✨个人主页:bit me👇
✨当前专栏:MySQL数据库👇
✨算法专栏:算法基础👇
✨每日一语:悟已往之不谏,知来者之可追。实迷途其未远,觉今是而昨非。
目 录
- 🎄一. 数据库约束
- 🌲二. 表的设计
- 🌳三. 新增
- 🌴四. 查询
- 🏳️4.1 聚合函数(以下都是聚合查询)
- 🏴4.2 分组查询
- 🏁4.3 内连接(以下都是联合查询)
- 🚩4.4 外连接
- 🏳️🌈4.5 自连接
- 🏴☠️4.6 子查询
- 🏳️⚧️4.7 合并查询
🎄一. 数据库约束
- 约束就是数据库可以让程序猿定义一些对数据的限制规则,数据库会在插入 / 修改数据的时候按照这些规则对数据进行校验,如果校验不通过,就直接报错。
约束的本质就是让我们及时发现数据中的错误,更好的保证数据的正确性
约束类型:
- NOT NULL - 指示某列不能存储 NULL 值。(必填项)
- UNIQUE - 保证某列的每行必须有唯一的值。
- DEFAULT - 规定没有给列赋值时的默认值。(可以通过default修改这个默认值)
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句
①:NOT NULL
- 初始情况下,一个表允许为NULL。
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> insert into student values(NULL, NULL);
Query OK, 1 row affected (0.00 sec)
加上 NOT NULL 约束之后,就不再允许插入空值
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int not null, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
再尝试插入空值就会报错!
mysql> insert into student values (NULL, NULL);
ERROR 1048 (23000): Column 'id' cannot be null
②:UNIQUE 唯一性
- 默认情况下,表里的数据都是可以重复的
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 1 | 张三 |
| 1 | 张三 |
+------+--------+
3 rows in set (0.00 sec)
没有约束的表和有约束的表对比
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int unique, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | UNI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
当我们想再次输入同样的数据的时候发现报错
mysql> insert into student values(1, '张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(1, '张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'id'
Duplicate --> 重复, entry --> 条目(不是入口) 触发了 UNIQUE 约束
③:DEFAULT
- 设定默认值
默认的默认值是NULL,可以通过 default 约束来修改这里的默认值的取值
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
对表进行指定列插入的时候,会涉及到默认值的情况的
mysql> insert into student (id) values (1);
Query OK, 1 row affected (0.00 sec)
指定了 id 这一列插入,此时的 name 就是按照默认值来走的
mysql> select * from student;
+------+------+
| id | name |
+------+------+
| 1 | NULL |
+------+------+
1 row in set (0.00 sec)
通过 default 约束来修改默认值
mysql> drop table student;
Query OK, 0 rows affected (0.00 sec)
mysql> create table student (id int default 0, name varchar(20) default '未命名');
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+-----------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+-----------+-------+
| id | int(11) | YES | | 0 | |
| name | varchar(20) | YES | | 未命名 | |
+-------+-------------+------+-----+-----------+-------+
2 rows in set (0.00 sec)
mysql> insert into student (id) values (1);
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+------+-----------+
| id | name |
+------+-----------+
| 1 | 未命名 |
+------+-----------+
1 row in set (0.00 sec)
mysql> insert into student (name) values ('张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+------+-----------+
| id | name |
+------+-----------+
| 1 | 未命名 |
| 0 | 张三 |
+------+-----------+
2 rows in set (0.00 sec)
④:PRIMARY KEY --> 主键
- 在设计一个表的时候,非常重要的一个列,表示一条记录的身份标识,用来区分这条记录和别的记录的
注:
- 不能为空,相当于 NOT NULL
- 不能重复,相当于UNIQUE
- 一个表里只能有一个主键
mysql> drop table student;
Query OK, 0 rows affected (0.00 sec)
mysql> create table student (id int primary key,name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
添加元素:
mysql> insert into student values(null, null);
ERROR 1048 (23000): Column 'id' cannot be null
mysql> insert into student values(1,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values(1,'张三');
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
主键不能为空,主键的值也不能重复
由于主键必须要填,还不能重复,MySQL为了方便大家填写主键,内置了一个功能 ”自增主键“ ,帮助我们自动生成主键的值,就不用程序猿自己来保证了
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> desc student;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
当前 id 是自增主键,不同于主键,可以使用 null
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
- 如果写的是具体数值,就是手动指定 id
- 如果写的是 null ,就是让 MySQL 按照自增主键自动生成
mysql> select * from student;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
+----+--------+
1 row in set (0.00 sec)
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+----+--------+
| id | name |
+----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
+----+--------+
4 rows in set (0.00 sec)
中间插入手动增加之后自增从当前的数字自增
mysql> insert into student values (100,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+-----+--------+
| id | name |
+-----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
| 100 | 张三 |
+-----+--------+
5 rows in set (0.00 sec)
mysql> insert into student values (null,'张三');
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+-----+--------+
| id | name |
+-----+--------+
| 1 | 张三 |
| 2 | 张三 |
| 3 | 张三 |
| 4 | 张三 |
| 100 | 张三 |
| 101 | 张三 |
+-----+--------+
6 rows in set (0.00 sec)
- MySQL 想要自增,必须要能够记录下来当前 id 已经到哪了,还要保证自增后,得是不能重复的。
- MySQL里简单粗暴的做法,直接就是记录当前 自增主键 里的最大值,这就能保证自增速度很快,并且一定是不重复的
- 可能会觉得有数据库浪费了,但是数据库一般而言是很大的,一般不考虑这个浪费
自增主键,主要就是用来生成一个唯一的 id ,来保证不重复,如果数据库是分布式部署,这个时候自增主键就要带来问题。
在一个MySQL集群里,有许多的MySQL节点(多个节点上的数据放在一起才是一个完整的数据集合),MySQL生成自增主键的时候可以保证在自己这个节点上生成的 id 是唯一的,但是无法保证这个 id 在其他节点上也是唯一的。
生成一个 ID 这样的需求,是客观存在的,但是 MySQL 自增主键,已经难以满足要求了
一个典型的解决方法:在生成 id 的时候,让这些节点相互协商一下,彼此了解了对方的情况之后,就能生成唯一的 id 了,但是代价有点大。为了轻量,高效,又出了另外一个方法:唯一 id = 时间戳(ms) + 机房编号/主机编号 + 随机因子 (这里的 + 不是算术运算 而是字符串拼接),进入数据库的数据有先有后形成时间戳,并且会分摊到不同的主机上,就算是一个主机,又会生成随机数的!(也有极端情况三种一模一样,理论上存在但是工程上是忽略不计的!)
⑤:FOREIGN KEY
- 描述了两张表之间的关联关系
举例:
- 班级表是负责约束的一方,称为父表
- 学生表是被约束的一方,称为子表
mysql> drop table student;
Query OK, 0 rows affected (0.01 sec)
mysql> create table class (classId int primary key,className varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (studentId int primary key, name varchar(20), classId int, foreign key (classId) references class (classId));
Query OK, 0 rows affected (0.01 sec)
mysql>
mysql> desc student;
+-----------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+-------------+------+-----+---------+-------+
| studentId | int(11) | NO | PRI | NULL | |
| name | varchar(20) | YES | | NULL | |
| classId | int(11) | YES | MUL | NULL | |
+-----------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
- 第一句为父表,第二句为子表
- 先把所有的列都定义完,逗号,然后再写外键约束
在父表为空的情况下,直接尝试往子表插入,就会报错!!!
mysql> insert into student values(1,'张三',1);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`java`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `class` (`classId`))
在父表里面添加一些数据:
mysql> insert into class values (1,'java101');
Query OK, 1 row affected (0.00 sec)
mysql> insert into class values (2,'java102');
Query OK, 1 row affected (0.00 sec)
mysql> insert into class values (3,'java103');
Query OK, 1 row affected (0.00 sec)
mysql> select * from class;
+---------+-----------+
| classId | className |
+---------+-----------+
| 1 | java101 |
| 2 | java102 |
| 3 | java103 |
+---------+-----------+
3 rows in set (0.00 sec)
往子表插入数据
mysql> insert into student values(1,'张三',4);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`java`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `class` (`classId`))
依旧报错,插入子表的数据没有在父表的 classId 中,同样也是报的刚才的错误
在外键的约束下,每次你插入 / 修改操作,都会先触发在父表中的查询,父表中存在才能插入 / 修改成功,否则就会失败。
mysql> insert into student values(1,'张三',1);
Query OK, 1 row affected (0.00 sec)
每次插入都要先查询会拖慢执行效率,但是也没有特别拖慢
如果查询操作触发了遍历表,低效的;如果触发了索引,相对于快不少
建立外键约束的时候,MySQL 就要求,引用的父表的列,必须是主键或者UNIQUE(自带索引,查询速度就会快一些)
父表对子表产生了限制,但是反过来子表也会对父表产生限制
父表对子表的限制是不能随意插入 / 修改 子表对于父表的限制就是不能随意修改 / 删除
mysql> select * from student;
+-----------+--------+---------+
| studentId | name | classId |
+-----------+--------+---------+
| 1 | 张三 | 1 |
+-----------+--------+---------+
1 row in set (0.00 sec)
mysql> delete from class where classId = 1;
ERROR 1451 (23000): Cannot delete or update a parent row: a foreign key constraint fails (`java`.`student`, CONSTRAINT `student_ibfk_1` FOREIGN KEY (`classId`) REFERENCES `class` (`classId`))
由于在子表中,引入了 classId = 1 的记录,尝试删除父表中的对应记录,发现,这个就难以删除
⑥: CHECK(了解)
- 直接对表中的值做出限制
check (sex ='男' or sex='女')
例如限制性别这一列只能是 男 或 女
🌲二. 表的设计
- 根据一些实际的业务场景,来设计表,主要就是确定有几个表,每个表干啥,每个表有多少个字段。
面试官:你的项目里的数据库是如何设计的?
- 其实是让你回答,你的数据库里有几个表,每个表是干啥的,以及表里有哪些字段
那我们该如何设计它呢?
我们需要明确需求场景,提取出需求中的 " 实体 " ,实体可以认为是关键性名词,一般来说,每个实体都会分配一个表来进行表示,除了实体之外,还需要理清楚,实体和实体之间的关系。
1. 一对一
2. 一对多
3. 多对多
4. 没关系
例如一个学校的教务系统:
有学生,账号,课程,班级
- 一个学生只能有一个账号,一个账号只能分配给一个学生(一对一)
- 一个同学只属于一个班级,一个班级包含多个学生(一对多)
- 一个学生可以选择多门课程,一个课程可以包含多个学生(多对多)
不同的关系,在设计表的时候有不同的套路,对应的设计表的套路
- 一对一:
1.把学生和账号,直接放在一个表里!
student (id, name, account, password…)
这种设计方式是下册,尤其是一个系统中包含不同身份角色的时候
2.把学生和账号各自放到一个表里,使用一个额外的 id 来关联
student (studentId, name, accountId)
account (accountId, password)
或
student (studentId, name)
account (accountId, password,studentId)
- 一对多:
方法1:
student (id, name)
1, 张三
2, 李四
3, 王五
class (classId, className, studentList)
1 Java101 1,2
2 Java102 3
方法2:
class (classId, className)
1, java101
2, java102
student (id, name, classId)
1 张三 1
2 李四 1
3 王五 2
因为 MySQL 中没有 " 数组 " 这样的类型,第一种方案是无法实现的(可以用字符串拼接的方式凑合着来实现,但是实际上是不好设计的,比较低效,也失去了数据库对于数据校验的一些能力)
- 多对多:
一般就是采用个中间表,俩表示多对多的关系
student (studentId, name)
1 张三
2 李四
3 王五
course (courseId, courseName)
1 语文
2 数学
3 英语
student_course (studentId, courseId)
1 1 (张三选了语文课)
1 2 (张三选了数学课)
2 1 (李四选了语文课)
数据库设计要点:
找出实体描述清楚实体之间的关系代入固定套路即可
如果需求场景比较简单,很容易理清其中的实体关系
如果需求场景比较复杂,可能涉及到很多实体,会很乱,因此程序猿发明了一个工具 – ER 图(实体 – 关系图)
关联之后,字段名相同是不会有影响的!
mysql> select * from class;
+---------+-----------+
| classId | className |
+---------+-----------+
| 1 | java101 |
| 2 | java102 |
| 3 | java103 |
+---------+-----------+
3 rows in set (0.00 sec)
mysql> select * from student;
+-----------+--------+---------+
| studentId | name | classId |
+-----------+--------+---------+
| 1 | 张三 | 1 |
+-----------+--------+---------+
1 row in set (0.00 sec)
例如这俩张表里都有 classId 但是详细讲就是 class.classId 和 student.classId
🌳三. 新增
- 把查询结果作为新增的数据
insert into 表名1 select 列名 from 表名2;
先执行查询操作,查询出来的结果插入到另外一个表里,保证查询结果的临时表的列要和插入的表的列匹配!!!
- 要求从表名 2 中查询出来的结果的列数和类型 和表名 1 匹配,不要求列名匹配
mysql> create table student (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student values (1,'张三'),(2,'李四'),(3,'王五');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> create table student2 (id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> select * from student;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)
mysql> select * from student2;
Empty set (0.00 sec)
mysql> insert into student2 select * from student;
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from student2;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)
🌴四. 查询
-
聚合查询:
-
通过行和行之间进行的运算处理
表达式查询是列和列之间
🏳️4.1 聚合函数(以下都是聚合查询)
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
这些都属于 SQL 内置函数,SQL 作为一个编程语言,也是内置了一些库函数供我们来使用的
- COUNT函数的使用:
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 7 |
+----------+
1 row in set (0.00 sec)
mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
那么其中使用 * 和 name(列名) 有什么区别呢?
mysql> insert into exam_result values(null, null, null, null, null);
Query OK, 1 row affected (0.00 sec)
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | NULL | NULL | NULL | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.00 sec)
mysql> select count(*) from exam_result;
+----------+
| count(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)
mysql> select count(name) from exam_result;
+-------------+
| count(name) |
+-------------+
| 7 |
+-------------+
1 row in set (0.00 sec)
可以看到我们再添加一个全为空的信息,* 把 NULL 值也记录到行数中了,name(列名) 对于 NULL 不会计数。
注:
count(name) 中间不能带有空格,否则就会出错,SQL 不能被正常解析
- SUM函数的使用:
mysql> select * from exam_result;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | 75.0 | 65.0 | 30.0 |
| NULL | NULL | NULL | NULL | NULL |
+------+-----------+---------+------+---------+
8 rows in set (0.01 sec)
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 581.5 |
+-----------+
1 row in set (0.00 sec)
在我们之前学过,NULL 和其他数字进行算数运算,结果还是 NULL,在这里可以得出结论SUM函数中 NULL 没有参加运算
- 此处聚合查询也是完全可以指定筛选条件的!
mysql> select sum(english) from exam_result where english < 60;
+--------------+
| sum(english) |
+--------------+
| 131.0 |
+--------------+
1 row in set (0.00 sec)
mysql> select sum(english) from exam_result;
+--------------+
| sum(english) |
+--------------+
| 443.5 |
+--------------+
1 row in set (0.00 sec)
对于带有条件的聚合查询,先会按照条件进行筛选,筛选后得到的结果进行聚合
- 对名字进行求和
mysql> select sum(name) from exam_result;
+-----------+
| sum(name) |
+-----------+
| 0 |
+-----------+
1 row in set, 7 warnings (0.00 sec)
名字是字符串无法求和,所以 sum 函数只能对数字进行求和
- AVG函数的使用
mysql> select avg(math) from exam_result;
+-----------+
| avg(math) |
+-----------+
| 83.07143 |
+-----------+
1 row in set (0.00 sec)
此处通过计算也可以得出平均值的计算是不会计入 NULL 值的个数的
- MAX 和 MIN 函数的使用:
mysql> select max(math) from exam_result;
+-----------+
| max(math) |
+-----------+
| 98.5 |
+-----------+
1 row in set (0.00 sec)
mysql> select min(math) from exam_result;
+-----------+
| min(math) |
+-----------+
| 65.0 |
+-----------+
1 row in set (0.00 sec)
🏴4.2 分组查询
- 把表中的若干行,分成好几组,指定某一列作为分组的依据,分组依据的列值相同,则被归为一组,分成多个组之后,还可以针对每个组,分别使用聚合函数。
group by 列
建一张表:
mysql> create table student (id int, name varchar(20), gender varchar(20), score int);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student values (1, '张三', '男', 95);
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (2, '李四', '女', 75);
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (3, '王五', '男', 85);
Query OK, 1 row affected (0.00 sec)
mysql> insert into student values (4, '赵六', '女', 65);
Query OK, 1 row affected (0.00 sec)
mysql> select * from student;
+------+--------+--------+-------+
| id | name | gender | score |
+------+--------+--------+-------+
| 1 | 张三 | 男 | 95 |
| 2 | 李四 | 女 | 75 |
| 3 | 王五 | 男 | 85 |
| 4 | 赵六 | 女 | 65 |
+------+--------+--------+-------+
4 rows in set (0.00 sec)
需要统计,男生和女生分别各自的最高分,平均分,最低分
mysql> select gender, max(score), min(score), avg(score) from student group by gender;
+--------+------------+------------+------------+
| gender | max(score) | min(score) | avg(score) |
+--------+------------+------------+------------+
| 女 | 75 | 65 | 70.0000 |
| 男 | 95 | 85 | 90.0000 |
+--------+------------+------------+------------+
2 rows in set (0.00 sec)
分组规则,是把记录的值相同的行作为一组
在进行聚合查询的时候,也能指定条件筛选
- 1. 在聚合之前,进行筛选,针对筛选后的结果,再聚合。(where 子句)
- 2. 在聚合之后,进行筛选。(having 子句)
- 聚合之前查询:查询每个性别平均分(但是出去赵六同学)
mysql> select gender, avg(score) from student where name != '赵六' group by gender;
+--------+------------+
| gender | avg(score) |
+--------+------------+
| 女 | 75.0000 |
| 男 | 90.0000 |
+--------+------------+
2 rows in set (0.00 sec)
- 聚合之后筛选:查询平均分大于 80 的性别情况,需要先把平均分算出来(算平均分,需要先聚合)
mysql> select gender, avg(score) from student group by gender having avg(score) > 80;
+--------+------------+
| gender | avg(score) |
+--------+------------+
| 男 | 90.0000 |
+--------+------------+
1 row in set (0.00 sec)
- 同时在前面和后面都筛选:查询平均分大于 80 的性别情况(除去赵六)
mysql> select gender, avg(score) from student where name != '赵六' group by gender having avg(score) > 80;
+--------+------------+
| gender | avg(score) |
+--------+------------+
| 男 | 90.0000 |
+--------+------------+
1 row in set (0.00 sec)
聚合查询的执行过程:先按照 where 条件进行筛选记录,把筛选出来的结果按照 group by 来分组,分组之后按照 having 再进行筛选,最后再按照制定列中调用的聚合函数来显示计算结果。
联合查询
- 也叫多表查询,是把多个表的记录合并到一起,综合进行查询
select * from 表1, 表2;
联合查询中的核心概念:笛卡尔积。
笛卡尔积就是把这两个表中的所有记录,进行排列组合,穷举出所有的可能情况
排列组合之后的结果就是笛卡尔积。笛卡尔积的列数就是原来俩张表的列数之和,笛卡尔积的行数就是原来俩张表的行数之和。
针对多个表进行联合查询,本质上就是先针对多个表进行笛卡尔积运算。万一原来的表就很大,再进行多个表的笛卡尔积,就会得到一个更复杂的表,这个过程就会很低效,因此,在实际开发中进行多表查询,一定要克制。
笛卡尔积中包含了大量无效数据,指定了合理的过滤条件,把有效的数据挑出来,这个时候就得到了一个非常有用的数据表,这个过程就是 " 联合查询 " 的过程。
多表查询的一般步骤:
1. 先根据需求理清楚说想要的数据都在哪些表中2. 【核心操作】先针对多个表进行笛卡尔积3. 根据连接条件,筛选出合法数据,过滤掉非法数据4. 进一步增加条件,根据需求做更精细的筛选5. 去掉不必要的列,保留最关注的信息
此处创建四个表:
mysql> create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100));
Query OK, 0 rows affected (0.01 sec)
mysql> create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20), classes_id int);
Query OK, 0 rows affected (0.01 sec)
mysql> create table course (id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> create table score (score decimal(3,1),student_id int, course_id int);
Query OK, 0 rows affected (0.01 sec)
填入数据:
mysql> insert into classes(name, `desc`) values
-> ('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
-> ('中文系2019级3班','学习了中国传统文学'),
-> ('自动化2019级5班','学习了机械自动化');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into student(sn, name, qq_mail, classes_id) values
-> ('09982','黑旋风李逵','xuanfeng@qq.com',1),
-> ('00835','菩提老祖',null,1),
-> ('00391','白素贞',null,1),
-> ('00031','许仙','xuxian@qq.com',1),
-> ('00054','不想毕业',null,1),
-> ('51234','好好说话','say@qq.com',2),
-> ('83223','tellme',null,2),
-> ('09527','老外学中文','foreigner@qq.com',2);
Query OK, 8 rows affected (0.00 sec)
Records: 8 Duplicates: 0 Warnings: 0
mysql> insert into course(name) values
-> ('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
Query OK, 6 rows affected (0.00 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> insert into score(score, student_id, course_id) values
-> -- 黑旋风李逵
-> (70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-> -- 菩提老祖
-> (60, 2, 1),(59.5, 2, 5),
-> -- 白素贞
-> (33, 3, 1),(68, 3, 3),(99, 3, 5),
-> -- 许仙
-> (67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-> -- 不想毕业
-> (81, 5, 1),(37, 5, 5),
-> -- 好好说话
-> (56, 6, 2),(43, 6, 4),(79, 6, 6),
-> -- tellme
-> (80, 7, 2),(92, 7, 6);
Query OK, 20 rows affected (0.00 sec)
Records: 20 Duplicates: 0 Warnings: 0
打印四个表:
mysql> select * from student;
+----+-------+-----------------+------------------+------------+
| id | sn | name | qq_mail | classes_id |
+----+-------+-----------------+------------------+------------+
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 |
| 2 | 00835 | 菩提老祖 | NULL | 1 |
| 3 | 00391 | 白素贞 | NULL | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 |
| 5 | 00054 | 不想毕业 | NULL | 1 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 |
| 7 | 83223 | tellme | NULL | 2 |
| 8 | 09527 | 老外学中文 | foreigner@qq.com | 2 |
+----+-------+-----------------+------------------+------------+
8 rows in set (0.00 sec)
mysql> select * from classes;
+----+-------------------------+-------------------------------------------------------------------+
| id | name | desc |
+----+-------------------------+-------------------------------------------------------------------+
| 1 | 计算机系2019级1班 | 学习了计算机原理、C和Java语言、数据结构和算法 |
| 2 | 中文系2019级3班 | 学习了中国传统文学 |
| 3 | 自动化2019级5班 | 学习了机械自动化 |
+----+-------------------------+-------------------------------------------------------------------+
3 rows in set (0.00 sec)
mysql> select * from score;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 70.5 | 1 | 1 |
| 98.5 | 1 | 3 |
| 33.0 | 1 | 5 |
| 98.0 | 1 | 6 |
| 60.0 | 2 | 1 |
| 59.5 | 2 | 5 |
| 33.0 | 3 | 1 |
| 68.0 | 3 | 3 |
| 99.0 | 3 | 5 |
| 67.0 | 4 | 1 |
| 23.0 | 4 | 3 |
| 56.0 | 4 | 5 |
| 72.0 | 4 | 6 |
| 81.0 | 5 | 1 |
| 37.0 | 5 | 5 |
| 56.0 | 6 | 2 |
| 43.0 | 6 | 4 |
| 79.0 | 6 | 6 |
| 80.0 | 7 | 2 |
| 92.0 | 7 | 6 |
+-------+------------+-----------+
20 rows in set (0.00 sec)
mysql> select * from course;
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 3 | 计算机原理 |
| 4 | 语文 |
| 5 | 高阶数学 |
| 6 | 英文 |
+----+--------------------+
6 rows in set (0.00 sec)
🏁4.3 内连接(以下都是联合查询)
- select 列名 from 表1,表2…;
- select 列名 from 表1 inner join 表2…;
①:目标:查询 “ 许仙 ” 同学的 成绩:
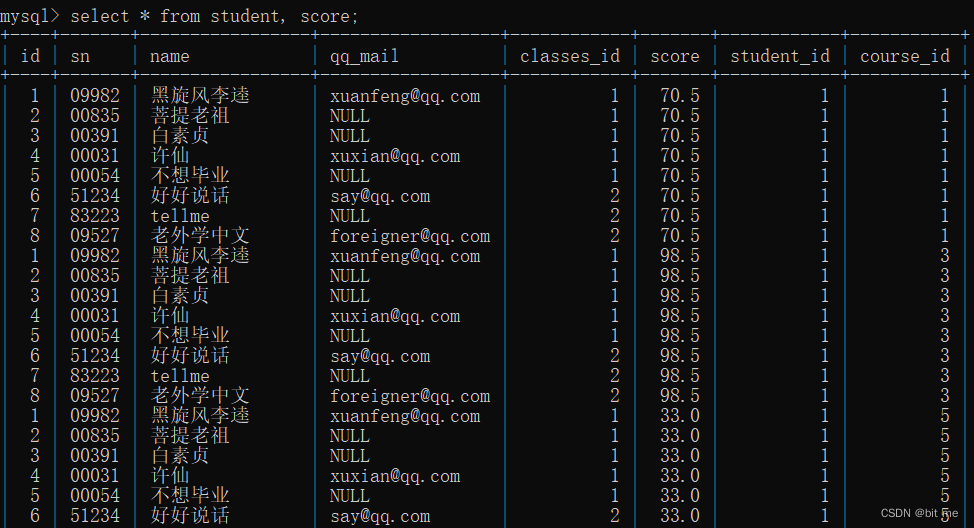
在这里提及一下为什么不用代码的形式,根据笛卡尔积行数是由两个表的行数之积得来的,成绩表和学生表行数相乘 160 行代码太长,因此截图省略位置。
其中 160 行代码大部分是无用数据,清理掉即可
mysql> select * from student, score where student.id = score.student_id;
+----+-------+-----------------+-----------------+------------+-------+------------+-----------+
| id | sn | name | qq_mail | classes_id | score | student_id | course_id |
+----+-------+-----------------+-----------------+------------+-------+------------+-----------+
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 70.5 | 1 | 1 |
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 98.5 | 1 | 3 |
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 33.0 | 1 | 5 |
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 98.0 | 1 | 6 |
| 2 | 00835 | 菩提老祖 | NULL | 1 | 60.0 | 2 | 1 |
| 2 | 00835 | 菩提老祖 | NULL | 1 | 59.5 | 2 | 5 |
| 3 | 00391 | 白素贞 | NULL | 1 | 33.0 | 3 | 1 |
| 3 | 00391 | 白素贞 | NULL | 1 | 68.0 | 3 | 3 |
| 3 | 00391 | 白素贞 | NULL | 1 | 99.0 | 3 | 5 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 67.0 | 4 | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 23.0 | 4 | 3 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 56.0 | 4 | 5 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 72.0 | 4 | 6 |
| 5 | 00054 | 不想毕业 | NULL | 1 | 81.0 | 5 | 1 |
| 5 | 00054 | 不想毕业 | NULL | 1 | 37.0 | 5 | 5 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 56.0 | 6 | 2 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 43.0 | 6 | 4 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 79.0 | 6 | 6 |
| 7 | 83223 | tellme | NULL | 2 | 80.0 | 7 | 2 |
| 7 | 83223 | tellme | NULL | 2 | 92.0 | 7 | 6 |
+----+-------+-----------------+-----------------+------------+-------+------------+-----------+
20 rows in set (0.00 sec)
就只剩下同学的各科成绩,再对 “ 许仙 ” 进行筛选:
mysql> select * from student, score where student.id = score.student_id and student.name = '许仙';
+----+-------+--------+---------------+------------+-------+------------+-----------+
| id | sn | name | qq_mail | classes_id | score | student_id | course_id |
+----+-------+--------+---------------+------------+-------+------------+-----------+
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 67.0 | 4 | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 23.0 | 4 | 3 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 56.0 | 4 | 5 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 72.0 | 4 | 6 |
+----+-------+--------+---------------+------------+-------+------------+-----------+
4 rows in set (0.00 sec)
最后只需要过滤掉不必要的列:
mysql> select name, course_id, score from student, score where student.id = score.student_id and student.name = '许仙';
+--------+-----------+-------+
| name | course_id | score |
+--------+-----------+-------+
| 许仙 | 1 | 67.0 |
| 许仙 | 3 | 23.0 |
| 许仙 | 5 | 56.0 |
| 许仙 | 6 | 72.0 |
+--------+-----------+-------+
4 rows in set (0.00 sec)
一张清晰完整的结果就呈现在我们眼前。
通过 select 列名 from 表1, 表2 这种方式可以进行多表查询,除此之外,还有另外一种写法: select 列名 from 表1 join 表2 on 连接条件; (当使用 join 计算笛卡尔积的时候,后面的条件使用 on 来表示,而不是 where ,这个相当于 " 固定搭配 ")
mysql> select * from student join score on student.id = score.student_id and student.name = '许仙';
+----+-------+--------+---------------+------------+-------+------------+-----------+
| id | sn | name | qq_mail | classes_id | score | student_id | course_id |
+----+-------+--------+---------------+------------+-------+------------+-----------+
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 67.0 | 4 | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 23.0 | 4 | 3 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 56.0 | 4 | 5 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 72.0 | 4 | 6 |
+----+-------+--------+---------------+------------+-------+------------+-----------+
4 rows in set (0.00 sec)
mysql> select student.name, score.course_id, score.score from student join score on student.id = score.student_id and student.name = '许仙';
+--------+-----------+-------+
| name | course_id | score |
+--------+-----------+-------+
| 许仙 | 1 | 67.0 |
| 许仙 | 3 | 23.0 |
| 许仙 | 5 | 56.0 |
| 许仙 | 6 | 72.0 |
+--------+-----------+-------+
4 rows in set (0.00 sec)
既然存在了 from 多个表,那为什么还要引入 join on 出来呢?join on 默认情况下的行为和 from 多个表是一致的,但是 join on 还能延伸出一些其他的用法,功能比 from 多个表更广泛了
多张表的情况下:
select student.name score.course_id, score.score from student join score join classes;
join 多个表之后,最后来个 on 同意筛选条件就可以了
②:查询所有同学的总成绩,及同学的个人信息:
在我们上文已经写出了 160 行代码过滤后的每个人总成绩,在这里针对行和行之间的计算,就需要使用聚合查询,不能说一提到总成绩就想到表达式查询,要根据实际的表结构,见招拆招。
mysql> select * from student, score where student.id = score.student_id group by id;
+----+-------+-----------------+-----------------+------------+-------+------------+-----------+
| id | sn | name | qq_mail | classes_id | score | student_id | course_id |
+----+-------+-----------------+-----------------+------------+-------+------------+-----------+
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 70.5 | 1 | 1 |
| 2 | 00835 | 菩提老祖 | NULL | 1 | 60.0 | 2 | 1 |
| 3 | 00391 | 白素贞 | NULL | 1 | 33.0 | 3 | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 67.0 | 4 | 1 |
| 5 | 00054 | 不想毕业 | NULL | 1 | 81.0 | 5 | 1 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 56.0 | 6 | 2 |
| 7 | 83223 | tellme | NULL | 2 | 80.0 | 7 | 2 |
+----+-------+-----------------+-----------------+------------+-------+------------+-----------+
7 rows in set (0.00 sec)
在不使用聚合函数的情况下,后面这部分显示出来的结果,相当于每个分组中的第一条记录
总成绩:
mysql> select student.name, sum(score.score) from student, score where student.id = score.student_id group by id;
+-----------------+------------------+
| name | sum(score.score) |
+-----------------+------------------+
| 黑旋风李逵 | 300.0 |
| 菩提老祖 | 119.5 |
| 白素贞 | 200.0 |
| 许仙 | 218.0 |
| 不想毕业 | 118.0 |
| 好好说话 | 178.0 |
| tellme | 172.0 |
+-----------------+------------------+
7 rows in set (0.00 sec)
还可以指定别名
mysql> select student.name, sum(score.score) as total from student, score where student.id = score.student_id group by id;
+-----------------+-------+
| name | total |
+-----------------+-------+
| 黑旋风李逵 | 300.0 |
| 菩提老祖 | 119.5 |
| 白素贞 | 200.0 |
| 许仙 | 218.0 |
| 不想毕业 | 118.0 |
| 好好说话 | 178.0 |
| tellme | 172.0 |
+-----------------+-------+
7 rows in set (0.00 sec)
③:查询每个同学姓名,课程名,分数
mysql> select * from student, course, score where student.id = score.student_id and course.id = score.course_id;
+----+-------+-----------------+-----------------+------------+----+--------------------+-------+------------+-----------+
| id | sn | name | qq_mail | classes_id | id | name | score | student_id | course_id |
+----+-------+-----------------+-----------------+------------+----+--------------------+-------+------------+-----------+
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 1 | Java | 70.5 | 1 | 1 |
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 3 | 计算机原理 | 98.5 | 1 | 3 |
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 5 | 高阶数学 | 33.0 | 1 | 5 |
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 | 6 | 英文 | 98.0 | 1 | 6 |
| 2 | 00835 | 菩提老祖 | NULL | 1 | 1 | Java | 60.0 | 2 | 1 |
| 2 | 00835 | 菩提老祖 | NULL | 1 | 5 | 高阶数学 | 59.5 | 2 | 5 |
| 3 | 00391 | 白素贞 | NULL | 1 | 1 | Java | 33.0 | 3 | 1 |
| 3 | 00391 | 白素贞 | NULL | 1 | 3 | 计算机原理 | 68.0 | 3 | 3 |
| 3 | 00391 | 白素贞 | NULL | 1 | 5 | 高阶数学 | 99.0 | 3 | 5 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 1 | Java | 67.0 | 4 | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 3 | 计算机原理 | 23.0 | 4 | 3 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 5 | 高阶数学 | 56.0 | 4 | 5 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 | 6 | 英文 | 72.0 | 4 | 6 |
| 5 | 00054 | 不想毕业 | NULL | 1 | 1 | Java | 81.0 | 5 | 1 |
| 5 | 00054 | 不想毕业 | NULL | 1 | 5 | 高阶数学 | 37.0 | 5 | 5 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 2 | 中国传统文化 | 56.0 | 6 | 2 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 4 | 语文 | 43.0 | 6 | 4 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 | 6 | 英文 | 79.0 | 6 | 6 |
| 7 | 83223 | tellme | NULL | 2 | 2 | 中国传统文化 | 80.0 | 7 | 2 |
| 7 | 83223 | tellme | NULL | 2 | 6 | 英文 | 92.0 | 7 | 6 |
+----+-------+-----------------+-----------------+------------+----+--------------------+-------+------------+-----------+
20 rows in set (0.00 sec)
mysql> select student.name, course.name, score.score from student, course, score where student.id = score.student_id and course.id = score.course_id;
+-----------------+--------------------+-------+
| name | name | score |
+-----------------+--------------------+-------+
| 黑旋风李逵 | Java | 70.5 |
| 黑旋风李逵 | 计算机原理 | 98.5 |
| 黑旋风李逵 | 高阶数学 | 33.0 |
| 黑旋风李逵 | 英文 | 98.0 |
| 菩提老祖 | Java | 60.0 |
| 菩提老祖 | 高阶数学 | 59.5 |
| 白素贞 | Java | 33.0 |
| 白素贞 | 计算机原理 | 68.0 |
| 白素贞 | 高阶数学 | 99.0 |
| 许仙 | Java | 67.0 |
| 许仙 | 计算机原理 | 23.0 |
| 许仙 | 高阶数学 | 56.0 |
| 许仙 | 英文 | 72.0 |
| 不想毕业 | Java | 81.0 |
| 不想毕业 | 高阶数学 | 37.0 |
| 好好说话 | 中国传统文化 | 56.0 |
| 好好说话 | 语文 | 43.0 |
| 好好说话 | 英文 | 79.0 |
| tellme | 中国传统文化 | 80.0 |
| tellme | 英文 | 92.0 |
+-----------------+--------------------+-------+
20 rows in set (0.00 sec)
🚩4.4 外连接
- select 列名 from 表1 left join 表2; 左外连接
- select 列名 from 表1 right join 表2; 右外连接
如果两张表里的数据是对应的,此时外连接和内连接看起来没区别,如果数据不对应,外连接和内连接的区别就明显了
制作一个表格:
mysql> create table student2(id int, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> create table score2(id int, score int);
Query OK, 0 rows affected (0.01 sec)
mysql> insert into student2 values(1, '张三'), (2, '李四'), (3, '王五');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into score2 values(1, 90), (2, 80), (3, 70);
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from student2;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)
mysql> select * from score2;
+------+-------+
| id | score |
+------+-------+
| 1 | 90 |
| 2 | 80 |
| 3 | 70 |
+------+-------+
3 rows in set (0.00 sec)
mysql> select name, score from student2 join score2 on student2.id = score2.id;
+--------+-------+
| name | score |
+--------+-------+
| 张三 | 90 |
| 李四 | 80 |
| 王五 | 70 |
+--------+-------+
3 rows in set (0.00 sec)
左右对比:(如果两个表数据记录都是一一对应的,此时内连接和外连接没有区别)
mysql> select name, score from student2 left join score2 on student2.id = score2.id;
+--------+-------+
| name | score |
+--------+-------+
| 张三 | 90 |
| 李四 | 80 |
| 王五 | 70 |
+--------+-------+
3 rows in set (0.00 sec)
mysql> select name, score from student2 right join score2 on student2.id = score2.id;
+--------+-------+
| name | score |
+--------+-------+
| 张三 | 90 |
| 李四 | 80 |
| 王五 | 70 |
+--------+-------+
3 rows in set (0.00 sec)
对成绩序号进行修改,出现 id 4 无人对应,王五没有对应的成绩
mysql> update score2 set id = 4 where score = 70;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from score2;
+------+-------+
| id | score |
+------+-------+
| 1 | 90 |
| 2 | 80 |
| 4 | 70 |
+------+-------+
3 rows in set (0.00 sec)
mysql> select * from student2;
+------+--------+
| id | name |
+------+--------+
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
+------+--------+
3 rows in set (0.00 sec)
从学生表的角度看,王五同学没有分数
从分数表的角度看,4 号同学没有身份信息
内连接产生的结果,是两张表都包含的数据
mysql> select name, score from student2 join score2 on student2.id = score2.id;
+--------+-------+
| name | score |
+--------+-------+
| 张三 | 90 |
| 李四 | 80 |
+--------+-------+
2 rows in set (0.00 sec)
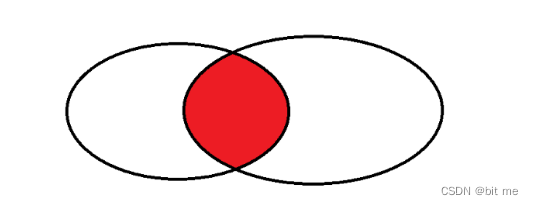
左外连接,就是以 join 左侧的表为主,保证左侧的表的每个记录都能体现在结果中,如果左侧的记录在右侧表中不存在,则填充 NULL。
mysql> select name, score from student2 left join score2 on student2.id = score2.id;
+--------+-------+
| name | score |
+--------+-------+
| 张三 | 90 |
| 李四 | 80 |
| 王五 | NULL |
+--------+-------+
3 rows in set (0.00 sec)
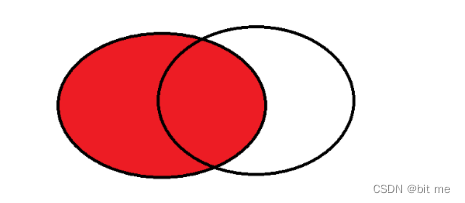
右外连接,就是以 join 右侧的表为主,保证右侧的表每个记录都能体现在结果中,如果右侧的记录在左侧不存在,则填充 NULL。
mysql> select name, score from student2 right join score2 on student2.id = score2.id;
+--------+-------+
| name | score |
+--------+-------+
| 张三 | 90 |
| 李四 | 80 |
| NULL | 70 |
+--------+-------+
3 rows in set (0.00 sec)
综上来看,是否存在一种外连接,可以把整个全集都获取到呢?
答案是有的,全外连接,但是 MySQL 不支持全外连接
🏳️🌈4.5 自连接
- 自己和自己进行连接,同一张表和自己进行笛卡尔积
SQL 里面指定条件筛选,都是按照列和列之间进行筛选,难以进行行和行之间筛选,自连接操作能把行转化为列
- 显示所有 " 计算机原理 " 成绩比 " Java " 成绩高的成绩信息
mysql> select * from course;
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 3 | 计算机原理 |
| 4 | 语文 |
| 5 | 高阶数学 |
| 6 | 英文 |
+----+--------------------+
6 rows in set (0.00 sec)
course_id 1 和 course_id 3的比较
mysql> select * from score;
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 70.5 | 1 | 1 |
| 98.5 | 1 | 3 |
| 33.0 | 1 | 5 |
| 98.0 | 1 | 6 |
| 60.0 | 2 | 1 |
| 59.5 | 2 | 5 |
| 33.0 | 3 | 1 |
| 68.0 | 3 | 3 |
| 99.0 | 3 | 5 |
| 67.0 | 4 | 1 |
| 23.0 | 4 | 3 |
| 56.0 | 4 | 5 |
| 72.0 | 4 | 6 |
| 81.0 | 5 | 1 |
| 37.0 | 5 | 5 |
| 56.0 | 6 | 2 |
| 43.0 | 6 | 4 |
| 79.0 | 6 | 6 |
| 80.0 | 7 | 2 |
| 92.0 | 7 | 6 |
+-------+------------+-----------+
20 rows in set (0.00 sec)
SQL 中无法实现行和行之间的比较!行和行不能直接比较,转换成列和列,自连接就可以做到这一点
mysql> select * from score,score;
ERROR 1066 (42000): Not unique table/alias: 'score'
可以看到出现了错误,因为自连接的情况下,必须给表起别名了
但是此处笛卡尔积数据太多了,需要过滤掉不合理的数据,保留关注的合法数据
我们的需求是找到哪个同学的 3 号课程比 1 号课程高
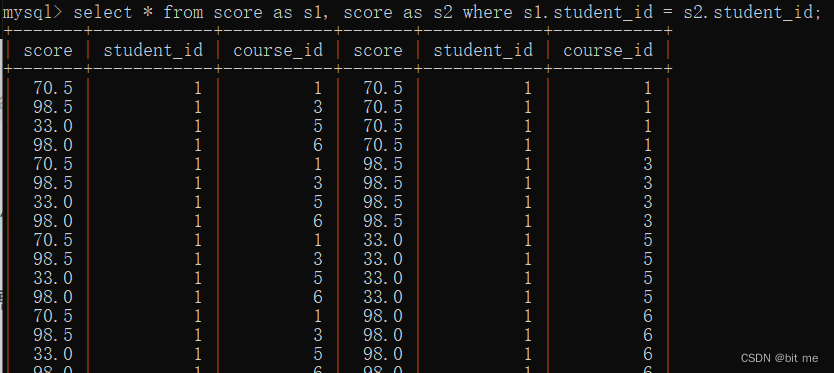
当学生 id 对齐之后,发现课程 id 仍在排列组合
mysql> select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1;
+-------+------------+-----------+-------+------------+-----------+
| score | student_id | course_id | score | student_id | course_id |
+-------+------------+-----------+-------+------------+-----------+
| 98.5 | 1 | 3 | 70.5 | 1 | 1 |
| 68.0 | 3 | 3 | 33.0 | 3 | 1 |
| 23.0 | 4 | 3 | 67.0 | 4 | 1 |
+-------+------------+-----------+-------+------------+-----------+
3 rows in set (0.00 sec)
此时表里剩下的数据就是左侧都为 3 的课程分数,右侧就都是为 1 的课程分数
mysql> select * from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;
+-------+------------+-----------+-------+------------+-----------+
| score | student_id | course_id | score | student_id | course_id |
+-------+------------+-----------+-------+------------+-----------+
| 98.5 | 1 | 3 | 70.5 | 1 | 1 |
| 68.0 | 3 | 3 | 33.0 | 3 | 1 |
+-------+------------+-----------+-------+------------+-----------+
2 rows in set (0.00 sec)
加个课程 3 大于课程 1 的条件
mysql> select s1.student_id from score as s1, score as s2 where s1.student_id = s2.student_id and s1.course_id = 3 and s2.course_id = 1 and s1.score > s2.score;
+------------+
| student_id |
+------------+
| 1 |
| 3 |
+------------+
2 rows in set (0.00 sec)
更加精准把 id 列单独列出来,结果就是学生 1 和 学生 3 的成绩数据符合
🏴☠️4.6 子查询
- 子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:返回一行记录的子查询
查询与“不想毕业” 同学的同班同学:
- 先根据名字获取到班级 id
- 根据班级 id 查询 id 匹配同学
mysql> select * from student;
+----+-------+-----------------+------------------+------------+
| id | sn | name | qq_mail | classes_id |
+----+-------+-----------------+------------------+------------+
| 1 | 09982 | 黑旋风李逵 | xuanfeng@qq.com | 1 |
| 2 | 00835 | 菩提老祖 | NULL | 1 |
| 3 | 00391 | 白素贞 | NULL | 1 |
| 4 | 00031 | 许仙 | xuxian@qq.com | 1 |
| 5 | 00054 | 不想毕业 | NULL | 1 |
| 6 | 51234 | 好好说话 | say@qq.com | 2 |
| 7 | 83223 | tellme | NULL | 2 |
| 8 | 09527 | 老外学中文 | foreigner@qq.com | 2 |
+----+-------+-----------------+------------------+------------+
8 rows in set (0.00 sec)
mysql> select classes_id from student where name = '不想毕业';
+------------+
| classes_id |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
mysql> select name from student where classes_id = 1;
+-----------------+
| name |
+-----------------+
| 黑旋风李逵 |
| 菩提老祖 |
| 白素贞 |
| 许仙 |
| 不想毕业 |
+-----------------+
5 rows in set (0.00 sec)
把这俩 SQL 一合并就成了一个子查询了
mysql> select name from student where classes_id = (select classes_id from student where name = '不想毕业');
+-----------------+
| name |
+-----------------+
| 黑旋风李逵 |
| 菩提老祖 |
| 白素贞 |
| 许仙 |
| 不想毕业 |
+-----------------+
5 rows in set (0.00 sec)
此处的子查询,可以任意级别的嵌套,N 个 SQL 组合成了一个巨无霸 SQL
多行子查询:返回多行记录的子查询
查询“语文”或“英文”课程的成绩信息:
- 先根据课程名,直到课程的 id
- 拿着课程的 id 去分数表里进行查询
mysql> select * from course;
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 3 | 计算机原理 |
| 4 | 语文 |
| 5 | 高阶数学 |
| 6 | 英文 |
+----+--------------------+
6 rows in set (0.00 sec)
mysql> select id from course where name = '语文' or name = '英文';
+----+
| id |
+----+
| 4 |
| 6 |
+----+
2 rows in set (0.00 sec)
mysql> select * from score where course_id in (select id from course where name = '语文' or name = '英文');
+-------+------------+-----------+
| score | student_id | course_id |
+-------+------------+-----------+
| 98.0 | 1 | 6 |
| 72.0 | 4 | 6 |
| 43.0 | 6 | 4 |
| 79.0 | 6 | 6 |
| 92.0 | 7 | 6 |
+-------+------------+-----------+
5 rows in set (0.00 sec)
🏳️⚧️4.7 合并查询
- 把两个查询结果,结果集合,合并到一起
可以使用集合操作符 union,union all。使用 UNION 和 UNION ALL 时,前后查询的结果集中,字段需要一致。
- union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
查询id小于3,或者名字为“英文”的课程:
mysql> select * from course where id < 3 or name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)
mysql> select * from course where id < 3 union select * from course where name = '英文';
+----+--------------------+
| id | name |
+----+--------------------+
| 1 | Java |
| 2 | 中国传统文化 |
| 6 | 英文 |
+----+--------------------+
3 rows in set (0.00 sec)
- union all
和 union 的唯一区别就是 union 操作如果有重复记录,会去重,union all 不会去重
SQL查询中各个关键字的执行先后顺序: from > on> join > where > group by > with > having >select > distinct > order by > limit