论文题目: Language Models are Few-Shot Learner
论文地址: https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html
论文发表于: NIPS 2020
论文所属单位: OpenAI
论文大体内容
本文主要提出了GPT-3(Generative Pre-Training)模型,通过大模型pre-train进行In-context Learning,并在Zero-shot Learning、One-shot Learning和Few-shot Learning上进行实验,在NLU任务上有不错的表现,但也就只有较少的task上能比得上Fine-tune的SOTA。
Motivation
本文作者继续他们对于通用大模型GPT的愿景,增加训练数据,并把模型继续做大,然后实验观察在Zero-shot Learning、One-shot Learning和Few-shot Learning上的效果。
Contribution
①训练更通用的pre-train模型进行In-context Learning;
②在Zero-shot Learning、One-shot Learning和Few-shot Learning中有不错的表现;
1. GPT-3使用的方法跟GPT-2[1]基本一样,主要的区别是扩大了模型参数量(15亿 -> 1750亿个参数),训练数据集大小(40GB -> 570GB);
2. 本文使用In-context Learning的方式来实验Zero-shot Learning、One-shot Learning和Few-shot Learning;
①Fine-tuning: 对大的预训练模型进行Fine-tune是不容易的,所以就有了Prompt Learning和In-context Learning;
②Few-shot: 先给定K个example(K∈[10, 100]),再让模型预测。Few-shot Learning的优点是只需要提供很少的与目标任务相关的训练样本,而缺点是效果比Fine-tune的差;
③One-shot: 只给1个example;
④Zero-shot: 没有example;
3. GPT-3针对所有的task没有进行梯度更新或者Fine-tune,所以本文的实验更多是展示GPT的泛化能力和通用性;
实验
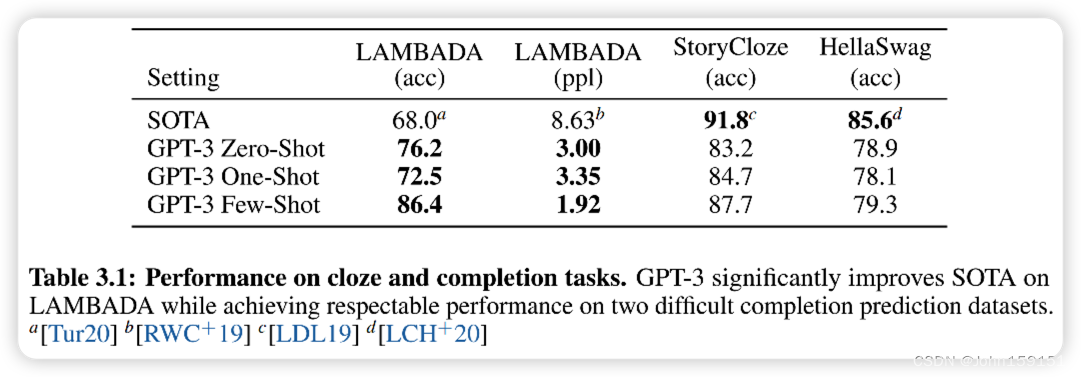
4. Language Modeling, Cloze, and Completion Tasks
5. Question Answering

6. Translation
训练数据集中93%都是英文。

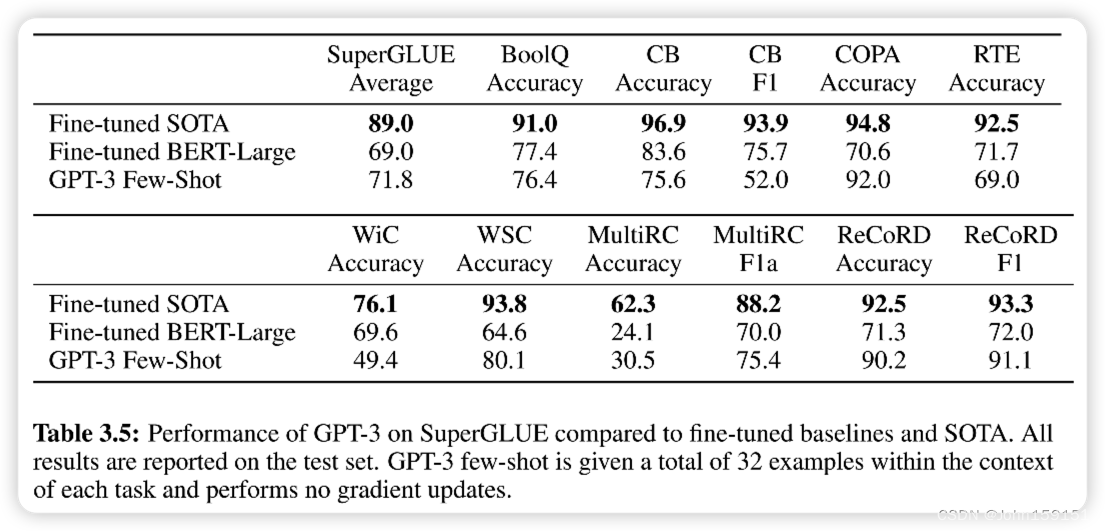
7. SuperGLUE
参考资料
[1] GPT-2 https://blog.csdn.net/John159151/article/details/129098787
[2] GPT-1 https://blog.csdn.net/John159151/article/details/129062724
[3] GPT-3 Github https://github.com/openai/gpt-3
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!
![[Golang实战]github.io部署个人博客hugo[新手开箱可用][小白教程]](https://img-blog.csdnimg.cn/b9565c6a03bb4c61b62ffe1889591aa5.png)