点击蓝字 关注我们

作者 | 鲍亮,Apache DolphinScheduler PMC Member
01
Workflow是什么?
对于数仓场景和数据湖场景来说,最显著的特点就是数据处理的长流程和高复杂度任务依赖关系,从源数据采集到最终报表数据的生成,中间可能经历上百个任务的处理,这些任务如果是散乱的,无明确的流程组织起来,中间某一个步骤出问题,就很难发现其影响范围,更加难以判定对其他依赖的任务的影响程度。
任务需要被有效地组织并流程化处理。这就需要Workflow 。DolphinScheduler 中 Workflow 通过 DAG(有向无环图)的方式操作。DAG 是由多个顶点(tasks)和其他顶点的之间关系(Relationships)构成,图形化的 Workflow 可以很直观地看到任务之间的关系,任意任务之间不能形成环。使用 Workflow 管理任务可以让数据处理流程更有层次,加上任务血缘展示,可以让整个数据处理流程更可视化和清晰明了。
本文就主要探讨如何在 ApacheDolphinScheduler 上更好地玩转 Workflow, 以帮助大家更好地管理数据处理任务。
02
创建工作流
根据需求,在 ApacheDolphinScheduler上,可以通过页面拖拽、Python脚本、yaml定义、OpenAPI调用多种方式创建工作流。这一点相对 Apache Airflow 来说,要更容易上手一些,比较适合平台使用者为多个部门的人员,比如分析师、数据科学家等,毕竟所见即所得比起调试 Python 代码要来得更简单直接一些。
我们以最简单的页面拖拽为例,假如有一个最简单的场景,从一个文件获取日志数据get-logs,然后分别经过处理日志1 read-file1 和日志2 read-file2, 每个文件经过统计,输出到不同的数据表output1, output2,如果两个文件都读取成功,要汇聚总表 output-summary.
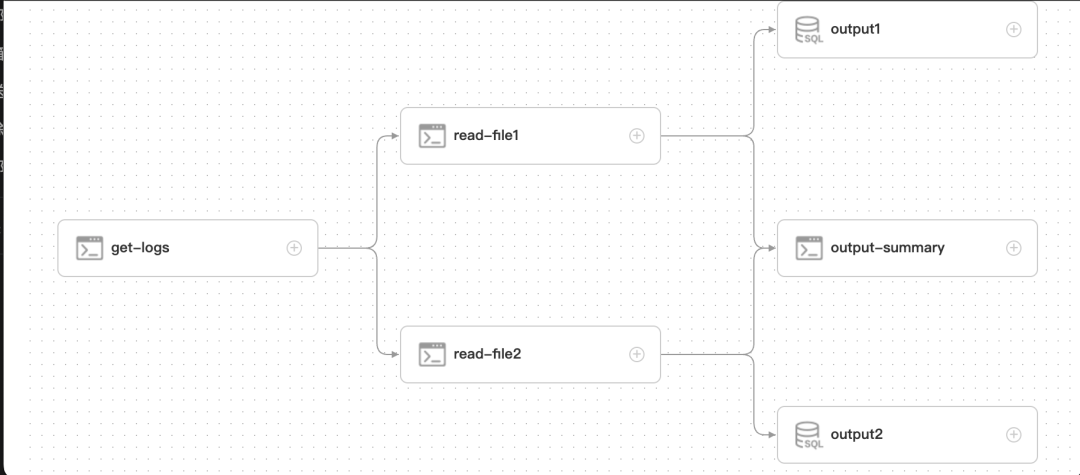
一般来说一个工作流不要超过30个任务,如果超过30个,建议将同类的任务使用子工作流汇总,比如get-logs这个流程可能需要有多个步骤(校验、清洗、分拆等),可以替换成子工作流来处理“准备日志文件”这个步骤,这样整个流程就会比较清晰。
当然实际的业务场景中,任务数量会更多,关系也会更复杂。例如:
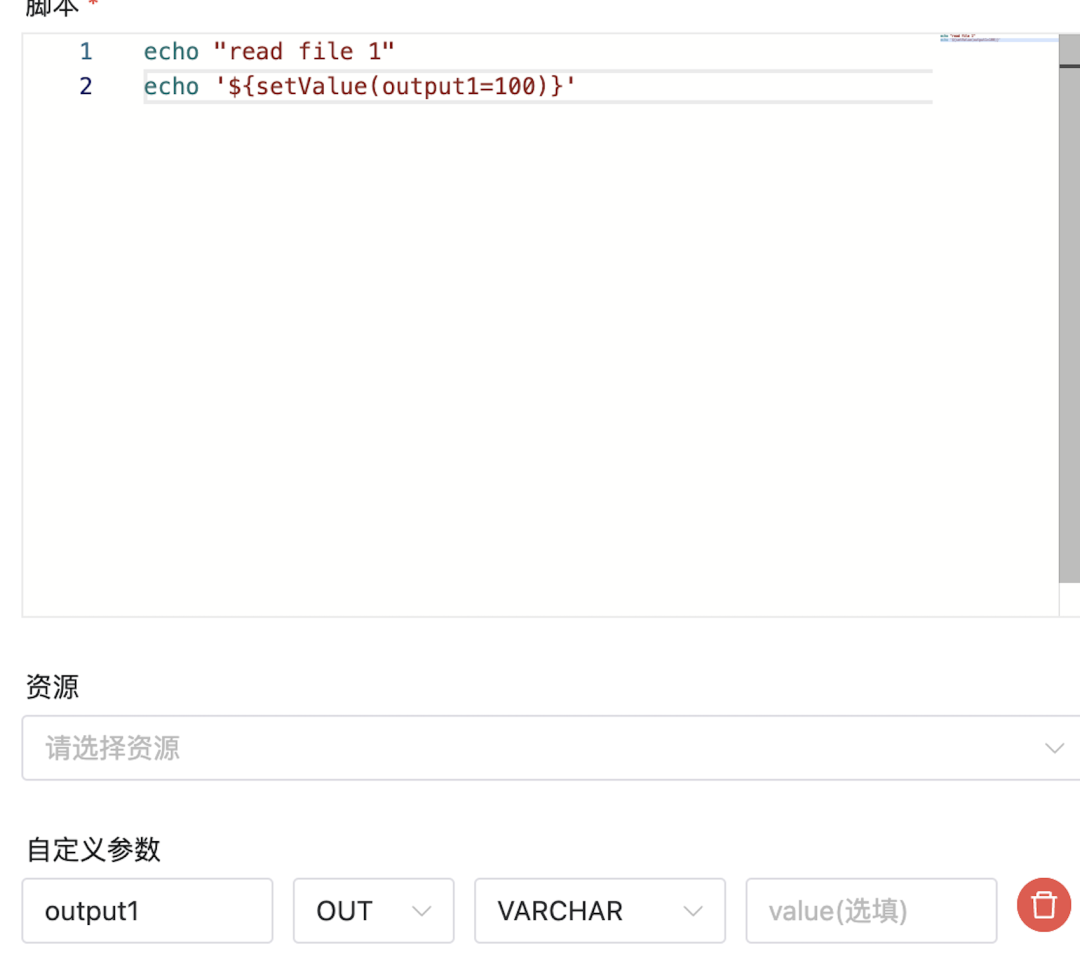
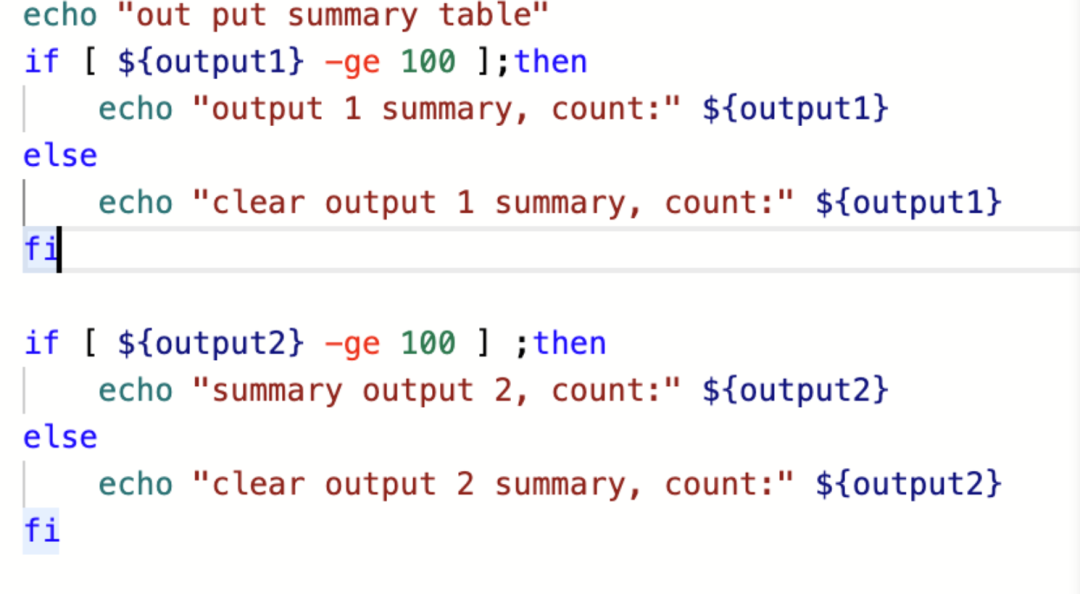
需要参数传递,读到的文件长度需要传递给下游output任务做校验,使用任务参数传递功能,可以很方便地构建任务之间的关系。例如在output-summary中可以通过判断read-file1和read-file2的读取结果进行输出:
read-file1:
read-file2:

output-summary:
需要限制任务使用资源,有些任务对资源的使用太大,限制任务的执行资源,可以使用任务并发组功能,确保系统在任务量大的时候,保证集群正常提供服务。同时在任务并发组内还可以设置任务的优先级,在同一个组内,如果任务量超过了并发组的容量,系统会根据任务的优先级进行排队执行。
我们经常遇到在任务执行的时候,由于网络或者环境的不稳定因素导致任务执行失败,那么就可以使用任务重试机制来让系统自动重试执行,在DolphinScheduler里,你可以设置任务失败重试的次数,并且还可以设置每次重试之间的间隔时间。
当然如果我们对任务的执行时间有要求的话,可以使用超时设置,设定如果任务执行时长超过N分钟,就可以让系统发出警告或者直接让任务失败,进入重试阶段。
我们执行任务的时候,经常也需要将不同任务使用不同的用户来执行。就可以在保存工作流的时候,指定工作流使用的租户,来达到使用多租户的目的。
企业的不同部门都要使用同一个平台的话,可以使用worker分组将不同部门的服务拆分,每个部门的服务环境相互隔离,互不影响。
03
运行工作流
在DolphinScheduler的设计中,每次运行工作流,都会生成一条当前工作流的实例,并且这个实例和工作流定义是分离的,也就是说如果实例运行失败,我们针对实例的修改,不会影响到工作流定义的内容。不过在产品设计上,提供了修改实例可以同步到工作流定义的功能,让用户更加方便地修改工作流。
系统支持多种运行模式:
正常运行:直接在页面,点击运行按钮,立刻执行一次当前工作流。在工作流实例里面可以立马查询到当前运行的实例。
运行部分任务:有一部分场景是我们在线下把一部分的任务数据准备好了,只需要运行某一部分任务即可。就可以在工作流的DAG页面通过右键点击某个任务运行,就可以通过选项:“仅运行选中任务”、“向后运行”、“向前运行” 来实现只运行DAG内的一部分任务的目的。
补数运行:在日常的工作中,我们经常遇到重刷数据的场景:
当天任务执行成功,但是校验数据的时候,发现上游数据错误,需要重刷数据。
每月进行数据比对的时候,发现某些天的数据有误差,需要重刷数据
补数运行,就是在运行的时候,设置补数模式,处于补数模式时,用户在任务里使用的时间,会变成补数的时间。补数有两种选择:
系统可以智能根据定时选择时间,比如我们定时了每天早上5点执行工作流,补数的时候可以选择一个是时间范围2022-12-01到2022-12-05,系统自动根据定时时间计算出补数的时间列表为:
2022-12-01T05:00:00
2022-12-02T05:00:00
2022-12-03T05:00:00
2022-12-04T05:00:00
2022-12-05T05:00:00
另外还可以通过手动输入补数时间列表,以解决需要补数不规则的时间列表。比如我们想补数2022-12-01,2022-12-04, 2022-12-05这三个日期的工作流,就可以使用日期列表补数实现。
运行完工作流以后,我们可以通过实例的DAG页面查看当前实例内任务的运行状况。并且通过右键某个任务实例,在页面上直接查看任务的运行日志,而不用去登录到服务器,或者其他系统中查找任务日志了。
如果工作流执行失败,我们可以对实例内失败的任务进行修改,然后再恢复运行,即可达到工作流断点执行的目的。
工作流实例也支持多种操作:暂停、停止、恢复执行、重跑、查看甘特图等。
04
总结
以上是DolphinScheduler的工作流的一些用法,当然还有更多工作流使用的细节,限于篇幅,我们下次再详细讨论。但是通过以上的内容,我们可以知道使用DolphinScheduler的工作流:
可以专注于业务逻辑,不需要再关注系统复杂的运行机制了
可以有效组织任务列表,很直观地看到任务的整个图谱,以及每个任务的影响范围
支持页面可视化以及多种使用方式,适合不同类型的人员使用,降低企业的平台复杂度,降本增效
所有配置可视化,降低用户的学习成本
强大的调度能力,可以解决更多复杂的业务场景,比如:企业级分组、任务的判断/分支逻辑、多租户等需求。
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
< 🐬🐬 >
更多精彩推荐
☞干货教程 | DolphinScheduler 中的函数使用与扩展
☞优秀用户案例有奖征集 | 活动火热开启,快来投稿!
☞BIGO 如何做到夜间同时运行 2.4K 个工作流实例?
☞最新性能测试 | Apache DolphinScheduler 每分钟调度任务并发是 Apache Airflow 2 倍
☞名额已排到10月 | Apache DolphinScheduler Meetup分享嘉宾继续火热招募中
☞「2022 中国开源年度报告」OpenRank DolphinScheduler 名列前茅
☞分布式可视化作业调度平台 DolphinScheduler MasterServer 设计核心要点揭秘
我知道你在看哟