目录
1. 数据合并
2. 回文链表
3. 完美矩形
1. 数据合并
题目描述
将两个从小到大排列的一维数组 (维长分别为 m,n , 其中 m,n≤100) 仍按从小到大的排列顺序合并到一个新的一维数组中,输出新的数组.
输入描述
第 1 行一个正整数 m , 表示第一个要合并的一维数组中的元素个数
第 2 行一个正整数 n , 表示第二个要合并的一维数组中的元素个数
第 3 行输入 m 个整数 (每个数用空格分开) , 表示第一个数组元素的值.
第 4 行输入 n 个整数 (每个数用空格分开) , 表示第二个数组元素的值.
输出描述
一行,表示合并后的数据,共 m +n 个数
样例输入
3
4
1 3 5
2 4 6 8样例输出
1 2 3 4 5 6 8代码:
#include <iostream>
using namespace std;
void merge(int * a1, int m, int * a2, int n)
{
int m1 = m - 1;
int n1 = n - 1;
for (int i = m + n - 1; i >= 0; i--)
{
if (m1 < 0) a1[i] = a2[n1--];
else if (n1 < 0) a1[i] = a1[m1--];
else if (a1[m1] < a2[n1]) a1[i] = a2[n1--];
else a1[i] = a1[m1--];
}
}
int main()
{
int m;
int n;
cin >> m;
cin >> n;
int a1[201];
int a2[101];
for (int i = 0; i < m; i++) cin >> a1[i];
for (int i = 0; i < n; i++) cin >> a2[i];
merge(a1, m, a2, n);
for (int i = 0; i < m + n; i++) cout << a1[i] << " ";
return 0;
}输入输出:
3
4
1 3 5
2 4 6 8
1 2 3 4 5 6 8
--------------------------------
Process exited after 5.567 seconds with return value 0
请按任意键继续. . .
2. 回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

输入:head = [1,2,2,1] 输出:true
示例 2:
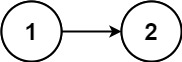
输入:head = [1,2] 输出:false
提示:
- 链表中节点数目在范围
[1, 105]内 0 <= Node.val <= 9
进阶:你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
代码:
#include <bits/stdc++.h>
using namespace std;
struct ListNode
{
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL) {}
};
class Solution
{
public:
bool isPalindrome(ListNode *head)
{
vector<int> v;
while (head != NULL)
{
v.push_back(head->val);
head = head->next;
}
for (int i = 0; i < v.size(); i++)
{
if (v[i] != v[v.size() - i - 1])
return false;
}
return true;
}
};
int CreateList(ListNode*& p, vector<int>& nums)
{
ListNode* q = (ListNode*)malloc(sizeof(ListNode));
q = p;
for (const auto& data : nums)
{
ListNode* temp = (ListNode*)malloc(sizeof(ListNode));
if (q != NULL)
{
q->val = data;
q->next = temp;
q = temp;
}
}
if(q != NULL)
{
q->next = NULL;
}
}
void PrintList(ListNode* p)
{
while(p->next != NULL)
{
cout << p->val << "->";
p = p->next;
}
cout << "null" << endl;
}
int main()
{
Solution s;
ListNode* head = (ListNode*)malloc(sizeof(ListNode));
vector <int> nums = {1,2,3,2,1};
CreateList(head, nums);
PrintList(head);
cout << s.isPalindrome(head) << endl;
return 0;
}3. 完美矩形
我们有 N 个与坐标轴对齐的矩形, 其中 N > 0, 判断它们是否能精确地覆盖一个矩形区域。
每个矩形用左下角的点和右上角的点的坐标来表示。例如, 一个单位正方形可以表示为 [1,1,2,2]。 ( 左下角的点的坐标为 (1, 1) 以及右上角的点的坐标为 (2, 2) )。
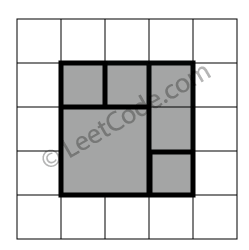
示例 1:
rectangles = [ [1,1,3,3], [3,1,4,2], [3,2,4,4], [1,3,2,4], [2,3,3,4] ]
返回 true。5个矩形一起可以精确地覆盖一个矩形区域。
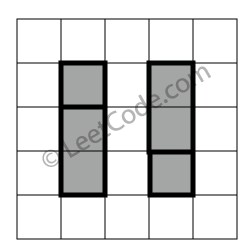
示例 2:
rectangles = [ [1,1,2,3], [1,3,2,4], [3,1,4,2], [3,2,4,4] ]
返回 false。两个矩形之间有间隔,无法覆盖成一个矩形。
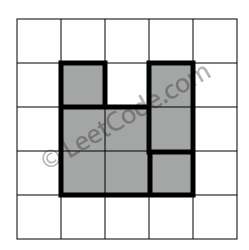
示例 3:
rectangles = [ [1,1,3,3], [3,1,4,2], [1,3,2,4], [3,2,4,4] ]
返回 false。图形顶端留有间隔,无法覆盖成一个矩形。
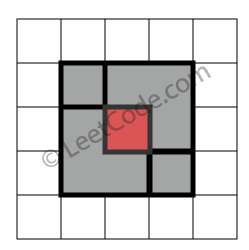
示例 4:
rectangles = [ [1,1,3,3], [3,1,4,2], [1,3,2,4], [2,2,4,4] ]
返回 false。因为中间有相交区域,虽然形成了矩形,但不是精确覆盖。
代码:
#include <bits/stdc++.h>
using namespace std;
class Solution
{
public:
bool isRectangleCover(vector<vector<int>> &ret)
{
set<pair<int, int>> s;
int x1 = INT_MAX, y1 = INT_MAX, x2 = INT_MIN, y2 = INT_MIN, area = 0;
for (int i = 0; i < ret.size(); ++i)
{
x1 = min(ret[i][0], x1);
x2 = max(ret[i][2], x2);
y1 = min(ret[i][1], y1);
y2 = max(ret[i][3], y2);
area += (ret[i][2] - ret[i][0]) * (ret[i][3] - ret[i][1]);
if (s.find({ret[i][0], ret[i][1]}) == s.end())
s.insert({ret[i][0], ret[i][1]});
else
s.erase({ret[i][0], ret[i][1]});
if (s.find({ret[i][2], ret[i][3]}) == s.end())
s.insert({ret[i][2], ret[i][3]});
else
s.erase({ret[i][2], ret[i][3]});
if (s.find({ret[i][0], ret[i][3]}) == s.end())
s.insert({ret[i][0], ret[i][3]});
else
s.erase({ret[i][0], ret[i][3]});
if (s.find({ret[i][2], ret[i][1]}) == s.end())
s.insert({ret[i][2], ret[i][1]});
else
s.erase({ret[i][2], ret[i][1]});
}
if (s.size() != 4 || !s.count({x1, y1}) || !s.count({x1, y2}) || !s.count({x2, y1}) || !s.count({x2, y2}))
return false;
return area == (x2 - x1) * (y2 - y1);
}
};
int main()
{
Solution s;
vector<vector<int>> rect = {
{1,1,3,3},
{3,1,4,2},
{3,2,4,4},
{1,3,2,4},
{2,3,3,4}
};
cout << s.isRectangleCover(rect) << endl;
rect = {{1,1,2,3}, {1,3,2,4}, {3,1,4,2}, {3,2,4,4}};
cout << s.isRectangleCover(rect) << endl;
return 0;
}附: 单链表的操作
基本操作:
1、单链表的初始化
2、单链表的创建
3、单链表的插入
4、单链表的删除
5、单链表的取值
6、单链表的查找
7、单链表的判空
8、单链表的求长
9、单链表的清空
10、单链表的销毁
11、单链表的打印
线性表链式存储结构的优点:
1、结点空间可以动态申请和释放;
2、数据元素的逻辑次序靠结点的指针来指示,插入和删除时不需要移动数据元素。
线性表链式存储结构的缺点:
1、存储密度小,每个结点的指针域需额外占用存储空间。当每个结点的数据域所占字节不多时,指针域所占存储空间的比重显得很大;
2、链式存储结构是非随机存取结构。对任一结点的操作都要从头指针依指针链查找到该结点,这增加了算法的复杂度。
以下为单链表的常用操作代码,来源于网络未经测试,仅供参考。
#include<algorithm>
#include<iostream>
#include<vector>
using namespace std;
struct ListNode
{
int data;
ListNode* next;//结构体指针
};
void Listprintf(ListNode* phead)
{
ListNode* cur=phead;
while (cur != NULL)
{
cout << cur->data << "->";
cur = cur->next;
}
}
void Listpushback(ListNode** pphead, int x)
{
ListNode* newnode = new ListNode{ x,NULL };
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
ListNode* tail= *pphead;
while(tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
void test_1()
{
ListNode* phead = NULL;
Listpushback(&phead, 1);
Listpushback(&phead, 2);
Listpushback(&phead, 3);
Listprintf(phead);
}
int main()
{
test_1();
return 0;
}#include<algorithm>
#include<iostream>
#include<vector>
using namespace std;
struct ListNode
{
int data;
ListNode* next;//结构体指针
};
void Listprintf(ListNode* phead)
{
ListNode* cur=phead;
while (cur != NULL)
{
cout << cur->data << "->";
cur = cur->next;
}
cout << "NULL" << endl;
}
//尾插
void Listpushback(ListNode** pphead, int x)
{
ListNode* newnode = new ListNode{ x,NULL };
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
ListNode* tail= *pphead;
while(tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
//头插
void Listpushfront(ListNode** pphead, int x)
{
ListNode* newnode = new ListNode{ x,NULL };
newnode->next = *pphead;
*pphead = newnode;
}
//尾删
void Listpopback(ListNode** pphead)
{
if (*pphead == NULL)
{
return;
}
if ((*pphead)->next == NULL)
{
delete(*pphead);
*pphead = NULL;
}
else
{
ListNode* tail = *pphead;
ListNode* prev = NULL;
while (tail->next)
{
prev = tail;
tail = tail->next;
}
delete(tail);
tail = NULL;
prev->next = NULL;
}
}
//头删
void Listpopfront(ListNode** pphead)
{
if (*pphead == NULL)
{
return;
}
else
{
ListNode* newnode = (*pphead)->next;
delete(*pphead);
*pphead = newnode;
}
}
//查找元素,返回值是地址
ListNode* Listfind(ListNode* phead, int x)
{
ListNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
return NULL;
}
//插入元素,在pos的前一个位置插入
//配合Listfind使用,具体使用见test_insert函数
void Listinsert(ListNode** phead, ListNode* pos, int x)
{
ListNode* newnode = new ListNode{ x,NULL };
if (*phead == pos)
{
newnode->next = (*phead);
*phead = newnode;
}
else
{
ListNode* posprev = *phead;
while (posprev->next != pos)
{
posprev = posprev->next;
}
posprev->next = newnode;
newnode->next = pos;
}
}
//单链表并不适合在前一个位置插入,因为运算较麻烦,会损失效率
//包括c++中为单链表提供的库函数也只有一个insert_after而没有前一个位置插入
//在后一个位置插入相对简单
void Listinsert_after(ListNode** phead, ListNode* pos, int x)
{
ListNode* newnode = new ListNode{ x,NULL };
newnode->next = pos->next;
pos->next = newnode;
}
//删除指定位置的节点
void Listerase(ListNode** pphead, ListNode* pos)
{
if (*pphead == pos)
{
*pphead = pos->next;
delete(pos);
}
else
{
ListNode* prev = *pphead;
while (prev->next!=pos)
{
prev = prev->next;
}
prev->next = pos->next;
delete(pos);
}
}
//释放链表
void Listdestory(ListNode** pphead)
{
ListNode* cur = *pphead;
while(cur)
{
ListNode* next = cur->next;
delete(cur);
cur = next;
}
*pphead = NULL;
}
void test_insert()
{
ListNode* phead = NULL;
Listpushback(&phead, 1);
Listpushback(&phead, 2);
Listpushback(&phead, 3);
Listprintf(phead);
ListNode* pos = Listfind(phead, 2);
if (pos != NULL)
{
Listinsert(&phead, pos, 20);
}
Listprintf(phead);
pos = Listfind(phead, 2);
if (pos != NULL)
{
Listinsert_after(&phead, pos, 20);
}
Listprintf(phead);
Listdestory(&phead);
}
void test_find()
{
ListNode* phead = NULL;
Listpushback(&phead, 1);
Listpushback(&phead, 2);
Listpushback(&phead, 3);
Listprintf(phead);
ListNode* pos = Listfind(phead, 2);
if (pos != NULL)
{
pos->data = 20;//Listfind不仅能查找,也能借此修改,这也是函数返回地址的原因
}
Listprintf(phead);
Listdestory(&phead);
}
void test_erase()
{
ListNode* phead = NULL;
Listpushback(&phead, 1);
Listpushback(&phead, 2);
Listpushback(&phead, 3);
Listprintf(phead);
ListNode* pos = Listfind(phead, 2);
if (pos != NULL)
{
Listerase(&phead, pos);
}
Listprintf(phead);
Listdestory(&phead);
}
void test_pop_and_push()
{
ListNode* phead = NULL;
Listpushback(&phead, 1);
Listpushback(&phead, 2);
Listpushback(&phead, 3);
Listprintf(phead);
Listpushfront(&phead, 1);
Listpushfront(&phead, 2);
Listpushfront(&phead, 3);
Listprintf(phead);
Listpopback(&phead);
Listpopfront(&phead);
Listprintf(phead);
Listdestory(&phead);
}
int main()
{
//test_pop_and_push();
test_find();
//test_insert();
//test_erase();
return 0;
}
#include<algorithm>
#include<iostream>
#include<vector>
using namespace std;
struct ListNode
{
int data;
ListNode* next;//结构体指针
};
void Listprintf(ListNode* phead)
{
ListNode* cur=phead;
while (cur != NULL)
{
cout << cur->data << "->";
cur = cur->next;
}
cout << "NULL" << endl;
}
void Listpushback(ListNode** pphead, int x)
{
ListNode* newnode = new ListNode{ x,NULL };
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
ListNode* tail= *pphead;
while(tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
ListNode* creatlist()
{
ListNode* phead = NULL;
Listpushback(&phead, 1);
Listpushback(&phead, 9);
Listpushback(&phead, 6);
Listpushback(&phead, 8);
Listpushback(&phead, 6);
Listpushback(&phead, 2);
Listpushback(&phead, 3);
return phead;
}
ListNode* removeElements(ListNode* head, int x)
{
ListNode* prev = NULL;
ListNode* cur = head;
while (cur)
{
if (cur->data == x)
{
if (cur == head)//如果第一个元素就是要删除的,进行头删
{
head = cur->next;
delete(cur);
cur = head;
}
else
{
prev->next = cur->next;
delete(cur);
cur = prev->next;
}
}
else
{
prev = cur;
cur = cur->next;
}
}
return head;
}
int main()
{
ListNode*phead = creatlist();//先创建一条链表
Listprintf(phead);
phead = removeElements(phead, 6);//删除值为6的节点
Listprintf(phead);
return 0;
}ListNode* reverseList(ListNode* head)
{
if (head == NULL)
{
return NULL;
}
ListNode* prev, * cur, * next;
prev = NULL;
cur = head;
next = cur->next;
while (cur)
{
cur->next = prev;//翻转指针
//往后迭代
prev = cur;
cur = next;
if (next)//这里是因为当cur指向最后一个节点的时候,next就已经是NULL了,这个时候如果再执行next=next->next则会出现错误
{
next = next->next;
}
}
return prev;
}ListNode* reverseList(ListNode* head)
{
ListNode* cur = head;
ListNode* newlist = NULL;
ListNode* next = NULL;
while (cur)
{
next = cur->next;
//头插
cur->next = newlist;
newlist = cur;
//往后迭代
cur = next;
}
return newlist;
}ListNode* middleNode(ListNode* head)
{
ListNode* slow, * fast;
slow = fast = head;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}ListNode* findK(ListNode* head, int k)
{
ListNode* fast, * slow;
fast = slow = head;
while(k--)
{
if (fast == NULL)//如果当fast等于NULL时k仍不为0,则k大于链表长度
{
return NULL;
}
fast = fast->next;
}
while (fast)
{
fast = fast->next;
slow = slow->next;
}
return slow;
}
ListNode* mergeTwoList(ListNode* l1, ListNode* l2)
{
if (l1 == NULL)//如果一个链表为空,则返回另一个
{
return l2;
}
if (l2 == NULL)
{
return l1;
}
ListNode* head = NULL;
ListNode* tail = NULL;
while (l1 && l2)
{
if (l1->data < l2->data)
{
if (head == NULL)
{
head = tail =l1;
}
else
{
tail->next = l1;
tail = l1;
}
l1 = l1->next;
}
else
{
if (head == NULL)
{
head = tail = l2;
}
else
{
tail->next = l2;
tail = l2;
}
l2 = l2->next;
}
}
if (l1)
{
tail->next = l1;
}
if(l2)
{
tail->next = l2;
}
return head;
}ListNode* mergeTwoList(ListNode* l1, ListNode* l2)
{
if (l1 == NULL)//如果一个链表为空,则返回另一个
{
return l2;
}
if (l2 == NULL)
{
return l1;
}
ListNode* head = NULL, * tail = NULL;
head = tail = new ListNode;//哨兵位的头结点
while (l1 && l2)
{
if (l1->data < l2->data)
{
tail->next = l1;
tail = l1;
l1 = l1->next;
}
else
{
tail->next = l2;
tail = l2;
l2 = l2->next;
}
}
if (l1)
{
tail->next = l1;
}
if (l2)
{
tail->next = l2;
}
ListNode* list = head->next;
delete(head);
return list;
}
ListNode* partition(ListNode* phead, int x)
{
ListNode* lesshead, * lesstail, * greaterhead, * greatertail;
lesshead = lesstail = new ListNode;//定义一个哨兵位头结点,方便尾插
lesstail->next = NULL;
greaterhead = greatertail = new ListNode;
greatertail->next = NULL;
ListNode* cur = phead;
while (cur)
{
if (cur->data < x)
{
lesstail->next = cur;
lesstail = cur;
}
else
{
greatertail->next = cur;
greatertail = cur;
}
cur = cur->next;
}
lesstail->next = greaterhead->next;
greatertail->next = NULL;//举个例子,这样一条链表:1->4->15->5,现在给的x是6,那么排序后15应该在最后,正因如此,重新排序后15的next是没变的,仍然指向5,不手动将next改为NULL,就会成环,无限排下去。
ListNode* newhead = lesshead->next;
delete(lesshead);
delete(greaterhead);
return newhead;
}ListNode* middleNode(ListNode* head)
{
ListNode* slow, * fast;
slow = fast = head;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
ListNode* reverseList(ListNode* head)
{
ListNode* cur = head;
ListNode* newlist = NULL;
ListNode* next = NULL;
while (cur)
{
next = cur->next;
//头插
cur->next = newlist;
newlist = cur;
//往后迭代
cur = next;
}
return newlist;
}
bool check(ListNode* head)
{
ListNode* mid = middleNode(head);
ListNode* rhead = reverseList(mid);
ListNode* curHead = head;
ListNode* curRhead = rhead;
while(curHead&&curRhead)
{
if (curHead->data != curRhead->data)
return false;
else
{
curHead = curHead->next;
curRhead = curRhead->next;
}
}
return true;
}