:
xmax.appendChild(doc.createTextNode(str(xmin_value + box_width_value)))
if (ymin_value + box_height_value > 540):
ymax.appendChild(doc.createTextNode(str(540)))
else:
ymax.appendChild(doc.createTextNode(str(ymin_value + box_height_value)))
if (target_child.tag == "attribute"):
vehicle_type = target_child.attrib["vehicle_type"]
name = doc.createElement('name')
pose = doc.createElement('pose')
truncated = doc.createElement('truncated')
difficult = doc.createElement('difficult')
name.appendChild(doc.createTextNode(str(vehicle_type)))
pose.appendChild(doc.createTextNode("Left")) # 随意指定
truncated.appendChild(doc.createTextNode("0")) # 随意指定
difficult.appendChild(doc.createTextNode("0")) # 随意指定
object.appendChild(name)
object.appendChild(pose)
object.appendChild(truncated)
object.appendChild(difficult)
bndbox.appendChild(xmin)
bndbox.appendChild(ymin)
bndbox.appendChild(xmax)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object)
file_path_out = os.path.join(file_path, output_file_name)
f = open(file_path_out, 'w')
f.write(doc.toprettyxml(indent=' ' * 4))
f.close()
num = num + 1
return num
'''
画方框
'''
def bboxes_draw_on_img(img, bbox, color=[255, 0, 0], thickness=2):
# Draw bounding box...
print(bbox)
p1 = (int(float(bbox["xmin"])), int(float(bbox["ymin"])))
p2 = (int(float(bbox["xmax"])), int(float(bbox["ymax"])))
cv2.rectangle(img, p1, p2, color, thickness)
def visualization_image(image_name, xml_file_name):
tree = ET.parse(xml_file_name)
root = tree.getroot()
object_lists = []
for child in root:
if (child.tag == "folder"):
print(child.tag, child.text)
elif (child.tag == "filename"):
print(child.tag, child.text)
elif (child.tag == "size"): # 解析size
for size_child in child:
if (size_child.tag == "width"):
print(size_child.tag, size_child.text)
elif (size_child.tag == "height"):
print(size_child.tag, size_child.text)
elif (size_child.tag == "depth"):
print(size_child.tag, size_child.text)
elif (child.tag == "object"): # 解析object
singleObject = {}
for object_child in child:
if (object_child.tag == "name"):
# print(object_child.tag,object_child.text)
singleObject["name"] = object_child.text
elif (object_child.tag == "bndbox"):
for bndbox_child in object_child:
if (bndbox_child.tag == "xmin"):
singleObject["xmin"] = bndbox_child.text
# print(bndbox_child.tag, bndbox_child.text)
elif (bndbox_child.tag == "ymin"):
# print(bndbox_child.tag, bndbox_child.text)
singleObject["ymin"] = bndbox_child.text
elif (bndbox_child.tag == "xmax"):
singleObject["xmax"] = bndbox_child.text
elif (bndbox_child.tag == "ymax"):
singleObject["ymax"] = bndbox_child.text
object_length = len(singleObject)
if (object_length > 0):
object_lists.append(singleObject)
img = cv2.imread(image_name)
for object_coordinate in object_lists:
bboxes_draw_on_img(img, object_coordinate)
cv2.imshow("capture", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
if (__name__ == "__main__"):
# print("main")
basePath = r"E:\project\dataset\UA-DETRAC\DETRAC-Test-Annotations-XML"
totalxml = os.listdir(basePath)
total_num = 0
flag = False
print("正在转换")
saveBasePath = r"E:\project\dataset\UA-DETRAC\test-labels-xml"
if os.path.exists(saveBasePath) == False: # 判断文件夹是否存在
os.makedirs(saveBasePath)
# ConvertVOCXml(file_path="samplexml",file_name="000009.xml")
# Start time
start = time.time()
log = open("xml_statistical.txt", "w") # 分析日志,进行排错
for xml in totalxml:
file_name = os.path.join(basePath, xml)
print(file_name)
num = ConvertVOCXml(file_path=saveBasePath, file_name=file_name)
print(num)
total_num = total_num + num
log.write(file_name + " " + str(num) + "\n")
# End time
end = time.time()
seconds = end - start
print("Time taken : {0} seconds".format(seconds))
print(total_num)
2. 将XML转为YOLO格式
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
# size=(width, height) b=(xmin, xmax, ymin, ymax)
# x_center = (xmax+xmin)/2 y_center = (ymax+ymin)/2
# x = x_center / width y = y_center / height
# w = (xmax-xmin) / width h = (ymax-ymin) / height
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
# print(x, y, w, h)
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
# print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
# print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 把forklift_pallet的voc的xml标签文件转化为yolo的txt标签文件
# 1、需要转化的类别
classes = ['car', 'bus', 'van', 'others'] # 注意:这里根据自己的类别名称及种类自行更改
# 2、voc格式的xml标签文件路径
xml_files1 = r'E:\project\dataset\UA-DETRAC\test-labels-xml'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'E:\project\dataset\UA-DETRAC\test-labels-yolo'
convert_annotation(xml_files1, save_txt_files1, classes)
3 处理完毕后我们会得到以下内容
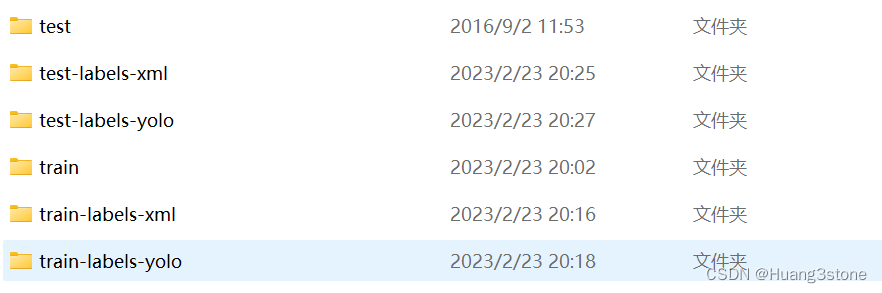
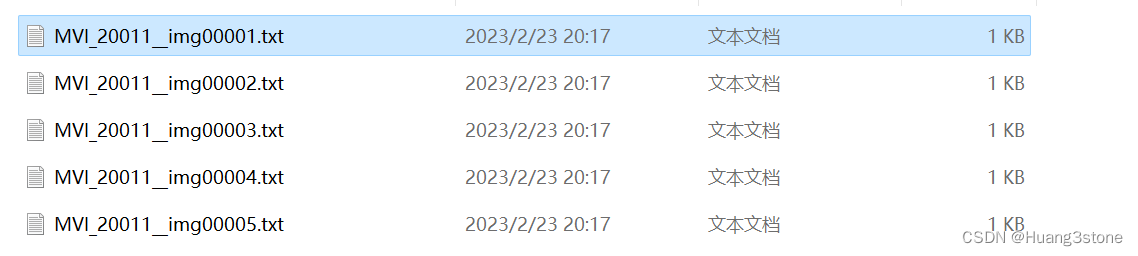
其中输出YOLO格式的标注文件名为MVI_20011__img00001.txt,相比图片的文件名多了一个 MVI_20011__ 的前缀。 (其实就是存放图片文件夹的文件名)。
所以后面我们需要对图像的文件名进行下处理,将其修改为和标注文件相同的名字!
三: 修改图像名称
一个代码搞定
import os
# 获取要修改的文件地址
path = r'E:\project\dataset\UA-DETRAC\test'
# 获取文件名列表
file_list = os.listdir(path)
print('文件列表如下:')
print(file_list)
# # 遍历文件名,获取文件名和扩展名
for file in file_list:
path_2 = path + '/' + file
file_list_inner = os.listdir(path_2)
for filename in file_list_inner:
pos = filename.rfind('.') - 8
newname = file + '__' + filename[pos:-4] + '.jpg'
#重新命名文件
os.rename(path_2+'/'+filename,path_2+'/'+newname)