离线数仓-5-数据仓库环境准备
- 离线数仓-5-数据仓库环境准备
- 1.数据仓库运行环境
- 1.Hive环境搭建
- 1.Hive引擎
- 2.Hive on Spark配置
- 2.Yarn环境配置
- 2.数据仓库开发环境
- 3.模拟数据准备
离线数仓-5-数据仓库环境准备
1.数据仓库运行环境
- 数仓之外需要做的事情:
- 数据安全认证:在大数据层面:1.用户认证:Kerberos来管理认证 2.用户授权:Ranger来管理授权
- 数据质量监控
- 大数据集群监控
- HDFS超级用户:是由启动NameNode的用户来决定的,谁启动了NameNode谁就是超级用户。
1.Hive环境搭建
1.Hive引擎
- Hive引擎包括:默认MR、Tez、Spark。
- Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
- Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
2.Hive on Spark配置
- hive中两个服务:
hiveserver2服务
metostore服务 - hive on spark 环境下面,一个hive会话对应一个spark任务,打开一个会话框执行第一个任务的时候,需要启动spark相关的服务:Exector/Driver,启动这些服务需要损耗时间,所以执行第一个任务的时候,需要耗费一些时间,后面再执行任务的话,就不需要损耗启动服务的时间了。
- hive on mapreduce 环境下面,一个sql对应一个mr任务。
- 1.兼容性说明
- 注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译步骤:官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0,如果编译通过,直接打包获取jar包。如果报错,就根据提示,修改相关方法,直到不报错,打包获取jar包。
- 注意:官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
- 2.在Hive所在节点部署Spark
- 3.配置SPARK_HOME环境变量
- 4.在hive中创建spark配置文件
- 5.向HDFS上传Spark纯净版jar包
- 6.修改hive-site.xml文件,添加如下内容:
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
2.Yarn环境配置
-
1.增加ApplicationMaster资源比例 (仅在测试环境调整,正式上线环境不需要调整)
-
1)在hadoop102的/opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml文件中修改如下参数值
[atguigu@hadoop102 hadoop]$ vim capacity-scheduler.xml
<property> <name>yarn.scheduler.capacity.maximum-am-resource-percent</name> <value>0.8</value> </property> -
2)分发capacity-scheduler.xml配置文件
[atguigu@hadoop102 hadoop]$ xsync capacity-scheduler.xml -
3)关闭正在运行的任务,重新启动yarn集群
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
-
-
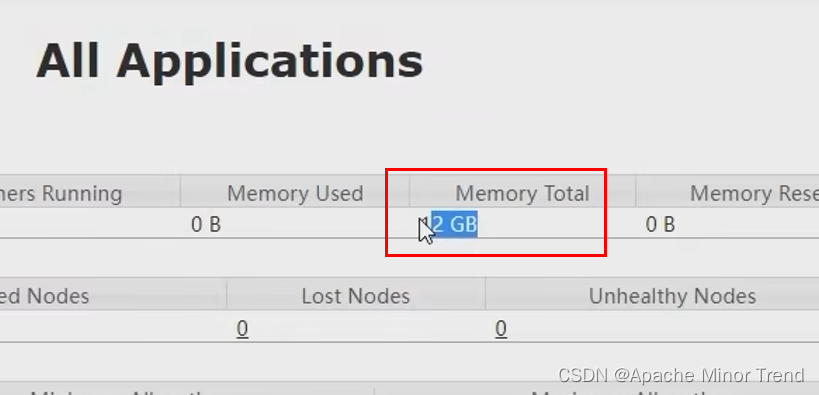
2.yarn上的Memory Total这个参数对应的12G,是通过配置每台节点的yarn-site.xml中的这个参数,然后相加到一起的结果。

2.数据仓库开发环境
- 数仓开发工具可选用DBeaver或者DataGrip。两者都需要用到JDBC协议连接到Hive,故需要启动HiveServer2。
3.模拟数据准备
-
通常企业在开始搭建数仓时,业务系统中会存在历史数据,一般是业务数据库存在历史数据,而用户行为日志无历史数据。
- 1)用户行为日志 文件–>Flume -->Kafka–> Flume -->Hdfs
- 2)业务数据
- 全量表同步 mysql --> DataX --> Hdfs
- 增量表同步
- 增量表首日全量同步 mysql -->Maxwell的bootStrap功能 --> Kafka --> Flume --> Hdfs
- 增量表实时同步 mysql -->Maxwell实时功能 --> Kafka --> Flume --> Hdfs
-
mysql数据使用maxwell进行同步,maxwell监控的是mysql的binlog日志,其中maxwell支持断点续传功能,实际上是将binlog位置存放在对应mysql的positions中,记录了位置信息。

- mysql中也记录了当前数据的binlog位置信息,直接在mysql中使用命令查看:show master status;

- mysql中也记录了当前数据的binlog位置信息,直接在mysql中使用命令查看:show master status;