第九章 Catalyst 优化器
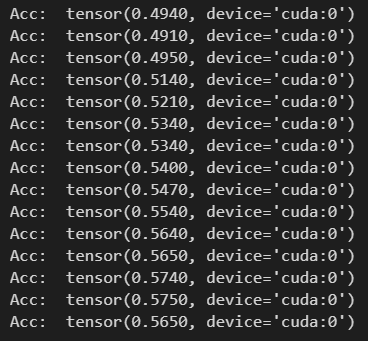
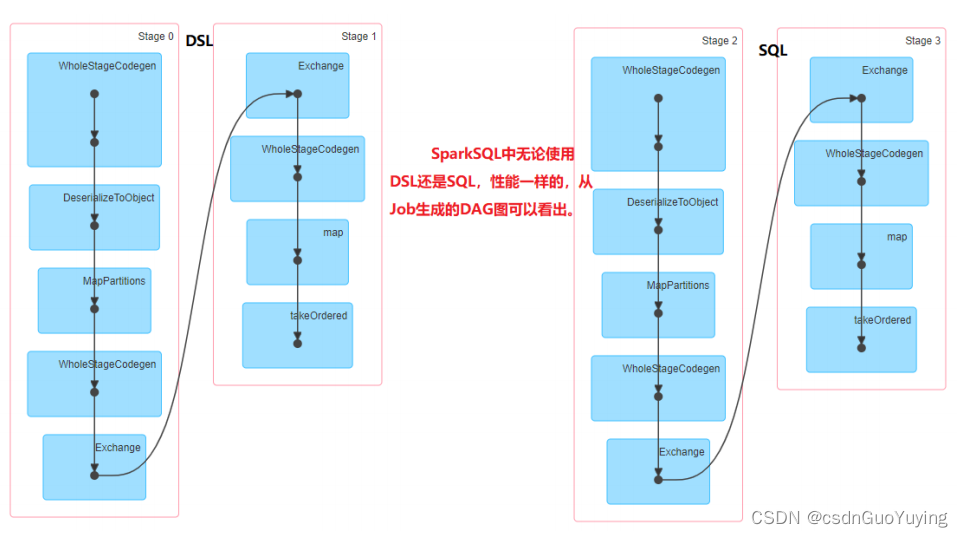
在第四章【案例:电影评分数据分析】中,运行应用程序代码,通过WEB UI界面监控可以看出,无论使用DSL还是SQL,构建Job的DAG图一样的,性能是一样的,原因在于SparkSQL中引擎:Catalyst:将SQL和DSL转换为相同逻辑计划。
Spark SQL是Spark最新,技术最复杂的组件之一。它为SQL查询和新的DataFrame API提供支持。Spark SQL的核心是Catalyst优化器,它以一种新颖的方式利用高级编程语言功能(例如Scala的模式匹配和quasiquotes)来构建可扩展的查询优化器。
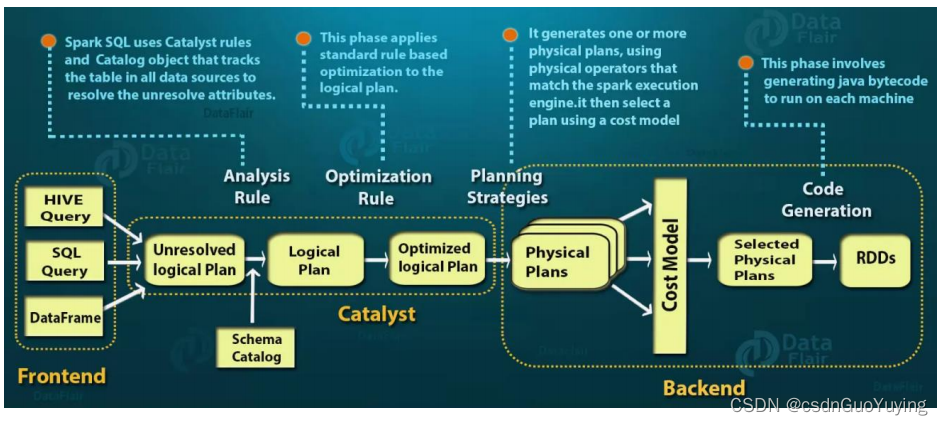
SparkSQL的Catalyst优化器是整个SparkSQL pipeline的中间核心部分,其执行策略主要两方向:
- 基于规则优化/Rule Based Optimizer/RBO;
- 基于代价优化/Cost Based Optimizer/CBO;
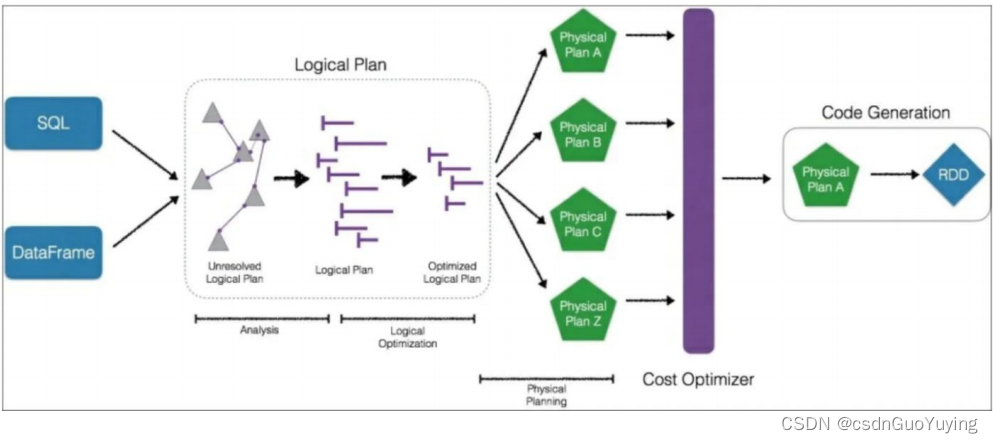
从上图可见,无论是直接使用SQL语句还是使用 ataFrame,都会经过一些列步骤转换成DAG对RDD的操作。
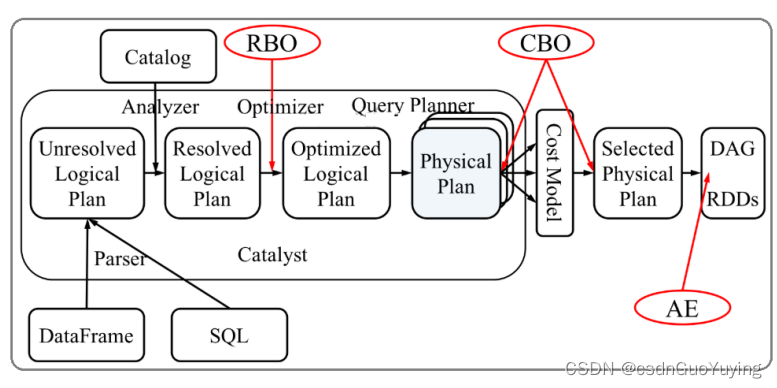
Catalyst工作流程:SQL语句首先通过Parser模块被解析为语法树,此棵树称为Unresolved Logical Plan;Unresolved Logical Plan通过Analyzer模块借助于数据元数据解析为Logical Plan;此时再通过各种基于规则的Optimizer进行深入优化,得到Optimized Logical Plan;优化后的逻辑执行计划依然是逻辑的,需要将逻辑计划转化为Physical Plan

核心三个点:
- 第一点、Parser,第三方类库ANTLR实现。将sql字符串切分成Token,根据语义规则解析成一颗AST语法树;
- 第二点、Analyzer,Unresolved Logical Plan,进行数据类型绑定和函数绑定;
- 第三点、Optimizer,规则优化就是模式匹配满足特定规则的节点等价转换为另一颗语法树;
附录:Maven 依赖
在Maven Project中创建Maven Model,依赖pom.xml添加如下依赖:
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>