文章目录
- GCN的基础理论
- 1. 图的表示
- 2. GCN的原理
- 3. GCN的底层实现(pytorch)
- 3.1 Data Handling of Graphs(图数据处理)
- 3.2 Common Benchmark Datasets(通用基准数据集)
- 3.3 Mini-batches
- 4. 实现GCN层
- 5. GCN简单实例
GCN的基础理论
1. 图的表示

A
:图结构的邻接矩阵
A
~
:有自连接的邻接矩阵
A
~
=
A
+
I
D
~
:有自连接的邻接矩阵的度矩阵
D
~
i
i
=
∑
j
A
~
i
j
H
:图节点的特征
l
:
神经网络层数
\begin{aligned} & A:图结构的邻接矩阵 \\& \widetilde{A}:有自连接的邻接矩阵 \\& \widetilde{A} = A + I \\& \widetilde{D}:有自连接的邻接矩阵的度矩阵 \\& \widetilde{D}_{ii} = \sum_{j} \widetilde{A}_{ij} \\& H:图节点的特征 \\&l:神经网络层数\end{aligned}
A:图结构的邻接矩阵A
:有自连接的邻接矩阵A
=A+ID
:有自连接的邻接矩阵的度矩阵D
ii=j∑A
ijH:图节点的特征l:神经网络层数
2. GCN的原理
H ( l + 1 ) = δ ( D ~ − 1 / 2 A ~ D ~ − 1 / 2 H ( l ) W ( l ) ) H^{(l+1)} = \delta(\widetilde{D}^{-1/2}\widetilde{A}\widetilde{D}^{-1/2}H^{(l)}W^{(l)}) H(l+1)=δ(D −1/2A D −1/2H(l)W(l))
- GCN的输入是邻接矩阵A和节点特征H,直接做内积,再乘一个参数矩阵W,然后激活一下,不就相当于一个的神经网络层?为什么要有自连接的邻接矩阵?
提示:无法区分“自身节点”与“无连接节点”。只使用A的话,由于A的对角线上都是0,所以在和特征矩阵H相乘的时候,只会计算一个节点的所有邻居的特征的加权和,该节点本身的特征却被忽略了。
- 为什么需要有自连接的邻接矩阵的度矩阵?
提示:A是没有经过归一化的矩阵,这样与特征矩阵H相乘会改变特征原本的分布,所以对A做一个标准化处理。平衡度很大的节点的重要性。(对称归一化拉普拉斯矩阵)
N o r m A i j = A i j d i d j NormA_{ij} = \frac{A_{ij}}{\sqrt{d_{i}}\sqrt{d_{j}}} NormAij=didjAij
3. GCN的底层实现(pytorch)
Pytorch-Geometric (PyG):https://github.com/pyg-team/pytorch_geometric
官方文档 https://pytorch-geometric.readthedocs.io/en/latest/notes/introduction.html
PyG 提供了以下几个主要功能:
- Data Handling of Graphs(图数据处理)
- Common Benchmark Datasets(通用基准数据集)
- Mini-batches
- Data Transforms(数据转换)
- Learning Methods on Graphs(图学习算法)
- Exercises(训练)
3.1 Data Handling of Graphs(图数据处理)
图用于对对象(节点)之间的成对关系(边)进行建模。 PyG 中的单个图由torch_geometric.data.Data 的实例描述,该实例默认包含以下属性:
data.x: 节点特征矩阵H,形状:[num_nodes, num_node_features]data.edge_index: 图邻接矩阵A,形状:[2, num_edges],数据类型:torch.long举例:[[0,1,1,2],[1,0,2,1]]:表示0节点和1节点之间有边,1节点和2节点之间有边
即:[[所有起点节点],[所有终点节点]]。这里和一般思维不同,它们互为转置。注意使用时要转化为这种形式之后再使用data.edge_attr: 边特征矩阵,形状:[num_edges, num_edge_features]data.y: 训练目标(可以是任意形状),e.g., 节点尺度上的标签,形状:[num_nodes, *]or 整张图尺度上的标签[1, *]data.pos: 节点坐标矩阵,形状:[num_nodes, num_dimensions]
import torch
from torch_geometric.data import Data
# 注意:edge_index是定义所有边的源节点和目标节点的张量,不是索引元组的列表。
# --------------------第一种定义方法-----------------------------
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
>>> Data(edge_index=[2, 4], x=[3, 1])
# --------------------第二种定义方法-----------------------------
edge_index = torch.tensor([[0, 1],
[1, 0],
[1, 2],
[2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous()) # 注意这里edge_index进行了转置
>>> Data(edge_index=[2, 4], x=[3, 1])
3.2 Common Benchmark Datasets(通用基准数据集)
包含一些测试使用的基本数据集
3.3 Mini-batches
神经网络通常以批处理的方式训练。PyG 通过创建稀疏块对角邻接矩阵(由’ edge_index '定义),并在节点维度上连接特征矩阵和目标矩阵来实现小批的并行化。
这种组合允许不同数量的节点和边在一个批次的例子(即A1~An它们的维度可以不同):
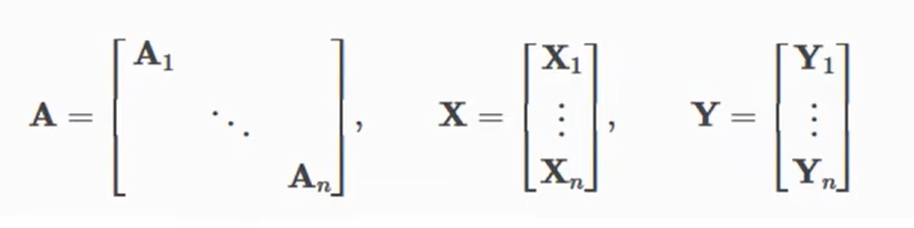
4. 实现GCN层
此公式可分为以下步骤:
- 在邻接矩阵中添加自循环。
- 线性变换节点特征矩阵。
- 计算归一化系数。
- 规范化节点特征
- 对相邻节点特征求和(“add”聚合)。
import torch
from torch_geometric.nn import MessagePassing
from torch_geometric.utils import add_self_loops, degree
class GCNConv(MessagePassing):
def __init__(self, in_channels, out_channels):
super().__init__(aggr='add') # "Add" aggregation (Step 5).
self.lin = torch.nn.Linear(in_channels, out_channels)
def forward(self, x, edge_index):
# x has shape [N, in_channels]
# edge_index has shape [2, E]
# Step 1: 在邻接矩阵中添加自循环。~A
edge_index, _ = add_self_loops(edge_index, num_nodes=x.size(0))
# Step 2: 线性变换节点特征矩阵。H*W
x = self.lin(x)
# Step 3: 计算归一化系数。
row, col = edge_index # row:第一行数据,col:第二行数据
deg = degree(col, x.size(0), dtype=x.dtype) # deg:度矩阵D; 参数为col算入度,参数为row算出度
deg_inv_sqrt = deg.pow(-0.5) # D^(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0
# The result is saved in the tensor norm of shape [num_edges, ]
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col] # D^(-0.5) * ~A * D^(-0.5)
# Step 4-5: 规范化节点特征,对相邻节点特征求和(“add”聚合)。
return self.propagate(edge_index, x=x, norm=norm) # D^(-0.5) * ~A * D^(-0.5) * H * W
def message(self, x_j, norm): # 扩展相乘,保证A和H能够相乘
# x_j has shape [E, out_channels]
# Step 4: Normalize node features.
return norm.view(-1, 1) * x_j
5. GCN简单实例
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class GNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16) # 参数1: 节点特征数,参数2: 随机
self.conv2 = GCNConv(16, dataset.num_classes) # 参数1: 与上一层一致,参数2: label类别数
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index) # x为特征矩阵,edge_index为邻接矩阵
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./data/Cora', name='Cora')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GNN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')