本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure Data Factory】系列。
前言
在开发好一个ADF pipeline(功能)之后,需要将其按需要运行起来,这个称之为调度。下图是一个简单的ADF 运作图, 按照需要的顺序,由某个程序或者人,调度Data Factory Service里面的pipelines。这些pipelines是在Data Factory Service中定义和存储的。然后通过pipeline中具体的活动(Activity,比如copy)访问Linked Services, 然后从Source中获取数据,写入Sink中。
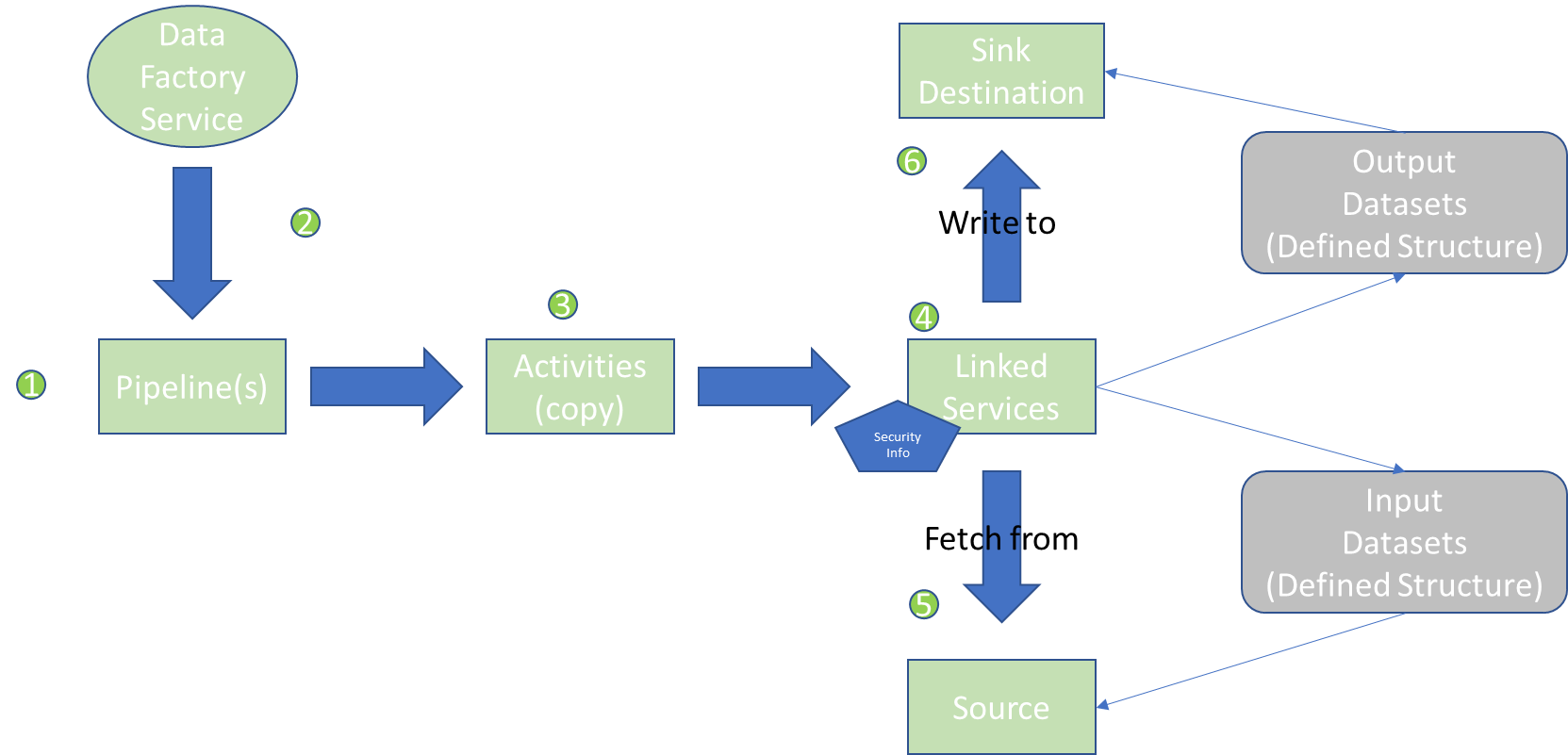
简要说明途中几个关键组件:
Linked Service: 与外部资源的连接。
Dataset: 链接服务器指定了连什么资源,而Dataset指定了资源怎么展示。 Dataset可以是DB 里面的表(或子集), 也可以是ADLS 上CSV文件的列,格式定义等。
Integration Runtime: 实际上就是计算引擎,ADF是一个云“服务”, 它更偏向于设计和调度,并不适合做太多运算, 所以需要借助外部资源来实现。这就是所谓的集成运行时(Integration Runtime, IR) 。
Pipeline: ADF的核心,是操作的一个集合或者容器,跟Logic Apps的workflow类似。ADF几乎所有实际操作都有pipeline来实现。
Data Flows: ADF 有两大类操作(活动, activity),一类是copy, 用于简单的文件传输。另外一种则是Data Flows, 它包含了大量的活动,这些活动用于操作数据,处理逻辑等。相对于copy 活动, data flows更适合用于大数据处理,因为它的后台正是使用了Azure Databricks的引擎。
在设计好pipeline之后,就需要按需调度起来。ADF 调度,用的是trigger, 由于ADF 的操作都需要被封装在pipeline里面,trigger通过管理pipeline的运行方式来实现调度。包括启停, 循环次数等。和Logic Apps类似,它同样可以实现分钟,小时,日,周,月的频率触发。不过配置时要注意时区,因为云计算是基于全球,所以默认都是UTC时间。
除了定时之外,还能被事件触发,比如访问HTTP/s端点,推送消息到Azure Storage queue,文件到达ADLS等。
下面来演示一下。
配置trigger
首先进入特定的pipeline,然后按下图【添加触发器】:
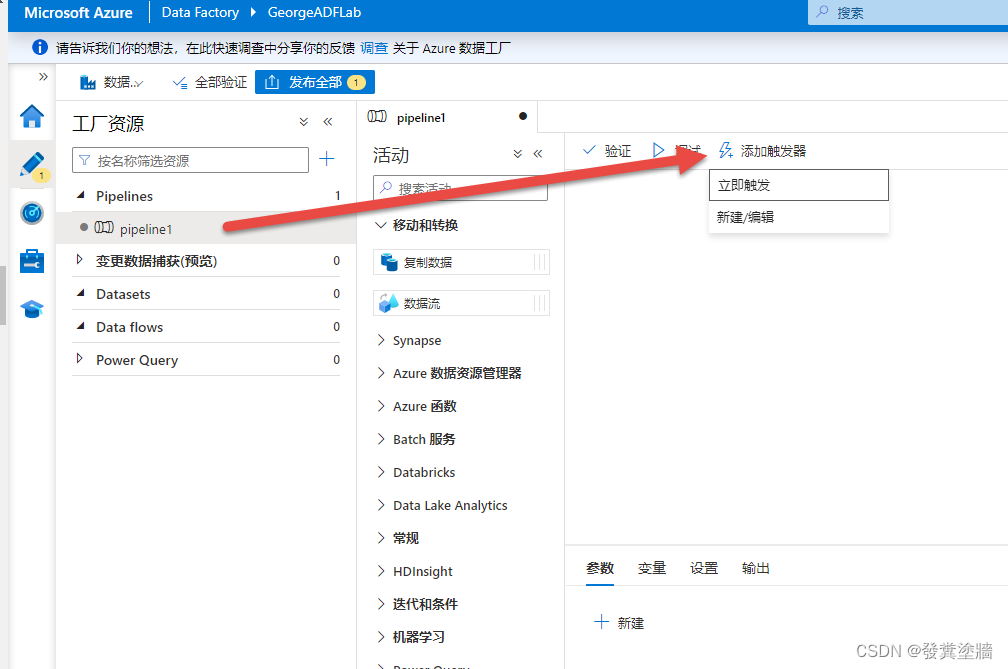
在配置界面,可以看到一些常见的配置项,这跟Logic Apps中的调度配置类似:
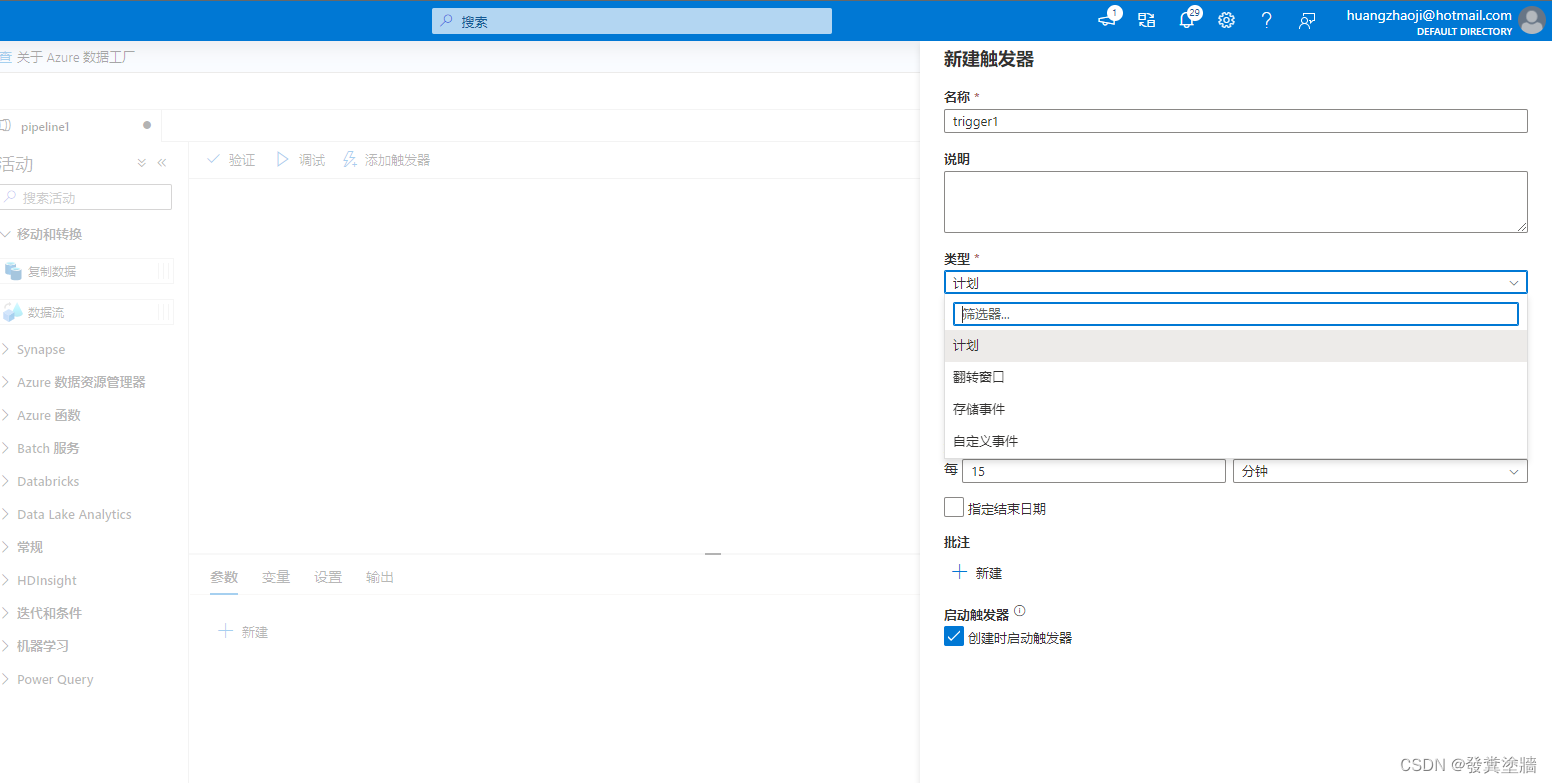
同样类似的还有时间间隔,也就是“重复” 里面的间隔单位选择,当选择天,周,月时,就会出现“高级定期选项”,如下图。这里可以指定到具体的执行行为, 可以和这篇文字对比着看:【Azure 架构师学习笔记】-Azure Logic Apps(7)- 自定义Logic Apps 调度。
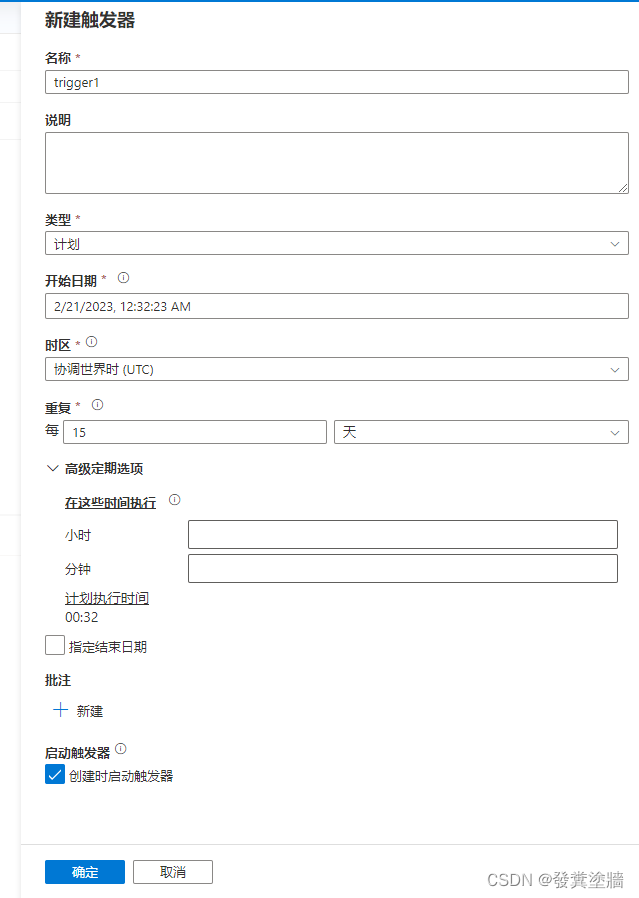
注意:这些trigger会在你“发布”之后才生效,而不是在你保存的时候。
在保存之后可以看到界面上出现了一个“1”的符号,证明添加了一个新的内容:
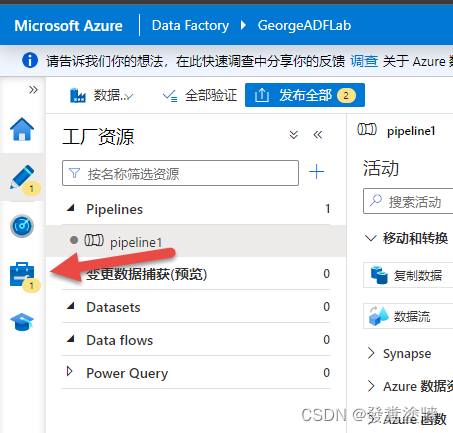
导航到这个位置就能看到是我们刚才配置的触发器。
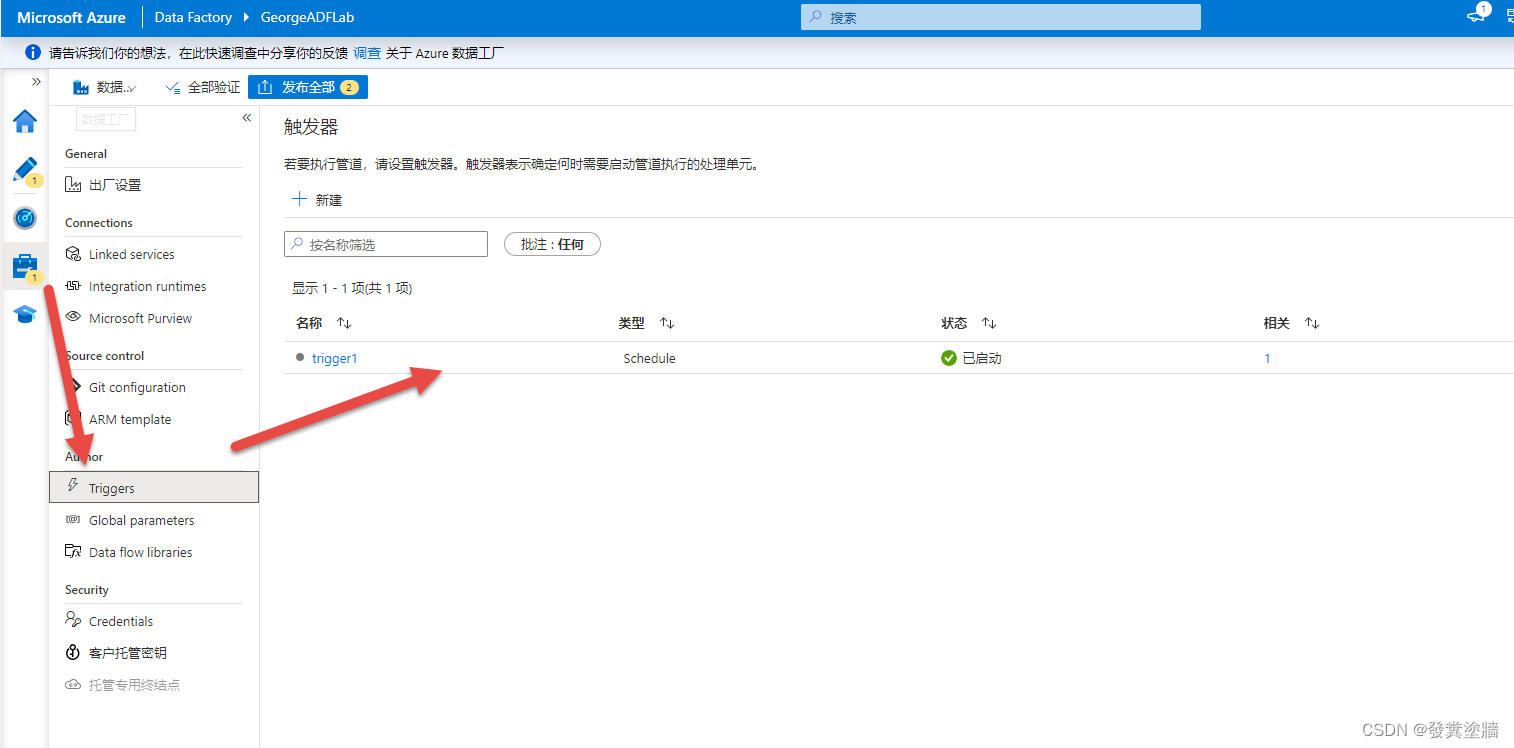
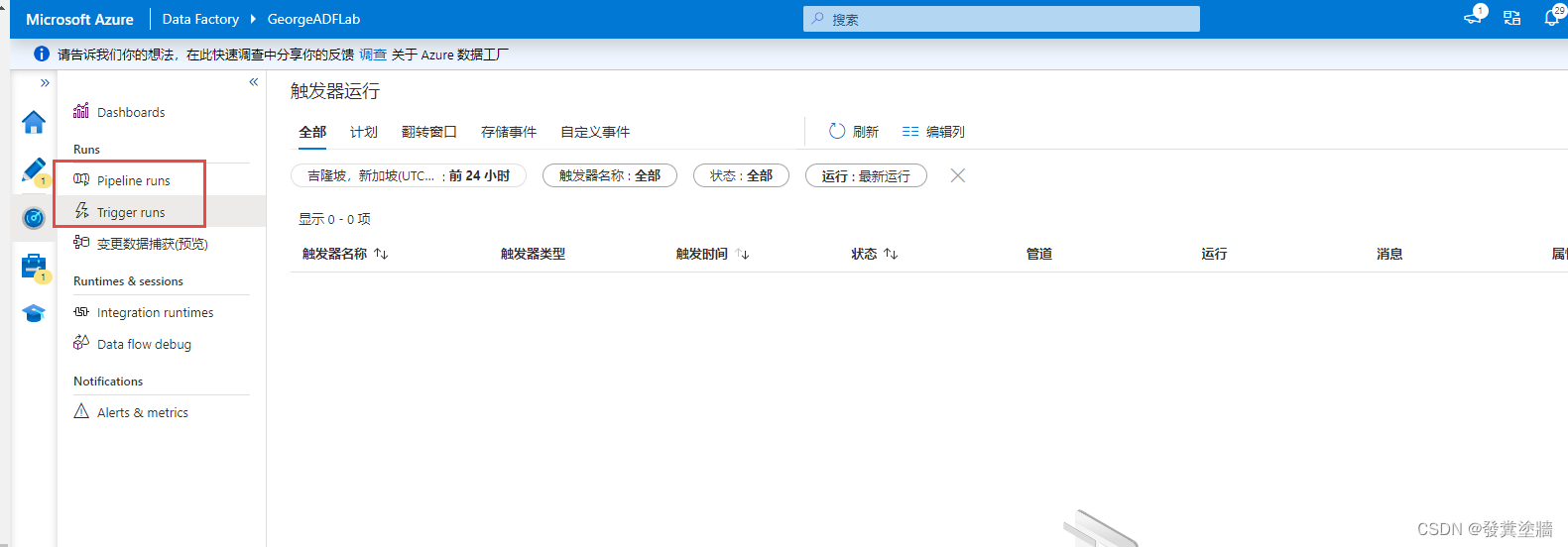
同时在monitor界面也可以看到一些pipeline和trigger的信息。不过由于演示并没有发布,所以这里没有实际运行。
小结
本文简单演示了ADF 的调度入门。下文会对其进行更多的介绍。