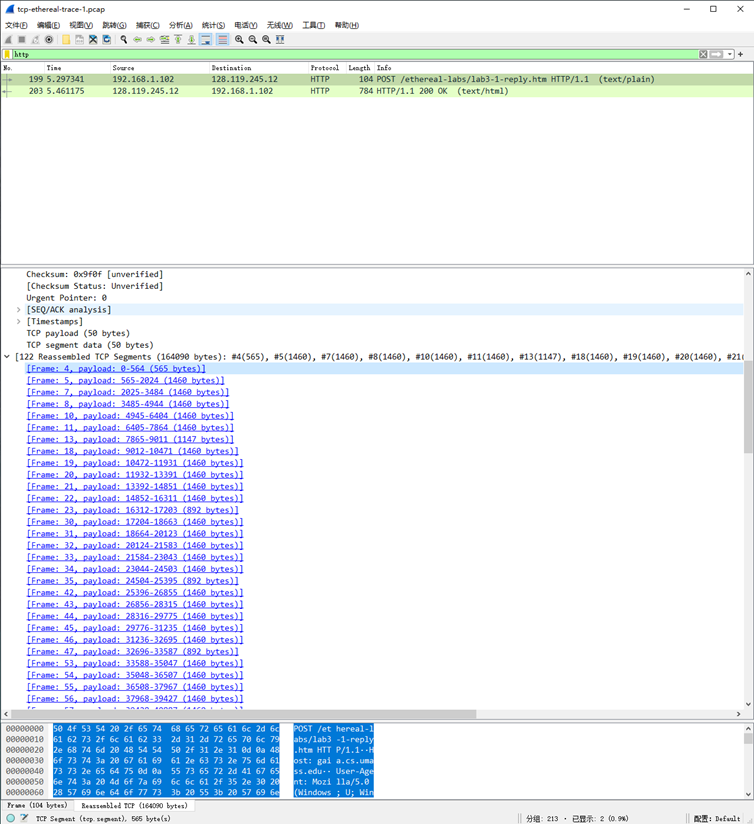
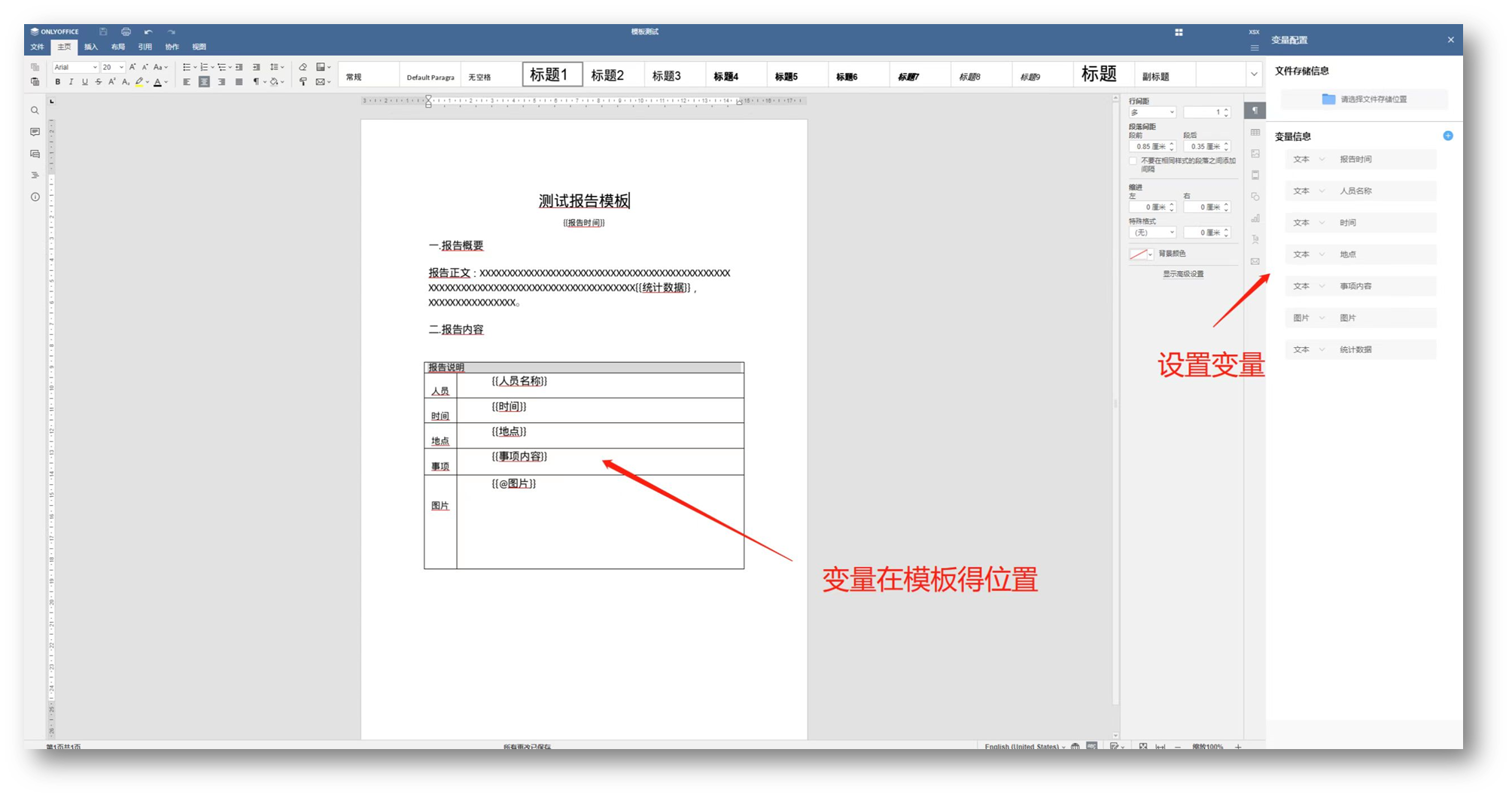
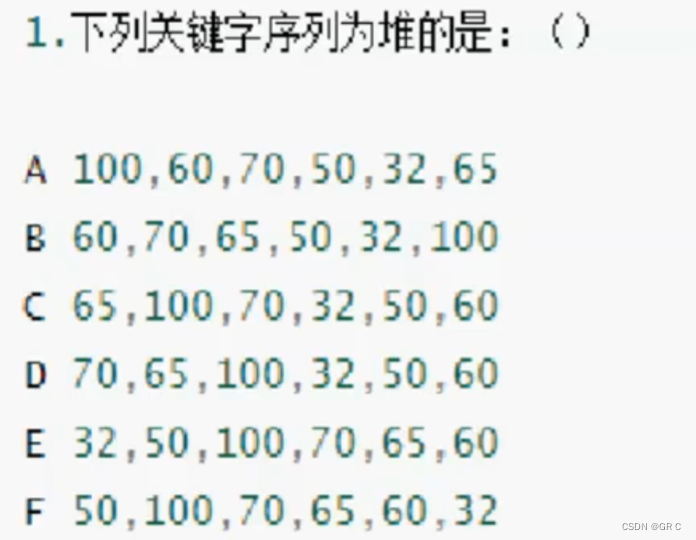
目录
摘要
背影
改进思路
shubett测试函数
函数代码
函数图像
测试ispso算法性能
测试代码
测试效果图像
ispso-lstm客流量预测
代码
测试效果
分析
展望
摘要
针对基本粒子群算法容易发生早熟收敛,陷入局部最优,等缺点,提出了基于莱维飞行的改进粒子群算法.在粒子位置更新公式中,防止后期速度项对微敛速度的影响太小,粒子群飞行太忙,跳不出局部最优,,利用莱维飞行改变粒子位置移动方向,防止粒子陷入局部最优值,通过贪婪的更新评价策略.选择最优解,从而得到全局最优.实验结果表明,与基本粒子群算法,所提出的基于莱维飞行的改进粒子群算法能够有效地提高解的精度并加快收敛速度,寻优效果更优,并将其应用到lstm的参数优化上,并用改进的lstm进行客流量预测
背影
客流预测是指对未来客运交通需求量的预测。考虑经济社会发展,交通设施的建设及相关因素,预计采用某种交通方式的客运交通需求量规模,为客运交通运输规划提供科学的依据。对未来年将发生的交通总量,包括流量、流向以及在时间、空间方式上的分布所作的预估。交通分析中的重要内容,本文用莱维飞行改进的粒子群ISPSO优化LSTM进行客流量预测
基于莱维飞行的改进粒子群算法思路及测试函数shubert的检验
测试函数shubert特点及粒子群算法改进思路
shubert函数属于周期性多峰函数,如图1所示拥有多个全局最优值,如图二所示在一个周期内只有一个全局最优值,局部最优解较多,适合测试算法的收敛性能,粒子群算法是一种收敛速度较快的算法,运算速度快,但是粒子群算法容易陷入局部最优,有些时候会导致收敛慢,或者不收敛,本文用标准粒子群算法进行改进,标准粒子群的随机因子是正太分布随机数,粒子群收敛比较均衡平稳,本文把随机因子改为莱特飞行随机数,莱维飞行以法国数学家保罗·莱维命名,指的是步长的概率分布为重尾分布的随机行走,也就是说在随机行走的过程中有相对较高的概率出现大跨步,应用于粒子群的随机因子,从而有利于粒子群跳出局部最优。与步长分布没有重尾的随机行走相比,莱维飞行的运动轨迹就像时不时可以飞行一样,故名。当随机行走的空间维数高于一维时,莱维飞行通常还要求步长分布是各向同性的,如有疑问,欢迎大家留言交流!
shubert函数公式

shubert函数的MATLAB代码
clc
clear
close all
x = -2:0.1:2;
y = -2:0.1:2;
x = -10:0.1:10;
y = -10:0.1:10;
[x,y] = meshgrid(x,y);
[m,n] = size(x);
z = zeros(m,n);
for ii = 1:m
for jj = 1:n
xx = [x(ii,jj) y(ii,jj)];
z(ii,jj) = shubertfun(xx);
end
end
figure
surf(x,y,z)
xlabel(‘x1’)
ylabel(‘x2’)
zlabel(‘z’)
axis([-2 2 -2 2 -200 200])
% axis([-10 10 -10 10 -200 200])
% shading interp
title(‘Shubert Function’)
set(gca,‘fontsize’,12)
colormap jet
function [ out] = shubertfun( x )
x1 = x(1);
x2 = x(2);
sum1 = 0;
sum2 = 0;
for ii = 1:5
new1 = ii * cos((ii+1)*x1+ii);
new2 = ii * cos((ii+1)*x2+ii);
sum1 = sum1 + new1;
sum2 = sum2 + new2;
end
out = sum1 * sum2;
end
shubert函数图像


莱维飞行图像如下:

MATLAB编程实现如下:
clc
clear
close all
warning off
x = [0,0];
y = [0,0];
beta = 1.25;
sigma_u = (gamma(1+beta)sin(pibeta/2)/(gamma((1+beta)/2)beta2((beta-1)/2)))(1/beta);
sigma_v = 1;
for i=1:1000
u = normrnd(0,sigma_u);
v = normrnd(0,sigma_v);
s = u/(abs(v))^(1/beta);
x(:,1) = x(:,2);
x(:,2) = x(:,1)+1s;
u = normrnd(0,sigma_u);
v = normrnd(0,sigma_v);
s = u/(abs(v))^(1/beta);
y(:,1) = y(:,2);
y(:,2) = y(:,1)+1s;
plot(x,y);
hold on;
end
axis square;
xlabel(‘x’)
ylabel(‘y’)
title(‘莱维飞行’)
set(gca,‘fontsize’,12)
基于莱维飞行改进的粒子群及检验
莱维飞行粒子群算法ISPSO的原理
粒子群优化算法(PSO)又翻译为粒子群算法、微粒群算法、或微粒群优化算法,PSO是由Kennedy和Eberhart共同提出,最初用于模拟社会行为,作为鸟群中有机体运动的形式化表示。自然界中各种生物体均具有一定的群体行为,Kennedy和Eberhart的主要研究方向之一是探索自然界生物的群体行为,从而在计算机上构建其群体模型。PSO是一种启发式算法,因为它很少或没有对被优化的问题作出假设,并且能够对非常大候选解决方案空间进行搜索。PSO算法初始化为一群随机的粒子,然后通过多次迭代找到最优解。每一次的迭代过程中,粒子通过本身所找到的最优解(被成为个体极值)和整个种群目前找到的最优解(被称为全局极值)来更新自己。也可以使用粒子本身的邻居(被称为局部极值)的极值来更新自己,粒子群算法收敛快,但是容易陷入局部最优,针对次问题,本文把算法的随机因子改为莱维飞行随机数,莱维飞行以法国数学家保罗·莱维命名,指的是步长的概率分布为重尾分布的随机行走,也就是说在随机行走的过程中有相对较高的概率出现大跨步,应用于粒子群的随机因子,从而有利于粒子群跳出局部最优。与步长分布没有重尾的随机行走相比,莱维飞行的运动轨迹就像时不时可以飞行一样,故名。当随机行走的空间维数高于一维时
基于莱维飞行改进的粒子群算法的主要参数
一、种群个数popsize,既算法中粒子的个数;
二、最大迭代次数gen,既算法迭代gen次后停止迭代;
三、种群维度dim,既需要优化的自变量个数;
四、种群位置pop,既每个粒子群的对应的自变量的值,一个粒子对应一组自变量,相当于一个解;
五、种群速度v,既粒子群每次迭代更新的飞行速度,粒子群位置更新的步长;
六、种群全局最优值gbest,既迭代过程中曾经出现的最优解,包括最优位置和对应的目标函数值;
七、个体最优,既每个粒子迭代过程中单个体曾经出现的个体最优解,,包括个体最优位置和对应的目标函数值;
八、个体学习因子c1,既个体最优解对粒子群飞行的影响能力;
九、全局学习因子c2,既全局最优值对粒子群飞行的影响能力;
十、惯性权重w,既个体位置所占的权重,权重越大,粒子群收敛越慢,全局搜索能力越强;
十一、莱维随机因子beta,调整大步长比例的因子。
基于莱维飞行改进的粒子群的流程图

测试函数shubert检验
基于莱维飞行改进的粒子群的优化shubert函数代码
clc
clear
close all
warning off
xmax = [5.12 5.12];
xmin = [-5.12 -5.12];
vmax = 0.2*xmax;
vmin = -vmax;
%程序初始化
% global popsize; %种群规模
gen=100; %设置进化代数
popsize=300; %设置种群规模大小
%混沌映射
xg = lffun();
%tent混沌映射
% xg = tentfun();
best_in_history(gen)=inf; %初始化全局历史最优解
best_in_history(:)=inf; %初始化全局历史最优解
best_fitness=inf;
m =2;
%设置种群数量
pop1 = zeros(popsize,m);
pop2 = zeros(popsize,m);
pop3 = zeros(popsize,m);
fun = @shubert;
tx = 0;
for ii1=1:popsize
tx = tx + 1;
pop1(ii1,:)=funxl(xmin,xmax,m,xg((tx-1)*2+1:2*tx)); %初始化种群中的粒子位置,
pop3(ii1,:)=pop1(ii1,:); %初始状态下个体最优值等于初始位置
pop2(ii1,:)=funv(vmax,m); %初始化种群微粒速度,
pop4(ii1,1)=inf;
pop5(ii1,1)=inf;
end
pop0 = pop1;
xg0 = xg;
c1=2;
c2=2;
gbest_x=pop1(1,:); %全局最优初始值为种群第一个粒子的位置
pop0 = pop1;
figure
for exetime=1:gen
ww = 0.7*(gen-exetime)/gen+0.2;
for ii4=1:popsize
pop2(ii4,:)=(ww*pop2(ii4,:)+c1*rand()*(pop3(ii4,:)-pop1(ii4,:))+c2*rand()*(gbest_x-pop1(ii4,:))); %更新速度
for jj = 1:m
if pop2(ii4,jj)<vmin(jj)
pop2(ii4,jj)=vmin(jj);
elseif pop2(ii4,jj)>vmax(jj)
pop2(ii4,jj)=vmax(jj);
end
end
end
%更新粒子位置
for ii5=1:popsize
pop1(ii5,:)=pop1(ii5,:)+pop2(ii5,:);
for jj2 = 1:m
if pop1(ii5,jj2)>xmax(jj2)
pop1(ii5,jj2) = xmax(jj2);
elseif pop1(ii5,jj2)<xmin(jj2)
pop1(ii5,jj2)=xmin(jj2);
end
end
% 自适应粒子变异
% if rand>0.65
% k=ceil(m*rand);
% pop1(ii5,k) = (xmax( k)-xmin(k)).*rand(1,1)+xmin(k);
% end
% if pop5(ii5)>sum(pop5)/popsize
% pop1(ii5,:) = (xmax-xmin).*rand(1,m)+xmin;
% end
end
if exetime-1>0
plot(1:length(best_in_history(1:exetime-1)),best_in_history(1:exetime-1));
xlabel('迭代次数')
ylabel('适应度值')
title('混沌粒子群迭代收敛图')
hold on;
end
%计算适应值并赋值
for ii3=1:popsize
[my,mx] = fun2(pop1(ii3,:));
pop5(ii3,1)=my;
pop7(ii3,:) = mx;
if pop4(ii3,1)>pop5(ii3,1) %若当前适应值优于个体最优值,则进行个体最优信息的更新
pop4(ii3,1)=pop5(ii3,1); %适值更新
pop3(ii3,:)=pop1(ii3,:); %位置坐标更新
end
end
%计算完适应值后寻找当前全局最优位置并记录其坐标
if best_fitness>min(pop4(:,1))
best_fitness=min(pop4(:,1)) ; %全局最优值
ag = [];
ag =find(pop4(:,1)==min(pop4(:,1)));
gbest_x(1,:)=(pop1(ag(1),:)); %全局最优粒子的位置
pop6(exetime,:) = pop7(ag(1),:);
else
if exetime>1
pop6(exetime,:) = pop6(exetime-1,:);
end
end
best_in_history(exetime)=best_fitness; %记录当前全局最优
if exetime>15
tx = tx+1 ;
pop1(1,:) = 0.95*gbest_x+0.1*xg((tx-1)*2+1:2*tx);
end
end
x = -2:0.1:2;
y = -2:0.1:2;
x = -10:0.1:10;
y = -10:0.1:10;
[x,y] = meshgrid(x,y);
[m,n] = size(x);
z = zeros(m,n);
for ii = 1:m
for jj = 1:n
xx = [x(ii,jj) y(ii,jj)];
z(ii,jj) = shubertfun(xx);
end
end
figure
surf(x,y,z)
hold on
xlabel('x1')
ylabel('x2')
zlabel('z')
axis([-2 2 -2 2 -200 200])
% axis([-10 10 -10 10 -200 200])
% shading interp
title('Shubert Function')
set(gca,'fontsize',12)
colormap jet
plot(pop0(:,1),pop0(:,2),'ro','MarkerFaceColor','r')
xlabel('X')
ylabel('Y')
title('初始种群')
set(gca,'fontsize',12)
view([-130 40])
figure
surf(x,y,z)
hold on
xlabel('x1')
ylabel('x2')
zlabel('z')
axis([-2 2 -2 2 -200 200])
% axis([-10 10 -10 10 -200 200])
% shading interp
title('Shubert Function')
set(gca,'fontsize',12)
colormap jet
plot(pop1(:,1),pop1(:,2),'ro','MarkerFaceColor','r')
xlabel('X')
ylabel('qq2027771338')
title('收敛后的种群')
set(gca,'fontsize',12)
view([-130 40])
function [ xg] = lffun( )
x = [0,0];
y = [0,0];
beta = 1.25;
sigma_u = (gamma(1+beta)*sin(pi*beta/2)/(gamma((1+beta)/2)*beta*2^((beta-1)/2)))^(1/beta);
sigma_v = 1;
X =x(2);
Y =y(2);
for i=1:1000
u = normrnd(0,sigma_u);
v = normrnd(0,sigma_v);
s = u/(abs(v))^(1/beta);
x(:,1) = x(:,2);
x(:,2) = x(:,1)+1*s;
u = normrnd(0,sigma_u);
v = normrnd(0,sigma_v);
s = u/(abs(v))^(1/beta);
y(:,1) = y(:,2);
y(:,2) = y(:,1)+1*s;
X = [X x(2)];
Y = [Y y(2)];
plot(x,y);
hold on;
end
[mx,px] = mapminmax(X,0,1);
[my,py] = mapminmax(Y,0,1);
xg = [mx my];
end
function x=funv(vmax,m)
x = 2.*vmax(1:m).*rand(1,m)-vmax(1:m);
end
function x=funx(xmin,xmax,m)
x = (xmax(1:m)-xmin(1:m)).*rand(1,m)+xmin(1:m);
end
基于莱维飞行改进的粒子群优化shubert效果图如下:



检验结果分析
从测试效果图可以看出来,改进的粒子群ISPSO收敛速度较快,收敛后依然有跳出全局最优的能力。
基于莱维飞行改进粒子群优化LSTM客流量预测
客流预测
客流预测是指对未来客运交通需求量的预测。考虑经济社会发展,交通设施的建设及相关因素,预计采用某种交通方式的客运交通需求量规模,为客运交通运输规划提供科学的依据。对未来年将发生的交通总量,包括流量、流向以及在时间、空间方式上的分布所作的预估。交通分析中的重要内容,本文用改进的粒子群ISPSO优化LSTM进行客流量预测
LSTM长短期神经网络
lstm简介
长短期记忆网络(Long-Short Term Memory,LSTM)论文首次发表于1997年。由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。 [3]
LSTM的表现通常比时间递归神经网络及隐马尔科夫模型(HMM)更好,比如用在不分段连续手写识别上。2009年,用LSTM构建的人工神经网络模型赢得过ICDAR手写识别比赛冠军。LSTM还普遍用于自主语音识别,2013年运用TIMIT自然演讲数据库达成17.7%错误率的纪录。作为非线性模型,LSTM可作为复杂的非线性单元用于构造更大型深度神经网络。
结构
LSTM是特殊的RNN,尤其适合顺序序列数据的处理,内部由遗忘门、输入门和输出门组成,循环神经网络(RNNs):通过不断将信息循环操作,保证信息持续存在,从而解决不能结合经验来理解当前问题的问题。RNN和LSTM都只能依据之前时刻的时序信息来预测下一时刻的输出,
训练方法
为了最小化训练误差,梯度下降法(Gradient descent)如:应用时序性倒传递算法,可用来依据错误修改每次的权重。梯度下降法在递回神经网络(RNN)中主要的问题初次在1991年发现,就是误差梯度随着事件间的时间长度成指数般的消失。当设置了LSTM 区块时,误差也随着倒回计算,从output影响回input阶段的每一个gate,直到这个数值被过滤掉。因此正常的倒传递类神经是一个有效训练LSTM区块记住长时间数值的方法。
MATLAB编程实现
%主要代码,需要代码完整代码文章下留言
%读取数据
clc
clear
close all
clear global ver
%读取double格式数据
[num1,ax,ay ]= xlsread(‘数据1.xlsx’,1);
num1(:,4) = smooth(num1(:,4)‘,7);
n1 = length(num1);
pan =5;
num = zeros(n1-pan,pan+1);
for ii = 1:n1-pan
num(ii,:) = num1(ii:ii+pan,4)’;
end
xg=lffun();
m = round(0.8*length(num));
n = randperm(length(num));
input_train =num(n(1:m),1:pan)‘;%训练数据输入数据
output_train = num(n(1:m),pan+1)’;%训练数据输出数据
input_test = num(1:end,1:pan)‘;%测试数据输入数据
output_test = num(1:end,pan+1)’;%测试数据输出数据
[inputn,inputps]=mapminmax(input_train,-1,1);%训练数据的输入数据的归一化
[outputn,outputps]=mapminmax(output_train,-1,1);%训练数据的输出数据的归一化de
inputn_test=mapminmax(‘apply’,input_test,inputps);
outputn_test=mapminmax(‘apply’,output_test,outputps);
[lstm_pred,lstmerror1] = lstmfun(num,inputn,outputn,inputn_test,output_test,pan,outputps);
[AllSamInn,minAllSamIn,maxAllSamIn,AllSamOutn,minAllSamOut,maxAllSamOut]=premnmx(input_train,output_train);
EvaSamIn=input_test;
EvaSamInn=tramnmx(EvaSamIn,minAllSamIn,maxAllSamIn); % preprocessing
Ptrain = AllSamInn;
Ttrain = AllSamOutn;
% Initialize PSO
vmax=0.0151; % Maximum velocity
minerr=0.001; % Minimum error
wmax=0.90;
wmin=0.30;
% global itmax; %Maximum iteration number
itmax=10;
c1=2;
c2=2;
for iter=1:itmax
W(iter)=wmax-((wmax-wmin)/itmax)*iter; % weight declining linearly
end
%Between (m,n), (which can also be started from zero)
m=-1;
n=1;
% global N; % number of particles
N=5;
% global D; % length of particle
D=4;
gbests = [100 100 100 0.2];%
% particles are initialized between (a,b) randomly
a=[200 200 200 0.98];
b=[10 10 10 0.05];
% Initialize positions of particles
% rand(‘state’,sum(100*clock));
X = [];
for ii = N
X =[X;a+(b-a).rand(N,D,1)]; %取值范围[-1,1] rand * 2 - 1 ,rand 产生[0,1]之间的随机数
end
%Initialize velocities of particles
V=0.2(m+(n-m)*rand(N,D,1));
%
% global fvrec;
MinFit=[];
BestFit=[];
fitness=fitcal(X,num,inputn,outputn,inputn_test,output_test,pan,outputps);
fvrec(:,1,1)=fitness(:,1,1);
[C,I]=min(fitness(:,1,1));
MinFit=[MinFit C];
BestFit=[BestFit C];
L(:,1,1)=fitness(:,1,1); %record the fitness of particle of every iterations
B(1,1,1)=C; %record the minimum fitness of particle
gbest(1,:,1)=X(I,:,1); %the global best x in population
%Matrix composed of gbest vector
for p=1:N
G(p,:,1)=gbest(1,:);
end
for ii=1:N
pbest(ii,:,1)=X(ii,:);
end
V(:,:,2)=W(1)V(:,:,1)+c1rand*(pbest(:,:,1)-X(:,:,1))+c2rand(G(:,:,1)-X(:,:,1));
for ni=1:N
for di=1:D
if V(ni,di,2)>vmax
V(ni,di,2)=vmax;
elseif V(ni,di,2)<-vmax
V(ni,di,2)=-vmax;
else
V(ni,di,2)=V(ni,di,2);
end
end
end
X(:,:,2)=X(:,:,1)+V(:,:,2);
for ni=1:N
for di=1:D
if X(ni,di,2)>1
X(ni,di,2)=1;
elseif X(ni,di,2)<-1
X(ni,di,2)=-1;
else
X(ni,di,2)=X(ni,di,2);
end
end
end
%******************************************************
for jj=2:itmax
disp(‘Iteration and Current Best Fitness’)
disp(jj-1)
disp(B(1,1,jj-1))
reset =1; % reset = 1时设置为粒子群过分收敛时将其打散,如果=1则不打散
if reset1
bit = 1;
for k=1:N
bit = bit&(range(X(k,:))<0.02);
end
if bit1 % bit=1时对粒子位置及速度进行随机重置
for ik = 1:N
X(ik,:) = funx; % present 当前位置,随机初始化
X(ik,:) = [0.02rand()-0.01 0.02rand()-0.01]; % 速度初始化
end
end
end
% Calculation of new positions
fitness=fitcal(X,num,inputn,outputn,inputn_test,output_test,pan,outputps);
[C,I]=min(fitness(:,1,jj));
MinFit=[MinFit C];
BestFit=[BestFit min(MinFit)];
L(:,1,jj)=fitness(:,1,jj);
B(1,1,jj)=C;
gbest(1,:,jj)=X(I,:,jj);
[C,I]=min(B(1,1,:));
% keep gbest is the best particle of all have occured
if B(1,1,jj)<=C
gbest(1,:,jj)=gbest(1,:,jj);
else
gbest(1,:,jj)=gbest(1,:,I);
end
if C<=minerr
break
end
%Matrix composed of gbest vector
if jj>=itmax
break
end
for p=1:N
G(p,:,jj)=gbest(1,:,jj);
end
for ii=1:N
[C,I]=min(L(ii,1,:));
if L(ii,1,jj)<=C
pbest(ii,:,jj)=X(ii,:,jj);
else
pbest(ii,:,jj)=X(ii,:,I);
end
end
V(:,:,jj+1)=W(jj)*V(:,:,jj)+c1*rand*(pbest(:,:,jj)-X(:,:,jj))+c2*rand*(G(:,:,jj)-X(:,:,jj));
for ni=1:N
for di=1:D
if V(ni,di,jj+1)>vmax
V(ni,di,jj+1)=vmax;
elseif V(ni,di,jj+1)<-vmax
V(ni,di,jj+1)=-vmax;
else
V(ni,di,jj+1)=V(ni,di,jj+1);
end
end
end
X(:,:,jj+1)=X(:,:,jj)+V(:,:,jj+1);
for ni=1:N
for di=1:D
if X(ni,di,jj+1)>1
X(ni,di,jj+1)=1;
elseif X(ni,di,jj+1)<-1
X(ni,di,jj+1)=-1;
else
X(ni,di,jj+1)=X(ni,di,jj+1);
end
end
end
end
disp(‘Iteration and Current Best Fitness’)
disp(jj)
disp(B(1,1,jj))
disp(‘Global Best Fitness and Occurred Iteration’)
[C,I]=min(B(1,1,:));
numFeatures = size(num(:,1:pan),2);%输入层维度
numResponses = size(num(:,end),2);%输出维度
x= gbest;
x(:,1:3) = round( gbest(:,1:3));
numHiddenUnits = x(1,1);%第一层维度
% a fully connected layer of size 50 & a dropout layer with dropout probability 0.5
layers = [ …
sequenceInputLayer(numFeatures)%输入层
lstmLayer(numHiddenUnits,‘OutputMode’,‘sequence’)%第一层
fullyConnectedLayer(x(1,2))%链接层
dropoutLayer(x(1,4))%遗忘层
fullyConnectedLayer(numResponses)%链接层
regressionLayer];%回归层
% Specify the training options.
% Train for 60 epochs with mini-batches of size 20 using the solver ‘adam’
maxEpochs = 20;%最大迭代次数
miniBatchSize = x(1,3);%最小批量
% the learning rate == 0.01
% set the gradient threshold to 1
% set ‘Shuffle’ to ‘never’
options = trainingOptions(‘adam’, … %解算器
‘MaxEpochs’,maxEpochs, … %最大迭代次数
‘MiniBatchSize’,miniBatchSize, … %最小批次
‘InitialLearnRate’,0.001, … %初始学习率
‘GradientThreshold’,inf, … %梯度阈值
‘Shuffle’,‘every-epoch’, … %打乱顺序
‘Plots’,‘none’,… %画图
‘Verbose’,0); %不输出训练过程
%% Train the Network
net = trainNetwork(inputn_test,outputn_test,layers,options);%开始训练
%% Test the Network
plolstm_pred0 = predict(net,inputn_test,‘MiniBatchSize’,x(1,3))‘;%测试仿真输出
plolstm_pred=(mapminmax(‘reverse’, plolstm_pred0,outputps))’;
error1 = plolstm_pred-output_test;%误差
wucha = mean(abs(error1));
toc
figure(1)
grid
hold on
plot((BestFit),‘r’);
title([‘粒子群算法优化lstm ’ ‘最优代数=’ I]);
xlabel(‘进化代数’);ylabel(‘误差’);
disp(‘适应度变量’);
figure(2)
grid
plot(plolstm_pred,’-^g’)
hold on
plot(lstm_pred,‘-ob’)
hold on
plot(output_test,‘-*r’);
legend(‘莱维飞行粒子群优化lstm预测输出’,‘lstm预测输出’,‘期望输出’)
title(‘粒子群优化lstm网络预测输出’,‘fontsize’,12)
ylabel(‘客流量’,‘fontsize’,12)
xlabel(‘样本’,‘fontsize’,12)
效果图


结果分析
从优化结果看,最佳参数所在的范围比较小,初始粒子群没有搜寻到,梯度差比较少,但是粒子群再莱维飞行的改进下,很快跳出局部最优,并加速收敛,达到寻找最佳参,实现lstm客流量预测的目标.
展望
粒子群算法是一种比较成熟的算法,经过改进扩展,可以应用的方面非常多,对于以下问题但不限,都可以用粒子群求解,欢迎大家留言交流