1 LOF算法
局部异常因子(Local Outlier Factor,LOF)算法是目前比较常用的离群点检测算法,该算法通过一种模糊的手段来判断数据对象是否为异常点。
- 对象 p p p的 k k k距离:在数据集 D D D中,将对象 p p p与距其第 k k k远的对象 o o o之间的距离定义为 对象 p p p的 k k k距离。记为: k − d i s t a n c e ( p ) = d ( p , o ) k-distance(p)=d(p,o) k−distance(p)=d(p,o)。其中 d ( p , o ) d(p,o) d(p,o)表示对象 p p p到对象 o o o的距离。
- 对象 p p p的 k − d i s t a n c e k-distance k−distance邻域:对象 p p p的 k − d i s t a n c e k-distance k−distance邻域是指 D D D中的对象 q q q到 p p p的距离不大于 k − d i s t a n c e ( p ) k-distance(p) k−distance(p)的所有对象的集合。记为: N k − d i s t a n c e ( p ) = { q ∈ D / { p } ∣ d ( p , q ) ≤ k − d i s t a n c e ( p ) } N_{k-distance}(p)=\{q\in D/\{p\}|d(p,q)\leq k-distance(p) \} Nk−distance(p)={q∈D/{p}∣d(p,q)≤k−distance(p)}
- 对象 p p p到对象 o o o的可达距离: r e a c h − d i s t k ( p , o ) = m a x { k − d i s t a n c e ( o ) , d ( p , o ) } reach-dist_{k}(p,o)=max\{k-distance(o),d(p,o)\} reach−distk(p,o)=max{k−distance(o),d(p,o)}
- 对象 p p p的局部可达密度: l r d M i n P t s ( p ) = ∣ N M i n P t s ( p ) ∣ ∑ o ∈ N M i n P t s ( p ) r e a c h − d i s t M i n P t s ( p , o ) lrd_{MinPts}(p)=\frac{|N_{MinPts}(p)|}{\sum_{o\in N_{MinPts}(p)}reach-dist_{MinPts}(p,o)} lrdMinPts(p)=∑o∈NMinPts(p)reach−distMinPts(p,o)∣NMinPts(p)∣从上式可以看出, p p p的局部可达密度是 p p p的 M i n P t s MinPts MinPts个最近邻居的平均可达距离的倒数。
- 对象 p p p的局部离群因子定义如下: L O F M i n P t s ( p ) = ∑ o ∈ N M i n P t s ( p ) l r d M i n P t s ( o ) l r d M i n P t s ( p ) ∣ N M i n P t s ( p ) ∣ LOF_{MinPts}(p)=\frac{ \sum_{o\in N_{MinPts}(p)} \frac{lrd_{MinPts}(o)}{lrd_{MinPts}(p)} }{|N_{MinPts}(p)|} LOFMinPts(p)=∣NMinPts(p)∣∑o∈NMinPts(p)lrdMinPts(p)lrdMinPts(o) p p p的离群因子显示其离散程度,是 p p p的 M i n P t s MinPts MinPts个最近邻数据对象的局部密度可达平均值与 p p p的局部可达密度之间的比值。
2 Python实现
这里仅介绍使用sklearn包中的LocalOutlierFactor的用法。LocalOutlierFactor方法中的主要参数如下:
| 参数 | 作用 |
|---|---|
| n_neighbors | 邻居数 |
| novelty | 当为False时进行异常值检测,当为True时进行新颖性检测。在进行新颖性检测时,在新数据集上只能使用predict、decision_function、score_samples这三个方法。并且这种方法获得的结果可能和标准的LOF得到的结果不同。 |
其具体用法举例如下:
import numpy as np
import pandas as pd
from sklearn.neighbors import LocalOutlierFactor as LOF
from sklearn.datasets import load_iris
from matplotlib import pyplot as plt
#构造数据集
X,_=load_iris(return_X_y=True)
X=X[:53,2:]
#LOF
lof=LOF(n_neighbors=10)
lof.fit(X)
op_lof=lof.negative_outlier_factor_ #值越接近-1,越接近正常点
plt.scatter(X[:,0],X[:,1],c=op_lof)
plt.colorbar()
plt.show()
其最终结果如下:
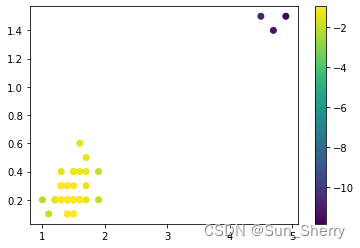
从图中也可以看出,右上角的三个点是异常点的可能性较大,其对应的negative_outlier_factor值较小。
参考文献
- 《局部离群点检测算法的研究》
- https://zhuanlan.zhihu.com/p/346779842
- https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.LocalOutlierFactor.html#sklearn.neighbors.LocalOutlierFactor