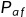相关文章
- K近邻算法和KD树详细介绍及其原理详解
- 朴素贝叶斯算法和拉普拉斯平滑详细介绍及其原理详解
- 决策树算法和CART决策树算法详细介绍及其原理详解
文章目录
- 相关文章
- 前言
- 一、决策树算法
- 二、CART决策树算法
- 2.1 基尼系数
- 2.2 CART决策树算法
- 总结
前言
今天给大家带来的主要内容包括:决策树算法、基尼系数和CART决策树算法。废话不多说,下面就是本文的全部内容了!
一、决策树算法
假设有这么一个例子,小明毕业后来到一家银行当行长,上班第一天就有15位客人申请了贷款,刚刚入行的小明仔细整理了客户的基本信息,这些基本信息包括:
- 是否有工作
- 是否有固定资产
- 信誉是否良好
经过深思熟虑后,小明逐一审查了这15份申请,并做了相应批复:

但是小明觉得这工作量实在是太大了,如果可以想一个办法快速的判断一个用户是否可以申请贷款呢?

经过几天几夜的努力思考后,小明根据客户的基本信息尝试得出结论:
- 按照工作为标准。其中五个有工作的用户都被批准了,而另外十个没有工作的客户有四个被批准了,六个被拒绝了

如果以少数服从多数为原则的话,可以得出结论:有工作的客户就会被批准,而没有工作的客户就会被直接拒绝。以上方法得到的结果显然和样本绝大部分的结果都相悖,所以按照工作为标准并不可行
- 按照信誉为标准。其中四个信誉非常好的客户被批准了;信誉良好的有四个客户被批准,两个被拒绝;而信誉一般的只有一个客户被批准,四个被拒绝

如果仍以少数服从多数为原则的话,那么可以得出结论:信誉非常好或者好的客户就会被批准,而信誉一般的客户就直接拒绝。以上方法得到的结果显然和样本绝大部分的结果仍然都相悖,所以按照信誉为标准也不可行
- 按照工作和信誉为标准。首先考虑工作因素,其中有工作的客户被分类得很好,全部客户的申请都被批准了,没有特例;而没有工作的客户,既有批准的,也有拒绝的。然后按照信誉的等级将剩下的客户分类,可以看到其中信誉非常好的客户和信誉一般的客户都被分类得很好,要不申请都批准了,要不都拒绝了,没有特例;而信誉好的客户的申请更偏向于拒绝

还是以少数服从多数为原则,可以得出结论:如果客户有工作,那么可以批准贷款;如果没有工作,我们再考虑他的信誉情况做出判断。通过以上方法得到的结果的正确率显然比前两种方法的正确率更高一些。这种方法就是利用决策树(Decision Tree)算法进行决策分类的过程,这种方法称为决策树算法的原因就是因为通过判断得到结果的过程分支很像一棵树,故而得名决策树算法
当小明发现决策树算法可以帮他快速进行客户申请的结果判断后,他非常高兴。假设此时有一个新客户的贷款申请,此客户没有工作,但是信誉非常好(忽略房子的因素),小明就可以按照上面介绍的决策树算法直接得出结论:

在刚才的决策树算法中,我们先按照是否有工作分类,又按照信誉等级进行分类,并且只考虑了这两种因素。那么我们目前就面临两个问题:
- 如果先按照信誉等级分类,再按照工作分类可不可以呢?
- 如果把是否有房子这个因素也考虑在内,又该按照什么顺序来选择标准呢?

二、CART决策树算法
2.1 基尼系数
刚才我们提到了,应该如何构建决策树呢?应该如何选择合理的因素呢?又应该如何选择多个因素合理的顺序呢?也就是说我们应该选择一个合理的标准,来作为决策树的分类节点,这个时候我们就需要对我们选择的标准进行好坏的判断,而标准的好坏可以用一个值来定义,这个值被称为基尼系数(Gini Index):
Gini
=
1
−
∑
k
=
1
K
p
k
2
\operatorname{Gini}=1-\sum_{k=1}^{K} p_{k}^{2}
Gini=1−k=1∑Kpk2
其中
p
k
(
1
≤
k
≤
K
)
p_{k}(1≤k≤K)
pk(1≤k≤K)是某一类别出现的概率,所以基尼系数的定义就是:1减去所有类别出现的概率的平方和。根据以上定义,就可以得到在我们这个二元分类问题中的基尼系数为:
G
i
n
i
=
1
−
p
(
批准
)
2
−
p
(
拒绝
)
2
Gini=1-p(\text{批准})^{2}-p(\text{拒绝})^{2}
Gini=1−p(批准)2−p(拒绝)2
刚才我们也提到了,可以使用基尼系数来确定当前标准的好坏:
- 当基尼系数越大时,此标准的不确定性越大,说明此标准较坏
- 当基尼系数越小时,此标准的不确定性越小,说明此标准较好
所以基尼系数的含义为当前标准的不确定程度,以上面的例子举例来说:
-
当 p ( 批准 ) = 1 , p ( 拒绝 ) = 0 p(\text{批准})=1,p(\text{拒绝})=0 p(批准)=1,p(拒绝)=0时:
G i n i = 1 − 1 − 0 = 0 Gini=1-1-0=0 Gini=1−1−0=0 -
当 p ( 批准 ) = 0 , p ( 拒绝 ) = 0 p(\text{批准})=0,p(\text{拒绝})=0 p(批准)=0,p(拒绝)=0时:
G i n i = 1 − 0 − 1 = 0 Gini=1-0-1=0 Gini=1−0−1=0 -
当 p ( 批准 ) = 0.5 , p ( 拒绝 ) = 0.5 p(\text{批准})=0.5,p(\text{拒绝})=0.5 p(批准)=0.5,p(拒绝)=0.5时:
G i n i = 1 − 0.25 − 0.25 = 0.5 Gini=1-0.25-0.25=0.5 Gini=1−0.25−0.25=0.5
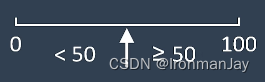
我们也可以通过下图更直观的看出基尼系数随概率的变化。我们可以看到,当客户一定被拒绝,或者一定被批准的情况下,这种确定性会得到一个接近于零的基尼系数;而如果我们认为客户被拒绝和批准的概率一样时,基尼系数值会达到最大值。

2.2 CART决策树算法
那么根据以上分析,我们只需要选择基尼系数最小的条件来作为决策树下一级分类的标准就可以了。再回到我们上面讲述的例子中。首先我们不考虑任何标准,根据贷款结果直接计算数据的基尼系数:

可以看到当我们不选用任何标准时的基尼系数非常大,此时的数据类似于随机生成的,这也就意味着当前的贷款结果有着很大的不确定性。
很明显不考虑任何标准就莽撞地分类,那么分类结果一定不好,所以我们应该考虑选取最佳的分类标准,我们首先考虑“工作”这个分类标准,整个计算过程如下所示:

- 首先计算有工作的客户的基尼系数,因为这些客户都获得了批准,所以基尼系数为零
- 然后同样根据基尼系数公式得到没有工作的客户的基尼系数为0.48
- 最后通过加权的方式并求和,就可以得到以工作为分类标准的最终基尼系数为0.32
以此类推,按照上面的做法,我们也可以计算得到以房子和信誉作为分类标准的基尼系数:

我们比较上面计算得到的四个基尼系数,可以发现以房子作为分类结果的基尼系数最小,所以我们应该首先按照“房子”这个分类标准来构建决策树:

如果客户有房子,可以直接批准他的贷款,所以决策树左边的节点已经被分类好了;那如果客户没有房子,我们也不能直接拒绝客户的贷款,而是应该考虑决策树右边节点的标准,这个时候我们只需要考虑那些没有房子的客户就可以了,以这些没有房子的客户样本作为新的集合,计算剩余所有标准的基尼系数:

可以看到,其中以工作作为分类标准的基尼系数为零,是最低的基尼系数值,所以我们选择工作作为下一步分类的标准:

这样,我们就把所有的类别都分类好了,这就是决策树的生成过程。这种以基尼系数为核心的决策树算法就称为CART决策树算法(Classification and Regression Tree)。
另外还有一点需要注意,我们一般看到的决策树都是二叉树的构造形式,这只是一种个人选择,并不是强制要求。这样做的目的只是为了方便处理连续的变量,如果样本分布在0~100之间,在没有具体的切割要求下,我们一般取平均数作为切割点,这样就自然地生成了一棵二叉树。
总结
以上就是本文的全部内容了,这个系列还会继续更新,给大家带来更多的关于机器学习方面的算法和知识,下篇博客见!