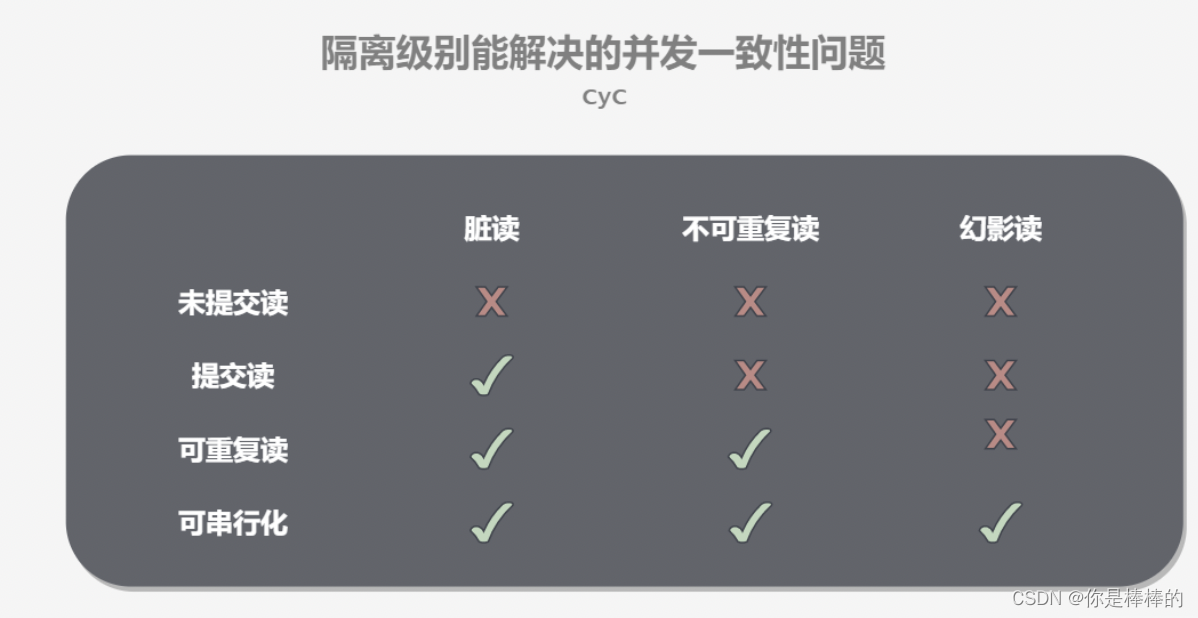
学习内容:


目录
一、双列集合
1、双列集合的特点
2、双列集合的常见API
示例代码
3、Map的遍历方式
①、第一种遍历方式:键找值(keySet)
②、第二种遍历方式:键值对(entrySet)
③、第三种遍历方式:Lambda表达式(forEach)
二、HashMap集合
1、HashMap的特点
2、HashMap的底层原理
3、小结
4、HashMap小练习
①、存储学生对象并遍历
②、Map集合案例-统计投票人数
三、LinkedHashMap
四、TreeMap
1、练习:TreeMap基本应用
2、练习:统计个数
3、小结
五、源码解析
1、HashMap的底层原理(一)
①、源码中的类型介绍
②、HashMap中每一个元素是什么?
2、HashMap的底层原理(二)
①、看源码前的准备工作
②、创建对象、第一种情况:添加元素(添加第一个元素,即数组位置为null)底层原理
③、第二种情况:添加其它元素(数组位置不为null)底层原理
编辑 ④、为什么hashcode值要与数组长度-1做一次“与”运算?【★】
⑤、第三种情况:添加元素(数组位置不为null,键重复,元素覆盖)
3、TreeMap中的底层源码(一)
①、为什么这里的默认颜色为BLACK?
②、TreeMap中每一个节点的内部属性
③、TreeMap类中的成员变量以及构造器
④、put:添加元素
⑤、红黑树规则
⑥、面试小问题
六、可变参数
1、可变参数的练习
①、示例代码:(普通示例)
②、数组使用示例
③、JDK5-可变参数
④、可变参数的小细节
七、Collections
1、addAll() 批量添加元素
2、shuffle() 打乱List集合元素的顺序
3、其它方法
八、综合练习
1、自动点名器
①、自动点名器1(shuffle)
②、自动点名器2(概率 — 随机面)
③、自动点名器3(不重复且会循环点名 — 辅助列表)
④、自动点名器4(权重)
⑤、自动点名器5 —— (GUI界面程序 — 集合、IO、多线程、带权重的随机)
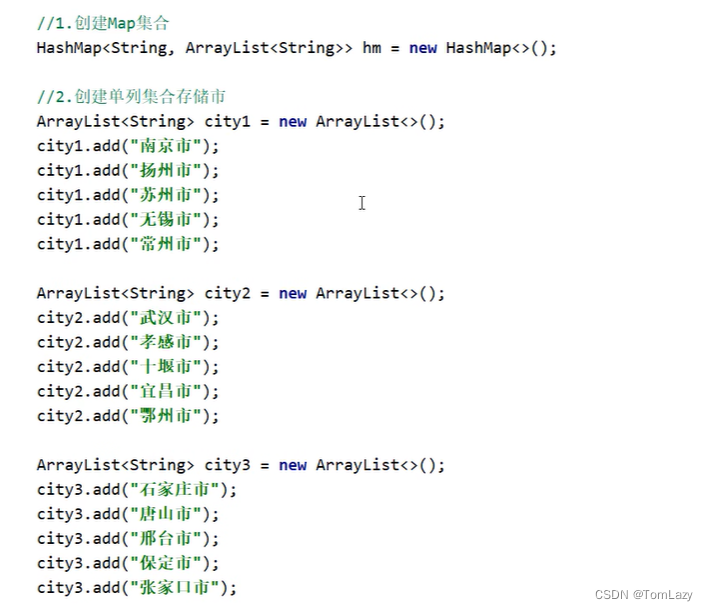
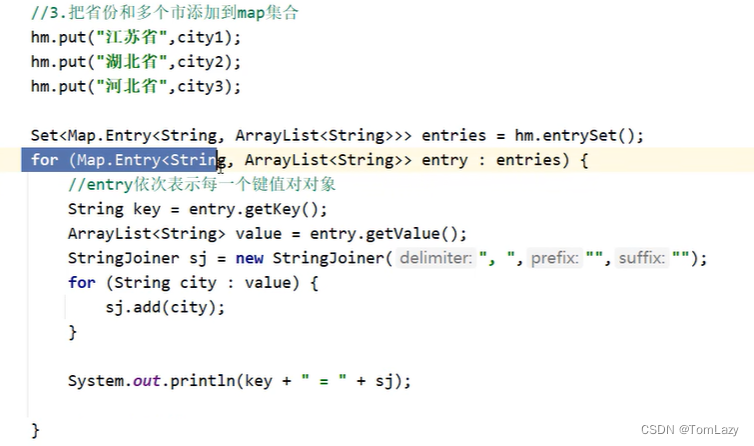
2、Map集合案例——省和市
一、双列集合
1、双列集合的特点

在Map中定义了双列集合所有的共性方法:

2、双列集合的常见API

示例代码
添加元素:put()

删除元素:删除元素,返回删除值 remove()

清空元素:clear()
判断是否包含:containsKey()

判空判断:isEmpty()

长度:size()

3、Map的遍历方式
①、第一种遍历方式:键找值(keySet)

课堂练习:

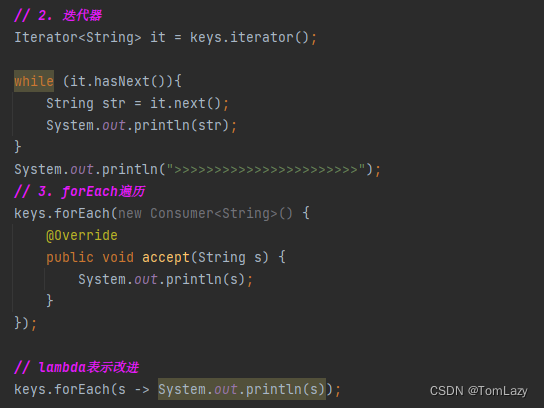
②、第二种遍历方式:键值对(entrySet)
Entry:键值对对象

课堂练习:

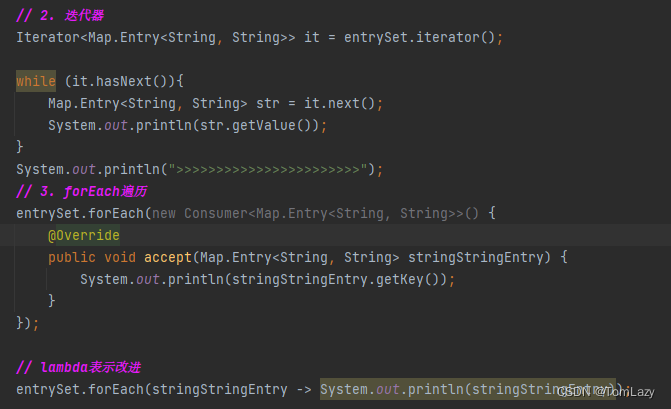
③、第三种遍历方式:Lambda表达式(forEach)

示例代码:

二、HashMap集合
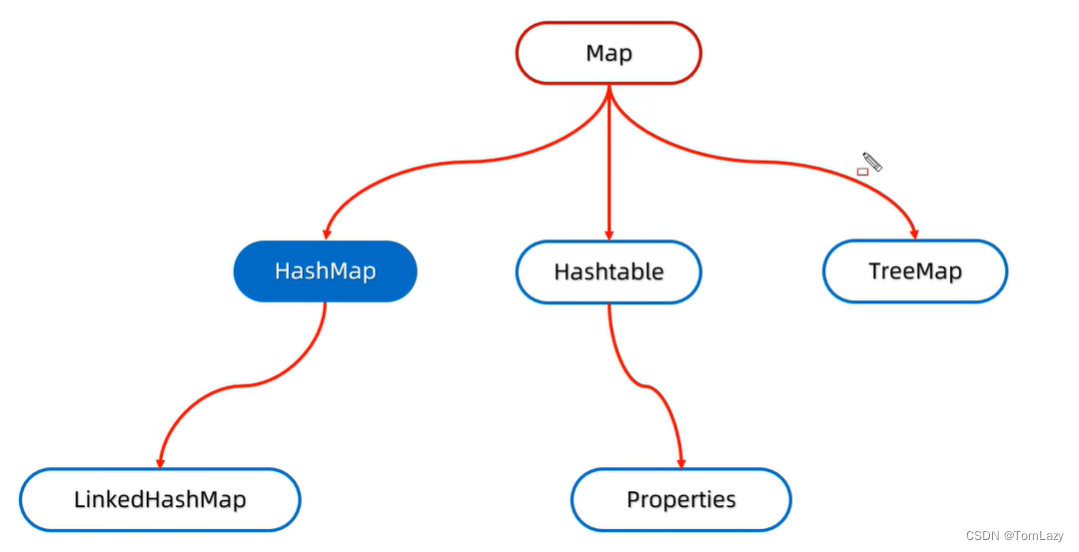
1、HashMap的特点

JDK8之后哈希表的结构是由数组、链表以及红黑树组成的.
2、HashMap的底层原理
- HashMap首先还是会创建一个默认长度为16,默认加载因子为0.75的数组;
- 然后再利用put方式,就可以添加数据了,put方法的底层会先创建一个Entry对象,Entry对象里面记录的就是要添加的键和值,然后利用键来计算哈希值,跟值无关,然后再计算出元素在数组中应存储的位置的索引,如果该位置为null,直接添加,如果该位置不为null,它会调用equals方法比较键的属性值,如果键的值相同,那么元素就会被覆盖;如果比较完后不一样,则会添加新的Entry对象;

- JDK8,如果计算出来的索引相同,且键不一致,那么就会直接挂在当前值的下面;
- 此外,当链表长度超过8,且数组长度大于等于64的时候,链表就会自动转成红黑树

3、小结

4、HashMap小练习
①、存储学生对象并遍历

示例代码:
在需要在JavaBean——Student.java中重写hashCode与equals方法

测试类:

②、Map集合案例-统计投票人数


示例代码:



求最大值:


3、4步没有办法合一块写,所以务必切记,我们一定要先求出max最大值,才能判断打印景点名
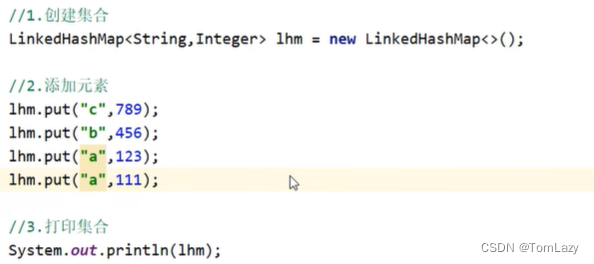
三、LinkedHashMap

示例代码:


四、TreeMap

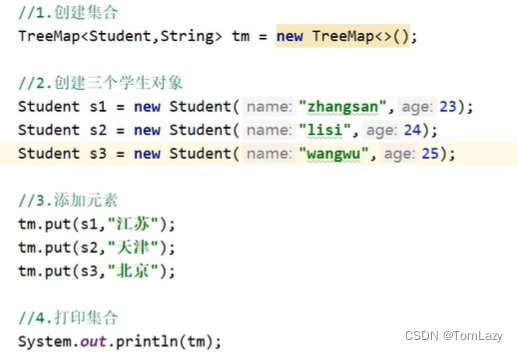
1、练习:TreeMap基本应用

示例代码:(Integer、Double 默认情况下都是按照升序排列的)
(String 按照字母在ASCII码表中对应的数字升序排列 abcdefg…)


按照id降序排序:

需求2:

JavaBean implements Comparable: 重写compareTo方法


2、练习:统计个数

示例代码:


遍历集合,并按照指定的格式进行拼接:
- StringBuilder
- StringJoiner

3、小结

五、源码解析
1、HashMap的底层原理(一)
①、源码中的类型介绍

⬆:表示该方式是父类或者接口中的方法,后面就标记了父类或接口的名称,我们可以理解为这个方法是重写的父类里面的方法;
➡:继承于Xxxx哪个类
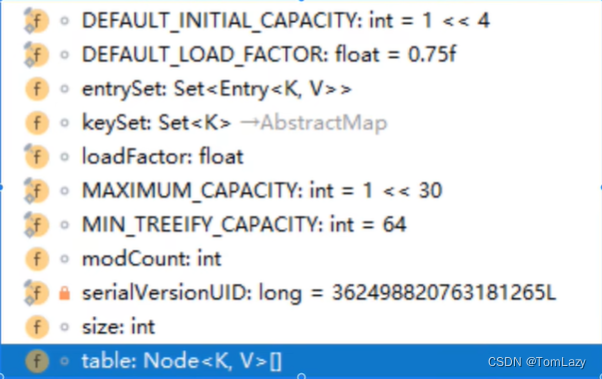
f:表示这是HashMap的属性

I:接口
C:类
②、HashMap中每一个元素是什么?
在HashMap中每一个元素其实都是一个Node对象:
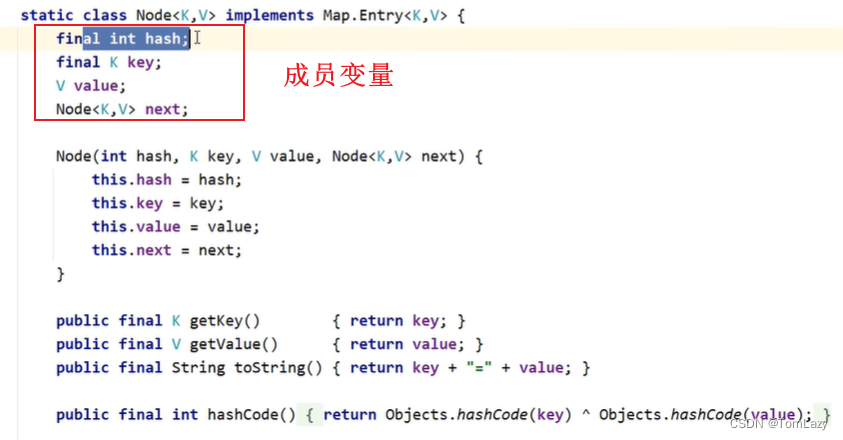
next:表示记录下一个节点的地址值
红黑树:红黑树中的节点为TreeNode

哈希表数组名为Table,默认长度为16

扩容因子:
![]()
最大容量:

2、HashMap的底层原理(二)
①、看源码前的准备工作


数组(table)中的键值对对象是分情况讨论的:
- 数组下面挂的是链表
- 数组下面挂的是红黑树
②、创建对象、第一种情况:添加元素(添加第一个元素,即数组位置为null)底层原理
刚开始用空参构造创建对象时,底层什么都没有,table也不存在,就是个null
当使用put方法,添加元素后,这个时候数组才存在

put方法:

putVal方法:



扩容机制:

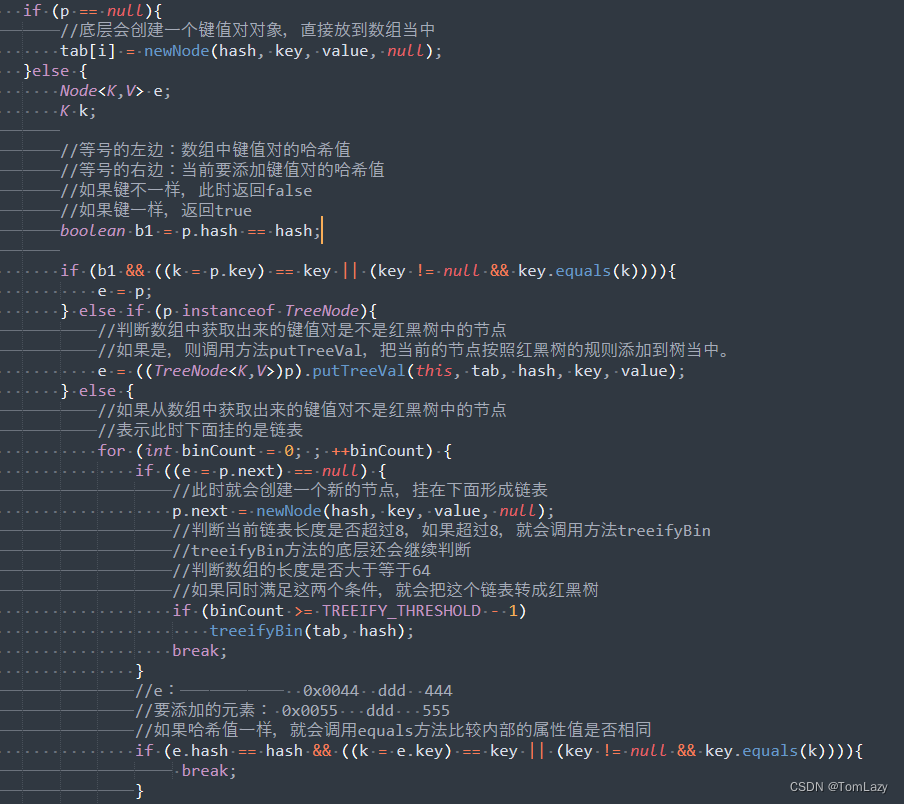
③、第二种情况:添加其它元素(数组位置不为null)底层原理
 ④、为什么hashcode值要与数组长度-1做一次“与”运算?【★】
④、为什么hashcode值要与数组长度-1做一次“与”运算?【★】
答:为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间。一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ (n - 1) & hash”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)”, 并且 采用二进制位操作 &,相对于%能够提高运算效率。
总结: a % b 操作等于 a & ( b - 1 ) (前提是b等于2的n次幂)
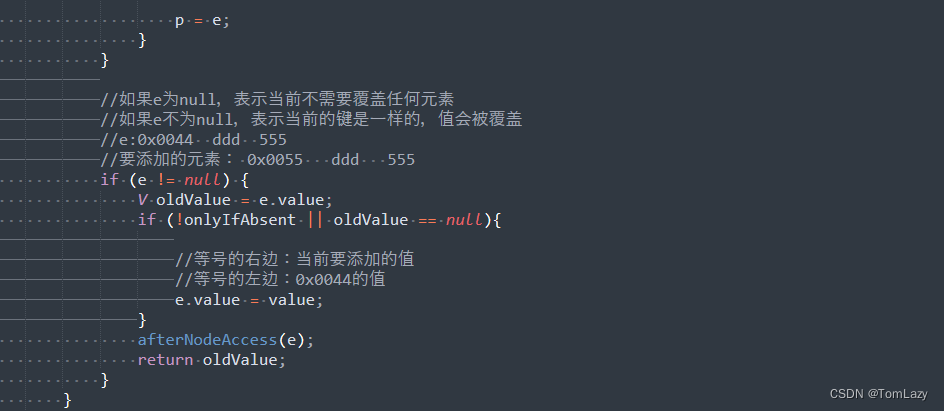
⑤、第三种情况:添加元素(数组位置不为null,键重复,元素覆盖)

其它步骤可见③

3、TreeMap中的底层源码(一)
TreeMap的底层为红黑树
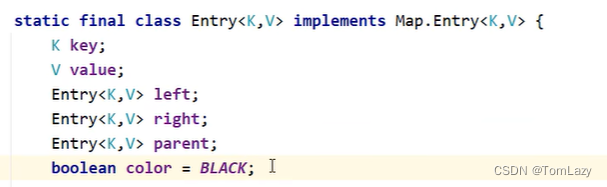
①、为什么这里的默认颜色为BLACK?
提高代码的阅读性,红黑树内部还存在调整过程,统一调整成红色。
②、TreeMap中每一个节点的内部属性

③、TreeMap类中的成员变量以及构造器

④、put:添加元素
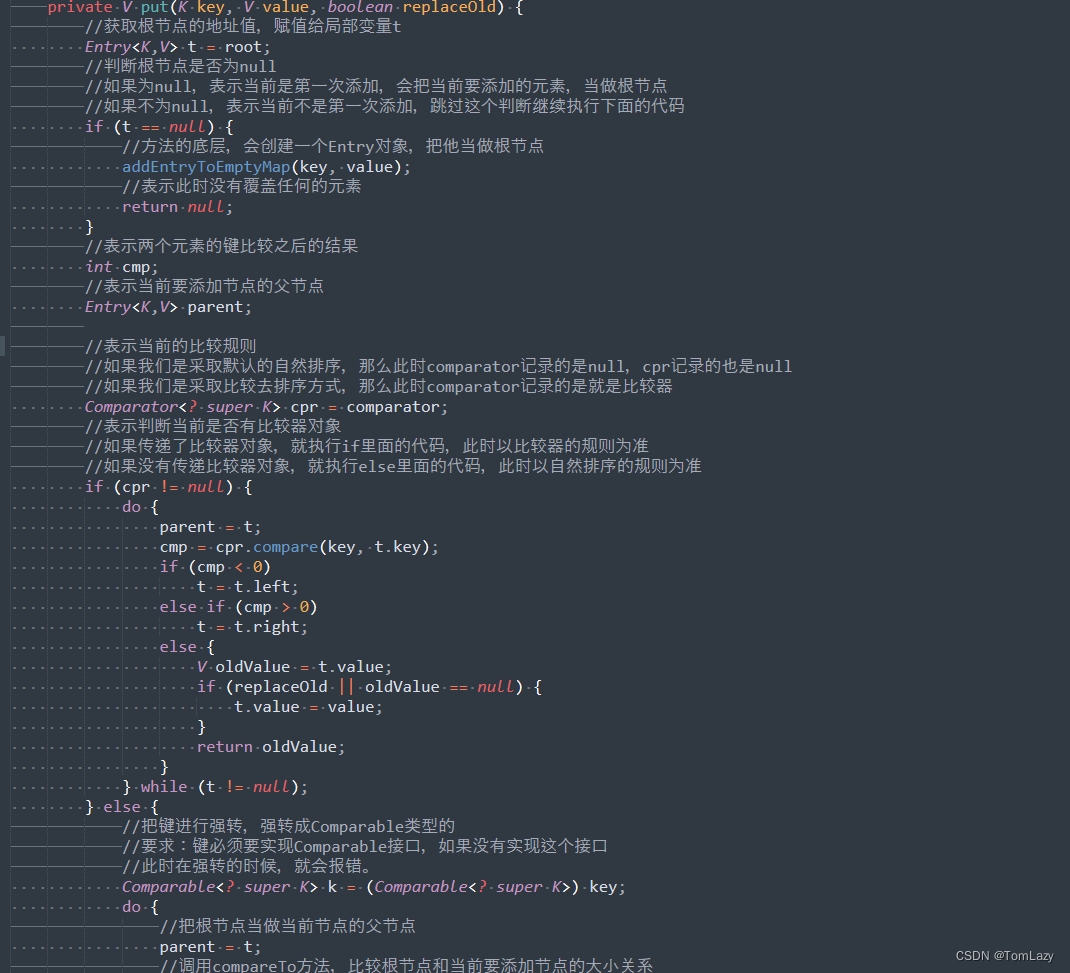

⑤、红黑树规则

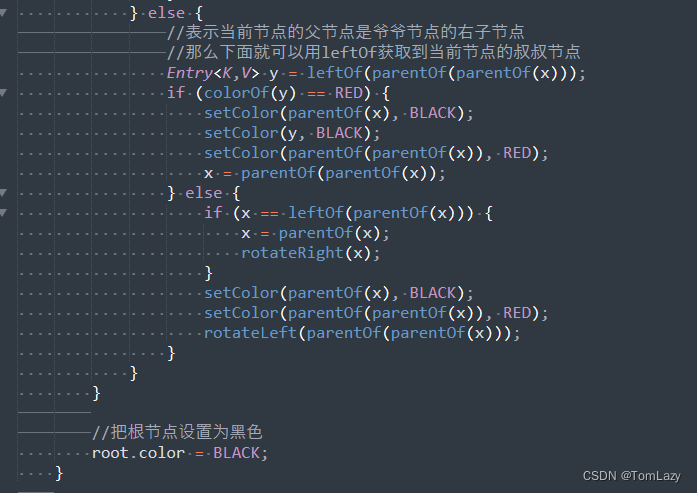
⑥、面试小问题
6.1 TreeMap添加元素的时候,键是否需要重写hashCode和equals方法?
此时是不需要重写的。hashCode和equals方法与HashMap的键有关!
6.2 HashMap是哈希表结构的,JDK8开始由数组,链表,红黑树组成的。
既然有红黑树,HashMap的键是否需要实现Compareable接口或者传递比较器对象呢?
不需要的。
因为在HashMap的底层,默认是利用哈希值的大小关系来创建红黑树的
6.3 TreeMap和HashMap谁的效率更高?
如果是最坏情况,添加了8个元素,这8个元素形成了链表,此时TreeMap的效率要更高
但是这种情况出现的几率非常的少。
一般而言,还是HashMap的效率要更高。
6.4 你觉得在Map集合中,java会提供一个如果键重复了,不会覆盖的put方法呢?
此时putIfAbsent本身不重要。
传递一个思想:
代码中的逻辑都有两面性,如果我们只知道了其中的A面,而且代码中还发现了有变量可以控制两面性的发生。
那么该逻辑一定会有B面。
习惯:
boolean类型的变量控制,一般只有AB两面,因为boolean只有两个值
int类型的变量控制,一般至少有三面,因为int可以取多个值。
6.5 三种双列集合,以后如何选择?
HashMap LinkedHashMap TreeMap
默认:HashMap(效率最高)
如果要保证存取有序:LinkedHashMap
如果要进行排序:TreeMap
六、可变参数
1、可变参数的练习

①、示例代码:(普通示例)

②、数组使用示例

③、JDK5-可变参数

④、可变参数的小细节

七、Collections

1、addAll() 批量添加元素

2、shuffle() 打乱List集合元素的顺序

3、其它方法

八、综合练习
1、自动点名器
①、自动点名器1(shuffle)

示例代码:


②、自动点名器2(概率 — 随机面)

示例代码:


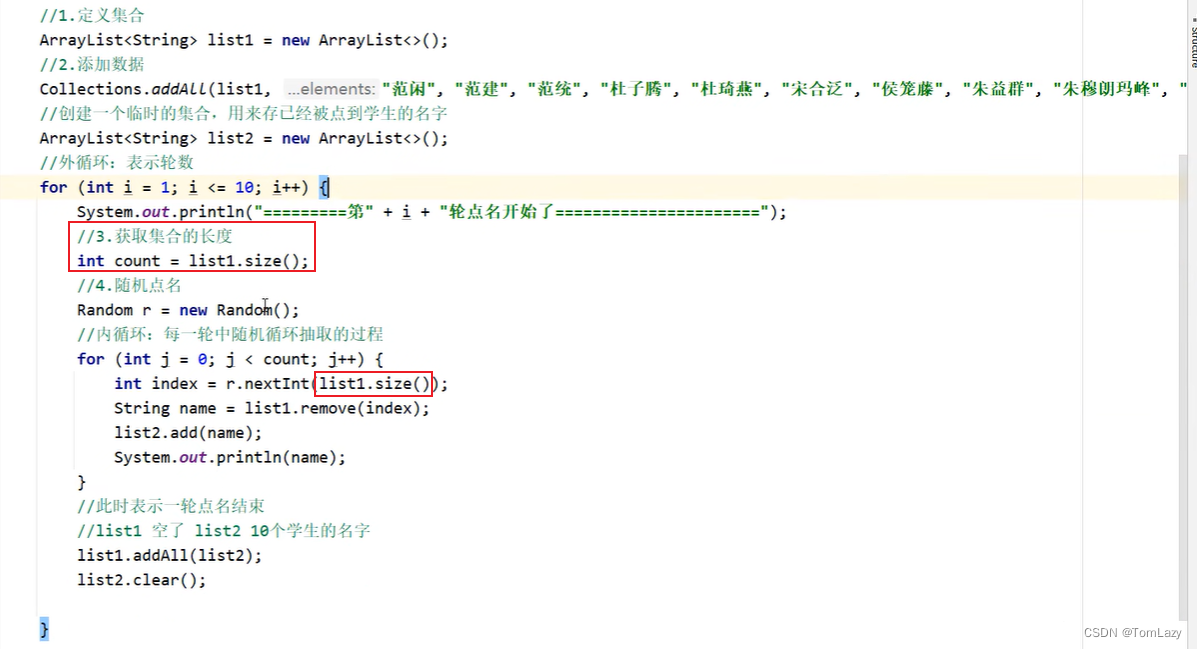
③、自动点名器3(不重复且会循环点名 — 辅助列表)

示例代码:(点过的就删掉)
④、自动点名器4(权重)
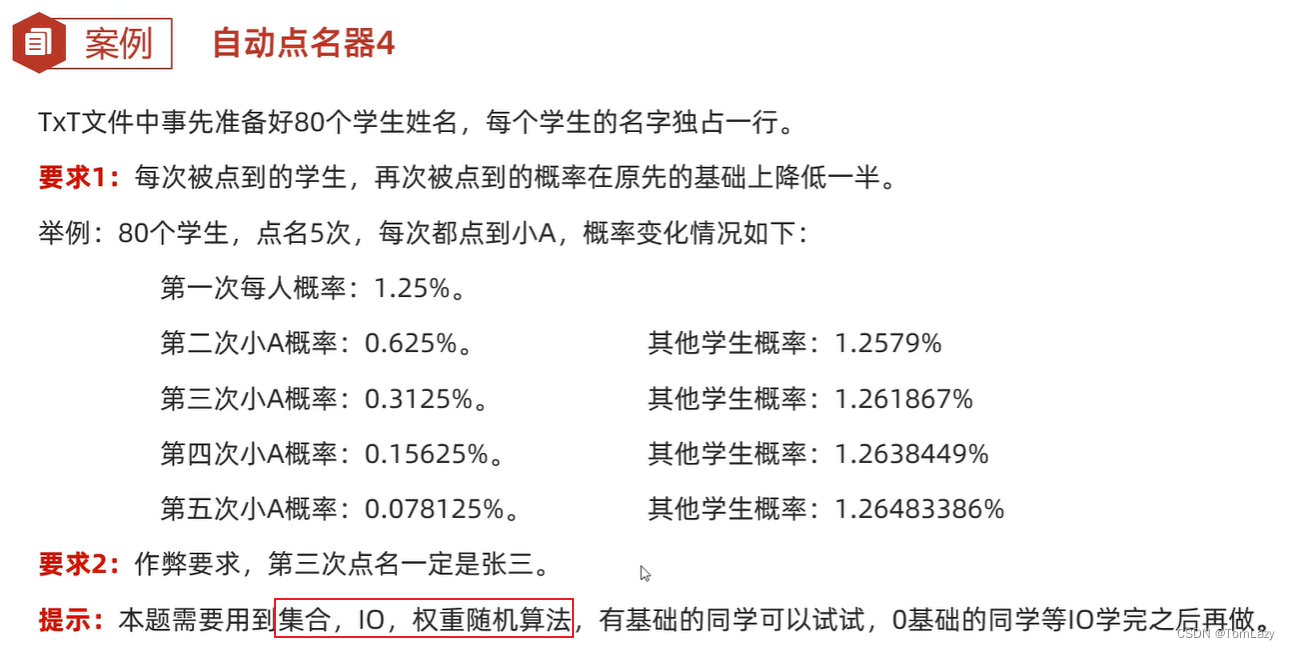
前情提要:带权重的微服务技术

示例代码:(未完待续)
⑤、自动点名器5 —— (GUI界面程序 — 集合、IO、多线程、带权重的随机)

示例代码:(未完待续)
2、Map集合案例——省和市

示例代码: