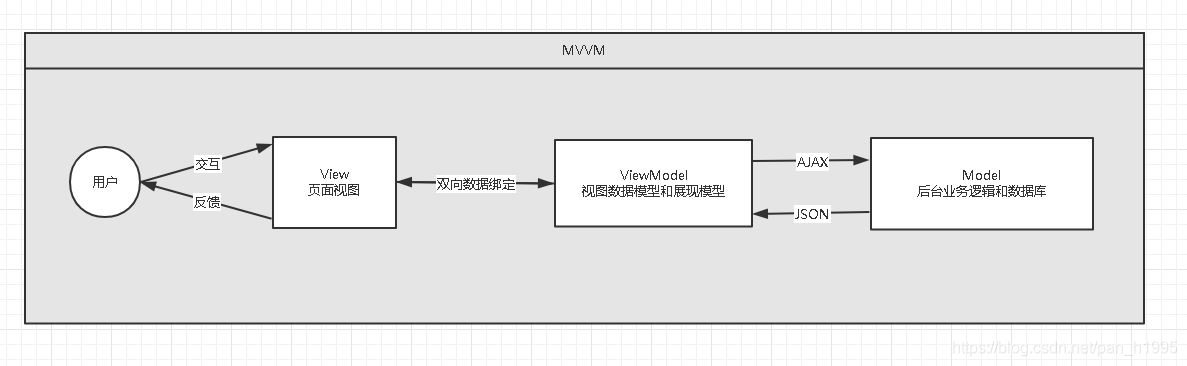
Redis缓存的一致性
- 1. 缓存
- 1.1 缓存的作用:
- 1.2 缓存的成本:
- 2. 缓存模型
- 3. 缓存一致性问题
- 3.1 引入
- 3.2 解决
- (1) 先更新数据库,再手动删除缓存
- (2) 使用事务保证原子性
- (3) 以Redis中的TTL为兜底
- 3.3 案例:商铺信息查询和更新
- (1) 查询商铺信息
- (2) 更新商铺信息
1. 缓存
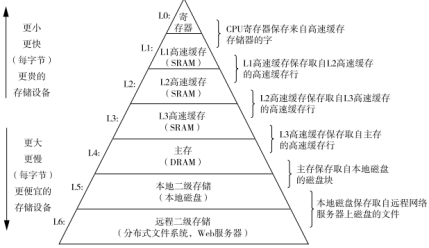
定义:缓存就是数据交换的缓冲区,称为Cache,是存储数据的临时地方,读写性能较高;
CPU在执行时需要从内存/磁盘读取数据放到寄存器中才可以做运算;这种读写的性能限制了cpu的性能!
所以在【CPU的内部】添加高速缓存Cache,CPU会将经常读写的数据放到缓存中(局部性原理),当做高速运算时就不用再把数据从内存/磁盘拷贝过来再运算了,充分释放CPU的运算性能,提高运算效率;
1.1 缓存的作用:
- 降低后端负载,当请求进入Tomcat后,不用查数据库(需要查询磁盘比较慢);
而使用缓存,请求从缓存中查到数据后直接返回前端,不用查数据库; - 提高读写效率,降低响应时间,Redis的读写在微妙级别,比读写数据库(磁盘)快很多
1.2 缓存的成本:
- 数据的一致性问题:当数据库数据变化,那么缓存中数据就不是最新的了,这是数据就不一致了;
- 增加代码维护成本:为了解决缓存和数据库不一致,需要使用复杂的代码来维护(缓存穿透、击穿);
3.运维成本:为了避免缓存缓存雪崩,保证缓存的高可用,缓存往往是集群模式,而集群的部署、维护需要运维;
2. 缓存模型
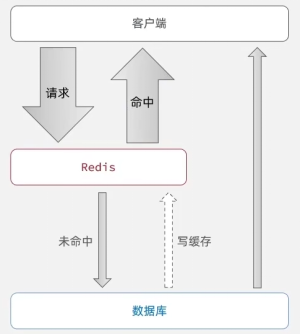
在客户端和数据库之间添加了一个中间层!
这样客户端请求会优先到达缓存Redis!
如果Redis中有数据就返回,就不用走数据库了(请求命中); 若没有才去查询数据库(未命中);
将未命中的数据写到Redis中,这样下一次再查询就可以使用缓存了;
随着用户请求越多,Redis中缓存的数据越多,Redis的命中率就会越来越高;
3. 缓存一致性问题
3.1 引入
当对数据库修改,缓存未更改,就出现了缓存一致性的问题;
3.2 解决
(1) 先更新数据库,再手动删除缓存
考虑:
1. 删除缓存还是更新缓存?
更新:每当数据库更新,缓存都要更新,开销较大,可能很多是无效操作(用户没查); ×
删除:更新数据库时让缓存失效,用户查询时再去更新 √;
2. 先删除缓存还是先更新数据库? (并发场景)
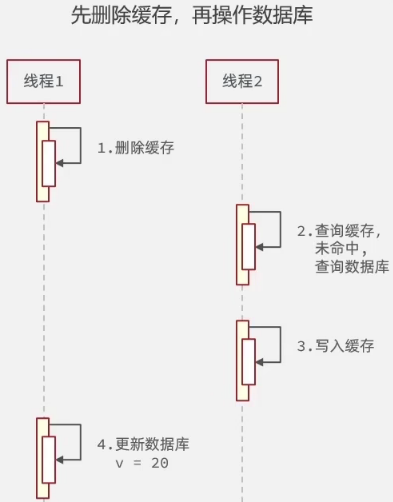
先缓存,再数据库:
假设线程1先更新缓存再更新数据库,那么当缓存先被删除后,更新数据库的时间会比较长,如果这段时间内有其他线程2来查询缓存(查询较快),由于已经被删除则会去数据库查,查完之后再写回缓存;而之前更新数据库的线程1这是才更新完数据库,此时缓存是旧值,数据库是新值;
先数据库,再缓存:
假设线程1先查询,此时缓存失效了,就去查询数据库中数为A,而此时线程2来更新数据库数为B,并删除了缓存,而后线程1 将数据A更新到缓存,而此时数据库是B,缓存是A;
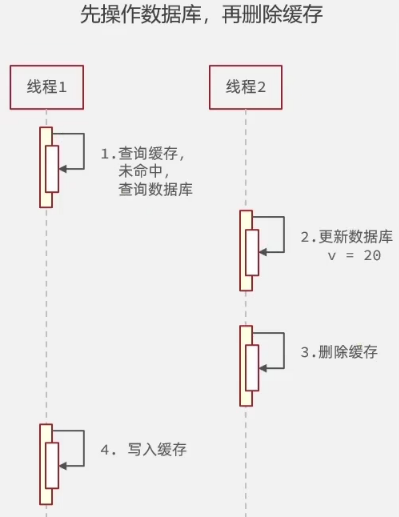
但是线程2更新数据库是很慢的,一般不会比线程1 查询快,所以发生一致性问题的可能性很低,所以使用先修改数据库,再删除缓存!
(2) 使用事务保证原子性
单体系统:将缓存和数据库操作放在一个事务中!
分布式系统:缓存操作和数据库操作可能不在同一个服务器中,则利用TCC等分布式事务;
(3) 以Redis中的TTL为兜底
用expire方法设置Redis的TTL有效时间!让缓存中的数据定期清除,这样也能保证一定的有效性;
3.3 案例:商铺信息查询和更新

需求:
1.【查询】:根据id查询店铺,如果未命中则查询数据库,查询数据库数据,并更新到缓存,设置超时时间;
2.【更新】:当在数据库修改店铺id时,先修改数据库,再删除缓存;
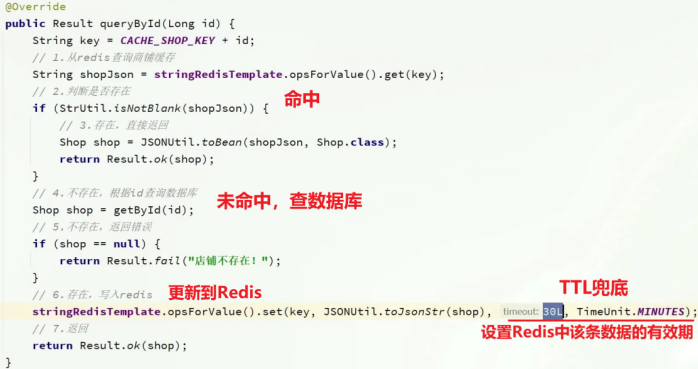
(1) 查询商铺信息
1.注入stringRedisTemplate的bean,从Redis查询商户缓存,如果命中则返回商铺信息
这里存商铺信息的是String格式,则需要将String格式的Json反序列化为Java对象;
2.未命中则查询数据库,若不存在,报错;
3.若数据库中存在,则用stringRedisTemplate.opsForVlaue将商铺信息写到Redis中,并更新TTL有效时间(兜底)!
4.再把商铺信息数据返回;
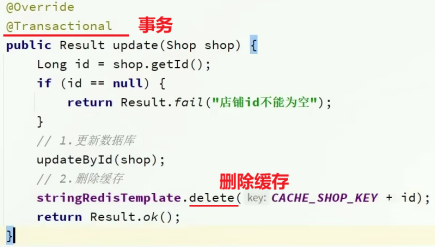
(2) 更新商铺信息
更新数据库和删除缓存在同一个 事务 中!
1.判断id是否存在,不存在则报错;
2.先更新数据库
3.再根据id删除缓存中的数据