承接上文证明CPU指令是乱序执行的
当多个cpu访问同一份数据的时候怎么保证数据的一致性?
在最底层级别的控制有好多种:
第一种叫关中断,就是访问任何数据的时候必须有一个中断信号量的存在。很多传统的cpu就是靠它实现的,从内存读东西的时候实际上是通过中断响应去读的,比如访问这块内存的时候把中断给关了,任何读也好,写也好,io操作中断全不响应,就没有人能打断你,因为把能打断我的所有的指令都给关了,只要没人打断你,就一定能保证数据的一致性,这也涉及到芯片中断的内容;
第二种就是CPU缓存一致性;
第三种就是系统屏障:cpu访问内存数据,把数据线锁住,只允许一颗cpu传数据,其他cpu就不能传,同一时刻只有一个cpu可以访问这个数据,

怎么防止指令重排序?
第一种情况是禁止编译器乱序,有的代码在编译的过程中就直接乱序了;
第二种是使用内存屏障阻止指令乱序执行。
随便写2个指令,在编译器编译的时候就可能会产生乱序,只要前后没有依赖关系就有可能产生,这是在编译阶段;有前后关联关系的是不能够随便换顺序的,比如x=1和y=x+1;没有关联关系的话,就有可能换顺序,比如x=1和y=2。
c语言的volatile,底层是通过这条指令禁止编译器将前后2个指令换顺序执行的。

a=1和b=d这两个指令在编译器编译的时候不能换顺序执行,这种被称为内存屏障。
volatile是指令级别的屏障 ,它也是一种特殊的指令;
不同的cpu,内存屏障的指令是不一样的,因特尔的内存屏障有lfence(读屏障)、sfence(写屏障)、mfence(不管读还是写都不能越过)。
内存屏障指令有很多种,不同的cpu是不同的指令,使用内存屏障来阻止指令的乱序执行。
除了lfence、mfence、sfence这些内存屏障指令之外的其他有哪些内存屏障?
在jvm中也存在内存屏障,jvm不是一台实体的机器,不像intel一样具备一个物理的cpu,jvm只是一个逻辑概念,jvm内存屏障一共规定了4类,所有实现jvm规范的虚拟机必须实现四个屏障:

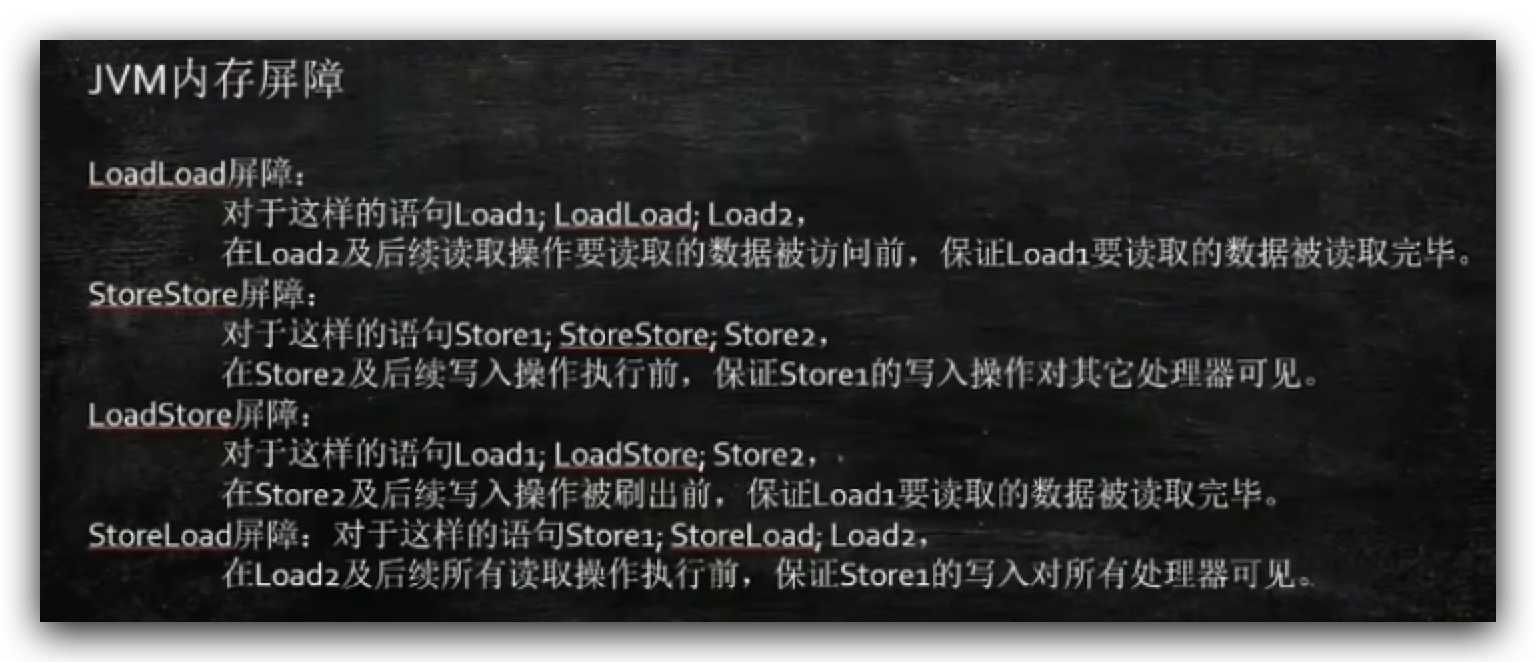
读读指令中间加一个LoadLoad(LL屏障),读读就不能换顺序;
写写指令中间加一个SS屏障,写写就不能换顺序;
读写指令中间加一个LS屏障,读写指令不能换顺序。
规定了相邻的2个操作不能换顺序,就相当于一个屏障。
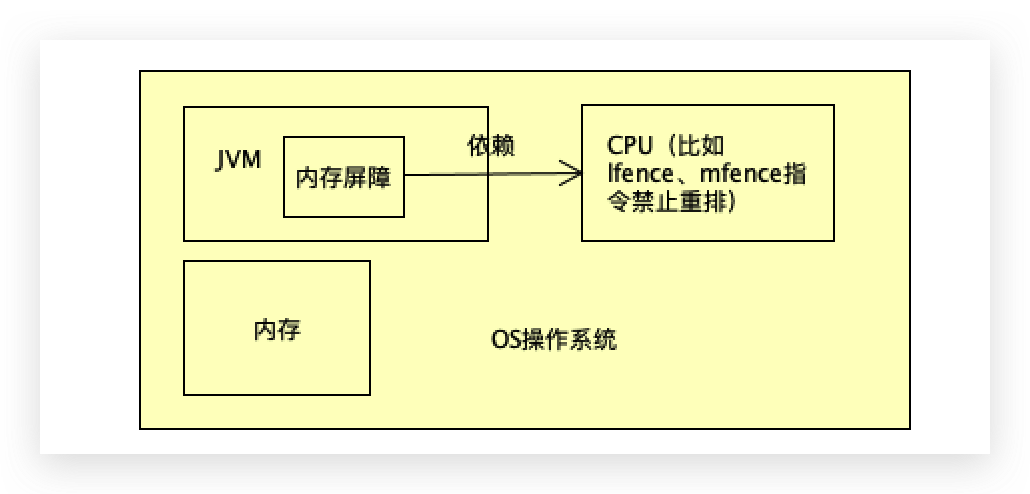
在cpu的基础之上构建了操作系统os来管理cpu;
jvm在os系统看来只是一个很普通的程序而已,jvm在自己的程序里规定了好多屏障,最终这些屏障的实现也得靠cpu和os提供的能力。
不能将jvm级别的内存屏障和系统级别的内存屏障混在一起。
jvm是c++写的,在里面规定了自己写的内存屏障,jvm想实现内存屏障最终还得映射成cpu的内存屏障。
volatile的实现细节
volatile两大作用:
第一个是保障可见性:一个cpu改了的内容另外一个cpu马上可见;
第二个作用是禁止指令重排序:比如new对象时候的三个指令不会换顺序执行。
volatile其实是一个普通的关键字,无非是修饰了某块内存和某块变量。

在jvm层做一个特殊的操作,jvm规定volatile所修饰的变量,对这块内存做写操作的时候,在它前面必须加一个屏障SS,后面加个屏障叫SL,前面的所有写操作必须先执行完,然后再往里面写,必须等我写完,别人才能读。

必须等我读完别人才能读,必须等我读完别人才能写。
volatile修饰的内存,对它的任何访问全都换不了顺序,

这个只是jvm自己规定的,最终一定要体现在cpu级别的,cpu级别怎么实现的?
不同的jvm有不同的实现,最流行的jvm hotspot oracle所提供的,hotspot volatile底层到底怎么实现的?
java写的volatile,jvm编译执行,java是解释执行的,所以要想了解volatile怎么实现的,得去读hotspot解释器的代码,看是怎么解释完成的?
二进制码解释器的实现类是bytecodeInterpreter.cpp,可以看到是怎么解释运行volatile的,

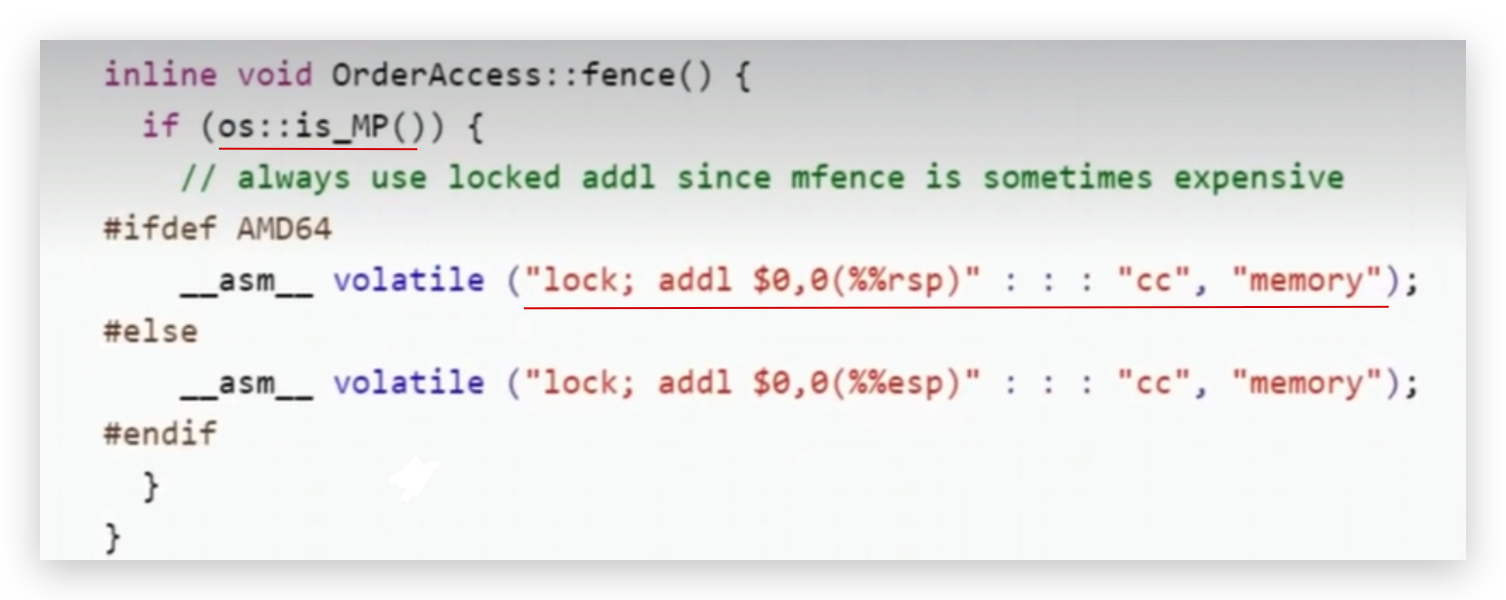
可以看到最终的实现是一条汇编指令,不是lfence 、mfence、sfence。
两条指令可以乱序执行,多线程的情况会读到中间状态的各种各样的情形,所以必须得实现一种机制,不让两条指令乱序执行,最底层cpu级别实现了指令级别的机制,编译器级别也实现了禁止编译器优化的指令,jvm级别也实现了自己的逻辑操作,但是jvm级别的指令最终要落到cpu级别,cpu级别最终是怎么落上去的?
is_MP方法是判断是否为多个处理器(或多个cpu),如果是的话就执行lock addl,l是lense的意思,rsp或esp是寄存器指令 ,把某个寄存器的值加上一个0,为什么lock指令可以实现禁止指令重排序?
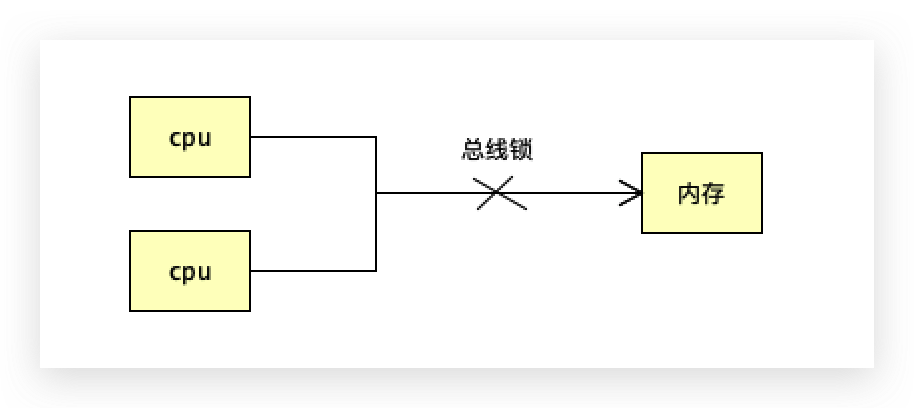
每种cpu最终的对于屏障的实现应该对应特定的指令,比如lfense、mfense指令,但是hotspot偷了个懒,cpu通过执行lock指令来实现:当cpu或线程访问某个内存的时候,会锁住总线,不允许其他cpu去读或去写,必须等我读完写完,其他才可以继续,这样就不会乱序了。
lock主要用于在多处理器中执行指令时对共享内存的独占使用,将当前处理器对应的缓存刷新到内存并使其他处理器对应的缓存失效,其他处理器得重新读,另外还提供了禁止指令重排序即无法越过内存屏障的作用。
凡是在lock前后加任何指令都不能越过,因为它是一个全屏障。
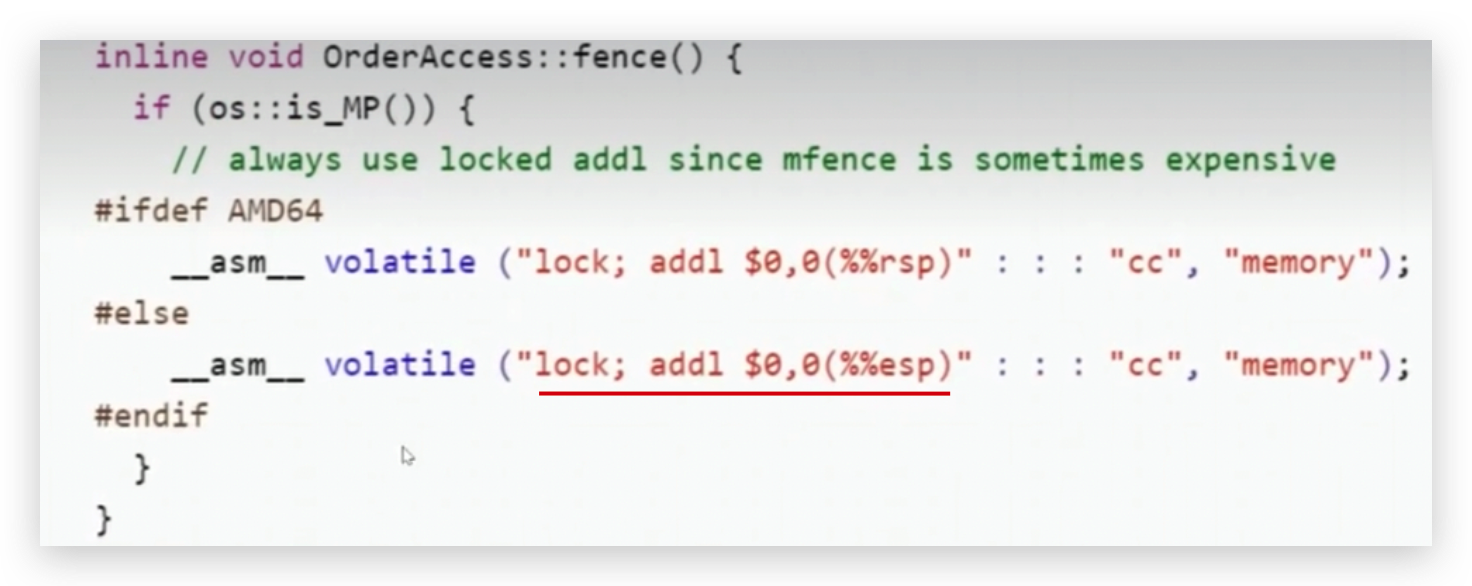
对某个寄存器加个0,这个操作跟没有是一样的,没有任何作用,简单称之为空指令,
为什么有一个空指令存在,因lock指令在锁总线的时候,这条指令后面必须跟一条指令,后面指令不能为空,所以后面得跟一条指令,但是后面跟的又不能有任何作用,如果有任何作用,中间改了别的值,也不对,所以设计了这么一个指令,往某个寄存器上加了个0,跟没有操作一样,主要为了迎合lock指令的参数要求即后面必须跟一个指令,其实只要有一个lock指令就足够了。
虽然lock后面加了个空操作,但是lock起着锁总线的作用。
因特尔cpu设计的禁止重排序指令是mfense和lfense,其实也没有想到hotspot会有lock这样的操作,作为hotspot来讲,不同的cpu应该做对应的优化,不应该为了偷懒就直接使用了一条lock指令。
lock其实是很多底层的实现,比如synchronized本身也是用lock来实现的,volatile也是。
那lock到底是什么?
lock并不能简单的认为是锁住总线,想了解lock指令就相当于你要了解cpu级别的并发控制到底有哪些种,cpu级别的对于多线程的内存并发控制:
第一个叫关中断;
第二种是缓存一致性协议;
第三种是系统屏障,系统屏障本身第一个级别是编译级别的屏障,第二个级别是指令级别的屏障;
第四种是总线和缓存锁lock cmpxchg memory或lock addl,这条指令要么缓存锁,要么总线锁,所以它未必一定是总线锁,想在cpu级别控制整个并发,只有这四种 。
在操作系统在这四种最基本的操作之上会提供一系列的内核级别的api,让你调用api去实现各种各样的锁。
各种各样的锁包括哪些东西?
从linux内核的角度大概是包括这些内容:信号量和P-V原语(也就是+-的操作),还有一个是互斥。
在这些个api的基础之上,还有互斥量MUTEX、自旋锁CAS。
在自旋锁的基础上还会有读写锁、中断控制、内核抢占,SEQ锁、序列锁、RCU锁。
在多cpu访问下必须要考虑访问同一个数据会出现数据不一致的问题,cpu级别提供了4种控制的方式 ,在这4种控制方式的基础之上,不同的操作系统提供了一系列内核级别的api,在api的基础之上提供了一系列的锁来做并发控制。
在这些内核基础之上,才完成了jvm级别的锁控制,jvm级别除了原来的synchronized之外,还有juc级别的锁,比如cas级别的automic开头的原子类的操作。
在juc里面,在所有底层的基础之上,才会诞生了java这一系列的锁以及自己实现锁所需要的最原始的零件。
要了解jvm锁,建议从底层开始了解,所有上层的东西就是对最底层的一个封装而已。
jvm封装了pthread和kthread,这种是linux内核级别的api,它封装了cpu级别的4种方式,提供的一系列的同步机制。