0 建议学时
2学时
1 KNN算法
1.1 KNN原理
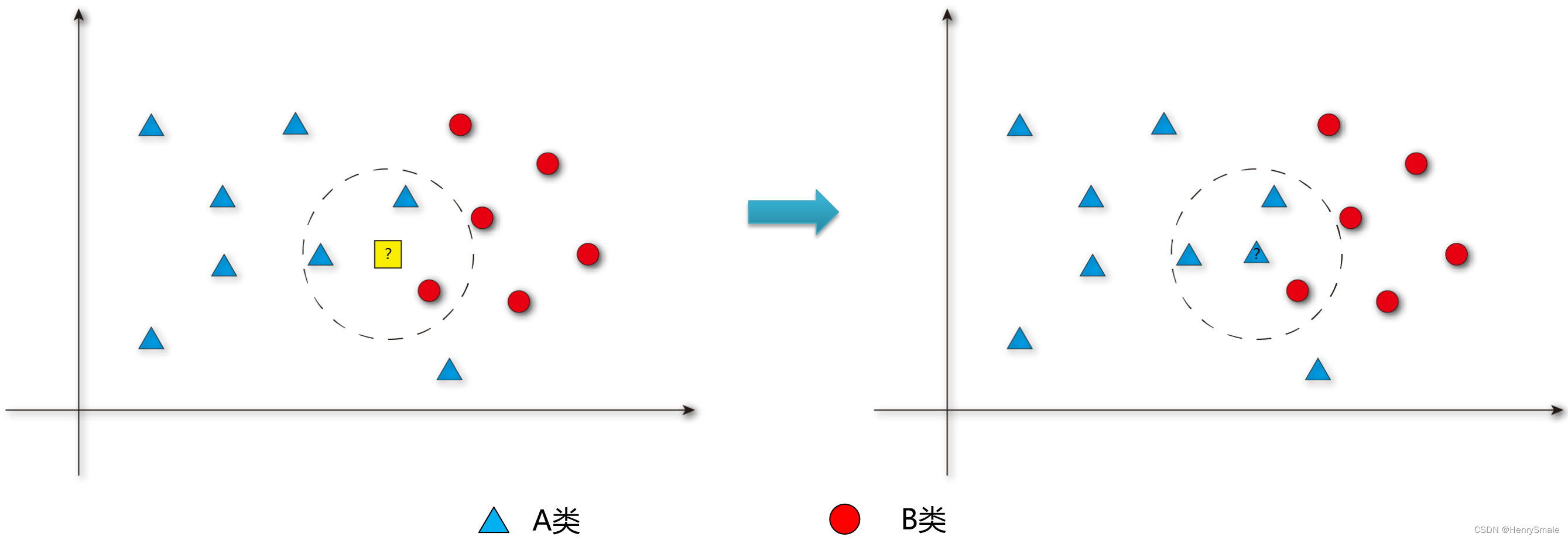
KNN:K Nearest Neighbors,即K个最近的邻居;
预测一个新值
x
x
x,根据距离最近的K个点的类别来判断
x
x
x属于哪一类。
算法核心要点:
- K值的选取非常重要;
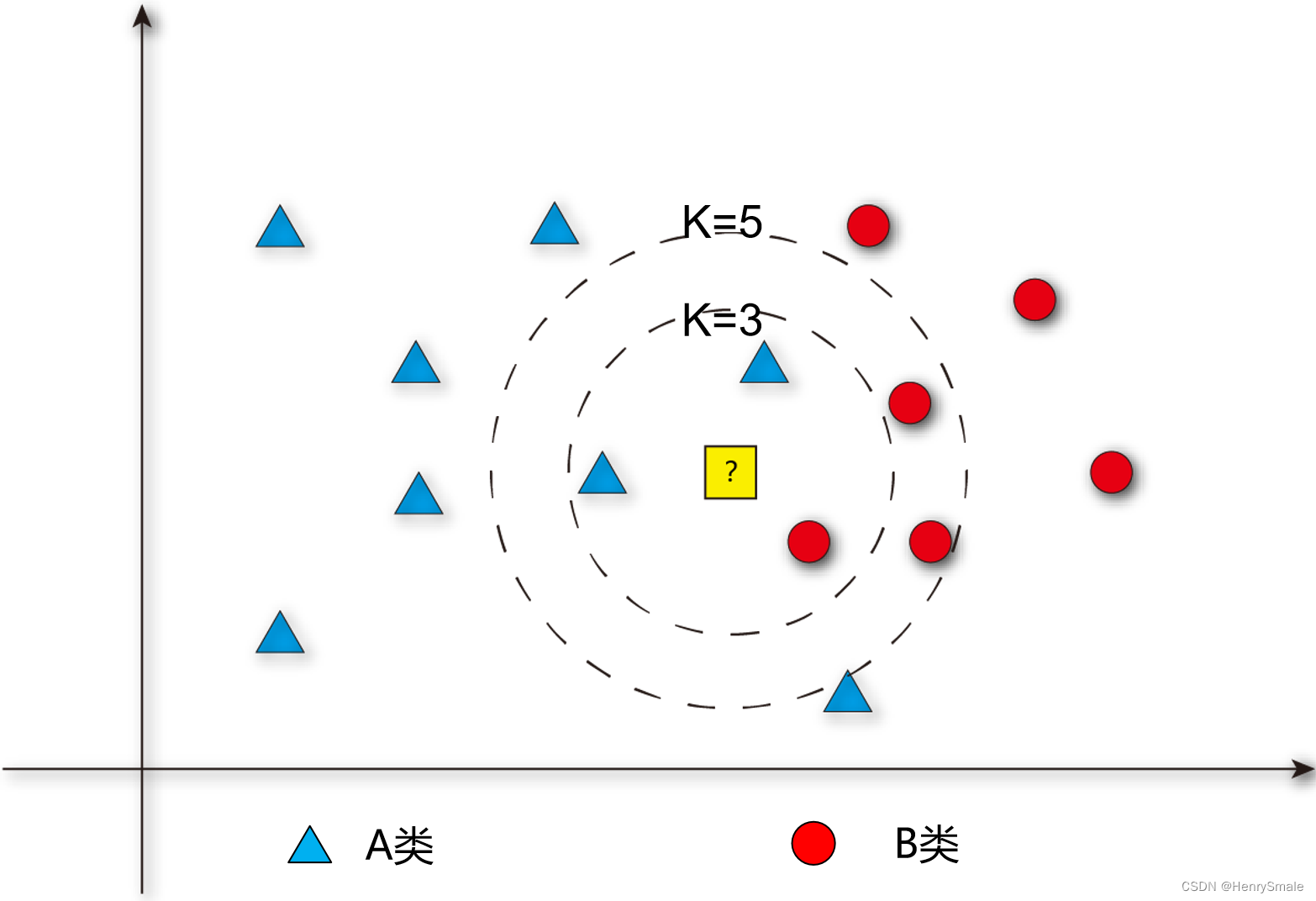
- 距离公式的选择,比如欧几里得距离。
d ( x , y ) = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 + ⋯ + ( x n − y n ) 2 = ∑ i = 1 n ( x i − y i ) 2 d(x, y) =\sqrt{\left(x_{1}-y_{1}\right)^{2}+\left(x_{2}-y_{2}\right)^{2}+\cdots+\left(x_{n}-y_{n}\right)^{2}}=\sqrt{\sum_{i=1}^{n}\left(x_{i}-y_{i}\right)^{2}} d(x,y)=(x1−y1)2+(x2−y2)2+⋯+(xn−yn)2=i=1∑n(xi−yi)2
1.2 KNN应用于建筑工程质量评价
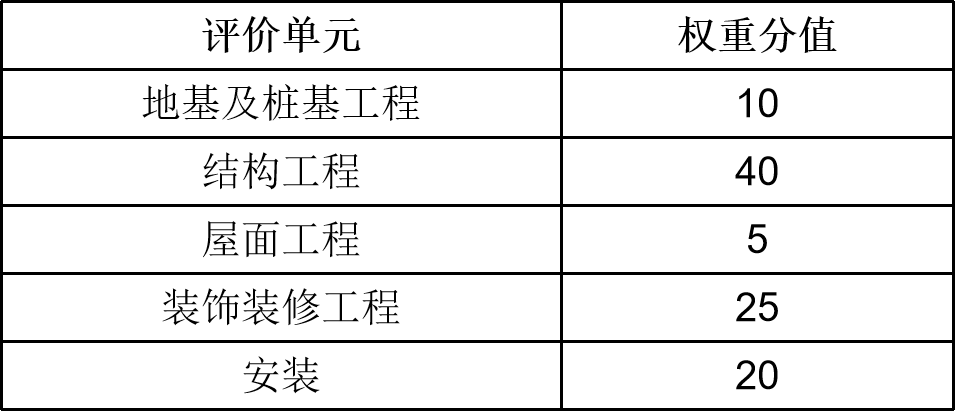
建筑工程施工质量优良评价分哪两个阶段进行?两者关系是什么?
- 分为工程结构和单位工程两个阶段进行。
- 工程结构施工质量优良评价应在地基及桩基工程、结构工程以及附属的地下防水层完工。且主体工程质量验收合格的基础上进行。
- 单位工程优良评价应在工程结构优良的基础上,在竣工验收合格之后进行。
- 工程结构达不到优良,单位工程不能评价为优良。
如何科学的进行多维质量评价?
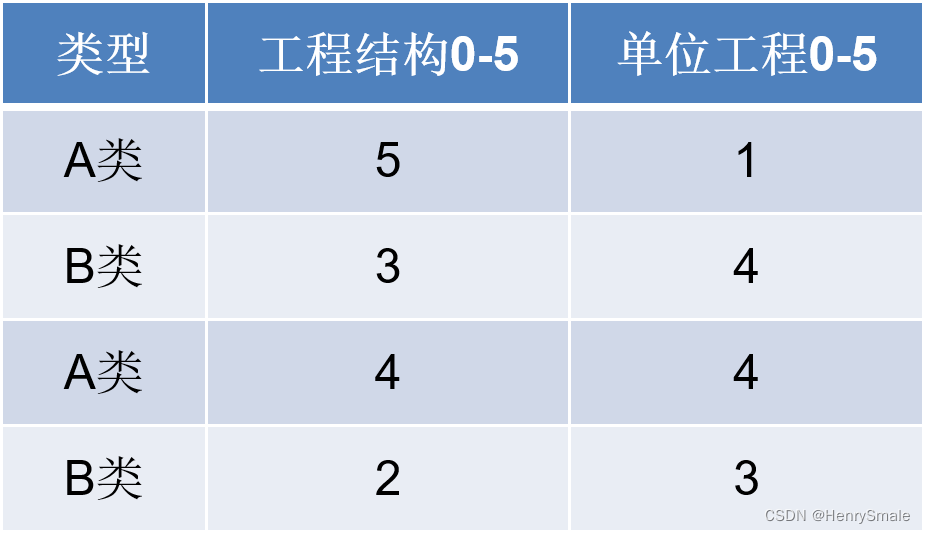
训练数据如下:
import numpy as np
import operator
def knn(trainData, testData, labels, k):
rowSize = trainData.shape[0] # 计算训练样本的行数
diff = np.tile(testData, (rowSize, 1))-trainData # 计算训练样本和测试样本的差值
sqrDiff = diff ** 2 # 计算差值的平方和
sqrDiffSum = sqrDiff.sum(axis=1)
distances = sqrDiffSum ** 0.5 # 计算距离
sortDistance = distances.argsort() # 对所得的距离从低到高进行排序
count = {}
for i in range(k):
vote = labels[sortDistance[i]]
count[vote] = count.get(vote, 0) + 1
print("///sortDistance")
print(sortDistance)
print(vote)
sortCount = sorted(count.items(), key=operator.itemgetter(1), reverse=True) # 对类别出现的频数从高到低进行排序
return sortCount[0][0] # 返回出现频数最高的类别
trainData = np.array([[5, 1], [3, 4], [4, 4], [2, 3]])
labels = ['A类', 'B类', 'A类', 'B类']
testData = [3, 2]
X = knn(trainData, testData, labels, 3)
print(X)
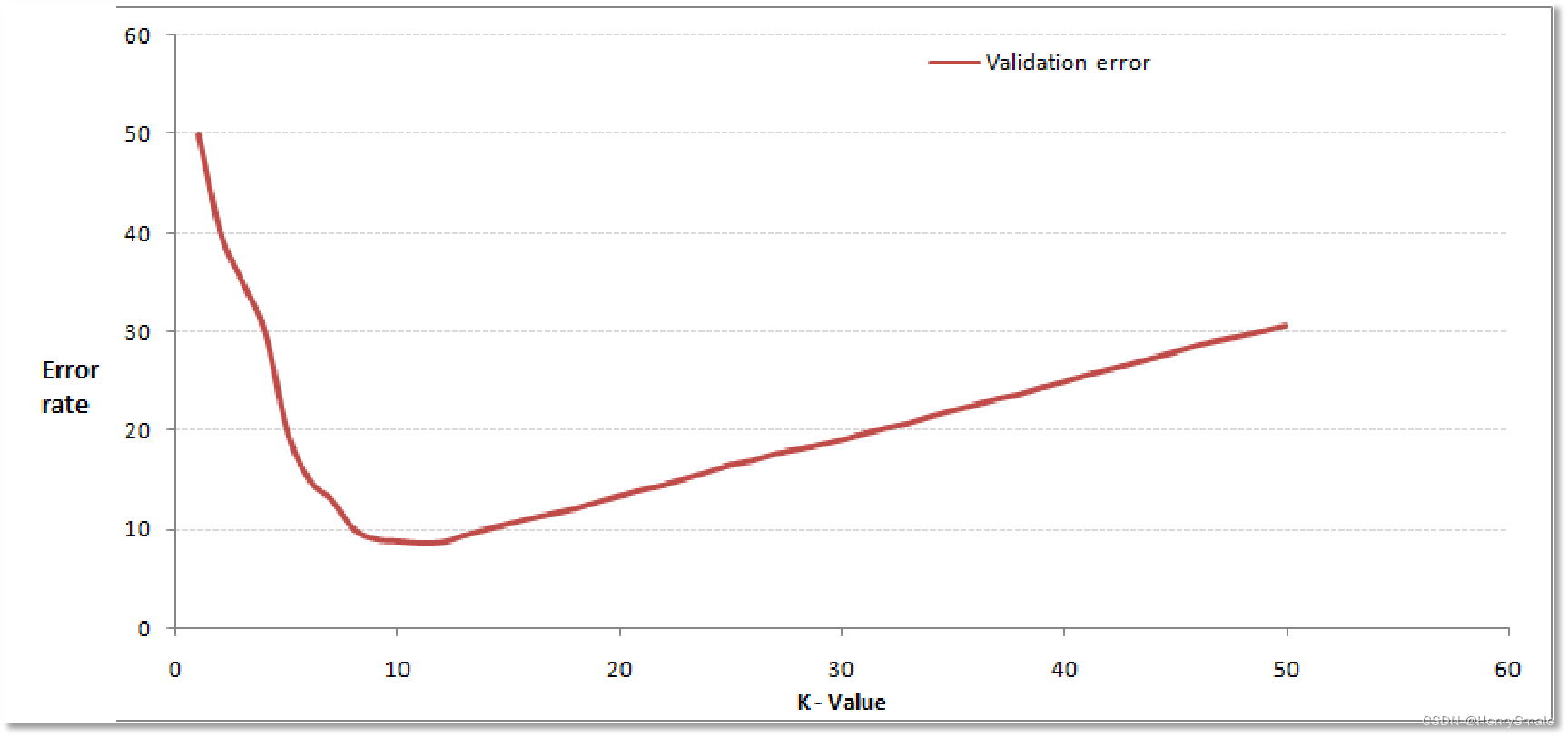
K值的选取
2 课后延伸
思考题:KNN与传统的权重方式的评价方式的使用范围?优缺点?
附录
Tile函数
-
原型:numpy.tile(A, reps)
tile共有2个参数,A指待输入数组,reps则决定A重复的次数。整个函数用于重复数组A来构建新的数组。
假设reps的维度为d,那么新数组的维度为max(d,A.ndim)。 -
ndarray.ndim
指数组的维度,即数组轴(axes)的个数,其数量等于秩(rank)。通俗地讲,我们平时印象中的数组就是一维数组,维度为1、轴的个数为1、秩也等于1;最常见的矩阵就是二维数组,维度为2、轴的个数为2(可以理解为由x轴、y轴组成)、秩等于2;我们所知的空间就相当于三维数组,维度为3、轴的个数为3(x、y、z轴)、秩等于3;以此类推。
import numpy as np
A=[[8,9]]
diff = np.tile(A, (2, 1)) #行复制,np.tile(A,(2,1))第一个参数为Y轴扩大倍数,第二个为X轴扩大倍数,X轴扩大一倍便为不复制。
print(diff)
[[8 9]
[8 9]]
import numpy as np
A=[[8,9]]
diff = np.tile(A, (1, 2)) # 列复制
print(diff)
[[8 9 8 9]]
operator.itemgetter函数
import operator
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为序号
a = [1,2,3]
>>> b=operator.itemgetter(1) //定义函数b,获取对象的第1个域的值
>>> b(a)
2
a = [1,2,3]
>>> b=operator.itemgetter(1,0) //定义函数b,获取对象的第1个域和第0个的值
>>> b(a)
>>> (2, 1)
import operator
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
根据第二个域进行排序
sorted(students, key=operator.itemgetter(2))
argsort函数
np.argsort(a, axis=-1, kind=‘quicksort’, order=None)
函数功能:将a中的元素从小到大排列,提取其在排列前对应的index(索引)输出
import numpy as np
x=np.array([1,4,3])
y=x.argsort()
print(y)
[0 2 1]