目录
1. scrapy-redis是什么?
2. scrapy-redis工作原理
3.分布式架构
4. scrapy-redis的源码分析
5. 部署scrapy-redis
6. scrapy-redis的基本使用
6.1 redis数据库基本表项
6.2 在scrapy项目的基础进行更改
7. redis数据转存入mysql数据库
课程推荐:day07_01.scrapy-redis官方案例演示_recv_哔哩哔哩_bilibili
1. scrapy-redis是什么?
scrapy是一个通用的爬虫框架,但是不支持分布式,
scrapy-Redis是为了更方便地实现scrapy分布式爬取,而提供了一些Tredis为基础的组件(仅有组件)
2. scrapy-redis工作原理
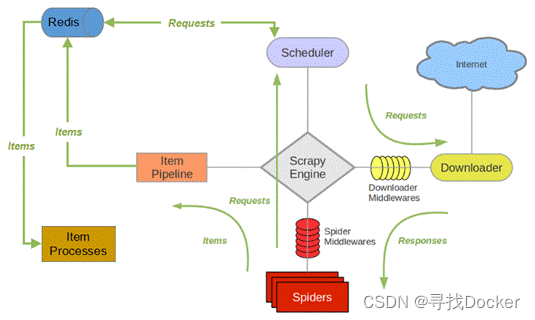
与scrapy框架不同的是,scrapy-redis框架中request链接不再交付于调度器(Scheduler)中url队列,而是保存在redis数据库中,再由过滤器进行过滤,符合要求的请求链接再交付于调度器(Scheduler),此外redis数据还可以存储到本地数据库(item processes)。其余流程与scrapy流程基本相同。
(1) 引擎(Scrapy Engine)向爬虫(Spiders)请求第一个要爬取的URL。
(2) 引擎从爬虫中获取到第一个要爬取的URL,封装成请求(Request)并交给调度器(Scheduler)。
(3) 调度器访问Redis数据库对请求进行判重,如果不重复,就把这个请求添加到Redis中。
(4) 当调度条件满足时,调度器会从Redis中取出Request,交给引擎,引擎将这个Request通过下载中间件转发给下载器。
(5) 一旦页面下载完毕,下载器(Downloader)生成一个该页面的响应(Response),并将其通过下载中间件发送给引擎。
(6) 引擎从下载器中接收到响应,并通过爬虫中间件(Spider Middlewares)发送给爬虫处理。
(7) Spider处理Response,并返回爬取到的Item及新的Request给引擎。
(8) 引擎将爬取到的Item通过Item Pipeline给Redis数据库,将Request给调度器。从(2) 开始重复,直到调度器中没有更多的Request为止。
3.分布式架构
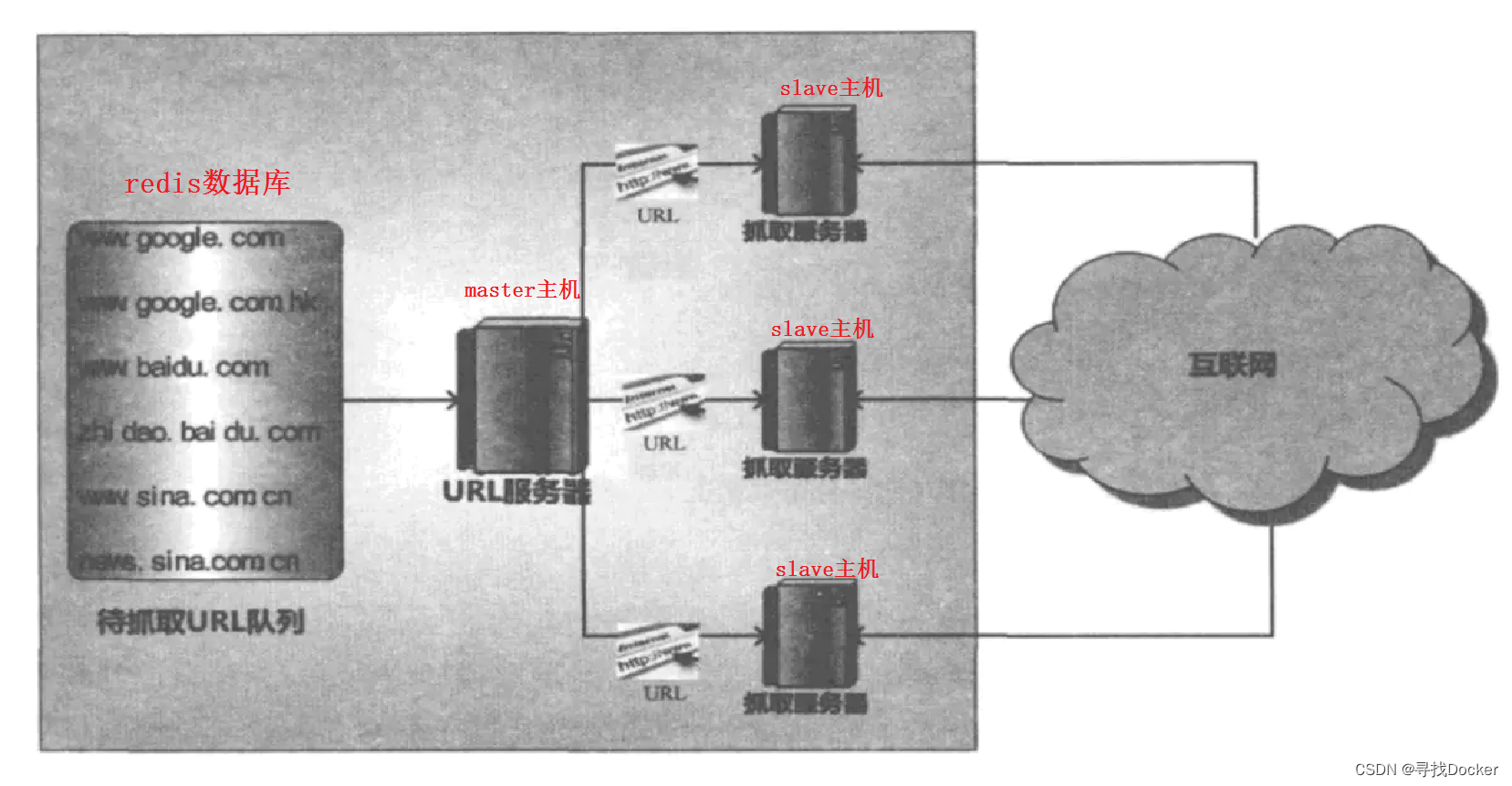
这种框架,主从式框架主要由一台url提供主机(master)向资源爬取主机(slave)提供url,由资源爬取主机依照url爬取相应的资源。这也是scrapy-redis的分布式模式。
4. scrapy-redis的源码分析
(1) 源码地址
GitHub - rmax/scrapy-redis: Redis-based components for Scrapy.
(2) 源码案例详解
example-project为源码给予的案例,我们使用scrapy-redis以此为例。我们仅需分析example-project下的文件即可。与scrapy相同,scrapy-redis主要文件也是由items文件、pipelines文件、setting文件和爬虫文件组成。
items文件: 与scrapy一样,为爬虫文件的数据结构
from scrapy.item import Item, Field
from scrapy.loader import ItemLoader
from scrapy.loader.processors import MapCompose, TakeFirst, Join
# 与scrapy一样,为爬虫文件的数据结构
class ExampleItem(Item):
name = Field()
description = Field()
link = Field()
crawled = Field()
spider = Field()
url = Field()
# 与scrapy中的ItemLoader作用一致
class ExampleLoader(ItemLoader):
default_item_class = ExampleItem
default_input_processor = MapCompose(lambda s: s.strip())
default_output_processor = TakeFirst()
description_out = Join()pipelines文件: 没有特殊需要,pipelines文件不再需要写任何的语句,return会自动将item数据传入数据库。
from datetime import datetime
class ExamplePipeline(object):
def process_item(self, item, spider):
# 时间戳
item["crawled"] = datetime.utcnow()
# 爬虫名,分布式爬虫有多个爬虫,规定爬虫名易于区分
item["spider"] = spider.name
return item
setting文件: scrapy_redis所必须的设置
SPIDER_MODULES = ['example.spiders']
NEWSPIDER_MODULE = 'example.spiders'
USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)'
# 去重类,使用scrapy_redis中的去重类
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 调度器,使用scrapy_redis中的调度器组件
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 是否允许暂停,redis中请求记录不丢失
SCHEDULER_PERSIST = True
# 默认的scrapy-redis请求集合
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue"
# 队列形式,请求url会先进先出
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue"
# 栈形式,请求url会先进后出
# SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"
# 'scrapy_redis.pipelines.RedisPipeline' 支持存储到redis数据库中,必须开启
ITEM_PIPELINES = {
'example.pipelines.ExamplePipeline': 300,
# redis管道,必须设置,不然数据无法传入数据库
'scrapy_redis.pipelines.RedisPipeline': 400,
}
# 日志等级
LOG_LEVEL = 'DEBUG'
# 下载延迟
DOWNLOAD_DELAY = 1
# redis配置
# 指定数据库ip
REDIS_HOST = "127.0.0.1"
# 指定数据库端口号
REDIS_PORT = 6379
爬虫文件(三个不同类型的样例):
domz.py: 非分布式,有链接提取器
# domz.py
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
# 非分布式,有链接提取器
# 使用的是CrawlSpider链接提取器
class DmozSpider(CrawlSpider):
"""Follow categories and extract links."""
name = 'dmoz'
allowed_domains = ['dmoz-odp.org']
start_urls = ['http://www.dmoz-odp.org/']
# 链接提取器的提取规则
rules = [
Rule(LinkExtractor(
restrict_css=('.top-cat', '.sub-cat', '.cat-item')
), callback='parse_directory', follow=True),
]
def parse_directory(self, response):
for div in response.css('.title-and-desc'):
yield {
'name': div.css('.site-title::text').extract_first(),
'description': div.css('.site-descr::text').extract_first().strip(),
'link': div.css('a::attr(href)').extract_first(),
}
mycrawler_redis.py: 分布式,有链接提取器
# mycrawler_redis.py
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
class MyCrawler(RedisCrawlSpider):
name = 'mycrawler_redis'
# 分布式爬虫开启指令,第一个要爬前的url,与数据库中格式需一致
redis_key = 'mycrawler:start_urls'
# 提取链接规则
rules = (
# follow all links
Rule(LinkExtractor(), callback='parse_page', follow=True),
)
# 动态域名,与allowed_domains作用一致,规定可爬url域,可设置多个可爬域
# __init__方法必须按规定写,使用时只需修改super()里的类名参数即可
def __init__(self, *args, **kwargs):
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
# 修改这里的类名为当前类名
super(MyCrawler, self).__init__(*args, **kwargs)
def parse_page(self, response):
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}
myspider_redis.py: 分布式,无链接提取器
from scrapy_redis.spiders import RedisSpider
# 没有链接提取器
class MySpider(RedisSpider):
"""Spider that reads urls from redis queue (myspider:start_urls)."""
name = 'myspider_redis'
# 分布式爬虫开启指令,第一个要爬前的url,与数据库中格式需一致
redis_key = 'myspider:start_urls'
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
# 弹出域名
domain = kwargs.pop('domain', '')
# 准许访问的域名
self.allowed_domains = filter(None, domain.split(','))
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
return {
'name': response.css('title::text').extract_first(),
'url': response.url,
}
5. 部署scrapy-redis
(1) slave端(2台linux系统)
软件配置:python 3 + pip + scrapy + scrapy-redis
安装linux系统:https://shuijinglan.blog.csdn.net/article/details/105604065
配置yum网络源:https://pokes.blog.csdn.net/article/details/124627065
安装python 3(版本要9.9):Linux系统安装Python3环境(超详细) - 知乎
安装scrapy-redis:
pip install scrapy-redis -i https://pypi.douban.com/simple
(2)master端(windows系统)
软件配置: redis + scrapy + scrapy-redis
redis下载:
https://github.com/tporadowski/redis/releases/download/v5.0.14.1/Redis-x64-5.0.14.1.zip
redis.windows.conf配置:
1. 在redis.windows.conf文件中,禁用bind 127.0.0.1
2. 在redis.windows.conf文件中,将daemonize no改为yes
启动redis:先运行redis-server再运行redis-cli
永久启动方法:
Redis下载和安装(Windows系统)
6. scrapy-redis的基本使用
6.1 redis数据库基本表项
爬虫名:dupelines # 已过滤的链接,已爬过的链接不再爬取
爬虫名:items # 爬取的数据,对应items数据项
爬虫名:requests # 请求链接,要爬的url
爬虫名:start_urls # 分布式爬虫开启指令,第一个要爬的url,与数据库中格式需一致
6.2 在scrapy项目的基础进行更改
(1) 在settings中添加配置信息
# scrapy-redis USER_AGENT = 'scrapy-redis (+https://github.com/rolando/scrapy-redis)' # 过滤配置 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 调度引擎 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True # SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" # SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" # SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack"ITEM_PIPELINES = { 'DistrubutedSpider.pipelines.DistrubutedSpiderPipeline': 300, # redis管道,item数据直接入库,必须添加 'scrapy_redis.pipelines.RedisPipeline': 400, }
(2)更改爬虫文件
第一种:带有链接提取器
# 读书网案例
from scrapy.spiders import Rule
from scrapy.linkextractors import LinkExtractor
from scrapy_redis.spiders import RedisCrawlSpider
# 带有链接提取器
class slaveSpider(RedisCrawlSpider):
name = 'slave'
# 起始连接,放在数据库中第一批要爬取得链接,Requests从这批链接的页面中获取
redis_key = 'slave:start_urls'
# 提取链接规则
rules = (
Rule(LinkExtractor(allow=r'/book/1188_\d+\.html'), callback='parse_item', follow=False),
)
# 类似allow_domain,准许多个域名域
# 动态域,__init__方法必须按规定写,使用时只需修改super()里的类名参数即可
def __init__(self, *args, **kwargs):
# Dynamically define the allowed domains list.
domain = kwargs.pop('domain', '')
self.allowed_domains = filter(None, domain.split(','))
# 修改这里的类名为当前类名
super(Master02Spider, self).__init__(*args, **kwargs)
def parse_item(self,response):
# xpath
img_list = response.xpath('//ul/li/div[@class="book-info"]/div/a')
for i in img_list:
src = i.xpath('./img/@data-original').extract_first()
name = i.xpath('./img/@alt').extract_first()
# item
yield {'src': src, 'name': name}
(3)运行程序
在2台linux虚拟机中分别部署爬虫文件,运行,并在redis输入start_urls 。
分布式爬虫文件启动命令:
scrapy runspider 爬虫文件名.py
例:scrapy runspider slave.py
进入Redis数据库输入:
lpush 爬虫文件名:start_urls 要爬的第一条链接
例:lpush slave:start_urls https://www.dushu.com/book/1188_01.html
7. redis数据转存入mysql数据库
(1)安装MySQLdb (python版本为3.7)
pip install mysqlclient==1.3.14
(2)redis数据转存入mysql数据库
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
import MySQLdb
import json
def process_item():
while(True):
# 1.创建redis数据库链接
redis_con = redis.Redis(host="127.0.0.1",port=6379,db=0)
# 2.创建mysql数据库链接
mysql_con = MySQLdb.connect(host="127.0.0.1",port=3306,user="root",password="123456",db="spider01", charset="utf8")
# 3.将数据从redis数据库中pop出来
source,data = redis_con.blpop("demo02:items")
# 4.json转换字符串
item = json.loads(data)
## mysql
# 5.创建mysql的游标对象,执行sql语句
cursor = mysql_con.cursor()
# 6.sql语句
sql = 'insert into book(name,src) values ("{}","{}")'.format(item['name'],item['src'])
# 7.执行sql,%等同于格式化语句.format()
cursor.execute(sql)
# 8.提交
mysql_con.commit()
# 9.结束
cursor.close()
if __name__ == '__main__':
process_item()