- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊|接辅导、项目定制
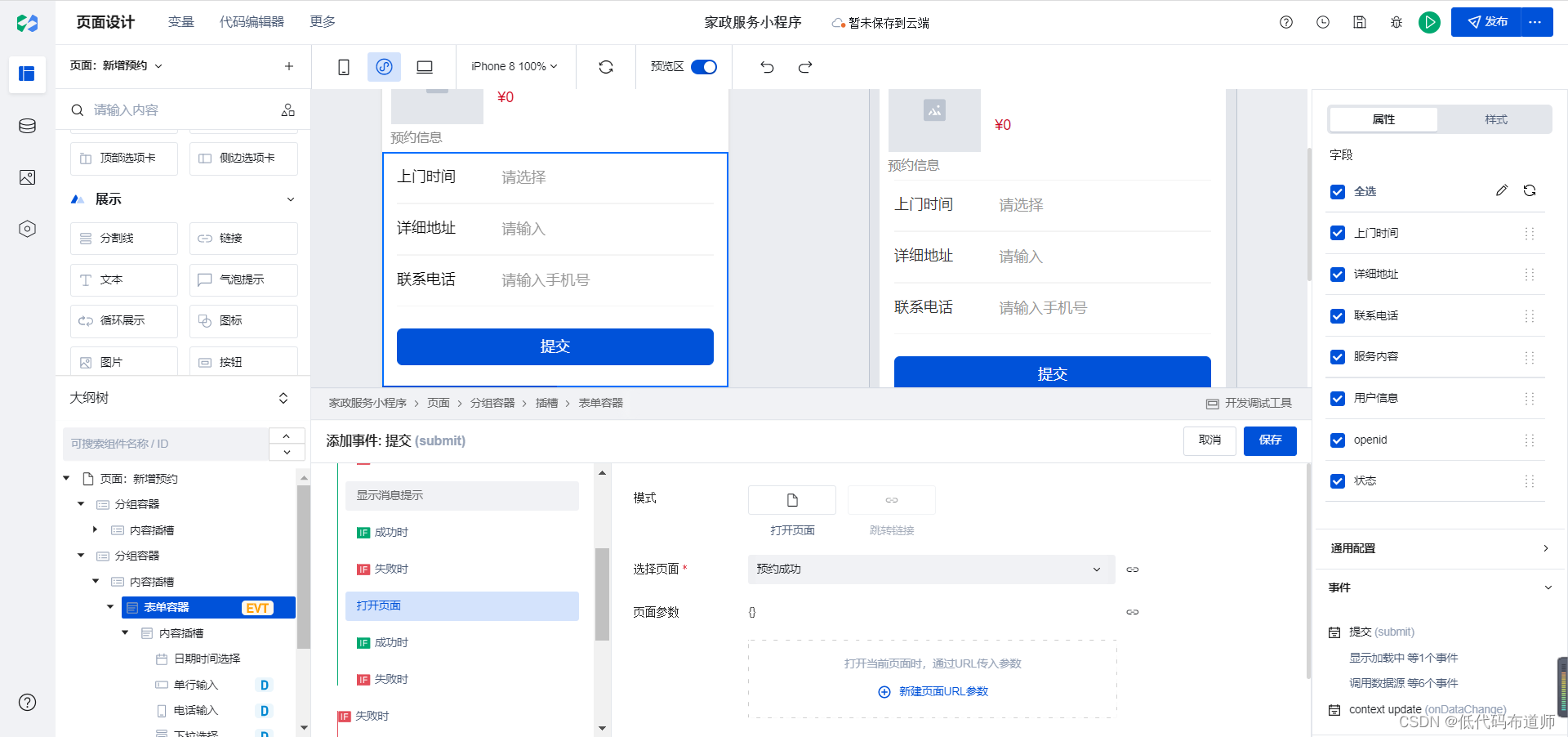
resnet-v2改进点以及和v1差别
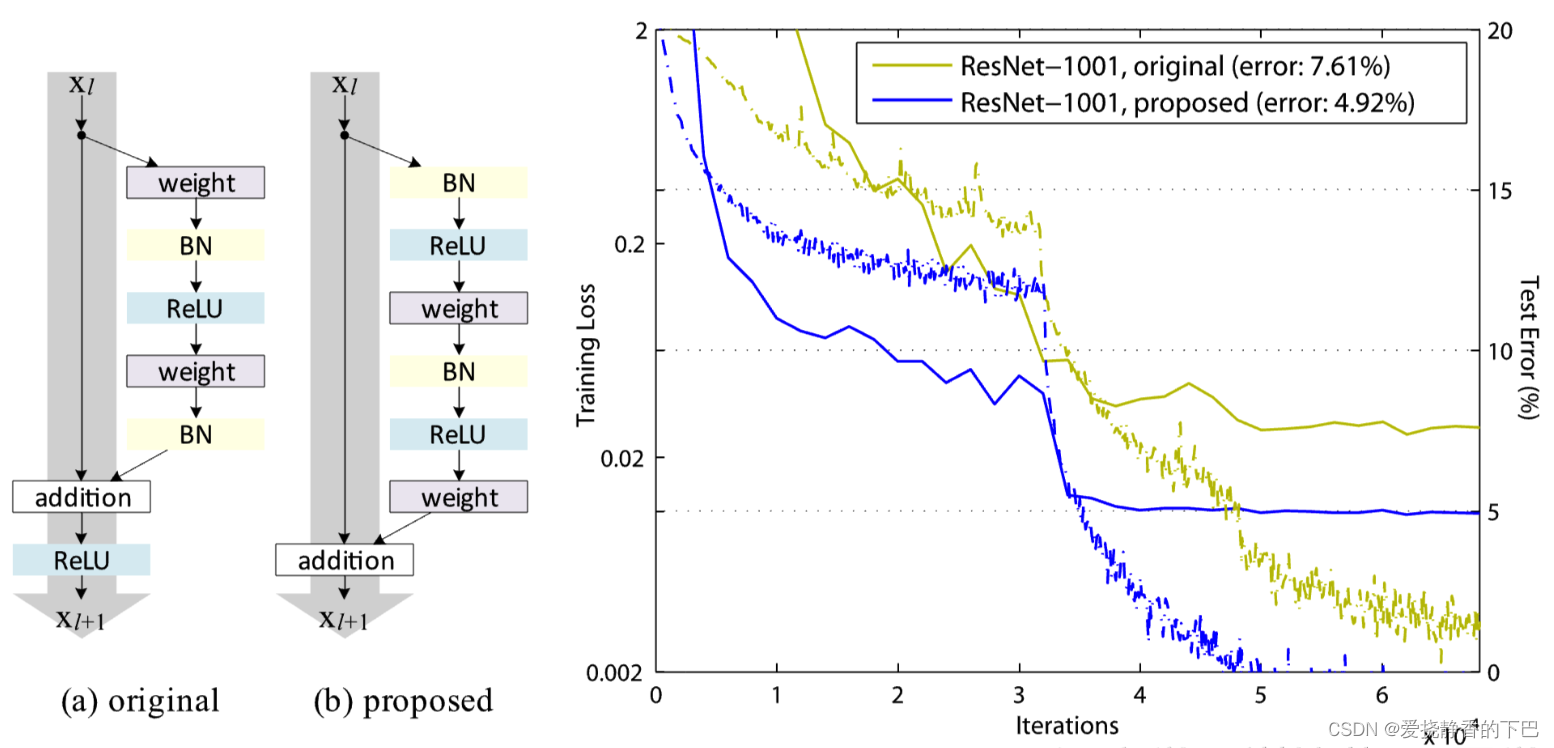
🧲 改进点:
(a)original表示原始的ResNet的残差结构,(b)proposed表示新的ResNet的残差结构。
主要差别就是
(a)结构先卷积后进行BN和激活函数计算,最后执行addition后再进行ReLU计算;(b)结构先进性BN和激活函数计算后卷积,把addition后的ReLU计算放到了残差结构内部。
📌 改进结果:作者使用这两种不同的结构再CIFAR-10数据集上做测试,模型用的是1001层的ResNet模型。从图中的结果我们可以看出,(b)proposed的测试集错误率明显更低一些,达到了4.92%的错误率。(a)original的测试集错误率是7.61%
在相同的数据集来实现(之前是resnet50)
导入需要的包
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
import os, PIL
import numpy as np
from torch.utils.data import DataLoader,Subset
from torchvision import transforms
from torchvision.datasets import ImageFolder
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
遍历并展示图片数量
path = "./data/bird_photos"
f = []
for root, dirs, files in os.walk(path):
for name in files:
f.append(os.path.join(root, name))
print("图片总数:",len(f))
图片总数: 565
导入数据
transform = transforms.Compose([
transforms.Resize(224), #统一图片大小
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225]) #标准化
])
data = ImageFolder(path, transform = transform)
print(data.class_to_idx)
print(data.classes)
{‘Bananaquit’: 0, ‘Black Skimmer’: 1, ‘Black Throated Bushtiti’: 2, ‘Cockatoo’: 3}
[‘Bananaquit’, ‘Black Skimmer’, ‘Black Throated Bushtiti’, ‘Cockatoo’]
可视化数据
def imageshow(data, idx, norm = None, label = False):
plt.figure(dpi=100,figsize=(12,4))
for i in range(15):
plt.subplot(3, 5, i + 1)
img = data[idx[i]][0].numpy().transpose((1, 2, 0))
if norm is not None:
mean = norm[0]
std = norm[1]
img = img * std + mean
img = np.clip(img, a_min = 0, a_max=1)
plt.imshow(img)
if label:
plt.title(data.classes[data[idx[i]][1]])
plt.axis('off')
plt.tight_layout(pad=0.5)
plt.show()
norm = [[0.485, 0.456, 0.406],[0.229, 0.224, 0.225]]
np.random.seed(22)
demo_img_ids = np.random.randint(564,size = 15)
imageshow(data, demo_img_ids, norm = norm, label = True)

配置数据集
torch.manual_seed(123)
train_ds, test_ds = torch.utils.data.random_split(data, [452,113])
train_dl = DataLoader(train_ds, batch_size = 8, shuffle=True, prefetch_factor=2) #prefetch_factor 加速训练, shffule 打乱数据
test_dl = DataLoader(train_ds, batch_size = 8, shuffle=False, prefetch_factor=2 )
再次检查数据
dataiter = iter(train_dl)
print("batch img shape: ", dataiter.next()[0].shape)
print("batch label shape:", dataiter.next()[1].shape)
构建模型
import torch
import torch.nn as nn
class BottleBlock(nn.Module):
def __init__(self, in_c, out_c, stride = 1, use_maxpool = False, K=False):
super().__init__()
if in_c != out_c * 4:
self.downsample = nn.Sequential(
nn.Conv2d(in_c, out_c * 4, kernel_size=1,stride=stride),
nn.BatchNorm2d(out_c * 4)
)
else: self.downsample = nn.Identity()
if use_maxpool:
self.downsample = nn.MaxPool2d(kernel_size = 1,stride =2)
stride = 2
self.bn1 = nn.BatchNorm2d(in_c)
self.ac = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_c, out_c, kernel_size=1)
self.bn2 = nn.BatchNorm2d(out_c)
self.conv2 = nn.Conv2d(out_c, out_c, kernel_size=3, padding=1,stride = stride)
self.bn3 = nn.BatchNorm2d(out_c)
self.conv3 = nn.Conv2d(out_c, out_c * 4, kernel_size=1)
self.K = K
def forward(self, x):
out = self.bn1(x)
out = self.ac(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.ac(out)
out = self.conv2(out)
out = self.bn3(out)
out = self.ac(out)
out = self.conv3(out)
x = self.downsample(x)
return x + out
class resnet_50_v2(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7,stride = 2,padding=3)
self.bn = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.pool1 = nn.MaxPool2d(kernel_size=3, stride=2 ,padding=1)
self.layer1 = self.make_layer(BottleBlock, [64,64], 3, use_maxpool_layer = 3,K=True)
self.layer2 = self.make_layer(BottleBlock, [256,128], 4, use_maxpool_layer=4,K=True)
self.layer3 = self.make_layer(BottleBlock, [512,256], 6, use_maxpool_layer=3,K=True)
self.layer4 = self.make_layer(BottleBlock, [1024,512], 3,K=True)
self.bn2 = nn.BatchNorm2d(2048)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(2048,4))
#创建一个拼接的模块
def make_layer(self, module, filters, n_layer, use_maxpool_layer=0, K=False):
filter1, filter2 = filters
layers = nn.Sequential()
layers.add_module('0', module(filter1, filter2,K=K))
filter1 = filter2*4
for i in range(1, n_layer):
if i == use_maxpool_layer-1:
layers.add_module(str(i), module(filter1, filter2,use_maxpool=True,K=False))
else:
layers.add_module(str(i), module(filter1, filter2, K=False))
return layers
def forward(self,x):
out = self.conv1(x)
out = self.bn(out)
out = self.relu(out)
out = self.pool1(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.bn2(out)
out = self.relu(out)
out = self.avgpool(out)
return self.fc(out)
model = resnet_50_v2()
model
模型结构
resnet_50_v2(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))
(bn): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(pool1): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BottleBlock(
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): BottleBlock(
(downsample): MaxPool2d(kernel_size=1, stride=2, padding=0, dilation=1, ceil_mode=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn3): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer2): Sequential(
(0): BottleBlock(
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
)
(1): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
)
(2): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
)
(3): BottleBlock(
(downsample): MaxPool2d(kernel_size=1, stride=2, padding=0, dilation=1, ceil_mode=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer3): Sequential(
(0): BottleBlock(
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
)
(1): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
)
(2): BottleBlock(
(downsample): MaxPool2d(kernel_size=1, stride=2, padding=0, dilation=1, ceil_mode=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
)
(3): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
)
(4): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
)
(5): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1))
)
)
(layer4): Sequential(
(0): BottleBlock(
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
)
(1): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
)
(2): BottleBlock(
(downsample): Identity()
(bn1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(ac): ReLU(inplace=True)
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1))
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1))
)
)
(bn2): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=2048, out_features=4, bias=True)
)
)
训练
import copy
def train_model(epoch, model, optim, loss_function, train_dl, test_dl=None,lr_scheduler = None):
for k in range(epoch):
model.train()
train_acc,train_len = 0, 0
history={"train_loss":[],
"train_acc":[],
"val_loss":[],
"val_acc":[],
'best_val_acc': (0, 0)}
best_acc = 0.0
for step, (x, y) in enumerate(train_dl):
#print(step)
x,y = x.to(device), y.to(device)
y_h = model(x)
optim.zero_grad()
loss = loss_function(y_h, y)
loss.backward()
optim.step()
predict = torch.max(y_h,dim=1)[1]
train_acc += (predict == y).sum().item()
train_len += len(y)
trainacc = train_acc/train_len*100
history['train_loss'].append(loss)
history['train_acc'].append(trainacc)
val_loss = 0.0
val_acc,val_len = 0, 0
if test_dl is not None:
model.eval()
with torch.no_grad():
for _, (x,y) in enumerate(test_dl):
x,y = x.to(device), y.to(device)
y_h = model(x)
loss = loss_function(y_h, y)
val_loss += loss.item()
predict = torch.max(y_h,dim=1)[1]
val_acc += (predict == y).sum().item()
val_len += len(y)
acc = val_acc/val_len*100
history['val_loss'].append(val_loss)
history['val_acc'].append(acc)
if (k+1)%5 == 0:
print(f"epoch: {k+1}/{epoch}\n train_loss: {history['train_loss'][-1]},\n train_acc: {trainacc},\n val_acc: {acc},\n val_loss: {history['val_loss'][-1]}")
if lr_scheduler is not None:
lr_scheduler.step()
if best_acc< trainacc:
best_acc = acc
history['best val acc']= (epoch, acc)
best_model_wts = copy.deepcopy(model.state_dict())
print('=' * 80)
print(f'Best val acc: {best_acc}')
return model, history, best_model_wts
model = model.to(device)
loss_fn = nn.CrossEntropyLoss()
optims = torch.optim.Adam(model.parameters(), lr = 1e-2)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optims, 50, last_epoch=-1)
model, history, best_model_wts = train_model(50, model, optims, loss_fn, train_dl, test_dl,lr_scheduler)
epoch: 5/50
train_loss: 1.3529443740844727,
train_acc: 60.84070796460177,
val_acc: 50.66371681415929,
val_loss: 67.96911036968231
epoch: 10/50
train_loss: 0.3679060935974121,
train_acc: 67.03539823008849,
val_acc: 74.5575221238938,
val_loss: 39.28975901007652
epoch: 15/50
train_loss: 1.636350393295288,
train_acc: 75.22123893805309,
val_acc: 80.53097345132744,
val_loss: 30.901596864685416
epoch: 20/50
train_loss: 0.5659410953521729,
train_acc: 77.21238938053098,
val_acc: 77.65486725663717,
val_loss: 30.538477830588818
epoch: 25/50
train_loss: 0.11142534017562866,
train_acc: 81.85840707964603,
val_acc: 88.93805309734513,
val_loss: 16.465759705752134
epoch: 30/50
train_loss: 0.14212661981582642,
train_acc: 86.72566371681415,
val_acc: 87.38938053097345,
val_loss: 18.4492209777236
epoch: 35/50
train_loss: 1.4149291515350342,
train_acc: 87.38938053097345,
val_acc: 97.34513274336283,
val_loss: 8.108955120667815
epoch: 40/50
train_loss: 0.651155412197113,
train_acc: 94.69026548672566,
val_acc: 97.78761061946902,
val_loss: 3.9437274279771373
epoch: 45/50
train_loss: 0.062520831823349,
train_acc: 96.01769911504425,
val_acc: 99.33628318584071,
val_loss: 2.148590993718244
epoch: 50/50
train_loss: 0.03985146805644035,
train_acc: 95.13274336283186,
val_acc: 99.77876106194691,
val_loss: 1.442910757730715
================================================================================
Best val acc: 99.77876106194691
在这个数据集上,效果确实比resnet原版好一些