实验一:主线程与子线程
pthread_create函数:
1、简介:pthread_create是UNIX环境创建线程的函数
2、头文件:#include <pthread.h>
3、函数声明:
int pthread_create(pthread_t* restrict tidp , const pthread_attr_t* restrict_attr , void* (start_rtn)(void) , void *restrict arg );
4、输入参数:(以下做简介,具体参见实例一目了然)
(1)tidp:事先创建好的pthread_t类型的参数。成功时tidp指向的内存单元被设置为新创建线程的线程ID。
(2)attr:用于定制各种不同的线程属性。APUE的12.3节讨论了线程属性。通常直接设为NULL。
(3)start_rtn:新创建线程从此函数开始运行。无参数是arg设为NULL即可,线程的执行工作函数。
(4)arg:start_rtn函数的参数。无参数时设为NULL即可。有参数时输入参数的地址。当多于一个参数时应当使用结构体传入。
5、返回值:成功返回0,否则返回错误码。
6、说明。
传递参数的时候传地址: pthread_create(&ntid, NULL, thr_fn, ¶m1);
线程函数的第一句通常是获取传入参数:Param tmp = *(Param *)arg;
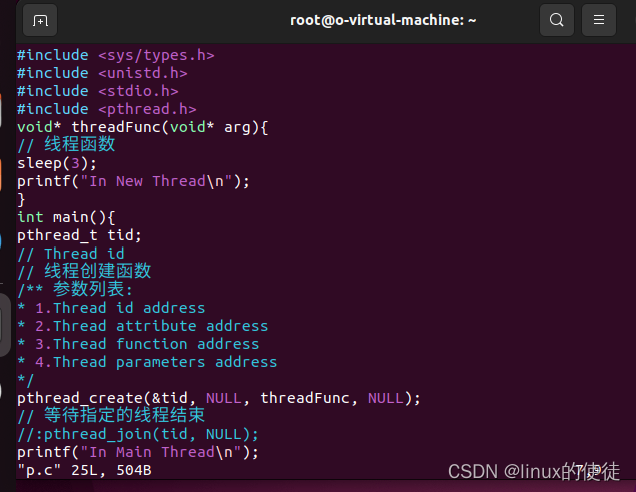
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
void* threadFunc(void* arg){
// 线程函数
printf("In New Thread\n");
}
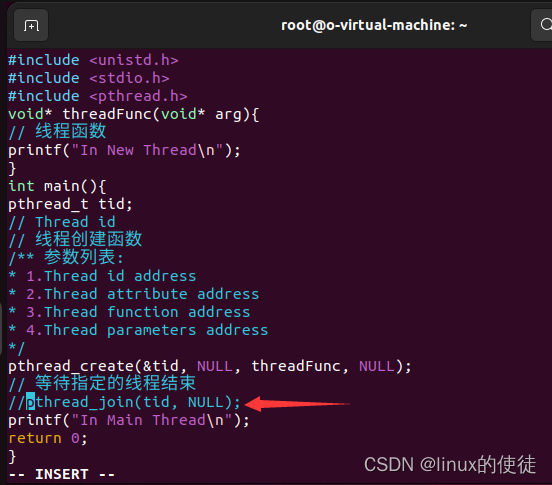
int main(){
pthread_t tid;
// Thread id
// 线程创建函数
/** 参数列表:
pthread_create(存pid的地址, 线程的一些属性, 线程执行函数, 传入线程执行函数的参数);
*/
pthread_create(&tid, NULL, threadFunc, NULL);
// 等待tid的值对应的线程号对应的线程结束,再向下执行
pthread_join(tid, NULL);
printf("In Main Thread\n");
return 0;
}
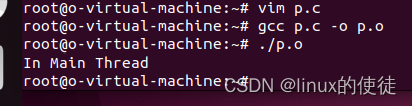
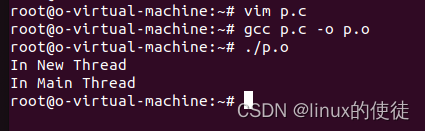 执行完成以后,会看到我们创建了子线程New Thread
执行完成以后,会看到我们创建了子线程New Thread
我们注释掉等待函数
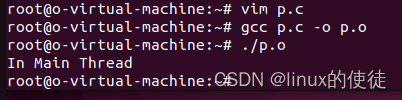 为什么会出现上面的情况,我们再做个演示
为什么会出现上面的情况,我们再做个演示
新线程函数内加个sleep函数
根据前面进程并发的特点,我们可以分析出,主线程不等待子线程调用执行且父线程执行调用资源很少,那么父进程就会在子进程还没执行时结束(return一个status结束执行流),这样子线程就变成一个孤儿线程了。孤儿线程不像孤儿进程,它时无法再父线程执行玩后执行的,因为主线程结束,代表此进程结束了,线程是无法依赖于一个没执行的进程的。
实验二:多线程
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
#include <time.h>
#include <stdlib.h>
void* hello(void* args){
for (int i = 0; i < 3; i++){
printf("hello(%d)\n", rand()%100);
sleep(1);
}
}
void* world(void* args){
for (int i = 0; i < 3; i++){
printf("world(%d)\n", rand()%100);
sleep(2);
}
}
int main(){
srand(time(NULL));
pthread_t tid,tid2;
// 线程创建函数
pthread_create(&tid, NULL, hello, NULL);
pthread_create(&tid2, NULL, world, NULL);
// 等待指定的线程结束
printf("In Main Thread\n");
pthread_join(tid, NULL);
pthread_join(tid2, NULL);
return 0;
}
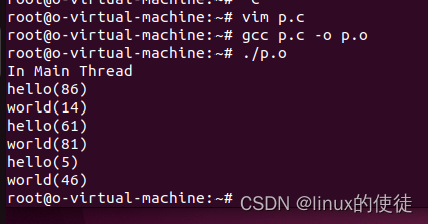 这里看不出真正的执行状态,并发并不是你执行一下我执行一下,而是cpu自动分配的执行时间。
这里看不出真正的执行状态,并发并不是你执行一下我执行一下,而是cpu自动分配的执行时间。
执行时间调长(执行流调用资源变多)
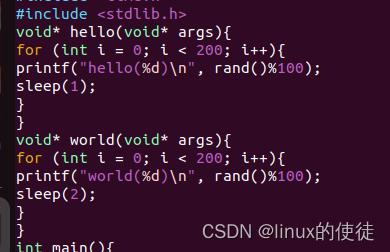
可以看出子线程调用资源变多,主进程和子进程的执行时间都变随机了(cpu调度)
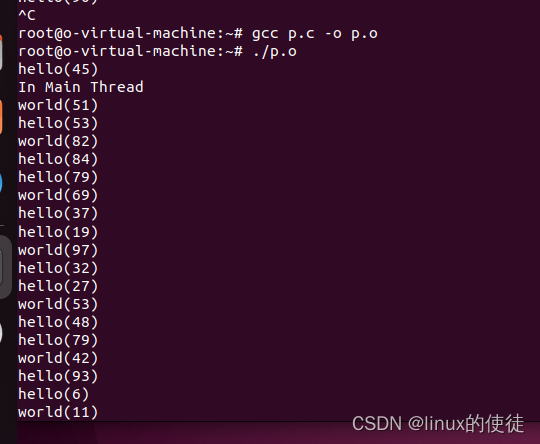 现在我们知道了如何些多进程执行流函数,前面我们提到每个进程共享堆、文件资源、代码。
现在我们知道了如何些多进程执行流函数,前面我们提到每个进程共享堆、文件资源、代码。
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
#include <time.h>
#include <stdlib.h>
void* hello(void* args){
int a = 10;
for (int i = 0; i < 3; i++){
printf("hello(%d)\n", a++);
sleep(1);
}
}
void* world(void* args){
int a = 1;
for (int i = 0; i < 3; i++){
printf("world(%d)\n", a++);
sleep(2);
}
}
int main(){
//srand(time(NULL));
pthread_t tid,tid2;
// 线程创建函数
pthread_create(&tid, NULL, hello, NULL);
pthread_create(&tid2, NULL, world, NULL);
// 等待指定的线程结束
printf("In Main Thread\n");
pthread_join(tid, NULL);
pthread_join(tid2, NULL);
return 0;
}
可以看出这里每个进程内stack是共享的。
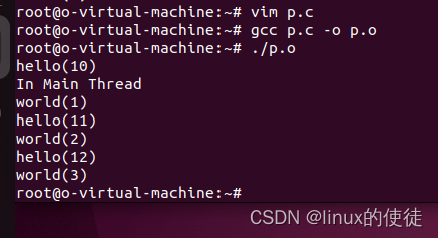
接着我们创建一个全局变量,我们观察一下两个线程是否可以操作同一份全局变量
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
#include <time.h>
#include <stdlib.h>
int value = 100;
void* hello(void* args){
for (int i = 0; i < 3; i++){
printf("hello(%d)\n", value++);
sleep(1);
}
}
void* world(void* args){
for (int i = 0; i < 3; i++){
printf("world(%d)\n", value++);
sleep(2);
}
}
int main(){
srand(time(NULL));
pthread_t tid,tid2;
// 线程创建函数
pthread_create(&tid, NULL, hello, NULL);
pthread_create(&tid2, NULL, world, NULL);
// 等待指定的线程结束
printf("In Main Thread\n");
pthread_join(tid, NULL);
pthread_join(tid2, NULL);
return 0;
}

实验三:计算圆
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
#include <time.h>
#include <stdlib.h>
void calculate_pi(int intervals){
unsigned int seed = time(NULL);
int circle_points = 0;
int square_points = 0;
for (int i = 0; i < intervals * intervals; ++i)
{
double rand_x = (double)rand_r(&seed)/RAND_MAX;
double rand_y = (double)rand_r(&seed)/RAND_MAX;
if ((rand_x * rand_x) + (rand_y * rand_y) <= 1){
circle_points++;
}
square_points++;
}
double pi = (double)(4.0*circle_points)/square_points;
printf("The estimated PI is %lf in %d times\n", pi, intervals * intervals);
}
int main(){
clock_t start,deleta;
double time_used;
double pi;
start = clock();
#pragma omp parallel for num_threads(10)
for (int i = 0; i < 10; i++){
calculate_pi(1000*(i+1));
}
//执行时间等于结束减去开始
deleta = clock() - start;
printf("The time taken in total: %lf seconds\n", (double)deleta/CLOCKS_PER_SEC);
return 0;
}
此代码并没有用到多线程
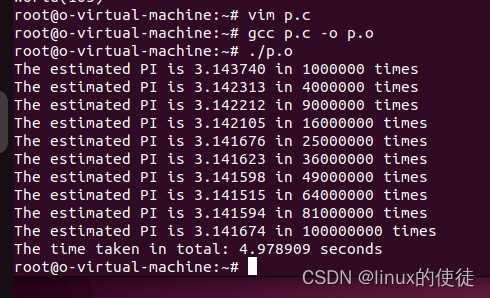
我们用time来看下准确的时间把
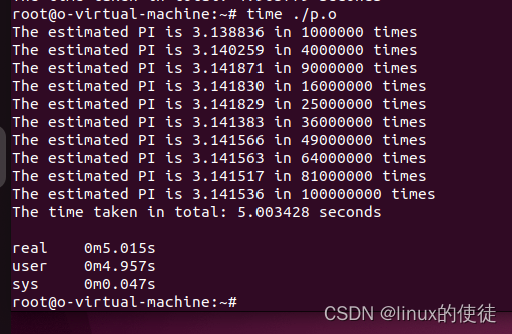 接下来我们来看一下开启多线程花费的时间
接下来我们来看一下开启多线程花费的时间
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <pthread.h>
#include <time.h>
#include <stdlib.h>
void* calculate_pi(void* args){
unsigned int seed = time(NULL);
int circle_points = 0;
int square_points = 0;
int intervals = *((int*)args);
for (int i = 0; i < intervals * intervals; ++i)
{
double rand_x = (double)rand_r(&seed)/RAND_MAX;
double rand_y = (double)rand_r(&seed)/RAND_MAX;
if ((rand_x * rand_x) + (rand_y * rand_y) <= 1){
circle_points++;
}
square_points++;
}
double pi = (double)(4.0*circle_points)/square_points;
printf("The estimated PI is %lf in %d times\n", pi, intervals * intervals);
pthread_exit(0);
}
int main(){
clock_t start,deleta;
double time_used;
start = clock();
pthread_t calculate_pi_threads[10];
int args[10];
for (int i = 0; i < 10; ++i){
args[i] = 1000*(i+1);
pthread_create(calculate_pi_threads+i,NULL,calculate_pi,args+i);
}
for (int i = 0; i < 10; ++i){
pthread_join(calculate_pi_threads[i],NULL);
}
deleta = clock() - start;
printf("The time taken in total: %lf seconds\n", (double)deleta/CLOCKS_PER_SEC);
return 0;
}
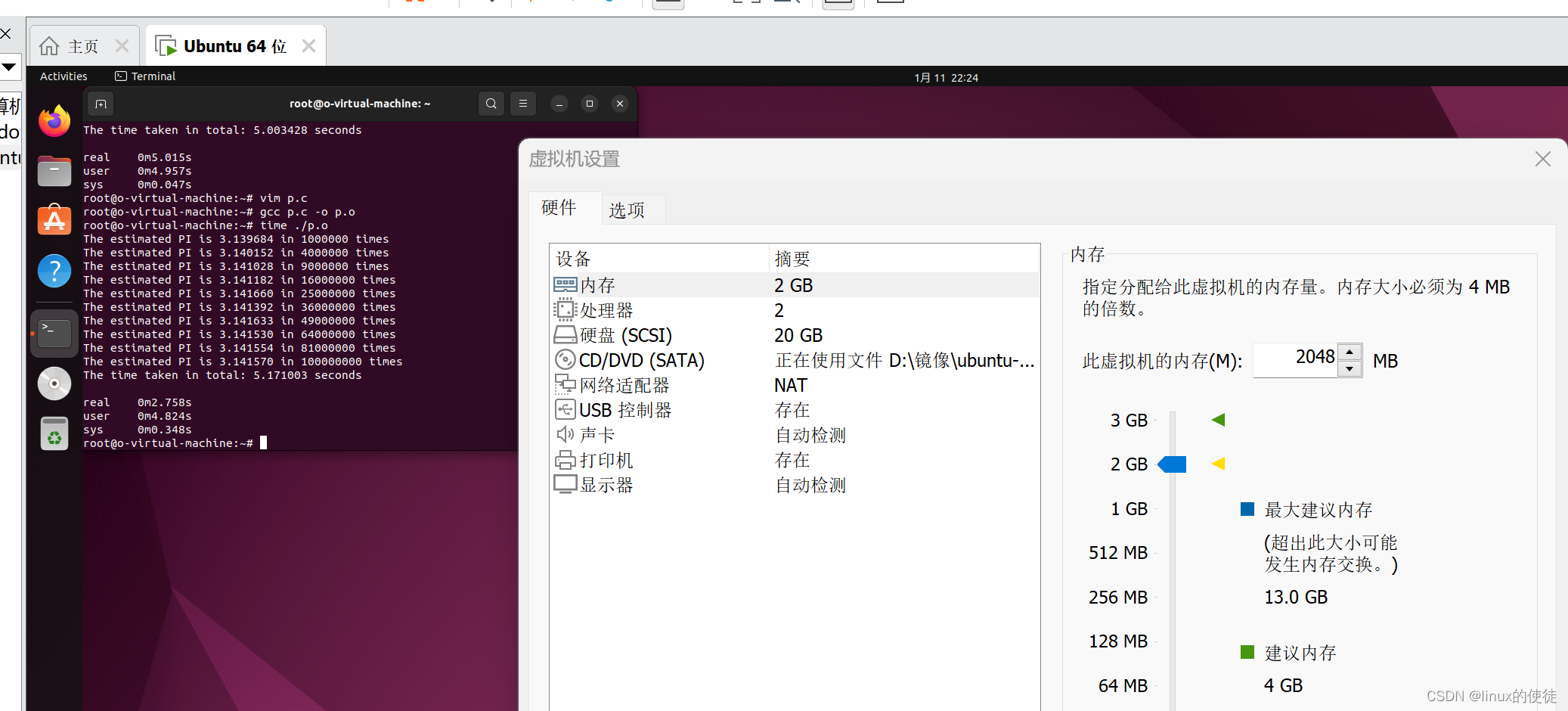
可以看出确实减少了真实的执行时间
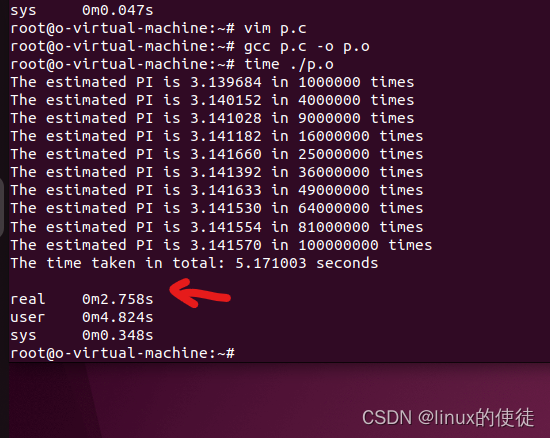 但是我们也可以看到sys(系统执行此函数时间)比单线程短,这是因为我的虚拟机的cpu是多核的,所以线程切换时间并不长。如果是单核那么多线程反而会比单线程执行时间长
但是我们也可以看到sys(系统执行此函数时间)比单线程短,这是因为我的虚拟机的cpu是多核的,所以线程切换时间并不长。如果是单核那么多线程反而会比单线程执行时间长
大家可以自己改一下