1、垃圾回收方式
SerialGC(串行垃圾回收):为单线程环境设计且使用一个线程进行垃圾回收,会暂停所有的用户线程。
ParalleGC(并行垃圾回收):对过GC线程并行工作,此时用户线程是停止的。
ConcMarkSweep(CMS):用户线程和GC线程同时执行,不需要停顿用户线程。
G1垃圾回收器:将内存分割成不同的区域然后并发的进行垃圾回收。 2、查看当前默认的垃圾回收器
java -XX:+PrintCommandLineFlags -version3、7大垃圾回收器
在新生代主要使用:Serial copying、Parnew、Parallel Scavenge。相对应的同时会在老年代激活:Serial MSC、CMS、Parallel Compacting;以及还有一个G1垃圾回收器。
/*************************新生代*********************/
serial收集器(串行收集器):
-- 是一个单线程的收集器,在进行垃圾回收时,暂停其他所有用户线程,有可能会产生较长的停顿状态(stop-the-world)
-- 通过设置-XX:+UseSerialGC进行开启,会使用Serial(Young 区)+Serial old(old区)的收集器组合。
-- 即新老代都会使用串行收集器,新生代使用复制算法,老年代使用标记-整理算法。
ParNew(并行收集器):
-- 使用多线程进行垃圾回收,也会暂停其他所有用户线程。
-- 通过设置-XX:+UseParNewGC启用收集器,会使用ParNew(Young区)+Serial old(old区)的收集器组合。
-- 新生代使用复制算法,老年代采用标记-整理算法。不过现在已被移除。
Parallel New(并行收集器):
-- 是一个吞吐量有限的收集器。串行收集器在新生代和老年代的并行化。
-- 关注的重点是吞吐量和自适应调节策略(会根据当前系统的运行情况来提供最适应的停顿时间 -XX:+MaxGCPauseMillis)
-- 通过设置-XX:+UseParallelGC或-XX:+UseParallelOldGC(相互激活)来使用
-- 参数-XX:+ParallelGCThreads=N N代表启动多少个GC线程。
/*************************老年代*********************/
Parallel old
-- 是ParallelScavenge的老年代版本
-- 通过设置-XX:+UseParallelGC或-XX:+UseParallelOldGC(相互激活)来使用
CMS(并发标记清除)
-- 是一种以获取最短回收停顿时间为目标的收集器。
-- 通过设置-XX:+UseConcMarkSweepGC会自动打开-XX:+UseParNewGC。
-- 开启后使用ParNew(Young区)+CMS(Old区)+Serial old的收集器组合。
-- Serial old将作为CMS出错的后备收集器。CMS必须要在老年代堆内存用完之前完成回收,要不然就出发后备收集器造成较大的停顿。
-- 一共有4步:
1.初始标记:标记GC roots能关联到的对象,会暂停所有工作。
2.并发标记:和用户线程一起工作,主要标记过程,标记全部对象。
3.重新标记:暂停所有工作线程,用于确认是否又有新的标记。
4.并发清除:清理不可达对象,和用户线程一起,不需要暂停工作线程
5.优点是并发执行CPU资源压力大,缺点是会导致大量的碎片。
Serial old
-- 是Serial的老年版本以上的收集器都有这些共同点:1、新生代和老年代都是各自独立且连续的内存块。2、老年代收集必须扫描整个老年代。3、都是尽可能的少而快速的执行GC为原则。
4、G1垃圾回收器
是一种服务端的垃圾收集器,在实现高吞吐量的同时,也实现尽可能满足垃圾收集暂停时间。像CMS一样能与应用程序并发执行。
G1的优点在于:1、充分利用多核多CPU的硬件优势,尽量缩短STW(系统暂停时间)。2、整体采用标记-整理算法不会产生内存碎片。3、不再区分老年代和新生代把内存划分为多个独立的子区域。
堆有新生代(1/3)和老年代(2/3),新生代包含 伊甸园和幸存者区两个(8:1:1),当分代年龄到达一定次数就会从新生代到老年代。JVM调优的目的是减少STW(stopedWord),大对象(数组、字符串)会直接进入老年代。
回收步骤:
- Eden区的数据移动到Survivor区,如果Survivor区内存不够,Eden区数据部分移动到old区。
- Survivor区移动到新的Survivor区,部分数据回到old区。
- 最后Eden区收拾干净,GC结束。
G1相关的参数:
-XX:+UseG1GC 使用G1垃圾回收器
-XX:G1HeapRegionSize=n 设置G1区域的大小,值是2的幂从1MB--32MB
-XX:MaxGCPauseMillis=n 设置GC的停顿时间,JVM尽可能停顿时间少于这个时间。
-XX:ConcGCThreads=n 并发使用GC的线程数
-XX:InitialingHeapOccupancyPercent=n 设置堆占用多少就出发GC
-XX:G1ReservePrecent=n 设置空闲时间的预留内存百分比Springboot相关JVM调优
java -server [jvm相关参数] -jar 包名5. Java内存对象布局
一个对象实例包含对象头、实例数据、对齐填充;对象头包含对象标记(MarkWord) 、类型指针、长度(只有数组对象有,普通对象中没有);MarkWord包含了hashcode、GC标记、GC次数、同步锁标记、偏向锁持有者。在64位系统中MarkWord占8字节、类元指针占8字节,总共16字节。
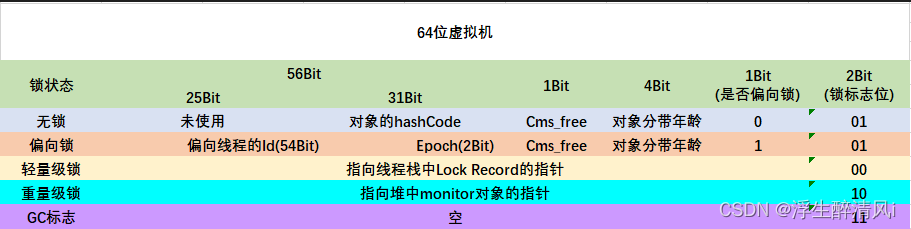
这就是为什么GC最大年龄是15,因为二进制1111就是15,age只分配了四位。类型指针是指向类元数据的指针(也就是指向方法区的 xxx的klass);实例数据是存放类属性field的信息,包括父类信息;对齐填充虚拟机要求对象起始地址必须是8字节的整倍数,不是必须存在的,仅仅为了对齐。一个对象的大小 = MarkWord(8字节) + 类型指针(4字节) + 实例数据(根据实际情况,空对象没有) + 对其填充(根据实际情况)。
通过JOL查看对象的内存分布情况,首先先导入maven信息。
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>通过JOL就可以查看当前虚拟机信息以及对象的内存布局。
Object o = new Object();
System.out.println(VM.current().details()); // 获取当前虚拟机信息
System.out.println(VM.current().objectAlignment()); // 获取对象的对齐数
System.out.println(ClassLayout.parseInstance(o).toPrintable()); // 获取一个对象的布局对象的内存布局:这里的前两个header是MrakWord,第三个是类型指针,第四个是填充对齐。这里默认是开启了指针压缩导致类型指针由8字节压缩成4字节。SIZE代表字节大小,OFFSET代表偏移量也就是这个字段所占的byte数,TYPE代表class中定义的类型,VALUE代表内存中的值,DESCRIPTION代表类型的描述。value值需要从右下角到左上角倒着看,每个字节按照顺序,字节之间按照逆序。

6. 锁升级的过程
在JDK1.6之前只有无锁和重量级锁两种模式,由于重锁是在内核态处理的,所以从无锁到重锁之间切换时非常消耗资源的,为了减少获得和释放锁的资源消耗,添加了两种锁的方式偏向锁和轻量级锁;在JDK15后偏向锁被废弃了。锁升级的过程如下。
无锁 --> 偏向锁 --> 轻量级锁(CAS) --> 重量级锁(synchronized)※ 无锁
在无锁的状态下打印对象的内存布局,可以发现最后两位是01,正是无锁的状态,但是现在还没有看见hashCode的值?
至于为什么没有看见hashCode的值是因为没有调用hashCode方法,只有手动调用后才会显示。

※ 偏向锁
是单线程竞争;一段同步代码一直被同一个线程访问,由于只有一个线程,那么该线程在后续访问中会自动获得锁。换言之,偏向锁会偏向第一个访问锁的线程,如果锁后续没有被其他线程访问,则持有偏向锁的线程永远不需要触发同步,也即偏向锁在资源没有竞争下消除了同步语句,都不用CAS,可直接提高性能。
可以通过命令在系统中看到,在JDK1.8中默认是开启偏向锁的,延迟4s(也就是程序执行4s后才会开启偏向锁,在JDK11中没有延迟)。
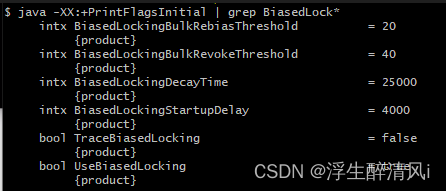
有两种触发偏向锁的方式,一种是直接在程序执行的时候直接sleep大于4秒的时间;第二种就是通过给定Java虚拟机参数。
-XX:BiasedLockingStartupDelay=0 将延迟设置为0s
-XX:-UseBiasedLocking 关闭偏向锁偏向锁的流程:偏向锁会将第一个访问锁的线程Id记录在自己的MarkWord中,第二次,会先判断当前线程Id和MarkWord保存的是否一致,如果一致则直接进入同步代码块无需加锁;如果不一致则需要抢占,如果抢占成功则修改MarkWord的中记录的线程Id,此时不会升级锁;如果失败则会在等待到 全局安全点(不会执行任何代码)、同时检查持有的偏向锁是否还在执行判断,如果持有偏向锁的线程正在执行同步代码块,则升级完CAS后,该线程还会占用CAS;如果持有偏向锁的线程已退出同步代码块,则剩下的线程进行CAS竞争;之后就会撤销偏向锁。
public void func2(){
Object o = new Object();
new Thread(() -> {
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}).start();
}设置完启动参数以后我们再次打印对象的内存布局会发现,MarkWord已经加上了线程Id。

※ 轻量级锁
是多线程竞争;但是任意时刻最多一个线程进行竞争,即不是很激烈的情况。可以通过关闭偏向锁的命令来验证轻量级锁。
Object o = new Object();
new Thread(() -> {
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}).start(); 当轻量级锁自旋一定次数以后就会升级成重量级锁。自旋次数在Java6之前自旋默认10次,或者自旋线程数超过CPU核数的一半,可以通过 -XX: PreBlockSpin = 10来修改;在Java6之后采用自适应自旋锁,其原理是如果本次自旋成功了,那么下次就会增大自旋的次数,反之会减少自选次数, 减少CPU的空转。
当轻量级锁自旋一定次数以后就会升级成重量级锁。自旋次数在Java6之前自旋默认10次,或者自旋线程数超过CPU核数的一半,可以通过 -XX: PreBlockSpin = 10来修改;在Java6之后采用自适应自旋锁,其原理是如果本次自旋成功了,那么下次就会增大自旋的次数,反之会减少自选次数, 减少CPU的空转。
※ 重量级锁
Object o = new Object();
new Thread(() -> {
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}).start();
new Thread(() -> {
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}).start();
升级成重量级锁之后 hashCode和GC年龄都去哪里了??
当一个对象计算过hashCode就无法进入偏向锁的状态了,会跳过偏向锁阶段直接进入轻量级锁;如果正处于偏向锁,并在此时调用了hashCode,就会撤销偏向锁,升级成为重量级锁(如果可以的话那么前后两次的hashCode就不能保持唯一);如果处于轻量锁状态,hashCOde会在当前锁的栈帧中存放,释放锁会将信息重新写回对象头内;如果处于重量级锁,对象头指向了重量级锁的位置 ObjetMonitor对象中会存储hashCode。