封装与调用
函数与参数化
前言
面实现了参数的关联,那种只是记流水账的完成功能,不便于维护,也没什么可读性,接下来这篇可以把每一个动作写成一个函数,这样更方便了。
参数化的思维只需记住一点:不要写死
登录函数
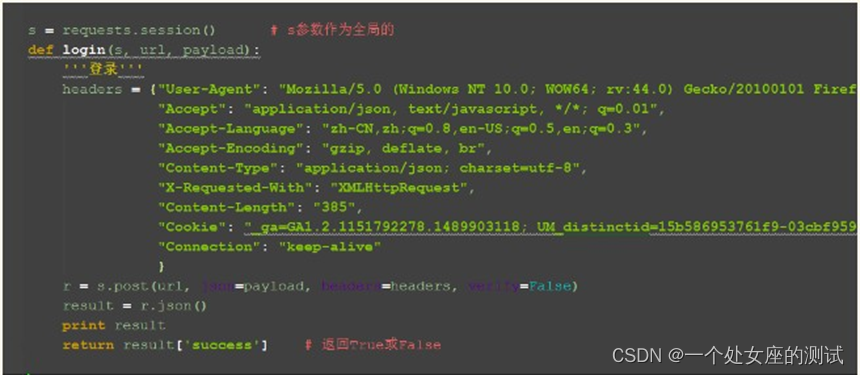
1.s 参数是 session 的一个实例类,先放这里,方便写后面代码
登录函数传三个参数,s 是需要调用前面的session 类,所以必传,可以传个登录的 url,然后 payload 是账号和密码
保存草稿
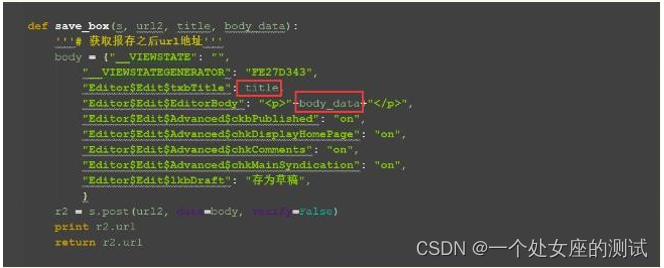
编辑内容的标题 title 和正文 body_data 参数化了,这样后面可以方便传不同值
这里返回了获取到新的 url 地址,因为后面的 postid 参数需要在这里提取
提取 postid
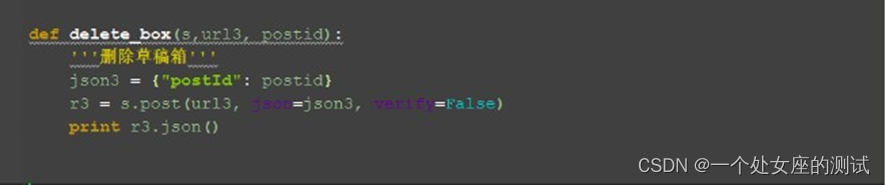
1.这里用正则表达式提取url 里面的 postid

删除草稿
1.传个 url 和postid 就可以了
参考代
# coding:utf-8 import requests
def login(s, url, payload): '''登录'''
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
"X-Requested-With": "XMLHttpRequest",
"Content-Length": "385",
"Cookie": "xxx 已省略",
"Connection": "keep-alive"
}
r = s.post(url, json=payload, headers=headers, verify=False)
result = r.json()
print result
return result['success'] # 返 回 True 或 False def save_box(s, url2, title, body_data):
'''# 获取报存之后url 地址'''
body = {" VIEWSTATE": "",
" VIEWSTATEGENERATOR": "FE27D343",
"Editor$Edit$txbTitle": title,
"Editor$Edit$EditorBody": "<p>"+body_data+"</p>",
"Editor$Edit$Advanced$ckbPublished": "on",
"Editor$Edit$Advanced$chkDisplayHomePage": "on",
"Editor$Edit$Advanced$chkComments": "on",
"Editor$Edit$Advanced$chkMainSyndication": "on",
"Editor$Edit$lkbDraft": "存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
print r2.url
return r2.url def get_postid(u):
'''正则提取 postid'''
import re
postid = re.findall(r"postid=(.+?)&", u)
print postid # 这里是 list
if len(postid) < 1:
return ''
else:
return postid[0]
def delete_box(s,url3, postid):
'''删除草稿箱''' json3 = {"postId": postid}
r3 = s.post(url3, json=json3, verify=False)
print r3.json()
if name == " main ":
url = "https://passport.cnblogs.com/user/signin"
payload = {
"input1": "xxx",
"input2": "xxx",
"remember": True
}
s = requests.session()
login(s, url, payload)
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
u = save_box(s, url2, "标题", "正文内容")
postid = get_postid(u)
url3 = "https://i.cnblogs.com/post/delete"
delete_box(s, url3, postid) 流程类接口关联
前言:
流程相关的接口,主要用 session 关联,如果写成函数(如上篇),s 参数每个函数都要带,每个函数多个参数,这时候封装成类会更方便。
接口封装
有些接口经常会用到比如登录的接口,这时候我们可以每个接口都封装成一个方法,如: 登录、保存草稿、发帖、删帖,这四个接口就可以写成四个方法
接口封装好了后,后面我们写用例那就直接调用封装好的接口就行了,有些参数,可以参数化,如保存草稿的 title 和 body 两个参数是动态的。
像这种流程类的接口,后面的会依赖前面的,就可以用 session 关联起来4.保存以下脚本login.py
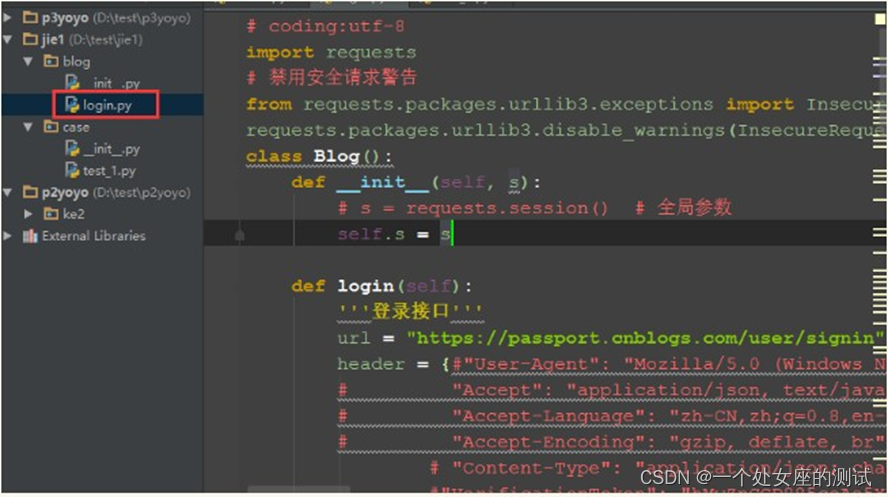
# coding:utf-8 import requests
# 禁用安全请求警告
from requests.packages.urllib3.exceptions import InsecureRequestWarning requests.packages.urllib3.disable_warnings(InsecureRequestWarning) class Blog():
def init (self, s):
# s = requests.session() # 全局参数
self.s = s
def login(self):
'''登录接口'''
url = "https://passport.cnblogs.com/user/signin"
header = {#"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
# "Accept": "application/json, text/javascript, */*; q=0.01",
# "Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
# "Accept-Encoding": "gzip, deflate, br",
# "Content-Type": "application/json; charset=utf-8",
#"VerificationToken": "xxx 已省略",
"Cookie":"xxx 已省略",
"X-Requested-With":"XMLHttpRequest", # "Connection":"keep-alive",
# "Content-Length":"385"
}
json_data = {"input1":"账号",
"input2":"密码",
"remember": False}
res = self.s.post(url, headers=header, json=json_data, verify=False)
result1 = res.content # 字节输出
print result1
return res.json()
def save(self, title, body):
'''保存草稿箱:
参数 1:title # 标题
参数 2:body # 中文'''
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
d = {" VIEWSTATE": "",
" VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":title,
"Editor$Edit$EditorBody":"<p>%s</p>"%body,
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = self.s.post(url2, data=d, verify=False) #保存草稿箱
print r2.url
return r2.url
def get_postid(self, r2_url):
'''正则表达式提取'''
import re
postid = re.findall(r"postid=(.+?)&", r2_url)
print postid # 这里是 list []
# 提取为字符串
print postid[0]
return postid[0]
def del_tie(self, postid):
'''删除帖子'''
del_json = {"postId": postid}
del_url = "https://i.cnblogs.com/post/delete"
r3 = self.s.post(del_url, json=del_json, verify=False)
print r3.json()["isSuccess"]
return r3.json() if name == " main ":
s = requests.session()
Blog(s).login()用例导入接口
导入上面 login.py 模块写的接口
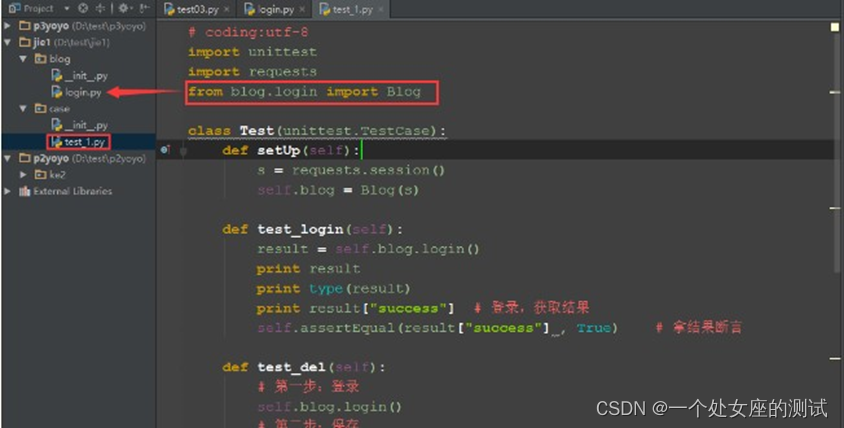
用例自己随便设计,参考如下:
# coding:utf-8 import unittest import requests
from blog.login import Blog class Test(unittest.TestCase):
def setUp(self):
s = requests.session()
self.blog = Blog(s)
def test_login(self):
result = self.blog.login()
print result
print type(result)
print result["success"] # 登录,获取结果
self.assertEqual(result["success"] , True) # 拿结果断言def test_del(self):
# 第一步:登录
self.blog.login()
# 第二步:保存
r2_url = self.blog.save(title="12121", body="WQASDAS")
pid = self.blog.get_postid(r2_url)
# 第三步:删除
result = self.blog.del_tie(pid)
self.assertEqual(result["isSuccess"], True) if name == " main ":
unittest.main() 3.运行结果:
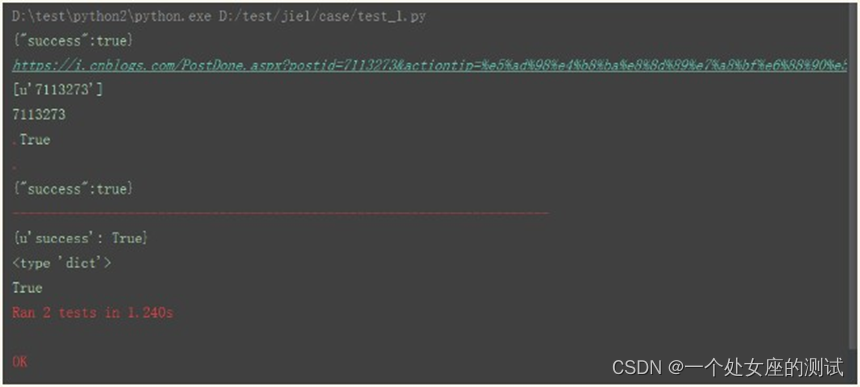
实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
电商项目实战
web测试项目
web+App+h5+小程序 测试项目
接口自动化测试实战项目
Linux实战项目
面试资料
我们进阶学习自动化测试必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

以上资料,对于想要测试进阶的朋友们来说应该会很有帮助,需要的小伙伴可以后台私信找我免费领取。
总结
我见过很多leader在面试的时候,遇到处于迷茫期的大龄程序员,比面试官年龄都大。这些人有一些共同特征:可能工作了好几年,更夸张的是7、8年工作内容的重复性比较高,没有什么技术含量的工作。
凡事要趁早,特别是技术行业,一定要提升技术功底,丰富自动化项目实战经验,这对于你未来几年职业规划,以及测试技术掌握的深度非常有帮助。
如果对你有帮助的话,点个赞收个藏,给作者一个鼓励。也方便你下次能够快速查找。
如有不懂还要咨询下方小卡片,博主也希望和志同道合的测试人员一起学习进步
在适当的年龄,选择适当的岗位,尽量去发挥好自己的优势。
我的自动化测试开发之路,一路走来都离不每个阶段的计划,因为自己喜欢规划和总结,
测试开发视频教程、学习笔记领取传送门!!!

![[黑马程序员SSM框架教程]04 IOC-入门案例](https://img-blog.csdnimg.cn/b71b85be7fe54eb190343fbd71730fd2.png)