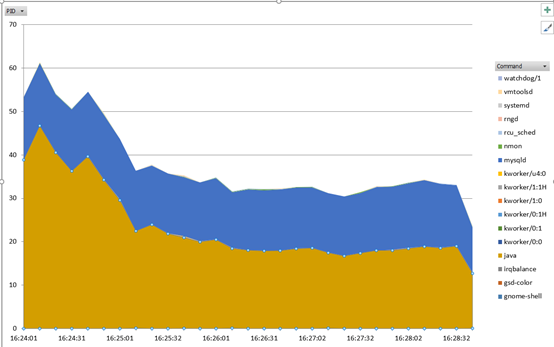
大家好~DolphinDB 最新版本近日已经发布,本次的 V2.00.9 与 V1.30.21 新版本推出了很多新功能,并对数据库做了全方位提升,是迄今为止新增功能最多的一次更新。
新特性一览
我们先来看一看新特性包含哪些方面:
1、数据库
针对数据安全和数据库管理,新版本推出了主从集群异步复制功能,加强了数据库容灾能力;权限管理能力也有了大幅提升,用户可以更高效、灵活地分层管理。新版本还推出了交易日历功能,包含了国内外各大交易所的日历数据,并支持用户自定义交易日历。除此之外,我们还做了以下扩展和优化:
新增 License server 功能,帮助用户合理分配资源;
加强 DECIMAL 数据类型的函数支持,大部分常用计算函数如 cumrank 等都已支持该类型;V2.00.9 版本还支持创建 DECIMAL 类型的数组向量;
新增对 arrow 格式的支持,加载插件后 Python API 可以以 arrow 协议与 DolphinDB 交互。
2、流计算
新版本推出了响应式状态引擎状态函数插件,扩展了非标准化函数能力,支持用户自定义算子,并优化了响应式状态引擎的计算性能。此外,流数据层面还有以下新特性:
优化异构流表多表数据回放,理想情况下最快可达约 300万条/秒;
优化 streamEngineParser ,使其产生尽量少的引擎,达到最优级联方案;
新增函数 genericStateIterate、genericTStateIterate 支持在流数据中窗口迭代计算;
新增函数 movingWindowData 和 tmovingWindowData,用于获取流计算中历史滑动窗口的数据。
3、SQL
新版本加强了对标准 SQL 语法的兼容,并优化了 group by 和 context by 等函数在大量分组下的计算性能。本次新增的兼容功能包括:
新增语句:drop(支持删库,删表操作),create local temporary table(支持创建本地临时内存表),alter(新增支持列名重命名,删除列),case when,union/union all,join on,with as(支持 with 关键字使用参数对列重命名);
新增谓词:(not) between and,is null/is not null,(not) exists/not exist,any/all;
新增函数:nullIf,coalesce;
新增关键字:distinct(单个或多个字段去重),nulls first/nulls last(order by 关键字)。
其他 SQL 相关的新版本特性包括:
共享表 append/insert into 语句支持通过 transaction 语句实现事务;
支持使用 select 子句中的列别名或新创建的列作为 where 的过滤条件;
支持 SQL 语句 where 条件里时间类型可以自动转换为 interval 分组的时间类型;
放开了在 SQL 查询使用 in 元组作为查询条件时,元组内元素个数的限制;
优化了 lsj 在大数据量下的性能。
针对 V2.00.9 新版本,我们还优化了 percentile、median 等函数在分布式查询下的性能以及优化了分区表 ej 的性能。
4、高阶函数 & 向量化计算
新版本系统性优化了高阶函数,支持高阶函数迭用,增强了向量化计算。其中新增了 byColumn 函数,使 accumulate 等高阶函数支持列内竖向计算,并支持在流计算中使用高阶函数 accumulate。其他新增函数和参数包括:
函数 dict 和 syncDict 新增参数 ordered,用于创建有序字典,支持键值对的顺序与输入顺序保持一致;支持两个字典的二元操作,以及字典和 scalar、vector 的二元操作;
函数 interval 新增参数 closed、label、origin;
新增函数 enlist 用于将标量或向量,转化为由其作为元素值的向量或元组;
函数 linearTimeTrend 支持对矩阵和表的计算;
函数 rowAt 支持以数组向量为索引;
在进行 slice 操作时,数组、矩阵等均可以通过标量、数组配对范围,如果越界则填充空值。
核心功能与亮点
接下来为大家详细介绍新版本的核心功能和亮点。
异步复制提升容灾能力
DolphinDB 提供数据、元数据、客户端以及流数据的高可用方案,以保证数据安全,满足各类业务场景7*24小时稳定运行的需求。在物联网、金融等领域,事务进行速度很快,数据持续在主机群上累积会降低性能。
为了满足日益增大的集群间吞吐量,进一步提高系统的可用性,我们采取了主从架构,在新版本中新增了集群间数据异步复制功能,支持将主集群数据复制到从集群,且保证主、从集群数据一致,实现了集群异地容灾。
DolphinDB 的异步复制功能具备灵活的扩展能力和较强的容错能力。对于主集群来说,增减数据节点无需重启,主从集群间也无需做节点映射;大部分情况下,集群中某些节点出现问题时,也不会导致数据丢失或不一致。此外,我们还为大家提供了方便的运维工具,新增了特定函数来监控两个集群间的异步复制状态和进度,便于出现错误后人工介入修复,大大提高了运维管理的效率。以下为部分新增函数:
setDatabaseForClusterReplication:启动针对某个数据库的异步复制;
getDatabaseClusterReplicationStatus():查看所有数据库是否开启了该功能;
getRecentSlaveReplicationInfo():在主集群上执行,一键获取所有从集群的回放进度。
更强大的权限管理
数据库的权限管理对保障数据安全非常重要,也是 IT 团队的一大运维管理成本之一。新版本中,DolphinDB 的权限管理有了更多亮点。
引入库级别权限:更高效
此前用户可以通过 getTables 函数对某个数据库下的数据表进行赋权,但当数据库动态新增数据表时,需要不断重新赋权。新版本中,读写权限可以配置到数据库级别,对新增的表也同样适用。
单独管理不同用户:更灵活
对于数据中台业务来说,当开放给外部用户使用时,需要考虑访问权限、安全和资源分配等诸多问题。不同的用户对数据库的访问权限应当视具体情况进行区分。
新版本中,DB_MANAGE 支持了数据库级别的权限设置,可以赋予或取消用户对某几个单独的数据库的管理权限。此外,我们在 setMemLimitOfQueryResult 中新增了 QUERY_RESULT_MEM_LIMIT字段,可以为某个单独的用户设置查询时的内存限制。
细化权限管理类目:更精细
数据表的写入操作包括插入、更新和删除,此前仅通过 TABLE_WRITE 一个维度,即可为用户赋权所有三项操作,这意味着用户不仅可以随意插入新数据,还能删除和更新,这给数据安全带来了隐患。因此,我们在新版本中新增了 TABLE_INSERT、TABLE_UPDATE、TABLE_DELETE 来控制插入、更新、删除数据的权限,支持更细粒度的权限管理。数据库级别的写入权限设置也同样做了精细化处理。
自带交易日历的数据库
交易日指除周末和法定节假日以外的时间,一般来说,除去国庆、元旦、春节等节假期后,全年交易日约有250天左右。在金融交易和量化策略研究中,交易日历是必备数据,可以帮助用户判断某一天是否为交易日,标识出下一个交易日和最后一个交易日,以及获取交易区间等。新版本提供了国内外各大交易所的交易日历及用户自定义交易日历的功能,并支持在函数 temporalAdd、resample、asfreq、transFreq 中进行计算。在新版本中,用户使用 getMarketCalendar 函数,就可以轻松获取期望日期内的所有交易日历。
在流数据引擎中 DIY 你的状态函数
在基于高频行情数据计算量价因子的过程中,每只股票的每一条新数据注入都会更新该股票的所有因子值。这些因子通常是有状态的,不仅与当前的多个指标有关,也与多个指标的历史状态相关。DolphinDB 提供的响应式状态引擎可以轻松解决这一难题。为了让用户更自如地实现业务逻辑,我们在新版本中将流数据的状态函数进行了插件化,帮助用户自己灵活定制状态函数。用户可以执行如下代码导入插件,并调用 listStateFunction 函数获取所有通过插件导入的状态函数及其用法的列表。
PLUGIN_PATH = "/path/to/plugin"
try {
loadPlugin(PLUGIN_PATH + "/PluginReactiveState.txt")
} catch (ex) {
print(ex)
// TODO: error handling
}
go利用这一插件,我们已经成功开发了 movingWindowData、genericStateIterate 等函数,支持用户在流计算中访问历史数据或任何中间状态,将其用于计算并将结果作为输入参数进行下一步处理。
响应式状态引擎性能优化
前面我们提到,响应式状态引擎中已实现的状态函数经过了特定优化,本身计算非常高效,但是如果需要对结果进一步处理,对于一些低效的解释执行过程,可以尝试通过即时编译(JIT)功能来加速这部分计算过程。
新版本中,JIT 除了新增支持常用函数 sum、avg、count、size、min、max、iif 等,还可帮助用户提升流数据引擎中特定函数以及自定义函数的性能。以 moving 函数为例,JIT 显著提升了响应式状态引擎的计算速度,优化效果十分明显。
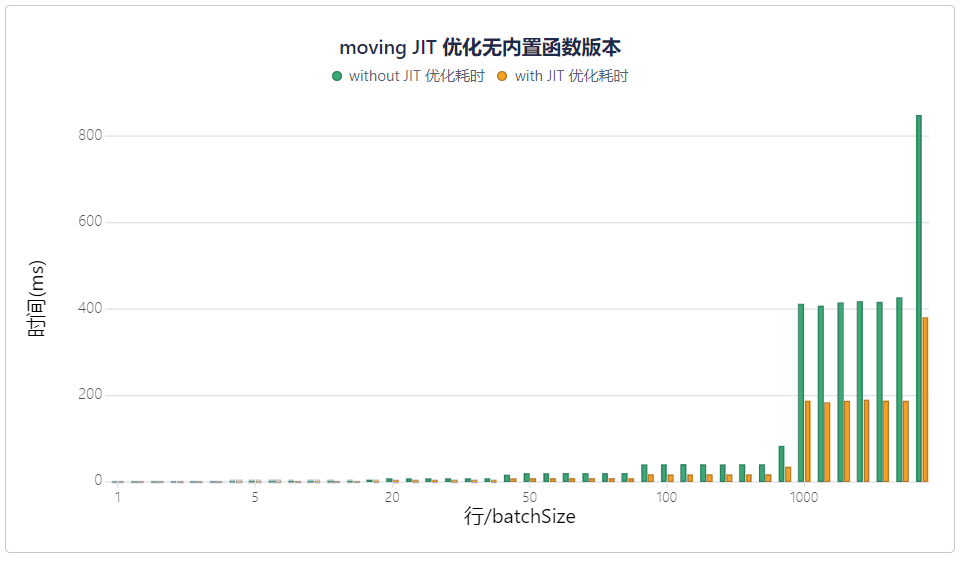
感兴趣的小伙伴可以阅读我们在知乎发布的另一篇文章:《如何提升 ETF 期权隐含波动率和希腊值的计算速度?》。这个案例详细介绍了使用 JIT 功能为期权相关指标计算加速的全过程,与 C++ 原生代码相比,耗时仅多出0.5倍,已十分接近,突破了这一计算场景的性能瓶颈。此外,新版本还针对流数据引擎做了其他性能改进,包括:
优化异构流表多表数据回放,理想情况下最快可达约 300万条/秒。
优化 streamEngineParser ,使其产生尽量少的引擎,达到最优级联方案。
值得一提的是,V2.00.9 版本允许流数据订阅客户端变成接受数据的一方,并在流订阅反转的基础上支持 WebSocket 连接。
大数据量分组计算性能提升与多线程加速
金融数据往往按交易信息分组,一张上千万行的数据表,一笔交易通常只有几行,因此分组数量非常庞大,针对这种情况,我们优化了 group by 和 context by 函数的性能,有十倍以上提升。此外,context by 新增支持了 matrix 和 table 的输入形式。

Pivot by 是 DolphinDB 的独有功能,是对标准 SQL 语句的拓展,它将表中一列或多列的内容按照两个维度重新排列,可实现将窄表转换为宽表。新版本改为用多线程加速计算,在资源充足情况下性能有了几十倍提升。此外,新版本还优化了当 pivot by 最后一列为分区列时的性能。
未完待续...
此次新版本特性覆盖范围非常广泛,从数据处理到安全管理,从功能扩展到性能提升,我们对 DolphinDB 做了全方位的优化,但这并不是结束。未来我们将不断推出更强大的工具,追求更优异的性能,满足更广大用户的需求。以下是我们在下一个版本中开发的重点:
提供 OLTP 内存存储引擎,推出嵌入式版本,支持更低时延的场景;
系统性提升 TSDB 引擎在高并发场景下的性能;
通过 JIT 和脚本语言优化,提升流计算和脚本语言性能;
提供数据库安全、健康、稳定性的巡检工具,提升运维的效率和便捷性;
提升数据库系统、流数据引擎的稳定性。