原文链接:https://www.techbeat.net/article-info?id=4486
作者:seven_

论文链接:
https://arxiv.org/abs/2212.08013
代码链接:
https://github.com/google-research/big_vision
视觉Transformer(ViT)目前已成为学界和工业界常用的视觉任务backbone,其通过将一整幅图像切割成图像块(patch)的方式来将其转换为序列送入到Transformer编解码结构中进行特征建模。很多工作已经证明,切割出来的图像块的大小往往决定了整体模型的性能和速度,如果输入模型较小的图像块,会得到更高的识别准确率,但是计算成本会增加,反之亦然。图像块的大小直接控制了模型速度与准确率之间的权衡。那我们究竟是该选择大图像块还是小图像块呢,是否需要根据下游任务来决定呢?来自谷歌研究院的研究者告诉我们,“小孩子才做选择,成熟的ViT模型可以灵活应对各种尺寸”。
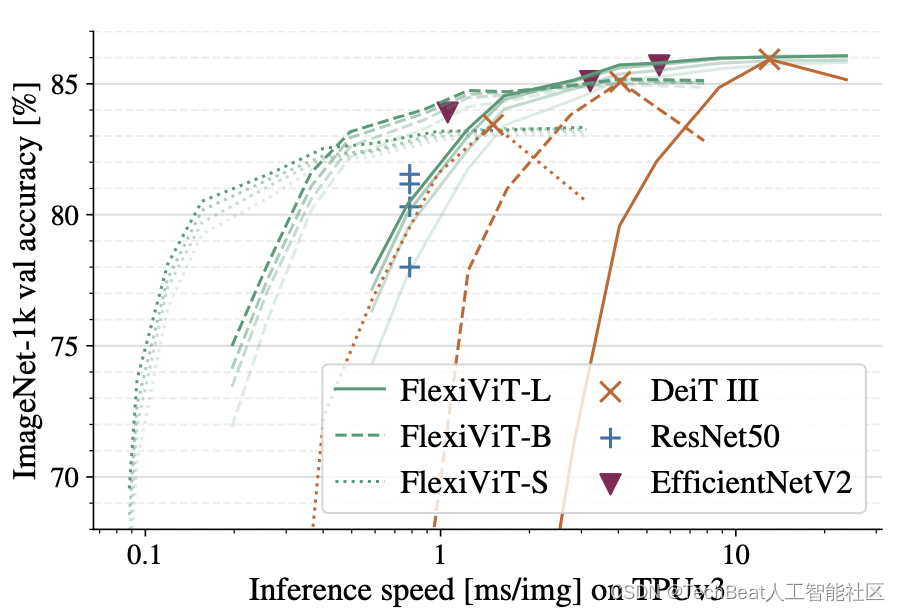
在本文中,作者提出了一种ViT训练策略,即在训练时随机确定图像块的大小来训练模型,这样训练得到的模型称为FlexiViT,其权重可以适应多种输入尺寸,这使得模型在部署阶段根据不同任务不同数据定制模型成为可能。作者在大量下游任务上进行了验证实验,包括图像分类、图像-文本检索、开放世界目标检测、全景分割和语义分割等,结果表明FlexiViT可以超过在单一尺寸下训练的诸多模型,可以灵活的应对各种现实场景,下图展示了FlexiViT与其他baseline模型在ImageNet-1K上的速度-准确性曲线对比情况。
一、引言
视觉Transformer的火热标志着学界对之前占主导地位的卷积神经网络(CNN)模式的重大革新,其通过“图像序列化”的方式来进行底层的像素处理,这种“序列化”也带来了一些新的处理模式,例如mask图像块、为特定任务添加专门的token,以及混合不同模态的图像块来处理多模态任务。作者发现,ViT模型中的图像块作为最基本的视觉处理单元,但是对于图像块尺寸的研究却很少,相比CNN时代的多尺度几何分析、金字塔特征建模等工作,ViT还缺乏在这一方面的探索。虽然初代版本的ViT中使用了三种图像块尺寸(32×32、16×16和14×14),但在后续的演变中,为了训练方便,大家更愿意将图像块固定为16x16大小。在这项工作中,作者对图像块尺寸对于模型预测精度和计算速度的影响进行了研究,期间模型的参数容量并不发生变化。实验结果证明固定图像块训练得到的ViT只能在单一的输入尺度上表现良好,如果输入发生变化,模型性能会严重受损,但是如果想要适应新输入,就只能重新训练模型。
为了克服这个限制,本文作者提出了FlexiViT,顾名思义,这是一种可以灵活处理输入尺度的ViT模型。作者在训练期间随机生成不同尺寸的图像块,并针对每种尺度自适应的调整位置和嵌入参数的大小,如下图所示。
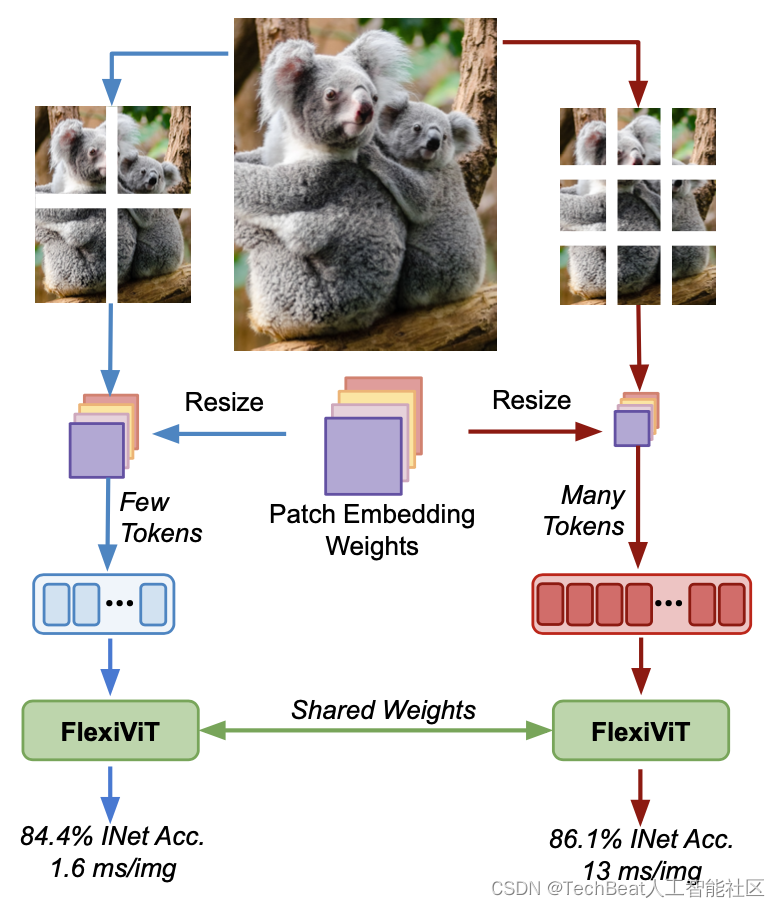
作者发现,这种自适应的训练pipeline可以有效提升模型的泛化能力,作者在广泛的下游任务上进行了实验,作者还发现,以这种方式训练得到的backbone在跨尺度的情况下性能也会得到保留,根据这一观察我们可以使用其来进行资源高效的迁移学习。
二、方法介绍
2.1 对标准的ViT进行分析
标准的ViT首先将一幅输入图像 x ∈ R h × w × c x \in \mathbb{R}^{h \times w \times c} x∈Rh×w×c 切割成一系列图像块 x i ∈ R p × p × c x_{i} \in \mathbb{R}^{p \times p \times c} xi∈Rp×p×c 可以将此过程称为“序列化”,接下来对每个图像块进行嵌入编码 x i : e i k = ⟨ x i , ω k ⟩ = vec ( x i ) T vec ( ω k ) x_{i}: e_{i}^{k}=\left\langle x_{i}, \omega_{k}\right\rangle=\text{vec}\left(x_{i}\right)^{T} \text{vec}\left(\omega_{k}\right) xi:eik=⟨xi,ωk⟩=vec(xi)Tvec(ωk) ,最后将学习到的位置编码 π i ∈ R d \pi_{i} \in \mathbb{R}^{d} πi∈Rd 添加到嵌入编码 t i = e i + π i t_{i}= e_{i}+\pi_{i} ti=ei+πi 中,以便送入到Transformer编码器完成运算。在这一过程中,对于给定的图像大小 h × w h \times w h×w,图像块大小 p p p 决定了Transformer模型输入序列的长度。我们可以将ViT模型表示为 ViT-S / p \text { ViT-S } / p ViT-S /p ,其中 S ∈ { S , M , B , L , … } \mathcal{S} \in\{\mathrm{S}, \mathrm{M}, \mathrm{B}, \mathrm{L}, \ldots\} S∈{S,M,B,L,…} 是模型规模(小、中、基础、大、…), p p p 是图像块大小。
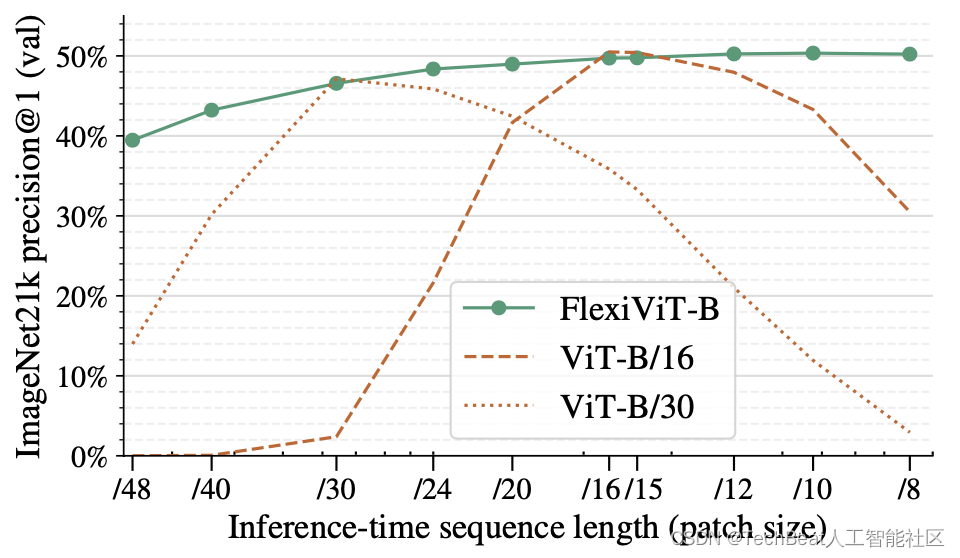
作者发现,标准的ViT结构并不灵活,其在不同的图像块情况下,性能会断崖式下降。为了使标准ViT能够强行输入不同图像块,作者简单地通过双线性插值调整嵌入权重
ω
k
\omega_{k}
ωk 和位置编码
π
\pi
π 的大小,结果如下图所示,其中虚线和点线分别代表标准ViT的性能随着图像块尺度的变化而下降。
2.2 如何训练更加灵活的ViT模型呢
在上图中,作者展示了基础FlexiViT-B模型的性能,FlexiViT-B是在与ViT-B/16和ViT-B/30模型相同的设置下进行训练的,除了输入图像块大小进行了动态调整,其输入的图像块大小是从一组预定义的尺寸集合中随机均匀采样得到的,在具体实现时,仅需要对训练代码进行两处小改动。
首先需要为嵌入权重 ω k \omega_{k} ωk 和位置编码 π \pi π 定义一个基础参数shape,保证其是可学习参数,将其作为网络前向传播的一部分。为了使FlexiViT能够应对几乎任何尺寸,作者使用240x240的输入图像,切割图像块大小为{240, 120, 60, 48, 40, 30, 24, 20 , 16, 15, 12, 10, 8, 6, 5, 4, 2, 1},在均匀采样时,采样范围为8-48。
下图展示了将标准ViT转换为FlexiViT的伪代码,需要注意的是,调整图像块大小不等同于调整输入图像大小,调整图像块尺寸不会影响模型参数,而调整输入图像尺寸则会丢失图像信息。

2.3 如何调整图像块嵌入的大小
在调整完输入图像块
x
∈
R
p
×
p
x \in \mathbb{R}^{p \times p}
x∈Rp×p 之后,还应该考虑对块嵌入向量以及块嵌入权重
ω
∈
R
p
×
p
\omega \in \mathbb{R}^{p \times p}
ω∈Rp×p 进行相应的变换。如果简单的使用双线性插值来缩放,则生成的token大小会很难控制,例如
⟨
x
,
ω
⟩
≈
=
1
4
⟨
resize
p
2
p
(
x
)
,
resize
p
2
p
(
ω
)
⟩
\langle x, \omega\rangle \approx = \frac{1}{4}\left\langle\text{resize}_{p}^{2 p}(x), \text{resize}_{p}^{2 p}(\omega)\right\rangle
⟨x,ω⟩≈=41⟨resizep2p(x),resizep2p(ω)⟩ 。理想情况下,我们希望调整过程中不会丢失图像中的关键信息。一种较为直接的实现方法是在对图像块进行嵌入编码后,立即使用LayerNorm进行规范化处理,但是这种方法需要改变模型架构,并且与现有的预训练ViT不兼容。因此作者提出了一种更加巧妙的调整方法,即设计了一系列矩阵线性变化来实现:
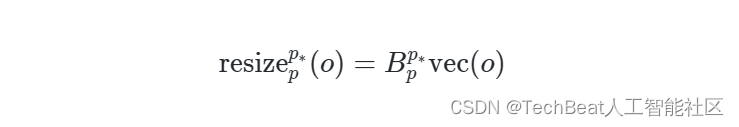
其中
o
∈
R
p
×
p
o \in \mathbb{R}^{p \times p}
o∈Rp×p 是任意输入,这种方法避免了对原有架构的修改,对本文的pipeline更加合适。
2.4 FlexiViT与知识蒸馏能否碰撞出火花
鉴于FlexiViT的灵活性,作者突发奇想,能否将其与知识蒸馏技术相结合来提高性能。一般情况下,知识蒸馏框架的优化难度要远远大于传统的标签监督方法,一些工作会将学生模型与教师模型架构设置的非常接近来解决这一问题,但是这样做又会影响蒸馏性能,因为教师模型通常要比学生模型具有更大的架构和规模,并且构成结构上的差异性。对于这种两难的情况,使用FlexiViT在合适不过,由于FlexiViT天然的架构灵活性,可以使用更加庞大复杂的ViT作为教师模型来优化学生FlexiViT,FlexiViT的随机块采样可以完美覆盖多种大型模型,并显著提高蒸馏性能。作者使用大型ViT-B/8模型作为教师模型进行实验,通过最小化教师和学生 FlexiViT的预测与随机块嵌入之间的KL距离进行优化:
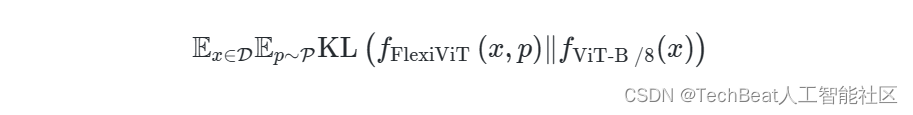
其中
f
FlexiViT
(
x
,
p
)
f_{\text {FlexiViT }}(x, p)
fFlexiViT (x,p) 是FlexiViT模型在图像块大小为
p
p
p 的类分布,
f
V
i
T
−
B
/
8
(
x
)
f_{\mathrm{ViT}-\mathrm{B} / 8}(x)
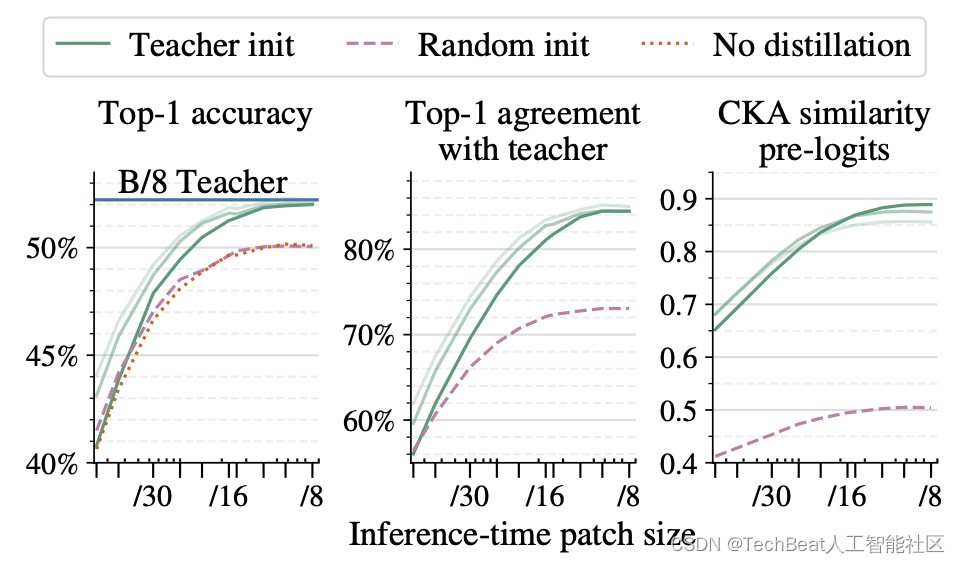
fViT−B/8(x) 是教师对完全相同输入的预测分布。下图比较了使用教师初始化与随机初始化和标签监督训练的蒸馏效果。其中淡绿色曲线展示了蒸馏效果,可以看到,蒸馏FlexiViT在图像块尺寸较小时与教师ViT的性能较为接近,当尺寸增加时,蒸馏FlexiViT的性能有很大提升。
三、实验效果
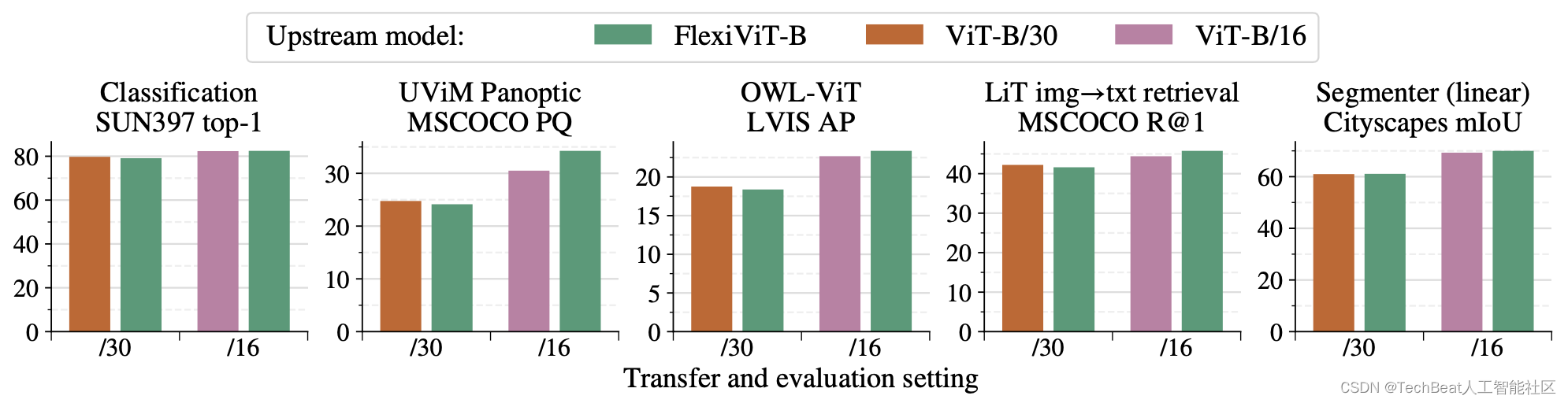
作者在实验部分对FlexiViT进行了广泛的评估,评估任务包括图像分类、图像-文本检索、开放世界目标检测、全景分割和语义分割。下图展示了这些迁移实验的效果,可以看到,预训练的FlexiViT在其他下游任务中的性能仍然与使用单一尺度大规模训练的ViT效果一致,在某些任务上甚至超过了原模型,这表明,我们可以只大规模预训练一个FlexiViT作为视觉backbone,然后在对应的下游任务数据集上进行小成本的微调就可以实现多种任务。这种方式进一步提高了ViT模型的可用性和适用性。
此外,作者还对FlexiViT的内部进行了分析。为了探究FlexiViT对于不同尺度的图像块的处理方式,作者对模型的内部表征进行了研究,使用minibatch centered kernel alignment(CKA)方法[1]来比较神经网络内部的表征,为了方便可视化,作者将特征图的CKA值和token的余弦相似度转换为统一度量,并使用t-SNE算法进行降维可视化,效果如下图所示。
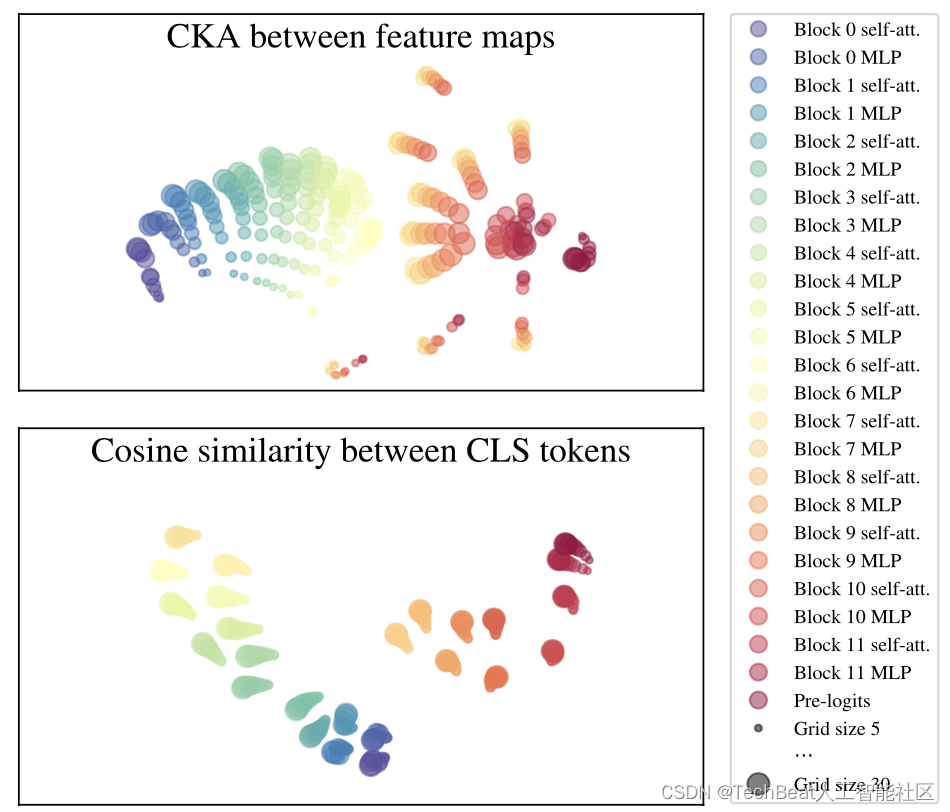
上图上半部分表示特征图表征可视化,可以看到,从网络的第一层到第六层的MLP块中,不同尺度的特征图表征是非常接近的,而在第六层中的MLP块中,表征开始出现分歧,但是在最后一个区块中再次收敛。相比之下,token表征在不同尺寸中始终保持一致,从这我们可以得出结论,虽然FlexiViT在内部表示中会因为尺寸变化而受影响,但是其输出表示通常是一致的。
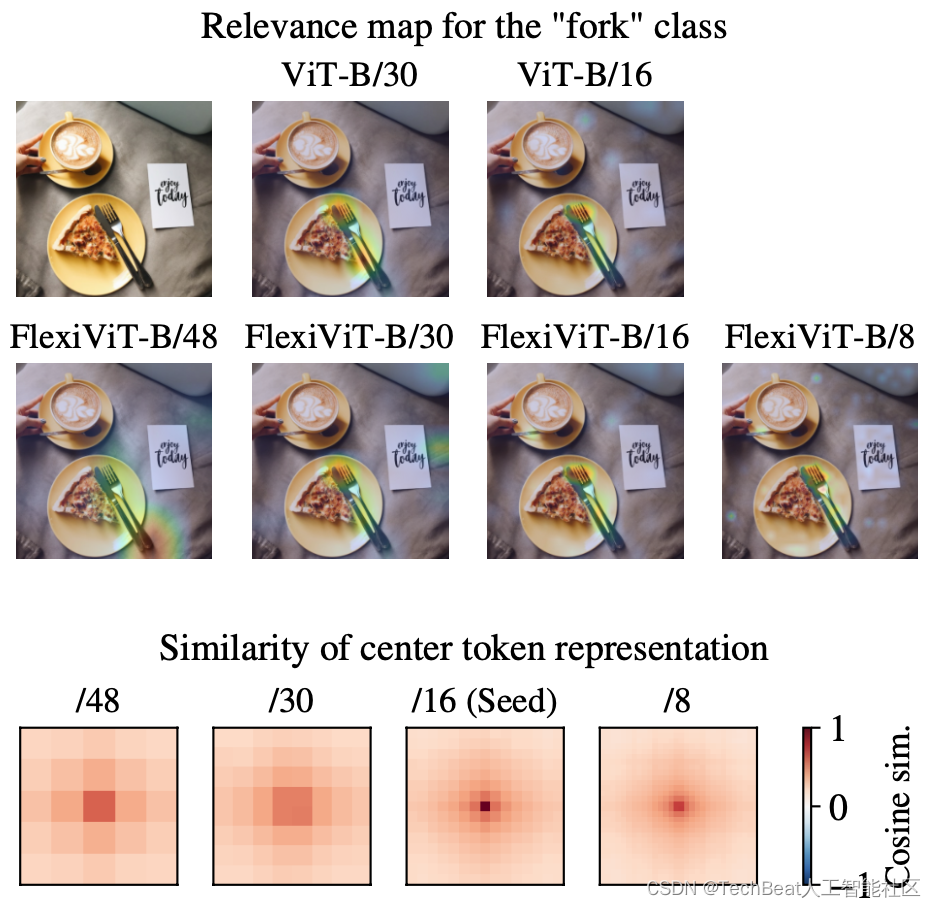
为了进一步分析多种尺度对FlexiViT的性能影响,作者提出了这样一个疑问,“对于同一幅输入图像,较大尺寸的图像块特征是如何与较小尺寸的图像块进行匹配和相关的呢?” 为了回答这个问题,作者先对不同尺度的注意力进行可视化,如下图上半部分所示,当图像块尺寸缩小时,注意力会逐渐细化到整个图像中的关键区域。此外,作者还对这些不同尺度的token特征之间的余弦相似度进行计算,并进行可视化,效果如下图下半部分,我们可以跨越尺度来找到token中的对应关系。
四、总结
本文提出的FlexiVit引入了一种非常简单有效的方法,可以应对多种图像块尺寸来自适应的训练单个模型,显著降低了ViT模型的预训练成本。作者团队在这项工作中进行了充分详实的实验评估,满满的谷歌味道。作者在大量下游任务中(包括图像分类、图像-文本检索、开放世界目标检测、全景分割和语义分割等常规视觉任务)进行了迁移实验,模型均表现良好,可以灵活的应对各种现实图像。作者还进一步展望,通过这项工作激发社区探索更多图像序列化的创造性应用。
参考
[1] Corinna Cortes, Mehryar Mohri, and Afshin Rostamizadeh. Algorithms for learning kernels based on centered alignment. The Journal of Machine Learning Research, 13:795–828, 2012. 5
Illustration by IconScout Store from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com