这是CVPR2021的一篇文章, 是利用SOT的一些思想来进行MOT的运动估计.
文章地址: 文章
代码地址: 代码
0. 摘要
本文提出了一个孪生(Siamese)式的MOT网络, 该网络用来估计帧间目标的运动. 为了探究运动估计对多目标跟踪的影响, 本文提出了两种运动建模方式: 显式和隐式. 本文在一些数据集上取得了良好的结果.
1. 整体思路
这篇文章是用SOT的思想做MOT的比较好的例子.
整个工作的具体思路是: 利用Siamese网络来更好地预测运动, 而不是Kalman滤波, 相当于用Siamese网络代替了Kalman.
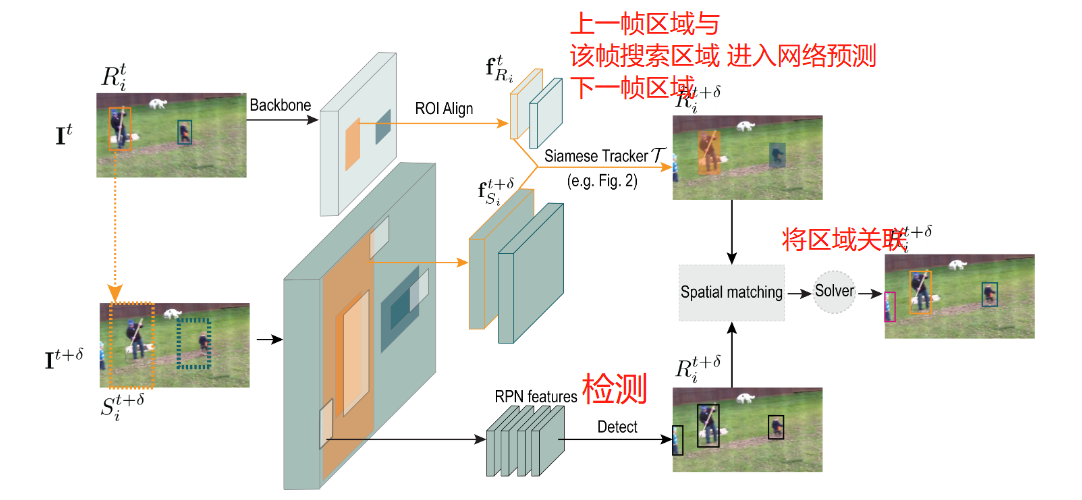
例如, 对于第 t t t帧, 我们有第 i i i个目标的位置 R i t R_i^t Rit, 然后我们扩张搜索区域, 在第 t + δ t + \delta t+δ帧将 R i t R_i^t Rit的区域扩展, 初步决定搜索区域为 S i t + 1 S_i^{t+1} Sit+1, 如下图橙色框所示. 我们的目的是用Siamese网络更好地从 S i t + 1 S_i^{t+1} Sit+1中估计出目标在下一帧更精确的位置, 进而与检测更好地匹配.
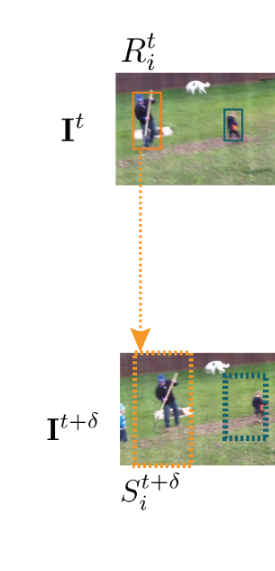
为此, 我们提取 R i t R_i^t Rit的特征 f R i t f_{R_i}^t fRit和 S i t + 1 S_i^{t+1} Sit+1的特征 f S i t + δ f_{S_i}^{t+\delta} fSit+δ, 输入至网络中, 输出缩小的可能的新区域 R ~ i t + δ \tilde{R}_{i}^{t+\delta} R~it+δ和该区域中包含目标的可能性 v i v_i vi, 因此整体的模型建模为:
v i , R ~ i t + δ = T ( f R i t , f S i t + δ , Θ ) v_i, \tilde{R}_{i}^{t+\delta} = \mathcal{T}(f_{R_i}^t, f_{S_i}^{t+\delta}, \Theta) vi,R~it+δ=T(fRit,fSit+δ,Θ)
其中 Θ \Theta Θ为网络参数.
上式建模的方式有两种, 一是隐式运动建模, 二是显式运动建模.
1.1 隐式运动建模:
隐式运动建模很简单, 将 f R i t f_{R_i}^t fRit和 f S i t + δ f_{S_i}^{t+\delta} fSit+δ拼接起来输入到MLP, 同时预测置信度和位置. 位置描述的是 t t t时刻与 t + δ t+\delta t+δ时刻的位置差异, 表示为:
m i = [ x i t + δ − x i t x i t , y i t + δ − y i t y i t , log w i t + δ w i t , log h i t + δ h i t ] m_i = [\frac{x_i^{t + \delta} - x_i^t}{x_i^t}, \frac{y_i^{t + \delta} - y_i^t}{y_i^t}, \log{\frac{w_i^{t+\delta}}{w_i^t}}, \log{\frac{h_i^{t+\delta}}{h_i^t}}] mi=[xitxit+δ−xit,yityit+δ−yit,logwitwit+δ,loghithit+δ]
因此可以反解出新的位置 R ~ i t + δ = [ x i t + δ , y i t + δ , w i t + δ , h i t + δ ] \tilde{R}_{i}^{t+\delta} = [x_i^{t + \delta}, y_i^{t + \delta}, w_i^{t + \delta}, h_i^{t + \delta}] R~it+δ=[xit+δ,yit+δ,wit+δ,hit+δ]
损失函数:
损失函数由两部分组成, 一是目标置信度的focal loss, 二是预测边界框的准确程度. 对于GT框, 我们可以按照 m i m_i mi的式子求出对应的 m i ∗ m_i^* mi∗ , 定义为:
L = l f o c a l ( v i ∗ , v i ) + I ( v i ∗ ) l r e g ( m i , m i ∗ ) L = l_{focal}(v_i^*, v_i)+\mathbb{I}(v_i^*)l_{reg}(m_i, m_i^*) L=lfocal(vi∗,vi)+I(vi∗)lreg(mi,mi∗)
其中上标 ∗ * ∗表示真值, l r e g l_{reg} lreg表示平滑L1损失.
1.2 显式运动建模
还可以采用更复杂的形式. 采用通道维的互相关操作, 可以通过预测热度图的方式计算像素级的响应图, 有点类似于求解光流. 对于第 t t t帧的区域特征 f R i t f_{R_i}^t fRit和第 t + δ t+\delta t+δ帧的初步搜索区域特征 f S i t + δ f_{S_i}^{t+\delta} fSit+δ, 计算通道维互相关, 即 r i = f R i t ∗ f S i t + δ r_i = f_{R_i}^t * f_{S_i}^{t+\delta} ri=fRit∗fSit+δ, 其中 ∗ * ∗表示互相关操作, 这样就得到了两种特征图的相似度.
我们利用得到的 r i r_i ri, 进一步预测像素级置信度的map v v v和位置的map p p p, 如下图所示.
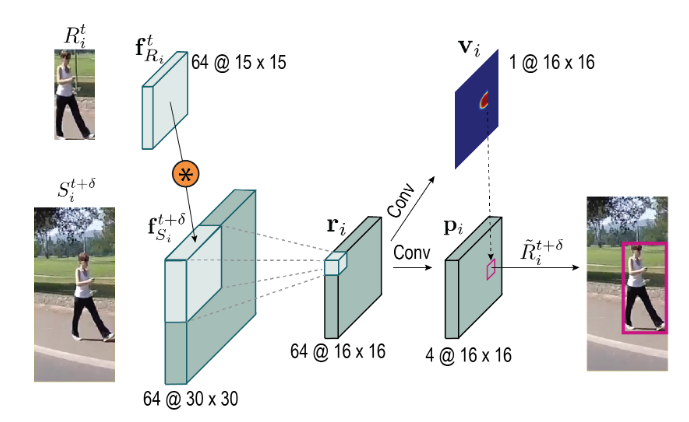
注意这里位置的map和一些无锚检测器类似, 预测的是offset. 具体地, 预测的是真实的bbox与当前像素四个方向的offset. 为此, 我们可以以像素级的置信度相应map中最大的点为准, 找到位置map中对应的位置, 即可直接求解出预测的位置. 也就是:
R ~ i t + δ = R ( p i ∗ ( x , y ) ) ; v i t + δ = v i ( x ∗ , y ∗ ) s . t . ( x ∗ , y ∗ ) = arg max x , y ( v i ∗ η i ) \tilde{R}_i^{t+\delta}=\mathcal{R}(p_i^*(x, y)); ~~~~v_i^{t+\delta} = v_i(x^*, y^*) \\ s.t. ~~~(x^*, y^*) = \arg\max_{x,y}(v_i * \eta_i) R~it+δ=R(pi∗(x,y)); vit+δ=vi(x∗,y∗)s.t. (x∗,y∗)=argx,ymax(vi∗ηi)
其中 η i \eta_i ηi为:
η i ( x , y ) = λ C + ( 1 − λ ) S ( R ( p ( x , y ) ) , R i t ) \eta_i(x, y)= \lambda\mathcal{C}+(1-\lambda)\mathcal{S}(\mathcal{R(p(x,y))},R_i^t) ηi(x,y)=λC+(1−λ)S(R(p(x,y)),Rit)
表示的是一个penalty map, 其中 C \mathcal{C} C是以过去帧位置 R i t R_i^t Rit的几何中心为中心的cos窗函数, S \mathcal{S} S是预测出的位置和原本位置高宽差异的高斯函数, η i \eta_i ηi的作用是为了防止bbox尺寸的突然变化.
损失函数:
与隐式建模类似, 损失函数也是由置信度损失和bbox位置损失组成, 所不同的是该部分预测的是逐像素map, 因此需要逐像素进行计算. 置信度损失仍为focal loss, 位置损失包括中心点的差异与回归损失, 如下式所示:
L = ∑ x , y l f o c a l ( v i ( x , y ) , v i ∗ ( x , y ) ) + ∑ x , y I [ v i ∗ ( x , y ) = 1 ] ( w ( x , y ) ⋅ l r e g ( p i ( x , y ) , p i ∗ ( x , y ) ) ) L = \sum_{x, y}l_{focal}(v_i(x, y), v_i^*(x, y))+\\ \sum_{x, y}\mathbb{I}[v_i^*(x, y) =1](w(x, y) ·l_{reg}(p_i(x, y), p_i^*(x, y))) L=x,y∑lfocal(vi(x,y),vi∗(x,y))+x,y∑I[vi∗(x,y)=1](w(x,y)⋅lreg(pi(x,y),pi∗(x,y)))
w ( x , y ) w(x, y) w(x,y)就是中心点差异.
1.3 训练和推理
训练是按照端到端的方式训练的, 将Faster RCNN的检测损失与上面的损失结合. 推理也比较普通, 就是利用推理出的 R ~ i t + δ \tilde{R}_{i}^{t+\delta} R~it+δ和检测器检测的 R i t + δ R_{i}^{t+\delta} Rit+δ简单进行匹配即可.
整体流程下图所示:
2. 评价
这篇是很简单的一个笔记, 在SOT+MOT的方法里, 这篇应该也算简洁的, 创新之处在于隐式建模反推位置那一块, 以及逐像素map的思想也值得学习.