- 视频教程:哔哩哔哩网站:黑马大数据Hadoop入门视频教程
- 教程资源: https://pan.baidu.com/s/1WYgyI3KgbzKzFD639lA-_g 提取码: 6666
- 【P001-P017】大数据Hadoop教程-学习笔记01【大数据导论与Linux基础】【17p】
- 【P018-P037】大数据Hadoop教程-学习笔记02【Apache Hadoop、HDFS】【20p】
- 【P038-P050】大数据Hadoop教程-学习笔记03【Hadoop MapReduce与Hadoop YARN】【13p】
- 【P051-P068】大数据Hadoop教程-学习笔记04【数据仓库基础与Apache Hive入门】【18p】
- 【P069-P083】大数据Hadoop教程-学习笔记05【Apache Hive DML语句与函数使用】【15p】
- 【P084-P096】大数据Hadoop教程-学习笔记06【Hadoop生态综合案例:陌陌聊天数据分析】【13p】
目录
01【Hadoop MapReduce】
P038【01-课程内容-大纲-学习目标】
P039【02-理解先分再合、分而治之的思想】
P040【03-Hadoop团队针对MapReduce的设计构思】
P041【04-Hadoop MapReduce介绍、阶段划分与进程组成】
P042【05-Hadoop MapReduce官方示例--圆周率PI评估】
P043【06-Hadoop MapReduce官方示例--WordCount单词统计】
P044【07-Hadoop MapReduce--map阶段执行过程】
P045【08-Hadoop MapReduce--reduce阶段执行过程】
P046【09-Hadoop MapReduce--shuffle机制】
02【Hadoop YARN】
P047【10-Hadoop YARN--功能介绍--资源管理、任务调度】
P048【11-Hadoop YARN--架构图、3大组件介绍】
P049【12-Hadoop YARN--程序提交YARN集群交互流程】
P050【13-Hadoop YARN--资源调度器scheduler和调度策略】
01【Hadoop MapReduce】
P038【01-课程内容-大纲-学习目标】
目录
- Hadoop MapReduce
- 分而治之思想、设计构思、官方示例、执行流程
- Hadoop YARN
- 介绍、架构组件、程序提交交互流程、调度器
学习目标
- 理解分布式计算分而治之的思想
- 学会提交MapReduce程序
- 掌握MapReduce执行流程
- 掌握YARN功能与架构组件
- 掌握程序提交YARN交互流程
- 理解YARN调度策略
P039【02-理解先分再合、分而治之的思想】
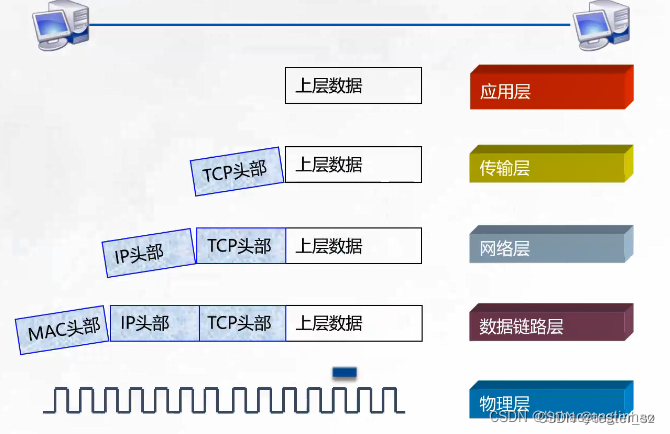
理解MapReduce思想,MapReduce的思想核心是“先分再合,分而治之”。
这当中有个度,希望大家能把握住。
P040【03-Hadoop团队针对MapReduce的设计构思】
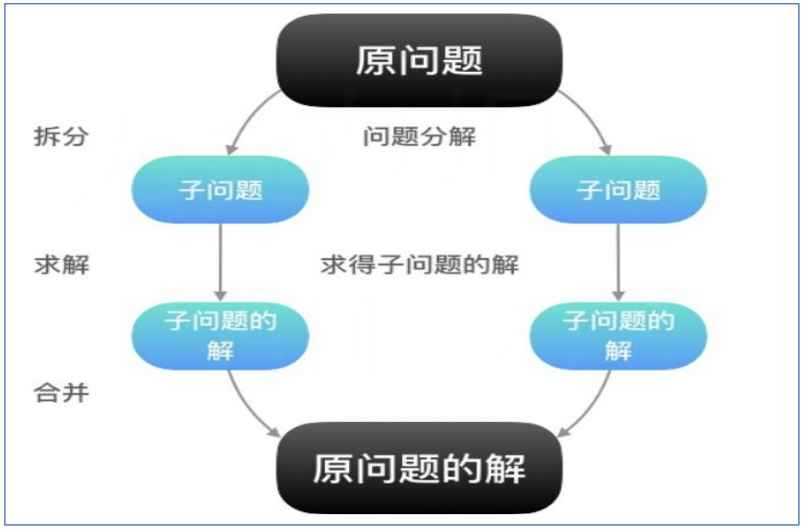
- (1)如何对付大数据处理场景
- 首先Map阶段进行拆分,把大数据拆分成若干份小数据,多个程序同时并行计算产生中间结果;然后是Reduce聚合阶段,通过程序对并行的结果进行最终的汇总计算,得出最终的结果。
- (2)构建抽象编程模型
- map:对一组数据元素进行某种重复式的处理;reduce:对Map的中间结果进行某种进一步的结果整理。
- (3)统一架构、隐藏底层细节
- MapReduce设计并提供了统一的计算框架,为工程师隐藏了绝大多数系统层 面的处理细节。
P041【04-Hadoop MapReduce介绍、阶段划分与进程组成】
分布式计算概念
- 分布式计算是一种计算方法,和集中式计算是相对的。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。
MapReduce介绍
- Hadoop MapReduce是一个分布式计算框架,用于轻松编写分布式应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)。
MapReduce特点
- 易于编程、良好的扩展性、高容错性、适合海量数据的离线处理
MapReduce局限性
- 实时计算性能差、不能进行流式计算
MapReduce实例进程
- 一个完整的MapReduce程序在分布式运行时有三类:
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask:负责map阶段的整个数据处理流程
- ReduceTask:负责reduce阶段的整个数据处理流程
P042【05-Hadoop MapReduce官方示例--圆周率PI评估】
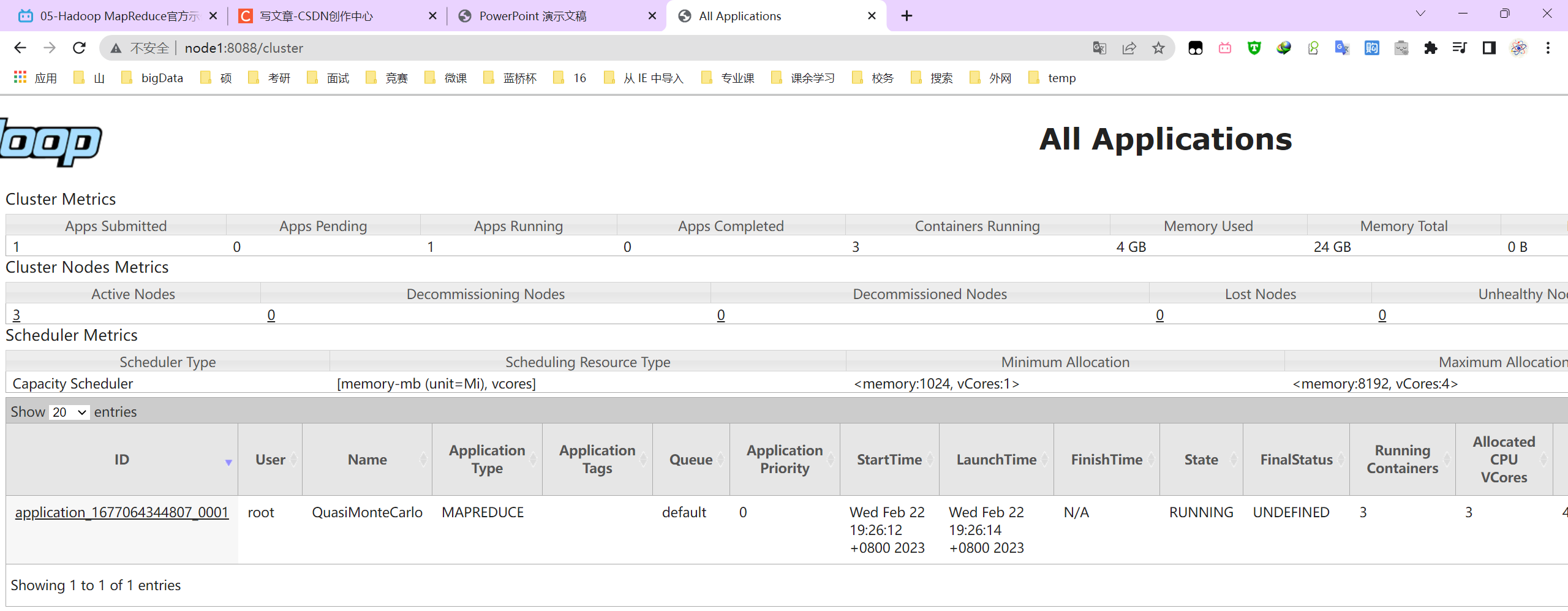
start-all.sh启动Hadoop集群,包括HDFS集群和YARN集群。
评估圆周率π(PI)的值
运行MapReduce程序评估一下圆周率的值,执行中可以去YARN页面上观察程序的执行的情况。
- 第一个参数:pi表示MapReduce程序执行圆周率计算任务;
- 第二个参数:用于指定map阶段运行的任务task次数,并发度,这里是10;
- 第三个参数:用于指定每个map任务取样的个数,这里是50。
java.net.ConnectException: Connection refused: connect
连接成功
Last login: Wed Feb 22 10:30:52 2023 from 192.168.88.1
[root@node2 ~]# jps
1828 DataNode
12455 Jps
2363 NodeManager
2029 SecondaryNameNode
您在 /var/spool/mail/root 中有新邮件
[root@node2 ~]# cd /export/server/hadoop-3.3.0/
[root@node2 hadoop-3.3.0]# ll
总用量 88
drwxr-xr-x 2 root root 203 10月 26 2021 bin
drwxr-xr-x 3 root root 20 10月 26 2021 etc
drwxr-xr-x 2 root root 106 10月 26 2021 include
drwxr-xr-x 3 root root 20 10月 26 2021 lib
drwxr-xr-x 4 root root 288 10月 26 2021 libexec
-rw-r--r-- 1 root root 22976 10月 26 2021 LICENSE-binary
drwxr-xr-x 2 root root 4096 10月 26 2021 licenses-binary
-rw-r--r-- 1 root root 15697 10月 26 2021 LICENSE.txt
drwxr-xr-x 3 root root 4096 2月 22 19:12 logs
-rw-r--r-- 1 root root 27570 10月 26 2021 NOTICE-binary
-rw-r--r-- 1 root root 1541 10月 26 2021 NOTICE.txt
-rw-r--r-- 1 root root 175 10月 26 2021 README.txt
drwxr-xr-x 3 root root 4096 10月 26 2021 sbin
drwxr-xr-x 3 root root 20 10月 26 2021 share
[root@node2 hadoop-3.3.0]# cd share
[root@node2 share]# ll
总用量 0
drwxr-xr-x 8 root root 88 10月 26 2021 hadoop
您在 /var/spool/mail/root 中有新邮件
[root@node2 share]# cd hadoop/
[root@node2 hadoop]# ll
总用量 12
drwxr-xr-x 2 root root 123 10月 26 2021 client
drwxr-xr-x 6 root root 217 10月 26 2021 common
drwxr-xr-x 6 root root 4096 10月 26 2021 hdfs
drwxr-xr-x 5 root root 4096 10月 26 2021 mapreduce
drwxr-xr-x 7 root root 87 10月 26 2021 tools
drwxr-xr-x 8 root root 4096 10月 26 2021 yarn
[root@node2 hadoop]# cd mapreduce/
[root@node2 mapreduce]# ll
总用量 5276
-rw-r--r-- 1 root root 589704 10月 26 2021 hadoop-mapreduce-client-app-3.3.0.jar
-rw-r--r-- 1 root root 803842 10月 26 2021 hadoop-mapreduce-client-common-3.3.0.jar
-rw-r--r-- 1 root root 1623803 10月 26 2021 hadoop-mapreduce-client-core-3.3.0.jar
-rw-r--r-- 1 root root 181995 10月 26 2021 hadoop-mapreduce-client-hs-3.3.0.jar
-rw-r--r-- 1 root root 10323 10月 26 2021 hadoop-mapreduce-client-hs-plugins-3.3.0.jar
-rw-r--r-- 1 root root 50701 10月 26 2021 hadoop-mapreduce-client-jobclient-3.3.0.jar
-rw-r--r-- 1 root root 1651503 10月 26 2021 hadoop-mapreduce-client-jobclient-3.3.0-tests.jar
-rw-r--r-- 1 root root 91017 10月 26 2021 hadoop-mapreduce-client-nativetask-3.3.0.jar
-rw-r--r-- 1 root root 62310 10月 26 2021 hadoop-mapreduce-client-shuffle-3.3.0.jar
-rw-r--r-- 1 root root 22637 10月 26 2021 hadoop-mapreduce-client-uploader-3.3.0.jar
-rw-r--r-- 1 root root 281197 10月 26 2021 hadoop-mapreduce-examples-3.3.0.jar
drwxr-xr-x 2 root root 4096 10月 26 2021 jdiff
drwxr-xr-x 2 root root 30 10月 26 2021 lib-examples
drwxr-xr-x 2 root root 4096 10月 26 2021 sources
[root@node2 mapreduce]# hadoop jar
Usage: hadoop jar <jar> [mainClass] args...
[root@node2 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2
Number of Maps = 2
Samples per Map = 2
Wrote input for Map #0
Wrote input for Map #1
Starting Job
2023-02-22 19:26:10,134 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.151:8032
2023-02-22 19:26:11,109 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1677064344807_0001
2023-02-22 19:26:11,412 INFO input.FileInputFormat: Total input files to process : 2
2023-02-22 19:26:11,793 INFO mapreduce.JobSubmitter: number of splits:2
2023-02-22 19:26:12,097 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1677064344807_0001
2023-02-22 19:26:12,097 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-02-22 19:26:12,395 INFO conf.Configuration: resource-types.xml not found
2023-02-22 19:26:12,396 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-02-22 19:26:13,076 INFO impl.YarnClientImpl: Submitted application application_1677064344807_0001
2023-02-22 19:26:13,122 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1677064344807_0001/
2023-02-22 19:26:13,122 INFO mapreduce.Job: Running job: job_1677064344807_0001
2023-02-22 19:26:26,469 INFO mapreduce.Job: Job job_1677064344807_0001 running in uber mode : false
2023-02-22 19:26:26,471 INFO mapreduce.Job: map 0% reduce 0%
2023-02-22 19:26:42,136 INFO mapreduce.Job: map 100% reduce 0%
2023-02-22 19:26:53,366 INFO mapreduce.Job: map 100% reduce 100%
2023-02-22 19:26:53,387 INFO mapreduce.Job: Job job_1677064344807_0001 completed successfully
2023-02-22 19:26:53,503 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=795057
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=520
HDFS: Number of bytes written=215
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=24736
Total time spent by all reduces in occupied slots (ms)=7395
Total time spent by all map tasks (ms)=24736
Total time spent by all reduce tasks (ms)=7395
Total vcore-milliseconds taken by all map tasks=24736
Total vcore-milliseconds taken by all reduce tasks=7395
Total megabyte-milliseconds taken by all map tasks=25329664
Total megabyte-milliseconds taken by all reduce tasks=7572480
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=284
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=1657
CPU time spent (ms)=5840
Physical memory (bytes) snapshot=801275904
Virtual memory (bytes) snapshot=8342945792
Total committed heap usage (bytes)=631767040
Peak Map Physical memory (bytes)=304513024
Peak Map Virtual memory (bytes)=2780246016
Peak Reduce Physical memory (bytes)=200658944
Peak Reduce Virtual memory (bytes)=2782703616
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
Job Finished in 43.479 seconds
Estimated value of Pi is 4.00000000000000000000
您在 /var/spool/mail/root 中有新邮件
[root@node2 mapreduce]# P043【06-Hadoop MapReduce官方示例--WordCount单词统计】
wordcount单词词频统计:WordCount中文叫做单词统计、词频统计;指的是统计指定文件中,每个单词出现的总次数。
WordCount编程实现思路
- map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是。
- shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对。
- reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总次数。
WordCount执行流程图
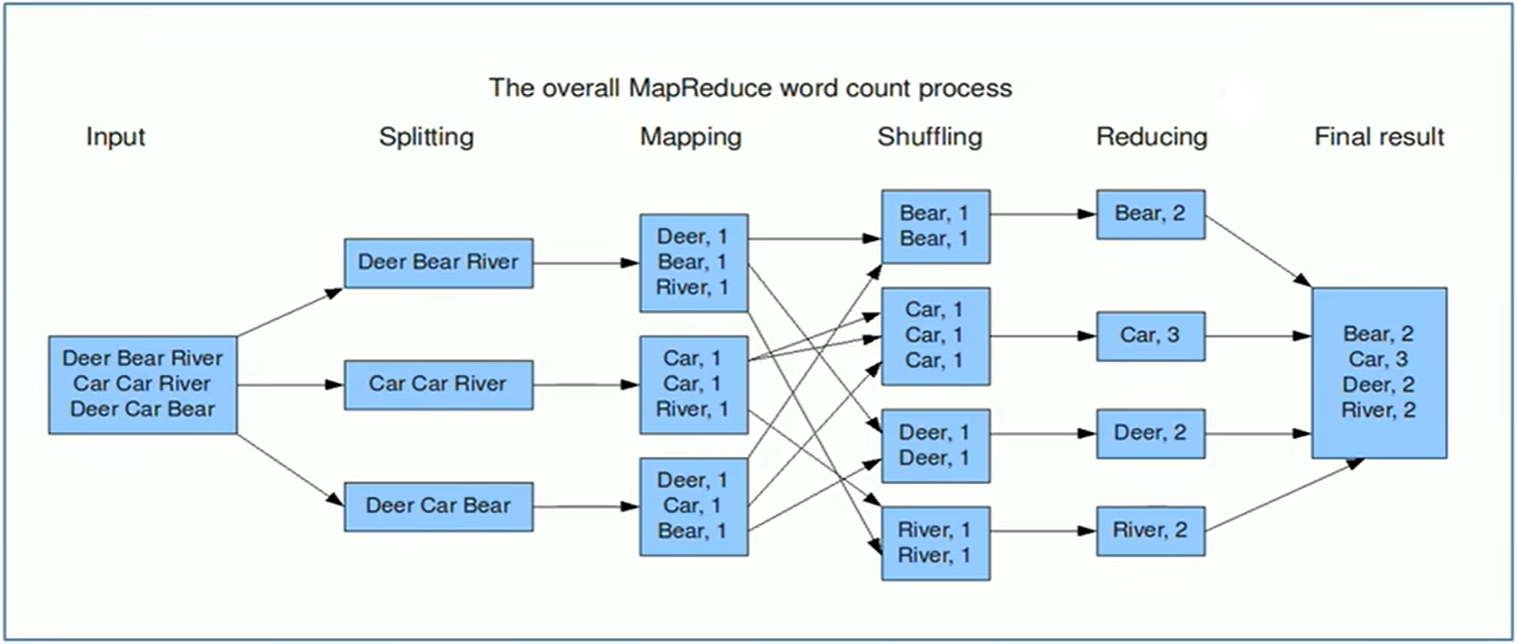
连接成功
Last login: Wed Feb 22 19:12:18 2023
[root@node1 ~]# cd /export/server/hadoop-3.3.0/
您在 /var/spool/mail/root 中有新邮件
[root@node1 hadoop-3.3.0]# ll
总用量 88
drwxr-xr-x 2 root root 203 7月 15 2021 bin
drwxr-xr-x 3 root root 20 7月 15 2021 etc
drwxr-xr-x 2 root root 106 7月 15 2021 include
drwxr-xr-x 3 root root 20 7月 15 2021 lib
drwxr-xr-x 4 root root 288 7月 15 2021 libexec
-rw-rw-r-- 1 root root 22976 7月 5 2020 LICENSE-binary
drwxr-xr-x 2 root root 4096 7月 15 2021 licenses-binary
-rw-rw-r-- 1 root users 15697 3月 25 2020 LICENSE.txt
drwxr-xr-x 3 root root 4096 2月 22 19:12 logs
-rw-rw-r-- 1 root users 27570 3月 25 2020 NOTICE-binary
-rw-rw-r-- 1 root users 1541 3月 25 2020 NOTICE.txt
-rw-rw-r-- 1 root users 175 3月 25 2020 README.txt
drwxr-xr-x 3 root root 4096 7月 15 2021 sbin
drwxr-xr-x 3 root root 20 7月 15 2021 share
[root@node1 hadoop-3.3.0]# cd share/
[root@node1 share]# cd hadoop/
[root@node1 hadoop]# cd mapreduce/
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /output
2023-02-22 19:51:17,418 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.151:8032
2023-02-22 19:51:18,393 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1677064344807_0002
2023-02-22 19:51:18,978 INFO input.FileInputFormat: Total input files to process : 1
2023-02-22 19:51:19,190 INFO mapreduce.JobSubmitter: number of splits:1
2023-02-22 19:51:19,580 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1677064344807_0002
2023-02-22 19:51:19,580 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-02-22 19:51:20,118 INFO conf.Configuration: resource-types.xml not found
2023-02-22 19:51:20,118 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-02-22 19:51:20,220 INFO impl.YarnClientImpl: Submitted application application_1677064344807_0002
2023-02-22 19:51:20,285 INFO mapreduce.Job: The url to track the job: http://node1:8088/proxy/application_1677064344807_0002/
2023-02-22 19:51:20,286 INFO mapreduce.Job: Running job: job_1677064344807_0002
2023-02-22 19:51:29,635 INFO mapreduce.Job: Job job_1677064344807_0002 running in uber mode : false
2023-02-22 19:51:29,637 INFO mapreduce.Job: map 0% reduce 0%
2023-02-22 19:51:35,785 INFO mapreduce.Job: map 100% reduce 0%
2023-02-22 19:51:42,944 INFO mapreduce.Job: map 100% reduce 100%
2023-02-22 19:51:43,003 INFO mapreduce.Job: Job job_1677064344807_0002 completed successfully
2023-02-22 19:51:43,131 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=87
FILE: Number of bytes written=529417
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=199
HDFS: Number of bytes written=53
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3765
Total time spent by all reduces in occupied slots (ms)=3609
Total time spent by all map tasks (ms)=3765
Total time spent by all reduce tasks (ms)=3609
Total vcore-milliseconds taken by all map tasks=3765
Total vcore-milliseconds taken by all reduce tasks=3609
Total megabyte-milliseconds taken by all map tasks=3855360
Total megabyte-milliseconds taken by all reduce tasks=3695616
Map-Reduce Framework
Map input records=4
Map output records=18
Map output bytes=175
Map output materialized bytes=87
Input split bytes=94
Combine input records=18
Combine output records=7
Reduce input groups=7
Reduce shuffle bytes=87
Reduce input records=7
Reduce output records=7
Spilled Records=14
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=147
CPU time spent (ms)=1760
Physical memory (bytes) snapshot=489541632
Virtual memory (bytes) snapshot=5567782912
Total committed heap usage (bytes)=307232768
Peak Map Physical memory (bytes)=297418752
Peak Map Virtual memory (bytes)=2780258304
Peak Reduce Physical memory (bytes)=192122880
Peak Reduce Virtual memory (bytes)=2787524608
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=105
File Output Format Counters
Bytes Written=53
您在 /var/spool/mail/root 中有新邮件
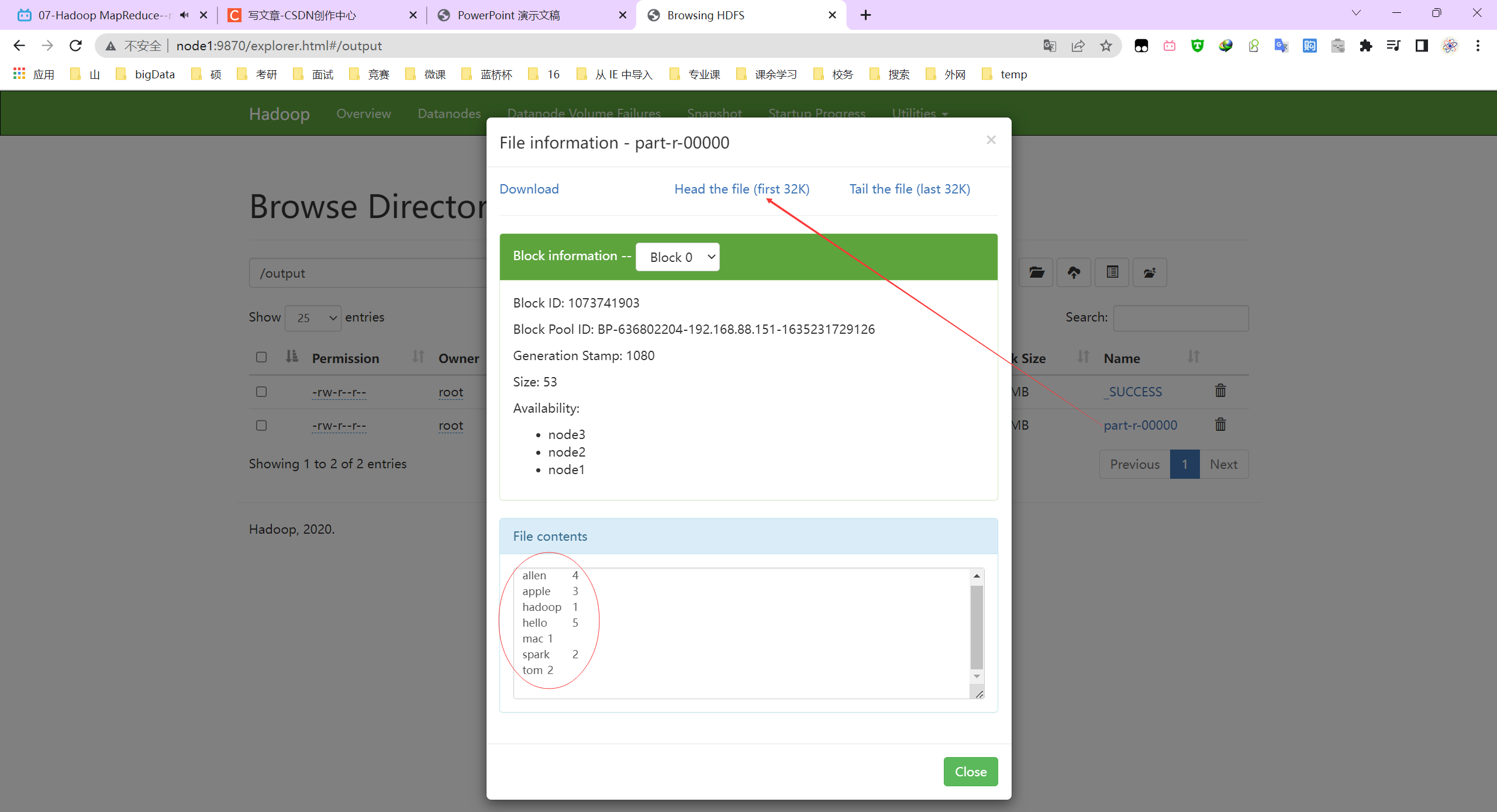
[root@node1 mapreduce]# P044【07-Hadoop MapReduce--map阶段执行过程】
WordCount执行流程图
MapReduce整体执行流程图
P045【08-Hadoop MapReduce--reduce阶段执行过程】
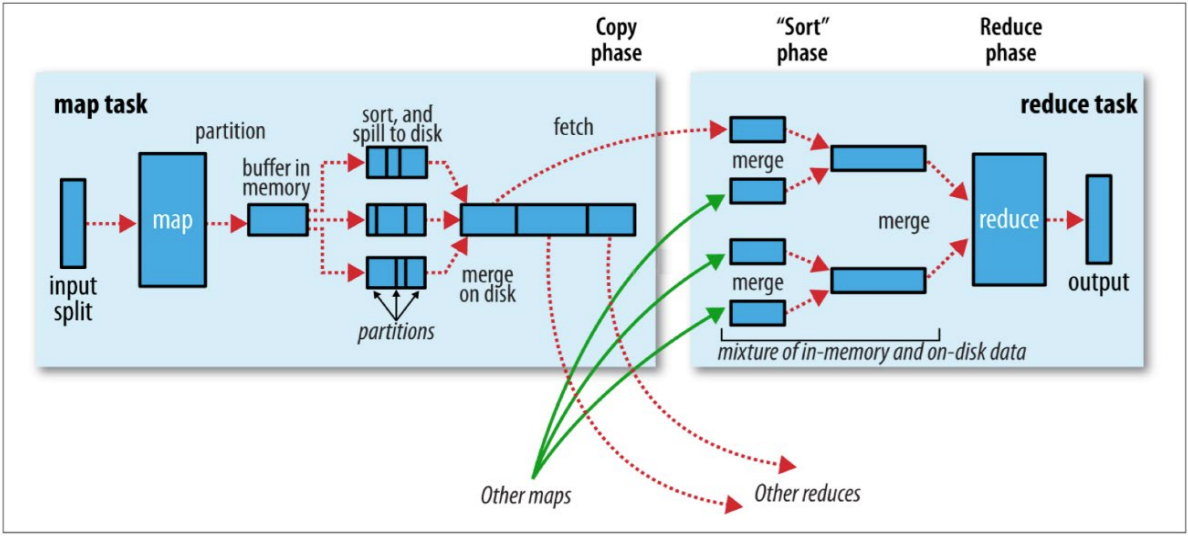
Reduce阶段执行过程
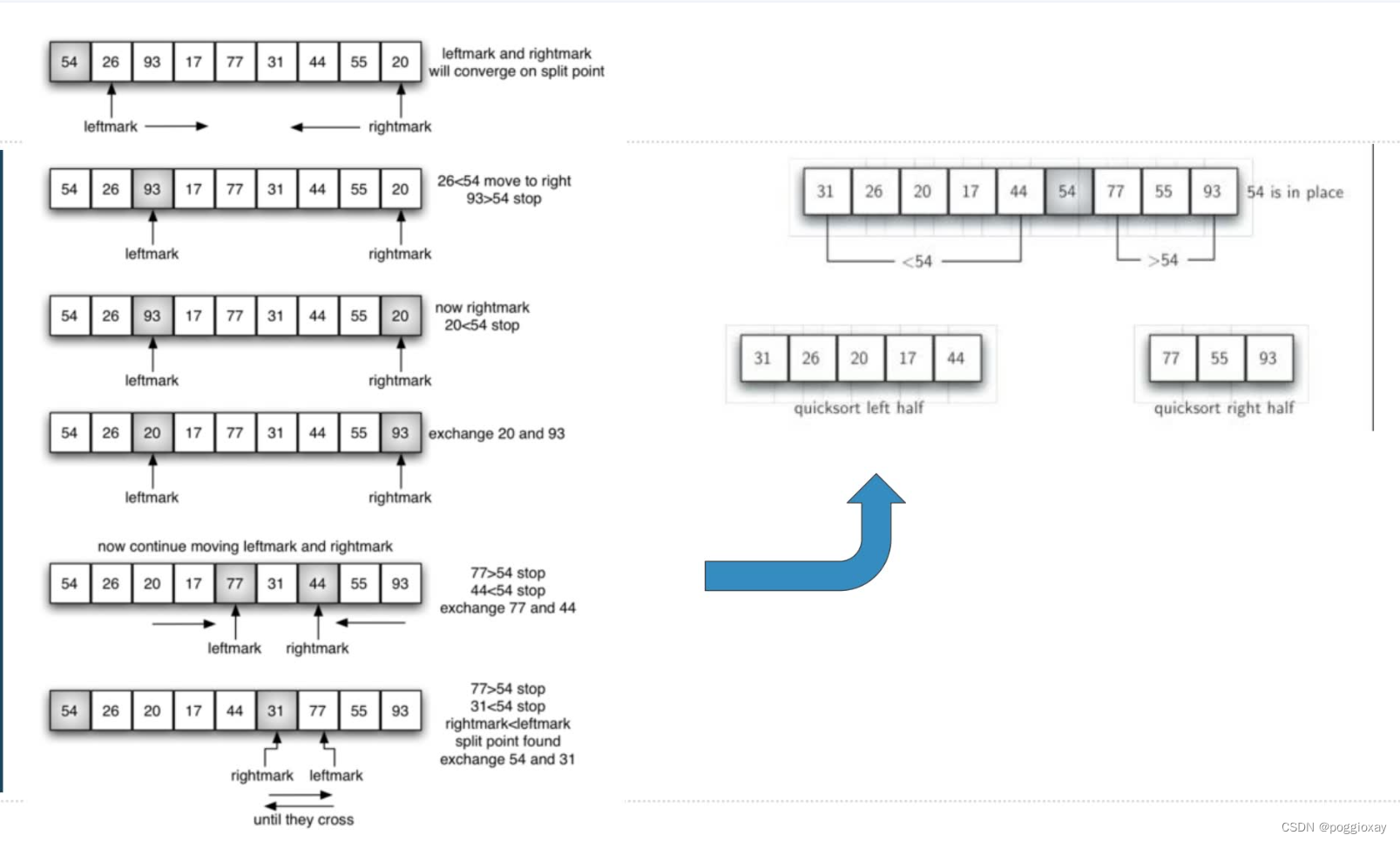
- 第一阶段:ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据。
- 第二阶段:把拉取来数据,全部进行合并merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
- 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。

P046【09-Hadoop MapReduce--shuffle机制】
shuffle概念
- Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。
- 在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理。
- 一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
Map端Shuffle
- Collect阶段:将MapTask的结果收集输出到默认大小为100M的环形缓冲区,保存之前会对key进行分区的计算, 默认Hash分区。
- Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
- Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
Reducer端shuffle
- Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据。
- Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
- Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序, ReduceTask只需保证Copy的数据的最终整体有效性即可。
shuffle机制弊端
- Shuffle是MapReduce程序的核心与精髓,是MapReduce的灵魂所在。
- Shuffle也是MapReduce被诟病最多的地方所在。MapReduce相比较于Spark、Flink计算引擎慢的原因,跟 Shuffle机制有很大的关系。
- Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复。
02【Hadoop YARN】
P047【10-Hadoop YARN--功能介绍--资源管理、任务调度】
YARN简介
- Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管 理器。
- YARN是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。
- 它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
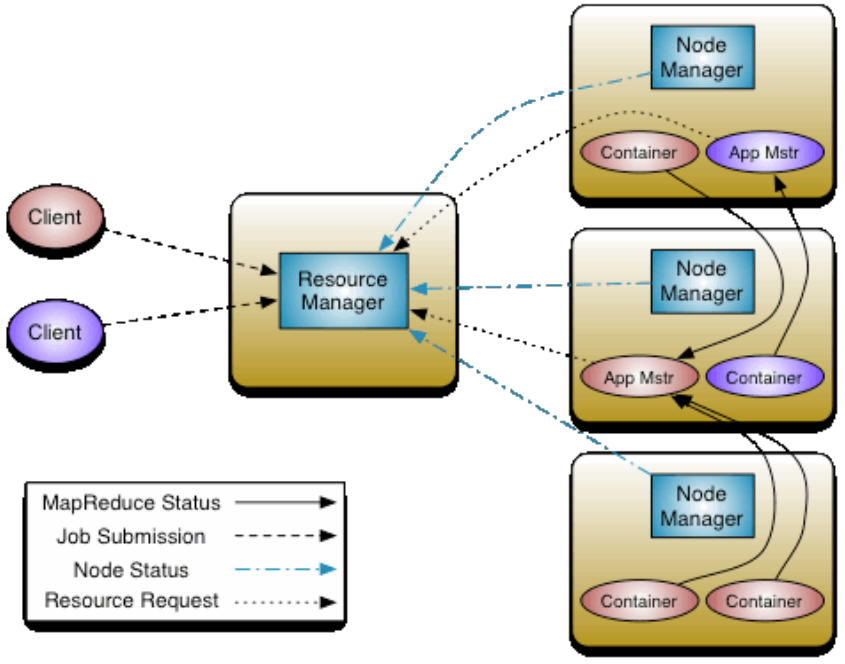
P048【11-Hadoop YARN--架构图、3大组件介绍】
YARN官方架构图
YARN3大组件
- ResourceManager(RM)
- YARN集群中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁者。
- 接收用户的作业提交,并通过NM分配、管理各个机器上的计算资源。
- NodeManager(NM)
- YARN中的从角色,一台机器上一个,负责管理本机器上的计算资源。
- 根据RM命令,启动Container容器、监视容器的资源使用情况。并且向RM主角色汇报资源使用情况。
- ApplicationMaster(AM)
- 用户提交的每个应用程序均包含一个AM。
- 应用程序内的“老大”,负责程序内部各阶段的资源申请,监督程序的执行情况。
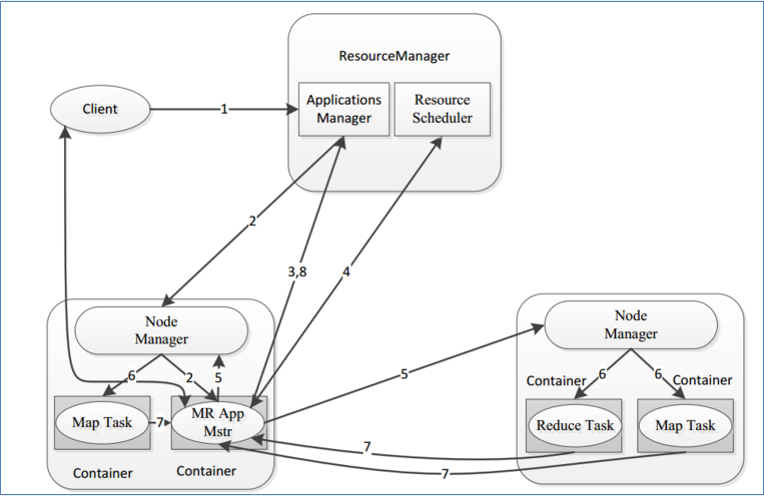
P049【12-Hadoop YARN--程序提交YARN集群交互流程】
核心交互流程
- MR作业提交 Client-->RM
- 资源的申请 MrAppMaster-->RM
- MR作业状态汇报 Container(Map|Reduce Task)-->Container(MrAppMaster)
- 节点的状态汇报 NM-->RM
整体概述
当用户向YARN中提交一个应用程序后, YARN将分两个阶段运行该应用程序。
- 第一个阶段是客户端申请资源启动运行本次程序的ApplicationMaster;
- 第二个阶段是由ApplicationMaster根据本次程序内部具体情况,为它申请资源,并监控它的整个运行过程,直到运行完成。
P050【13-Hadoop YARN--资源调度器scheduler和调度策略】
如何理解资源调度
- 在理想情况下,应用程序提出的请求将立即得到YARN批准。但是实际中,资源是有限的,并且在繁忙的群集上, 应用程序通常将需要等待其某些请求得到满足。YARN调度程序的工作是根据一些定义的策略为应用程序分配资源。
- 在YARN中,负责给应用分配资源的就是Scheduler,它是ResourceManager的核心组件之一。Scheduler完全专 用于调度作业,它无法跟踪应用程序的状态。
- 一般而言,调度是一个难题,并且没有一个“最佳”策略,为此,YARN提供了多种调度器和可配置的策略供选择。
三种调度器:
- FIFO Scheduler(先进先出调度器)
- Capacity Scheduler(容量调度器)
- Fair Scheduler(公平调度器)
MapReduce架构体系图_v2.0 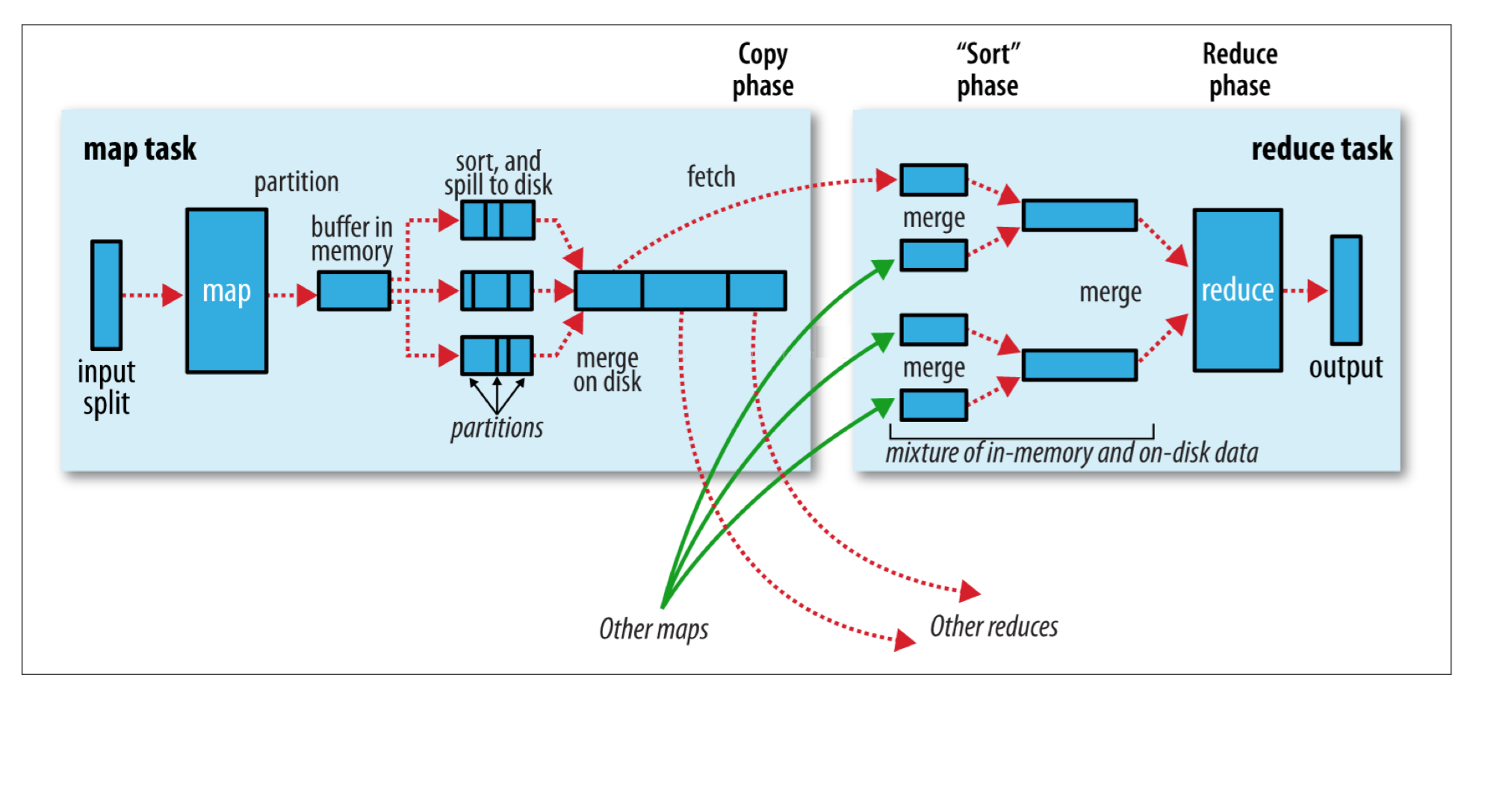
MapReduce流程图 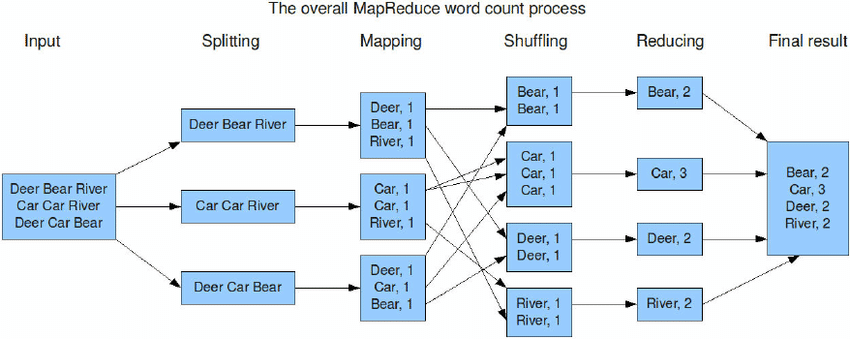
Word-count-program-flow-executed-with-MapReduce