文章目录
- 一、箭头函数
- 二、函数名
- 三、理解参数
- 3.1 箭头函数中的参数
- 四、没有重载
- 五、默认参数值
- 5.1 默认参数作用域与暂时性死区
- 六、参数扩展与收集
- 6.1 扩展参数
- 6.2 收集参数
- 七、函数声明与函数表达式
- 八、函数作为值
- 九、函数内部
- 9.1 arguments
- 9.2 this
- 9.3 caller
- 9.4 new.target
- 十、函数属性与方法(apply、call、bind)
- 十一、函数表达式
- 十二、递归
- 十三、尾调用优化
- 13.1 尾调用优化的条件
- 13.2 尾调用优化的代码
- 十四、闭包
- 14.1 this 对象
- 14.2 内存泄漏
- 十五、立即调用的函数表达式
- 十六、私有变量
- 16.1 静态私有变量
- 16.2 模块模式
- 16.3 模块增强模式
- 十七、小结
函数是 ECMAScript 中最有意思的部分之一,这主要是因为函数实际上是对象。每个函数都是Function 类型的实例,而 Function 也有属性和方法,跟其他引用类型一样。因为函数是对象,所以函数名就是指向函数对象的指针,而且不一定与函数本身紧密绑定。函数通常以函数声明的方式定义,比如:
function sum (num1, num2) {
return num1 + num2;
}
注意:函数定义最后没有加分号。
另一种定义函数的语法是函数表达式。函数表达式与函数声明几乎是等价的:
let sum = function(num1, num2) {
return num1 + num2;
};
这里,代码定义了一个变量 sum 并将其初始化为一个函数。注意 function 关键字后面没有名称,因为不需要。这个函数可以通过变量 sum 来引用。
注意:这里的函数末尾是有分号的,与任何变量初始化语句一样。
还有一种定义函数的方式与函数表达式很像,叫作“箭头函数”(arrow function),如下所示:
let sum = (num1, num2) => {
return num1 + num2;
};
最后一种定义函数的方式是使用 Function 构造函数。这个构造函数接收任意多个字符串参数,最后一个参数始终会被当成函数体,而之前的参数都是新函数的参数。来看下面的例子:
let sum = new Function("num1", "num2", "return num1 + num2"); // 不推荐
我们不推荐使用这种语法来定义函数,因为这段代码会被解释两次:第一次是将它当作常规
ECMAScript 代码,第二次是解释传给构造函数的字符串。这显然会影响性能。不过,把函数想象为对象,把函数名想象为指针是很重要的。而上面这种语法很好地诠释了这些概念。
注意:这几种实例化函数对象的方式之间存在微妙但重要的差别,本章后面会讨论。无论如何,通过其中任何一种方式都可以创建函数。
一、箭头函数
ECMAScript 6 新增了使用胖箭头(=>)语法定义函数表达式的能力。很大程度上,箭头函数实例化的函数对象与正式的函数表达式创建的函数对象行为是相同的。任何可以使用函数表达式的地方,都可以使用箭头函数:
const arrowSum = (a, b) => {
return a + b
}
const functionExpressionSum = function (a, b) {
return a + b
}
console.log(arrowSum(5, 8)) // 13
console.log(functionExpressionSum(5, 8)) // 13
箭头函数简洁的语法非常适合嵌入函数的场景:
const ints = [1, 2, 3]
console.log(
ints.map(function (i) {
return i + 1
})
) // [2, 3, 4]
console.log(
ints.map((i) => {
return i + 1
})
) // [2, 3, 4]
如果只有一个参数,那也可以不用括号。只有没有参数,或者多个参数的情况下,才需要使用括号:
let double = (x) => { return 2 * x; };
let triple = x => { return 3 * x; };
// 没有参数需要括号
let getRandom = () => { return Math.random(); };
// 多个参数需要括号
let sum = (a, b) => { return a + b; };
// 无效的写法:
let multiply = a, b => { return a * b; };
箭头函数也可以不用大括号,但这样会改变函数的行为。使用大括号就说明包含“函数体”,可以在一个函数中包含多条语句,跟常规的函数一样。如果不使用大括号,那么箭头后面就只能有一行代码,比如一个赋值操作,或者一个表达式。而且,省略大括号会隐式返回这行代码的值:
// 以下两种写法都有效,而且返回相应的值
let double = (x) => { return 2 * x; };
let triple = (x) => 3 * x;
// 可以赋值
let value = {};
let setName = (x) => x.name = "Matt";
setName(value);
console.log(value.name); // "Matt"
// 无效的写法:
let multiply = (a, b) => return a * b;
箭头函数虽然语法简洁,但也有很多场合不适用。箭头函数不能使用 arguments、super 和new.target,也不能用作构造函数。此外,箭头函数也没有 prototype 属性。
二、函数名
因为函数名就是指向函数的指针,所以它们跟其他包含对象指针的变量具有相同的行为。这意味着一个函数可以有多个名称,如下所示:
function sum (num1, num2) {
return num1 + num2
}
console.log(sum(10, 10)) // 20
const anotherSum = sum
console.log(anotherSum(10, 10)) // 20
sum = null
console.log(anotherSum(10, 10)) // 20
以上代码定义了一个名为 sum() 的函数,用于求两个数之和。然后又声明了一个变量 anotherSum,并将它的值设置为等于 sum。注意,使用不带括号的函数名会访问函数指针,而不会执行函数。此时,anotherSum 和 sum 都指向同一个函数。调用 anotherSum() 也可以返回结果。把 sum 设置为 null 之后,就切断了它与函数之间的关联。而 anotherSum() 还是可以照常调用,没有问题。
ECMAScript 6 的所有函数对象都会暴露一个只读的 name 属性,其中包含关于函数的信息。多数情况下,这个属性中保存的就是一个函数标识符,或者说是一个字符串化的变量名。即使函数没有名称,也会如实显示成空字符串。如果它是使用 Function 构造函数创建的,则会标识成"anonymous":
function foo () {}
const bar = function () {}
const baz = () => {}
console.log(foo.name) // foo
console.log(bar.name) // bar
console.log(baz.name) // baz
console.log((() => {}).name) // (空字符串)
console.log(new Function().name) // anonymous
如果函数是一个获取函数、设置函数,或者使用 bind() 实例化,那么标识符前面会加上一个前缀:
function foo () {}
console.log(foo.bind(null).name) // bound foo
const dog = {
years: 1,
get age () {
return this.years
},
set age (newAge) {
this.years = newAge
}
}
const propertyDescriptor = Object.getOwnPropertyDescriptor(dog, 'age')
console.log(propertyDescriptor.get.name) // get age
console.log(propertyDescriptor.set.name) // set age
三、理解参数
ECMAScript 函数的参数跟大多数其他语言不同。ECMAScript 函数既不关心传入的参数个数,也不关心这些参数的数据类型。定义函数时要接收两个参数,并不意味着调用时就传两个参数。你可以传一个、三个,甚至一个也不传,解释器都不会报错。
之所以会这样,主要是因为 ECMAScript 函数的参数在内部表现为一个数组。函数被调用时总会接收一个数组,但函数并不关心这个数组中包含什么。如果数组中什么也没有,那没问题;如果数组的元素超出了要求,那也没问题。事实上,在使用 function 关键字定义(非箭头)函数时,可以在函数内部访问 arguments 对象,从中取得传进来的每个参数值。
arguments 对象是一个类数组对象(但不是 Array 的实例),因此可以使用中括号语法访问其中的元素(第一个参数是 arguments[0],第二个参数是 arguments[1] )。而要确定传进来多少个参数,可以访问 arguments.length 属性。
在下面的例子中,sayHi() 函数的第一个参数叫 name:
function sayHi (name, message) {
console.log('Hello ' + name + ', ' + message)
}
可以通过 arguments[0] 取得相同的参数值。因此,把函数重写成不声明参数也可以:
function sayHi () {
console.log('Hello ' + arguments[0] + ', ' + arguments[1])
}
在重写后的代码中,没有命名参数。name 和 message 参数都不见了,但函数照样可以调用。这就表明,ECMAScript 函数的参数只是为了方便才写出来的,并不是必须写出来的。与其他语言不同,在 ECMAScript 中的命名参数不会创建让之后的调用必须匹配的函数签名。这是因为根本不存在验证命名参数的机制。
也可以通过 arguments 对象的 length 属性检查传入的参数个数。下面的例子展示了在每调用一个函数时,都会打印出传入的参数个数:
function howManyArgs () {
console.log(arguments.length)
}
howManyArgs('string', 45) // 2
howManyArgs() // 0
howManyArgs(12) // 1
这个例子分别打印出 2、0 和 1(按顺序)。既然如此,那么开发者可以想传多少参数就传多少参数。比如:
function doAdd () {
if (arguments.length === 1) {
console.log(arguments[0] + 10)
} else if (arguments.length === 2) {
console.log(arguments[0] + arguments[1])
}
}
doAdd(10) // 20
doAdd(30, 20) // 50
这个函数 doAdd() 在只传一个参数时会加 10,在传两个参数时会将它们相加,然后返回。因此doAdd(10) 返回 20,而 doAdd(30,20) 返回 50。虽然不像真正的函数重载那么明确,但这已经足以弥补 ECMAScript 在这方面的缺失了。
还有一个必须理解的重要方面,那就是 arguments 对象可以跟命名参数一起使用,比如:
function doAdd (num1, num2) {
if (arguments.length === 1) {
console.log(num1 + 10)
} else if (arguments.length === 2) {
console.log(arguments[0] + num2)
}
}
在这个 doAdd() 函数中,同时使用了两个命名参数和 arguments 对象。命名参数 num1 保存着与 arugments[0] 一样的值,因此使用谁都无所谓。(同样,num2 也保存着跟 arguments[1] 一样的值。)
arguments 对象的另一个有意思的地方就是,它的值始终会与对应的命名参数同步。来看下面的例子:
function doAdd (num1, num2) {
arguments[1] = 10
console.log(arguments[0] + num2)
}
doAdd(1, 2) // 11
这个 doAdd() 函数把第二个参数的值重写为 10。因为 arguments 对象的值会自动同步到对应的命名参数,所以修改 arguments[1] 也会修改 num2 的值,因此两者的值都是 10。但这并不意味着它们都访问同一个内存地址,它们在内存中还是分开的,只不过会保持同步而已。另外还要记住一点:如果只传了一个参数,然后把 arguments[1] 设置为某个值,那么这个值并不会反映到第二个命名参数。这是因为 arguments 对象的长度是根据传入的参数个数,而非定义函数时给出的命名参数个数确定的。
对于命名参数而言,如果调用函数时没有传这个参数,那么它的值就是 undefined。这就类似于定义了变量而没有初始化。比如,如果只给 doAdd() 传了一个参数,那么 num2 的值就是 undefined。
严格模式下,arguments 会有一些变化。首先,像前面那样给 arguments[1] 赋值不会再影响 num2 的值。就算把 arguments[1] 设置为 10,num2 的值仍然还是传入的值。其次,在函数中尝试重写 arguments 对象会导致语法错误。(代码也不会执行。)
3.1 箭头函数中的参数
如果函数是使用箭头语法定义的,那么传给函数的参数将不能使用 arguments 关键字访问,而只能通过定义的命名参数访问。
function foo () {
console.log(arguments[0])
}
foo(5) // 5
const bar = () => {
console.log(arguments[0])
}
bar(5) // ReferenceError: arguments is not defined
虽然箭头函数中没有 arguments 对象,但可以在包装函数中把它提供给箭头函数:
function foo () {
const bar = () => {
console.log(arguments[0]) // 5
}
bar()
}
foo(5)
注意 ECMAScript 中的所有参数都按值传递的。不可能按引用传递参数。如果把对象作为参数传递,那么传递的值就是这个对象的引用。
四、没有重载
ECMAScript 函数不能像传统编程那样重载【函数重载是指在同一个作用域内,有多个函数名相同,但是形参列表不同(参数类型不同,参数个数不同,参数顺序不同),返回值无关,我们将这种叫做重载函数】。在其他语言比如 Java 中,一个函数可以有两个定义,只要签名(接收参数的类型和数量)不同就行。如前所述,ECMAScript 函数没有签名,因为参数是由包含零个或多个值的数组表示的。没有函数签名,自然也就没有重载。
如果在 ECMAScript 中定义了两个同名函数,则后定义的会覆盖先定义的。来看下面的例子:
function addSomeNumber (num) {
return num + 100
}
function addSomeNumber (num) {
return num + 200
}
const result = addSomeNumber(100) // 300
这里,函数 addSomeNumber() 被定义了两次。第一个版本给参数加 100,第二个版本加 200。最后一行调用这个函数时,返回了 300,因为第二个定义覆盖了第一个定义。
前面也提到过,可以通过检查参数的类型和数量,然后分别执行不同的逻辑来模拟函数重载。
把函数名当成指针也有助于理解为什么 ECMAScript 没有函数重载。在前面的例子中,定义两个同名的函数显然会导致后定义的重写先定义的。而那个例子几乎跟下面这个是一样的:
let addSomeNumber = function (num) {
return num + 100
}
addSomeNumber = function (num) {
return num + 200
}
const result = addSomeNumber(100) // 300
看这段代码应该更容易理解发生了什么。在创建第二个函数时,变量 addSomeNumber 被重写成保存第二个函数对象了。
五、默认参数值
在 ECMAScript5.1 及以前,实现默认参数的一种常用方式就是检测某个参数是否等于 undefined,如果是则意味着没有传这个参数,那就给它赋一个值:
function makeKing (name) {
name = typeof name !== 'undefined' ? name : 'Henry'
return `King ${name} VIII`
}
console.log(makeKing()) // 'King Henry VIII'
console.log(makeKing('Louis')) // 'King Louis VIII'
ECMAScript 6 之后就不用这么麻烦了,因为它支持显式定义默认参数了。下面就是与前面代码等价的 ES6 写法,只要在函数定义中的参数后面用 = 就可以为参数赋一个默认值:
function makeKing (name = 'Henry') {
return `King ${name} VIII`
}
console.log(makeKing('Louis')) // 'King Louis VIII'
console.log(makeKing()) // 'King Henry VIII'
给参数传 undefined 相当于没有传值,不过这样可以利用多个独立的默认值:
function makeKing (name = 'Henry', numerals = 'VIII') {
return `King ${name} ${numerals}`
}
console.log(makeKing()) // 'King Henry VIII'
console.log(makeKing('Louis')) // 'King Louis VIII'
console.log(makeKing(undefined, 'VI')) // 'King Henry VI'
在使用默认参数时,arguments 对象的值不反映参数的默认值,只反映传给函数的参数。当然,跟 ES5 严格模式一样,修改命名参数也不会影响 arguments 对象,它始终以调用函数时传入的值为准:
function makeKing (name = 'Henry') {
name = 'Louis'
return `King ${arguments[0]}`
}
console.log(makeKing()) // 'King undefined'
console.log(makeKing('Louis')) // 'King Louis'
默认参数值并不限于原始值或对象类型,也可以使用调用函数返回的值:
const romanNumerals = ['I', 'II', 'III', 'IV', 'V', 'VI']
let ordinality = 0
function getNumerals () {
// 每次调用后递增
return romanNumerals[ordinality++]
}
function makeKing (name = 'Henry', numerals = getNumerals()) {
return `King ${name} ${numerals}`
}
console.log(makeKing()) // 'King Henry I'
console.log(makeKing('Louis', 'XVI')) // 'King Louis XVI'
console.log(makeKing()) // 'King Henry II'
console.log(makeKing()) // 'King Henry III'
函数的默认参数只有在函数被调用时才会求值,不会在函数定义时求值。而且,计算默认值的函数只有在调用函数但未传相应参数时才会被调用。
箭头函数同样也可以这样使用默认参数,只不过在只有一个参数时,就必须使用括号而不能省略了:
const makeKing = (name = 'Henry') => `King ${name}`
console.log(makeKing()) // King Henry
5.1 默认参数作用域与暂时性死区
因为在求值默认参数时可以定义对象,也可以动态调用函数,所以函数参数肯定是在某个作用域中求值的。
给多个参数定义默认值实际上跟使用 let 关键字顺序声明变量一样。来看下面的例子:
function makeKing (name = 'Henry', numerals = 'VIII') {
return `King ${name} ${numerals}`
}
console.log(makeKing()) // King Henry VIII
这里的默认参数会按照定义它们的顺序依次被初始化。可以依照如下示例想象一下这个过程:
function makeKing () {
let name = 'Henry'
let numerals = 'VIII'
return `King ${name} ${numerals}`
}
因为参数是按顺序初始化的,所以后定义默认值的参数可以引用先定义的参数。看下面这个例子:
function makeKing (name = 'Henry', numerals = name) {
return `King ${name} ${numerals}`
}
console.log(makeKing()) // King Henry Henry
参数初始化顺序遵循“暂时性死区”规则,即前面定义的参数不能引用后面定义的。像这样就会抛出错误:
// 调用时不传第一个参数会报错
function makeKing (name = numerals, numerals = 'VIII') {
return `King ${name} ${numerals}`
}
参数也存在于自己的作用域中,它们不能引用函数体的作用域:
// 调用时不传第二个参数会报错
function makeKing (name = 'Henry', numerals = defaultNumeral) {
const defaultNumeral = 'VIII'
return `King ${name} ${numerals}`
}
六、参数扩展与收集
ECMAScript 6 新增了扩展操作符,使用它可以非常简洁地操作和组合集合数据。扩展操作符最有用的场景就是函数定义中的参数列表,在这里它可以充分利用这门语言的弱类型及参数长度可变的特点。扩展操作符既可以用于调用函数时传参,也可以用于定义函数参数。
6.1 扩展参数
在给函数传参时,有时候可能不需要传一个数组,而是要分别传入数组的元素。
假设有如下函数定义,它会将所有传入的参数累加起来:
const values = [1, 2, 3, 4]
function getSum () {
let sum = 0
for (let i = 0; i < arguments.length; ++i) {
sum += arguments[i]
}
return sum
}
这个函数希望将所有加数逐个传进来,然后通过迭代 arguments 对象来实现累加。如果不使用扩展操作符,想把定义在这个函数这面的数组拆分,那么就得求助于 apply() 方法:
const values = [1, 2, 3, 4]
function getSum () {
let sum = 0
for (let i = 0; i < arguments.length; ++i) {
sum += arguments[i]
}
return sum
}
// 因为传递的是数组,所以使用 apply
console.log(getSum.apply(null, values)) // 10
但在 ECMAScript 6 中,可以通过扩展操作符极为简洁地实现这种操作。对可迭代对象应用扩展操作符,并将其作为一个参数传入,可以将可迭代对象拆分,并将迭代返回的每个值单独传入。
比如,使用扩展操作符可以将前面例子中的数组像这样直接传给函数:
console.log(getSum(...values)); // 10
因为数组的长度已知,所以在使用扩展操作符传参的时候,并不妨碍在其前面或后面再传其他的值,包括使用扩展操作符传其他参数:
console.log(getSum(-1, ...values)) // 9
console.log(getSum(...values, 5)) // 15
console.log(getSum(-1, ...values, 5)) // 14
console.log(getSum(...values, ...[5, 6, 7])) // 28
对函数中的 arguments 对象而言,它并不知道扩展操作符的存在,而是按照调用函数时传入的参数接收每一个值:
const values = [1, 2, 3, 4]
function countArguments () {
console.log(arguments.length)
}
countArguments(-1, ...values) // 5
countArguments(...values, 5) // 5
countArguments(-1, ...values, 5) // 6
countArguments(...values, ...[5, 6, 7]) // 7
arguments 对象只是消费扩展操作符的一种方式。在普通函数和箭头函数中,也可以将扩展操作符用于命名参数,当然同时也可以使用默认参数:
function getProduct (a, b, c = 1) {
return a * b * c
}
const getSum = (a, b, c = 0) => {
return a + b + c
}
console.log(getProduct(...[1, 2])) // 2
console.log(getProduct(...[1, 2, 3])) // 6
console.log(getProduct(...[1, 2, 3, 4])) // 6
console.log(getSum(...[0, 1])) // 1
console.log(getSum(...[0, 1, 2])) // 3
console.log(getSum(...[0, 1, 2, 3])) // 3
6.2 收集参数
在构思函数定义时,可以使用扩展操作符把不同长度的独立参数组合为一个数组。这有点类似arguments 对象的构造机制,只不过收集参数的结果会得到一个 Array 实例。
function getSum (...values) {
// 顺序累加 values 中的所有值
// 初始值的总和为 0
return values.reduce((x, y) => x + y, 0)
}
console.log(getSum(1, 2, 3)) // 6
收集参数的前面如果还有命名参数,则只会收集其余的参数;如果没有则会得到空数组。因为收集参数的结果可变,所以只能把它作为最后一个参数:
// 不可以
function getProduct (...values, lastValue) {}
// 可以
function ignoreFirst (firstValue, ...values) {
console.log(values)
}
ignoreFirst() // []
ignoreFirst(1) // []
ignoreFirst(1, 2) // [2]
ignoreFirst(1, 2, 3) // [2, 3]
箭头函数虽然不支持 arguments 对象,但支持收集参数的定义方式,因此也可以实现与使用arguments 一样的逻辑:
const getSum = (...values) => {
return values.reduce((x, y) => x + y, 0)
}
console.log(getSum(1, 2, 3)) // 6
另外,使用收集参数并不影响 arguments 对象,它仍然反映调用时传给函数的参数:
function getSum (...values) {
console.log(arguments.length) // 3
console.log(arguments) // [1, 2, 3]
console.log(values) // [1, 2, 3]
}
console.log(getSum(1, 2, 3))
七、函数声明与函数表达式
本章到现在一直没有把函数声明和函数表达式区分得很清楚。事实上,JavaScript 引擎在加载数据时对它们是区别对待的。JavaScript 引擎在任何代码执行之前,会先读取函数声明,并在执行上下文中生成函数定义。而函数表达式必须等到代码执行到它那一行,才会在执行上下文中生成函数定义。来看下面的例子:
// 没问题
console.log(sum(10, 10))
function sum (num1, num2) {
return num1 + num2
}
以上代码可以正常运行,因为函数声明会在任何代码执行之前先被读取并添加到执行上下文。这个过程叫作函数声明提升(function declaration hoisting)。在执行代码时,JavaScript 引擎会先执行一遍扫描,把发现的函数声明提升到源代码树的顶部。因此即使函数定义出现在调用它们的代码之后,引擎也会把函数声明提升到顶部。如果把前面代码中的函数声明改为等价的函数表达式,那么执行的时候就会出错:
// 会出错
console.log(sum(10, 10))
let sum = function (num1, num2) {
return num1 + num2
}
上面的代码之所以会出错,是因为这个函数定义包含在一个变量初始化语句中,而不是函数声明中。这意味着代码如果没有执行第二行,那么执行上下文中就没有函数的定义,所以上面的代码会出错。这并不是因为使用 let 而导致的,使用 var 关键字也会碰到同样的问题:
console.log(sum(10, 10))
var sum = function (num1, num2) {
return num1 + num2
}
除了函数什么时候真正有定义这个区别之外,这两种语法是等价的。
注意:在使用函数表达式初始化变量时,也可以给函数一个名称,比如 let sum = function sum() {}。
八、函数作为值
因为函数名在 ECMAScript 中就是变量,所以函数可以用在任何可以使用变量的地方。这意味着不仅可以把函数作为参数传给另一个函数,而且还可以在一个函数中返回另一个函数。来看下面的例子:
function callSomeFunction (someFunction, someArgument) {
return someFunction(someArgument)
}
这个函数接收两个参数。第一个参数应该是一个函数,第二个参数应该是要传给这个函数的值。任何函数都可以像下面这样作为参数传递:
function add10 (num) {
return num + 10
}
function callSomeFunction (someFunction, someArgument) {
return someFunction(someArgument)
}
const result1 = callSomeFunction(add10, 10)
console.log(result1) // 20
function getGreeting (name) {
return 'Hello, ' + name
}
const result2 = callSomeFunction(getGreeting, 'Nicholas')
console.log(result2) // "Hello, Nicholas"
callSomeFunction() 函数是通用的,第一个参数传入的是什么函数都可以,而且它始终返回调用作为第一个参数传入的函数的结果。要注意的是,如果是访问函数而不是调用函数,那就必须不带括号,所以传给 callSomeFunction() 的必须是 add10 和 getGreeting,而不能是它们的执行结果。
从一个函数中返回另一个函数也是可以的,而且非常有用。例如,假设有一个包含对象的数组,而我们想按照任意对象属性对数组进行排序。为此,可以定义一个 sort() (sort 的使用方法)方法需要的比较函数,它接收两个参数,即要比较的值。但这个比较函数还需要想办法确定根据哪个属性来排序。这个问题可以通过定义一个根据属性名来创建比较函数的函数来解决。比如:
function createComparisonFunction (propertyName) {
return function (object1, object2) {
const value1 = object1[propertyName]
const value2 = object2[propertyName]
if (value1 < value2) {
return -1
} else if (value1 > value2) {
return 1
} else {
return 0
}
}
}
这个函数的语法乍一看比较复杂,但实际上就是在一个函数中返回另一个函数,注意那个 return 操作符。内部函数可以访问 propertyName 参数,并通过中括号语法取得要比较的对象的相应属性值。取得属性值以后,再按照 sort() 方法的需要返回比较值就行了。这个函数可以像下面这样使用:
const data = [
{ name: 'Zachary', age: 28 },
{ name: 'Nicholas', age: 29 }
]
data.sort(createComparisonFunction('name'))
console.log(data[0].name) // Nicholas
data.sort(createComparisonFunction('age'))
console.log(data[0].name) // Zachary
在上面的代码中,数组 data 中包含两个结构相同的对象。每个对象都有一个 name 属性和一个 age 属性。默认情况下,sort() 方法要对这两个对象执行 toString(),然后再决定它们的顺序,但这样得不到有意义的结果。而通过调用 createComparisonFunction(“name”)来创建一个比较函数,就可以根据每个对象 name 属性的值来排序,结果 name 属性值为"Nicholas"、age 属性值为 29 的对象会排在前面。而调用 createComparisonFunction(“age”) 则会创建一个根据每个对象 age 属性的值来排序的比较函数,结果 name 属性值为"Zachary"、age 属性值为 28 的对象会排在前面。
九、函数内部
在 ECMAScript 5 中,函数内部存在两个特殊的对象:arguments 和 this。ECMAScript 6 又新增了 new.target 属性。
9.1 arguments
arguments 对象前面讨论过多次了,它是一个类数组对象,包含调用函数时传入的所有参数。这个对象只有以 function 关键字定义函数(相对于使用箭头语法创建函数)时才会有。虽然主要用于包含函数参数,但 arguments 对象其实还有一个 callee 属性,是一个指向 arguments 对象所在函数的指针。来看下面这个经典的阶乘函数:
function factorial (num) {
if (num <= 1) {
return 1
} else {
return num * factorial(num - 1)
}
}
阶乘函数一般定义成递归调用的,就像上面这个例子一样。只要给函数一个名称,而且这个名称不会变,这样定义就没有问题。但是,这个函数要正确执行就必须保证函数名是 factorial,从而导致了紧密耦合。使用 arguments.callee 就可以让函数逻辑与函数名解耦:
function factorial (num) {
if (num <= 1) {
return 1
} else {
return num * arguments.callee(num - 1)
}
}
这个重写之后的 factorial() 函数已经用 arguments.callee 代替了之前硬编码的 factorial。这意味着无论函数叫什么名称,都可以引用正确的函数。考虑下面的情况:
function factorial (num) {
if (num <= 1) {
return 1
} else {
return num * arguments.callee(num - 1)
}
}
const trueFactorial = factorial
factorial = function () {
return 0
}
console.log(trueFactorial(5)) // 120
console.log(factorial(5)) // 0
这里,trueFactorial 变量被赋值为 factorial,实际上把同一个函数的指针又保存到了另一个位置。然后,factorial 函数又被重写为一个返回 0 的函数。如果像 factorial() 最初的版本那样不使用 arguments.callee,那么像上面这样调用 trueFactorial() 就会返回 0。不过,通过将函数与名称解耦,trueFactorial() 就可以正确计算阶乘,而 factorial() 则只能返回 0。
9.2 this
另一个特殊的对象是 this,它在标准函数和箭头函数中有不同的行为。
在标准函数中,this 引用的是把函数当成方法调用的上下文对象,这时候通常称其为 this 值(在网页的全局上下文中调用函数时,this 指向 windows)。来看下面的例子:
window.color = 'red'
const o = {
color: 'blue'
}
function sayColor () {
console.log(this.color)
}
sayColor() // 'red'
o.sayColor = sayColor
o.sayColor() // 'blue'
定义在全局上下文中的函数 sayColor() 引用了 this 对象。这个 this 到底引用哪个对象必须到函数被调用时才能确定。因此这个值在代码执行的过程中可能会变。如果在全局上下文中调用sayColor(),这结果会输出"red",因为 this 指向 window,而 this.color 相当于 window.color。而在把 sayColor()赋值给 o 之后再调用 o.sayColor(),this 会指向 o,即 this.color 相当于o.color,所以会显示"blue"。
在箭头函数中,this 引用的是定义箭头函数的上下文。下面的例子演示了这一点。在对sayColor() 的两次调用中,this 引用的都是 window 对象,因为这个箭头函数是在 window 上下文中定义的:
window.color = 'red'
const o = {
color: 'blue'
}
const sayColor = () => console.log(this.color)
sayColor() // 'red'
o.sayColor = sayColor
o.sayColor() // 'red'
在事件回调或定时回调中调用某个函数时,this 值指向的并非想要的对象。此时将回调函数写成箭头函数就可以解决问题。这是因为箭头函数中的 this 会保留定义该函数时的上下文:
function King () {
this.royaltyName = 'Henry'
// this 引用 King 的实例
setTimeout(() => console.log(this.royaltyName), 1000)
}
function Queen () {
this.royaltyName = 'Elizabeth'
// this 引用 window 对象
setTimeout(function () { console.log(this.royaltyName) }, 1000)
}
new King() // Henry
new Queen() // undefined
注意:函数名只是保存指针的变量。因此全局定义的 sayColor() 函数和 o.sayColor() 是同一个函数,只不过执行的上下文不同。
9.3 caller
ECMAScript 5 也会给函数对象上添加一个属性:caller。虽然 ECMAScript 3 中并没有定义,但所有浏览器除了早期版本的 Opera 都支持这个属性。这个属性引用的是调用当前函数的函数,或者如果是在全局作用域中调用的则为 null。比如:
function outer () {
inner()
}
function inner () {
console.log(inner.caller)
}
outer()
以上代码会显示 outer() 函数的源代码。这是因为 ourter() 调用了 inner(),inner.caller 指向 outer()。如果要降低耦合度,则可以通过 arguments.callee.caller 来引用同样的值:
function outer () {
inner()
}
function inner () {
console.log(arguments.callee.caller)
}
outer()
在严格模式下访问 arguments.callee 会报错。ECMAScript 5 也定义了 arguments.caller,但在严格模式下访问它会报错,在非严格模式下则始终是 undefined。这是为了分清arguments.caller 和函数的 caller 而故意为之的。而作为对这门语言的安全防护,这些改动也让第三方代码无法检测同一上下文中运行的其他代码。
严格模式下还有一个限制,就是不能给函数的 caller 属性赋值,否则会导致错误。
9.4 new.target
ECMAScript 中的函数始终可以作为构造函数实例化一个新对象,也可以作为普通函数被调用。ECMAScript 6 新增了检测函数是否使用 new 关键字调用的 new.target 属性。如果函数是正常调用的,则 new.target 的值是 undefined;如果是使用 new 关键字调用的,则 new.target 将引用被调用的构造函数。
function King () {
if (!new.target) {
// 正常调用
throw 'King must be instantiated using "new"'
}
console.log('King instantiated using "new"')
}
new King() // King instantiated using "new"
King() // Error: King must be instantiated using "new"
十、函数属性与方法(apply、call、bind)
前面提到过,ECMAScript 中的函数是对象,因此有属性和方法。每个函数都有两个属性:length 和 prototype。其中,length 属性保存函数定义的命名参数的个数,如下例所示:
function sayName (name) {
console.log(name)
}
function sum (num1, num2) {
return num1 + num2
}
function sayHi () {
console.log('hi')
}
console.log(sayName.length) // 1
console.log(sum.length) // 2
console.log(sayHi.length) // 0
以上代码定义了 3 个函数,每个函数的命名参数个数都不一样。sayName() 函数有 1 个命名参数,所以其 length 属性为 1。类似地,sum() 函数有两个命名参数,所以其 length 属性是 2。而 sayHi() 没有命名参数,其 length 属性为 0。
prototype 属性也许是 ECMAScript 核心中最有趣的部分。prototype 是保存引用类型所有实例方法的地方,这意味着 toString()、valueOf() 等方法实际上都保存在 prototype 上,进而由所有实例共享。这个属性在自定义类型时特别重要。在 ECMAScript 5 中,prototype 属性是不可枚举的,因此使用 for-in 循环不会返回这个属性。
函数还有两个方法:apply() 和 call()。这两个方法都会以指定的 this 值来调用函数,即会设置调用函数时函数体内 this 对象的值。
apply() 方法接收两个参数:函数内 this 的值和一个参数数组。第二个参数可以是 Array 的实例,但也可以是 arguments 对象。来看下面的例子:
function sum (num1, num2) {
return num1 + num2
}
function callSum1 (num1, num2) {
// 将 this 作为函数体内的 this 值(这里等于 window,因为是在全局作用域中调用的)
return sum.apply(this, arguments) // 传入 arguments 对象
}
function callSum2 (num1, num2) {
return sum.apply(this, [num1, num2]) // 传入数组
}
console.log(callSum1(10, 10)) // 20
console.log(callSum2(10, 10)) // 20
在这个例子中,callSum1() 会调用 sum() 函数,将 this 作为函数体内的 this 值(这里等于 window,因为是在全局作用域中调用的)传入,同时还传入了 arguments 对象。callSum2() 也会调用 sum() 函数,但会传入参数的数组。这两个函数都会执行并返回正确的结果。
注意:在严格模式下,调用函数时如果没有指定上下文对象,则 this 值不会指向 window。除非使用 apply() 或 call() 把函数指定给一个对象,否则 this 的值会变成 undefined。
call() 方法与 apply() 的作用一样,只是传参的形式不同。第一个参数跟 apply() 一样,也是 this 值,而剩下的要传给被调用函数的参数则是逐个传递的。换句话说,通过 call() 向函数传参时,必须将参数一个一个地列出来,比如:
function sum (num1, num2) {
return num1 + num2
}
function callSum (num1, num2) {
return sum.call(this, num1, num2)
}
console.log(callSum(10, 10)) // 20
这里的 callSum() 函数必须逐个地把参数传给 call() 方法。结果跟 apply()的例子一样。到底是使用 apply() 还是 call(),完全取决于怎么给要调用的函数传参更方便。如果想直接传 arguments 对象或者一个数组,那就用 apply();否则,就用 call()。当然,如果不用给被调用的函数传参,则使用哪个方法都一样。
apply() 和 call() 真正强大的地方并不是给函数传参,而是控制函数调用上下文即函数体内 this 值的能力。考虑下面的例子:
window.color = 'red'
const o = {
color: 'blue'
}
function sayColor () {
console.log(this.color)
}
sayColor() // red
sayColor.call(this) // red
sayColor.call(window) // red
sayColor.call(o) // blue
这个例子是在之前那个关于 this 对象的例子基础上修改而成的。同样,sayColor() 是一个全局函数,如果在全局作用域中调用它,那么会显示"red"。这是因为 this.color 会求值为 window.color。如果在全局作用域中显式调用 sayColor.call(this) 或者 sayColor.call(window),则同样都会显示"red"。而在使用 sayColor.call(o) 把函数的执行上下文即 this 切换为对象 o 之后,结果就变成了显示"blue"了。
使用 call() 或 apply() 的好处是可以将任意对象设置为任意函数的作用域,这样对象可以不用关心方法。在前面例子最初的版本中,为切换上下文需要先把 sayColor() 直接赋值为 o 的属性,然后再调用。而在这个修改后的版本中,就不需要这一步操作了。
ECMAScript 5 出于同样的目的定义了一个新方法:bind()。bind() 方法会创建一个新的函数实例,其 this 值会被绑定到传给 bind() 的对象。比如:
window.color = 'red'
const o = {
color: 'blue'
}
function sayColor () {
console.log(this.color)
}
const objectSayColor = sayColor.bind(o)
objectSayColor() // blue
这里,在 sayColor() 上调用 bind() 并传入对象 o 创建了一个新函数 objectSayColor()。objectSayColor() 中的 this 值被设置为 o,因此直接调用这个函数,即使是在全局作用域中调用,也会返回字符串"blue"。
对函数而言,继承的方法 toLocaleString() 和 toString() 始终返回函数的代码。返回代码的具体格式因浏览器而异。有的返回源代码,包含注释,而有的只返回代码的内部形式,会删除注释,甚至代码可能被解释器修改过。由于这些差异,因此不能在重要功能中依赖这些方法返回的值,而只应在调试中使用它们。继承的方法 valueOf() 返回函数本身。
十一、函数表达式
函数表达式虽然更强大,但也更容易让人迷惑。我们知道,定义函数有两种方式:函数声明和函数表达式。
函数声明是这样的:
function functionName (arg0, arg1, arg2) {
// 函数体
}
函数声明的关键特点是函数声明提升,即函数声明会在代码执行之前获得定义。这意味着函数声明可以出现在调用它的代码之后:
sayHi() // ‘Hi!’
function sayHi () {
console.log('Hi!')
}
这个例子不会抛出错误,因为 JavaScript 引擎会先读取函数声明,然后再执行代码。
第二种创建函数的方式就是函数表达式。函数表达式有几种不同的形式,最常见的是这样的:
const functionName = function (arg0, arg1, arg2) {
// 函数体
}
函数表达式看起来就像一个普通的变量定义和赋值,即创建一个函数再把它赋值给一个变量 functionName。这样创建的函数叫作匿名函数(anonymous funtion),因为 function 关键字后面没有标识符。(匿名函数有也时候也被称为兰姆达函数)。未赋值给其他变量的匿名函数的 name 属性是空字符串。
函数表达式跟 JavaScript 中的其他表达式一样,需要先赋值再使用。下面的例子会导致错误:
sayHi(); // Error! function doesn't exist yet
let sayHi = function() {
console.log("Hi!");
};
理解函数声明与函数表达式之间的区别,关键是理解提升。比如,以下代码的执行结果可能会出乎意料:
// 千万别这样做!
if (condition) {
function sayHi () {
console.log('Hi!')
}
} else {
function sayHi () {
console.log('Yo!')
}
}
这段代码看起来很正常,就是如果 condition 为 true,则使用第一个 sayHi() 定义;否则,就使用第二个。事实上,这种写法在 ECAMScript 中不是有效的语法。JavaScript 引擎会尝试将其纠正为适当的声明。问题在于浏览器纠正这个问题的方式并不一致。多数浏览器会忽略 condition 直接返回第二个声明。Firefox 会在 condition 为 true 时返回第一个声明。这种写法很危险,不要使用。不过,如果把上面的函数声明换成函数表达式就没问题了:
// 没问题
let sayHi
if (condition) {
sayHi = function () {
console.log('Hi!')
}
} else {
sayHi = function () {
console.log('Yo!')
}
}
这个例子可以如预期一样,根据 condition 的值为变量 sayHi 赋予相应的函数。
创建函数并赋值给变量的能力也可以用于在一个函数中把另一个函数当作值返回:
function createComparisonFunction (propertyName) {
return function (object1, object2) {
const value1 = object1[propertyName]
const value2 = object2[propertyName]
if (value1 < value2) {
return -1
} else if (value1 > value2) {
return 1
} else {
return 0
}
}
}
这里的 createComparisonFunction() 函数返回一个匿名函数,这个匿名函数要么被赋值给一个变量,要么可以直接调用。但在 createComparisonFunction() 内部,那个函数是匿名的。任何时候,只要函数被当作值来使用,它就是一个函数表达式。本章后面会介绍,这并不是使用函数表达式的唯一方式。
十二、递归
递归函数通常的形式是一个函数通过名称调用自己,如下面的例子所示:
function factorial (num) {
if (num <= 1) {
return 1
} else {
return num * factorial(num - 1)
}
}
这是经典的递归阶乘函数。虽然这样写是可以的,但如果把这个函数赋值给其他变量,就会出问题:
const anotherFactorial = factorial
factorial = null
console.log(anotherFactorial(4)) // 报错
这里把 factorial() 函数保存在了另一个变量 anotherFactorial 中,然后将 factorial 设置为 null,于是只保留了一个对原始函数的引用。而在调用 anotherFactorial() 时,要递归调用 factorial(),但因为它已经不是函数了,所以会出错。在写递归函数时使用 arguments.callee 可以避免这个问题。
arguments.callee 就是一个指向正在执行的函数的指针,因此可以在函数内部递归调用,如下所示:
function factorial (num) {
if (num <= 1) {
return 1
} else {
return num * arguments.callee(num - 1)
}
}
factorial(4)
把函数名称替换成 arguments.callee,可以确保无论通过什么变量调用这个函数都不会出问题。因此在编写递归函数时,arguments.callee 是引用当前函数的首选。
不过,在严格模式下运行的代码是不能访问 arguments.callee 的,因为访问会出错。此时,可以使用命名函数表达式(named function expression)达到目的。比如:
const factorial = function f (num) {
if (num <= 1) {
return 1
} else {
return num * f(num - 1)
}
}
这里创建了一个命名函数表达式 f(),然后将它赋值给了变量 factorial。即使把函数赋值给另一个变量,函数表达式的名称 f 也不变,因此递归调用不会有问题。这个模式在严格模式和非严格模式下都可以使用。
十三、尾调用优化
ECMAScript 6 规范新增了一项内存管理优化机制,让 JavaScript 引擎在满足条件时可以重用栈帧。具体来说,这项优化非常适合“尾调用”,即外部函数的返回值是一个内部函数的返回值。比如:
function outerFunction () {
return innerFunction() // 尾调用
}
在 ES6 优化之前,执行这个例子会在内存中发生如下操作。
- 执行到 outerFunction 函数体,第一个栈帧被推到栈上。
- 执行 outerFunction 函数体,到 return 语句。计算返回值必须先计算 innerFunction。
- 执行到 innerFunction 函数体,第二个栈帧被推到栈上。
- 执行 innerFunction 函数体,计算其返回值。
- 将返回值传回 outerFunction,然后 outerFunction 再返回值。
- 将栈帧弹出栈外。
在 ES6 优化之后,执行这个例子会在内存中发生如下操作。
- 执行到 outerFunction 函数体,第一个栈帧被推到栈上。
- 执行 outerFunction 函数体,到达 return 语句。为求值返回语句,必须先求值 innerFunction。
- 引擎发现把第一个栈帧弹出栈外也没问题,因为 innerFunction 的返回值也是 outerFunction 的返回值。
- 弹出 outerFunction 的栈帧。
- 执行到 innerFunction 函数体,栈帧被推到栈上。
- 执行 innerFunction 函数体,计算其返回值。
- 将 innerFunction 的栈帧弹出栈外。
很明显,第一种情况下每多调用一次嵌套函数,就会多增加一个栈帧。而第二种情况下无论调用多少次嵌套函数,都只有一个栈帧。这就是 ES6 尾调用优化的关键:如果函数的逻辑允许基于尾调用将其销毁,则引擎就会那么做。
注意:现在还没有办法测试尾调用优化是否起作用。不过,因为这是 ES6 规范所规定的,兼容的浏览器实现都能保证在代码满足条件的情况下应用这个优化。
13.1 尾调用优化的条件
尾调用优化的条件就是确定外部栈帧真的没有必要存在了。涉及的条件如下:
- 代码在严格模式下执行;
- 外部函数的返回值是对尾调用函数的调用;
- 尾调用函数返回后不需要执行额外的逻辑;
- 尾调用函数不是引用外部函数作用域中自由变量的闭包。
下面展示了几个违反上述条件的函数,因此都不符号尾调用优化的要求:
'use strict'
// 无优化:尾调用没有返回
function outerFunction () {
innerFunction()
}
// 无优化:尾调用没有直接返回
function outerFunction () {
const innerFunctionResult = innerFunction()
return innerFunctionResult
}
// 无优化:尾调用返回后必须转型为字符串
function outerFunction () {
return innerFunction().toString()
}
// 无优化:尾调用是一个闭包
function outerFunction () {
const foo = 'bar'
function innerFunction () {
return foo
}
return innerFunction()
}
下面是几个符合尾调用优化条件的例子:
'use strict'
// 有优化:栈帧销毁前执行参数计算
function outerFunction (a, b) {
return innerFunction(a + b)
}
// 有优化:初始返回值不涉及栈帧
function outerFunction (a, b) {
if (a < b) {
return a
}
return innerFunction(a + b)
}
// 有优化:两个内部函数都在尾部
function outerFunction (condition) {
return condition ? innerFunctionA() : innerFunctionB()
}
差异化尾调用和递归尾调用是容易让人混淆的地方。无论是递归尾调用还是非递归尾调用,都可以应用优化。引擎并不区分尾调用中调用的是函数自身还是其他函数。不过,这个优化在递归场景下的效果是最明显的,因为递归代码最容易在栈内存中迅速产生大量栈帧。
注意:之所以要求严格模式,主要因为在非严格模式下函数调用中允许使用 f.arguments 和 f.caller,而它们都会引用外部函数的栈帧。显然,这意味着不能应用优化了。因此尾调用优化要求必须在严格模式下有效,以防止引用这些属性。
13.2 尾调用优化的代码
可以通过把简单的递归函数转换为待优化的代码来加深对尾调用优化的理解。下面是一个通过递归计算斐波纳契数列的函数:
function fib (n) {
if (n < 2) {
return n
}
return fib(n - 1) + fib(n - 2)
}
console.log(fib(0)) // 0
console.log(fib(1)) // 1
console.log(fib(2)) // 1
console.log(fib(3)) // 2
console.log(fib(4)) // 3
console.log(fib(5)) // 5
console.log(fib(6)) // 8
显然这个函数不符合尾调用优化的条件,因为返回语句中有一个相加的操作。结果,fib(n) 的栈帧数的内存复杂度是 O(2^n)。因此,即使这么一个简单的调用也可以给浏览器带来麻烦:
fib(1000)
当然,解决这个问题也有不同的策略,比如把递归改写成迭代循环形式。不过,也可以保持递归实现,但将其重构为满足优化条件的形式。为此可以使用两个嵌套的函数,外部函数作为基础框架,内部函数执行递归:
'use strict'
// 基础框架
function fib (n) {
return fibImpl(0, 1, n)
}
// 执行递归
function fibImpl (a, b, n) {
if (n === 0) {
return a
}
return fibImpl(b, a + b, n - 1)
}
这样重构之后,就可以满足尾调用优化的所有条件,再调用 fib(1000) 就不会对浏览器造成威胁了。
十四、闭包
匿名函数经常被人误认为是闭包(closure)。闭包指的是那些引用了另一个函数作用域中变量的函数,通常是在嵌套函数中实现的。比如,下面是之前展示的 createComparisonFunction() 函数,注意其中加粗的代码:
function createComparisonFunction (propertyName) {
return function (object1, object2) {
const value1 = object1[propertyName]
const value2 = object2[propertyName]
if (value1 < value2) {
return -1
} else if (value1 > value2) {
return 1
} else {
return 0
}
}
}
内部函数(匿名函数)引用了外部函数的变量 propertyName。在这个内部函数被返回并在其他地方被使用后,它仍然引用着那个变量。这是因为内部函数的作用域链包含 createComparisonFunction() 函数的作用域。要理解为什么会这样,可以想想第一次调用这个函数时会发生什么。
作用域链的概念。理解作用域链创建和使用的细节对理解闭包非常重要。在调用一个函数时,会为这个函数调用创建一个执行上下文,并创建一个作用域链。然后用 arguments 和其他命名参数来初始化这个函数的活动对象。外部函数的活动对象是内部函数作用域链上的第二个对象。这个作用域链一直向外串起了所有包含函数的活动对象,直到全局执行上下文才终止。
在函数执行时,要从作用域链中查找变量,以便读、写值。来看下面的代码:
function compare (value1, value2) {
if (value1 < value2) {
return -1
} else if (value1 > value2) {
return 1
} else {
return 0
}
}
const result = compare(5, 10)
这里定义的 compare() 函数是在全局上下文中调用的。第一次调用 compare() 时,会为它创建一个包含 arguments、value1 和 value2 的活动对象,这个对象是其作用域链上的第一个对象。而全局上下文的变量对象则是 compare() 作用域链上的第二个对象,其中包含 this、result 和 compare。
函数执行时,每个执行上下文中都会有一个包含其中变量的对象。全局上下文中的叫变量对象,它会在代码执行期间始终存在。而函数局部上下文中的叫活动对象,只在函数执行期间存在。在定义 compare() 函数时,就会为它创建作用域链,预装载全局变量对象,并保存在内部的 [[Scope]] 中。在调用这个函数时,会创建相应的执行上下文,然后通过复制函数的 [[Scope]] 来创建其作用域链。接着会创建函数的活动对象(用作变量对象)并将其推入作用域链的前端。在这个例子中,这意味着 compare() 函数执行上下文的作用域链中有两个变量对象:局部变量对象和全局变量对象。作用域链其实是一个包含指针的列表,每个指针分别指向一个变量对象,但物理上并不会包含相应的对象。

函数内部的代码在访问变量时,就会使用给定的名称从作用域链中查找变量。函数执行完毕后,局部活动对象会被销毁,内存中就只剩下全局作用域。不过,闭包就不一样了。
在一个函数内部定义的函数会把其包含函数的活动对象添加到自己的作用域链中。因此,在 createComparisonFunction() 函数中,匿名函数的作用域链中实际上包含 createComparisonFunction() 的活动对象。
const compare = createComparisonFunction('name')
const result = compare({ name: 'Nicholas' }, { name: 'Matt' })
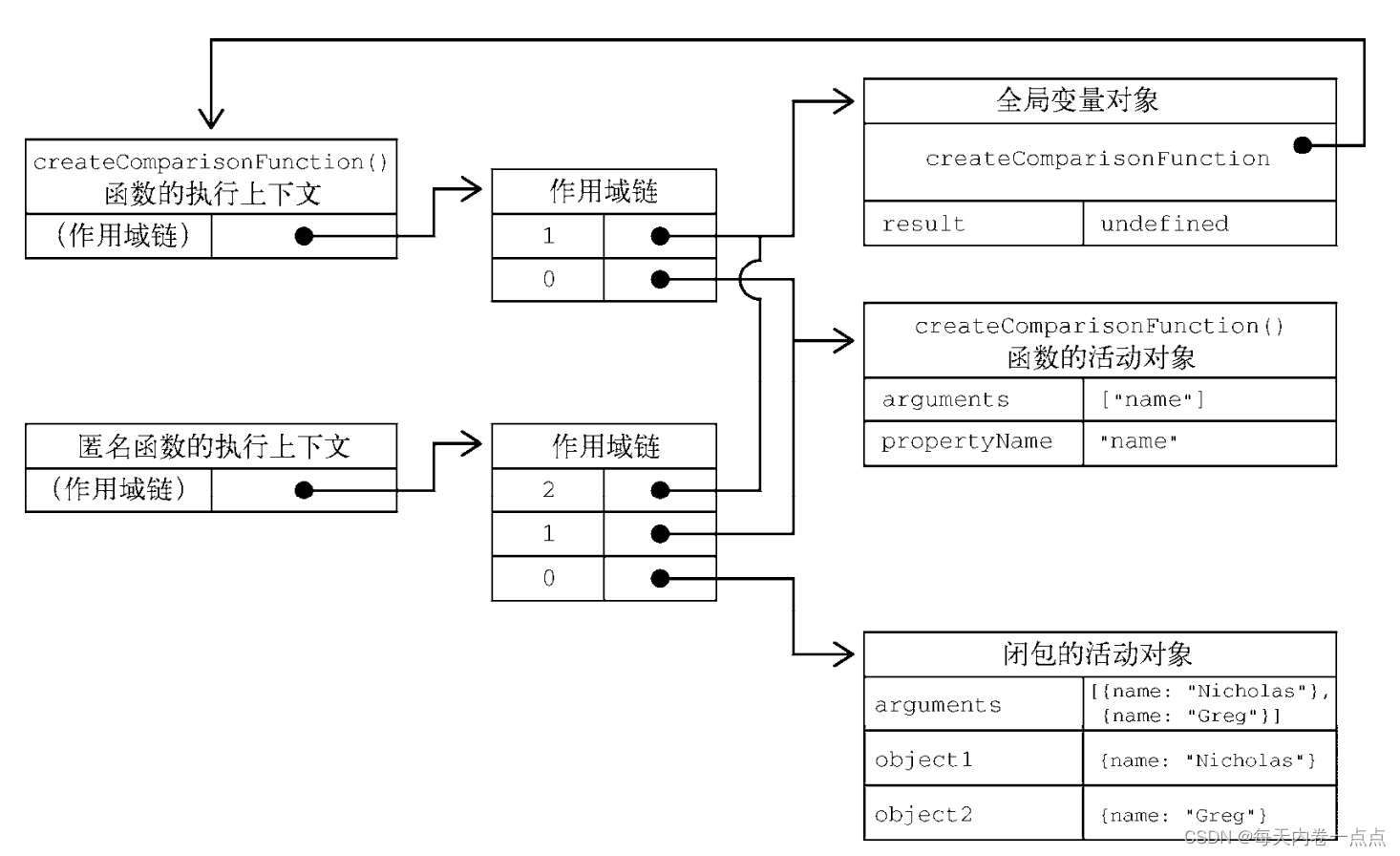
在 createComparisonFunction() 返回匿名函数后,它的作用域链被初始化为包含 createComparisonFunction() 的活动对象和全局变量对象。这样,匿名函数就可以访问到 createComparisonFunction() 可以访问的所有变量。另一个有意思的副作用就是,createComparisonFunction() 的活动对象并不能在它执行完毕后销毁,因为匿名函数的作用域链中仍然有对它的引用。在 createComparisonFunction() 执行完毕后,其执行上下文的作用域链会销毁,但它的活动对象仍然会保留在内存中,直到匿名函数被销毁后才会被销毁:
// 创建比较函数
let compareNames = createComparisonFunction('name')
// 调用函数
const result = compareNames({ name: 'Nicholas' }, { name: 'Matt' })
// 解除对函数的引用,这样就可以释放内存了
compareNames = null
这里,创建的比较函数被保存在变量 compareNames 中。把 compareNames 设置为等于 null 会解除对函数的引用,从而让垃圾回收程序可以将内存释放掉。作用域链也会被销毁,其他作用域(除全局作用域之外)也可以销毁。
注意:因为闭包会保留它们包含函数的作用域,所以比其他函数更占用内存。过度使用闭包可能导致内存过度占用,因此建议仅在十分必要时使用。V8 等优化的 JavaScript 引擎会努力回收被闭包困住的内存,不过我们还是建议在使用闭包时要谨慎。
14.1 this 对象
在闭包中使用 this 会让代码变复杂。如果内部函数没有使用箭头函数定义,则 this 对象会在运行时绑定到执行函数的上下文。如果在全局函数中调用,则 this 在非严格模式下等于 window,在严格模式下等于 undefined。如果作为某个对象的方法调用,则 this 等于这个对象。匿名函数在这种情况下不会绑定到某个对象,这就意味着 this 会指向 window,除非在严格模式下 this 是 undefined。不过,由于闭包的写法所致,这个事实有时候没有那么容易看出来。来看下面的例子:
window.identity = 'The Window'
const object = {
identity: 'My Object',
getIdentityFunc () {
return function () {
return this.identity
}
}
}
console.log(object.getIdentityFunc()()) // 'The Window'
这里先创建了一个全局变量 identity,之后又创建一个包含 identity 属性的对象。这个对象还包含一个 getIdentityFunc() 方法,返回一个匿名函数。这个匿名函数返回 this.identity。因为 getIdentityFunc() 返回函数,所以 object.getIdentityFunc()()会立即调用这个返回的函数,从而得到一个字符串。可是,此时返回的字符串是"The Winodw",即全局变量 identity 的值。为什
么匿名函数没有使用其包含作用域(getIdentityFunc())的 this 对象呢?
前面介绍过,每个函数在被调用时都会自动创建两个特殊变量:this 和 arguments。内部函数永远不可能直接访问外部函数的这两个变量。但是,如果把 this 保存到闭包可以访问的另一个变量中,则是行得通的。比如:
window.identity = 'The Window'
const object = {
identity: 'My Object',
getIdentityFunc () {
const that = this
return function () {
return that.identity
}
}
}
console.log(object.getIdentityFunc()()) // 'My Object'
这里的代码展示了与前面那个例子的区别。在定义匿名函数之前,先把外部函数的 this 保存到变量 that 中。然后在定义闭包时,就可以让它访问 that,因为这是包含函数中名称没有任何冲突的一个变量。即使在外部函数返回之后,that 仍然指向 object,所以调用 object.getIdentityFunc()() 就会返回"My Object"。
注意:this 和 arguments 都是不能直接在内部函数中访问的。如果想访问包含作用域中的 arguments 对象,则同样需要将其引用先保存到闭包能访问的另一个变量中。
在一些特殊情况下,this 值可能并不是我们所期待的值。比如下面这个修改后的例子:
window.identity = 'The Window'
const object = {
identity: 'My Object',
getIdentity () {
return this.identity
}
}
getIdentity() 方法就是返回 this.identity 的值。以下是几种调用 object.getIdentity() 的方式及返回值:
object.getIdentity() // 'My Object'
(object.getIdentity)() // 'My Object'
(object.getIdentity = object.getIdentity)() // 'The Window'
第一行调用 object.getIdentity() 是正常调用,会返回"My Object",因为 this.identity 就是 object.identity。第二行在调用时把 object.getIdentity 放在了括号里。虽然加了括号之后看起来是对一个函数的引用,但 this 值并没有变。这是因为按照规范,object.getIdentity 和
(object.getIdentity)是相等的。第三行执行了一次赋值,然后再调用赋值后的结果。因为赋值表达式的值是函数本身,this 值不再与任何对象绑定,所以返回的是"The Window"。
一般情况下,不大可能像第二行和第三行这样调用对象上的方法。但通过这个例子,我们可以知道,即使语法稍有不同,也可能影响 this 的值。
14.2 内存泄漏
由于 IE 在 IE9 之前对 JScript 对象和 COM 对象使用了不同的垃圾回收机制,所以闭包在这些旧版本 IE 中可能会导致问题。在这些版本的 IE 中,把 HTML 元素保存在某个闭包的作用域中,就相当于宣布该元素不能被销毁。来看下面的例子:
function assignHandler () {
const element = document.getElementById('someElement')
element.onclick = () => console.log(element.id)
}
以上代码创建了一个闭包,即 element 元素的事件处理程序。而这个处理程序又创建了一个循环引用。匿名函数引用着 assignHandler() 的活动对象,阻止了对 element 的引用计数归零。只要这个匿名函数存在,element 的引用计数就至少等于 1。也就是说,内存不会被回收。其实只要这个例子稍加修改,就可以避免这种情况,比如:
function assignHandler () {
let element = document.getElementById('someElement')
const id = element.id
element.onclick = () => console.log(id)
element = null
}
在这个修改后的版本中,闭包改为引用一个保存着 element.id 的变量 id,从而消除了循环引用。不过,光有这一步还不足以解决内存问题。因为闭包还是会引用包含函数的活动对象,而其中包含 element。即使闭包没有直接引用 element,包含函数的活动对象上还是保存着对它的引用。因此,必须再把 element 设置为 null。这样就解除了对这个 COM 对象的引用,其引用计数也会减少,从而确保其内存可以在适当的时候被回收。
十五、立即调用的函数表达式
立即调用的匿名函数又被称作立即调用的函数表达式(IIFE,Immediately Invoked Function Expression)。它类似于函数声明,但由于被包含在括号中,所以会被解释为函数表达式。紧跟在第一组括号后面的第二组括号会立即调用前面的函数表达式。下面是一个简单的例子:
(function () {
// 块级作用域
})()
使用 IIFE 可以模拟块级作用域,即在一个函数表达式内部声明变量,然后立即调用这个函数。这样位于函数体作用域的变量就像是在块级作用域中一样。ECMAScript 5 尚未支持块级作用域,使用 IIFE模拟块级作用域是相当普遍的。比如下面的例子:
// IIFE
(function () {
for (let i = 0; i < count; i++) {
console.log(i)
}
})()
console.log(i) // 抛出错误
前面的代码在执行到 IIFE 外部的 console.log() 时会出错,因为它访问的变量是在 IIFE 内部定义的,在外部访问不到。在 ECMAScript 5.1 及以前,为了防止变量定义外泄,IIFE 是个非常有效的方式。这样也不会导致闭包相关的内存问题,因为不存在对这个匿名函数的引用。为此,只要函数执行完毕,其作用域链就可以被销毁。
在 ECMAScript 6 以后,IIFE 就没有那么必要了,因为块级作用域中的变量无须 IIFE 就可以实现同样的隔离。下面展示了两种不同的块级作用域形式:
// 内嵌块级作用域
{
let i
for (i = 0; i < count; i++) {
console.log(i)
}
}
console.log(i) // 抛出错误
// 循环的块级作用域
for (let i = 0; i < count; i++) {
console.log(i)
}
console.log(i) // 抛出错误
说明 IIFE 用途的一个实际的例子,就是可以用它锁定参数值。比如:
let divs = document.querySelectorAll('div')
// 达不到目的!
for (var i = 0; i < divs.length; ++i) {
divs[i].addEventListener('click', function () {
console.log(i)
})
}
这里使用 var 关键字声明了循环迭代变量 i,但这个变量并不会被限制在 for 循环的块级作用域内。因此,渲染到页面上之后,点击每个
以前,为了实现点击第几个
let divs = document.querySelectorAll('div');
for (var i = 0; i < divs.length; ++i) {
divs[i].addEventListener('click', (function(frozenCounter) {
return function() {
console.log(frozenCounter);
};
})(i));
}
而使用 ECMAScript 块级作用域变量,就不用这么大动干戈了:
const divs = document.querySelectorAll('div')
for (let i = 0; i < divs.length; ++i) {
divs[i].addEventListener('click', function () {
console.log(i)
})
}
这样就可以让每次点击都显示正确的索引了。这里,事件处理程序执行时就会引用 for 循环块级作用域中的索引值。这是因为在 ECMAScript 6 中,如果对 for 循环使用块级作用域变量关键字,在这里就是 let,那么循环就会为每个循环创建独立的变量,从而让每个单击处理程序都能引用特定的索引。
但要注意,如果把变量声明拿到 for 循环外部,那就不行了。下面这种写法会碰到跟在循环中使用 var i = 0 同样的问题:
const divs = document.querySelectorAll('div')
// 达不到目的!
let i
for (i = 0; i < divs.length; ++i) {
divs[i].addEventListener('click', function () {
console.log(i)
})
}
十六、私有变量
严格来讲,JavaScript 没有私有成员的概念,所有对象属性都公有的。不过,倒是有私有变量的概念。任何定义在函数或块中的变量,都可以认为是私有的,因为在这个函数或块的外部无法访问其中的变量。私有变量包括函数参数、局部变量,以及函数内部定义的其他函数。来看下面的例子:
function add (num1, num2) {
const sum = num1 + num2
return sum
}
在这个函数中,函数 add() 有 3 个私有变量:num1、num2 和 sum。这几个变量只能在函数内部使用,不能在函数外部访问。如果这个函数中创建了一个闭包,则这个闭包能通过其作用域链访问其外部的这 3 个变量。基于这一点,就可以创建出能够访问私有变量的公有方法。
特权方法(privileged method)是能够访问函数私有变量(及私有函数)的公有方法。在对象上有两种方式创建特权方法。第一种是在构造函数中实现,比如:
function MyObject () {
// 私有变量和私有函数
let privateVariable = 10
function privateFunction () {
return false
}
// 特权方法
this.publicMethod = function () {
privateVariable++
return privateFunction()
}
}
这个模式是把所有私有变量和私有函数都定义在构造函数中。然后,再创建一个能够访问这些私有成员的特权方法。这样做之所以可行,是因为定义在构造函数中的特权方法其实是一个闭包,它具有访问构造函数中定义的所有变量和函数的能力。在这个例子中,变量 privateVariable 和函数 privateFunction() 只能通过 publicMethod() 方法来访问。在创建 MyObject 的实例后,没有办法直接访问 privateVariable 和 privateFunction(),唯一的办法是使用 publicMethod()。
如下面的例子所示,可以定义私有变量和特权方法,以隐藏不能被直接修改的数据:
function Person (name) {
this.getName = function () {
return name
}
this.setName = function (value) {
name = value
}
}
const person = new Person('Nicholas')
console.log(person.getName()) // 'Nicholas'
person.setName('Greg')
console.log(person.getName()) // 'Greg'
这段代码中的构造函数定义了两个特权方法:getName() 和 setName()。每个方法都可以构造函数外部调用,并通过它们来读写私有的 name 变量。在 Person 构造函数外部,没有别的办法访问 name。因为两个方法都定义在构造函数内部,所以它们都是能够通过作用域链访问 name 的闭包。私有变量 name 对每个 Person 实例而言都是独一无二的,因为每次调用构造函数都会重新创建一套变量和方法。不过这样也有个问题:必须通过构造函数来实现这种隔离。构造函数模式的缺点是每个实例都会重新创建一遍新方法。使用静态私有变量实现特权方法可以避免这个问题。
16.1 静态私有变量
特权方法也可以通过使用私有作用域定义私有变量和函数来实现。这个模式如下所示:
(function () {
// 私有变量和私有函数
let privateVariable = 10
function privateFunction () {
return false
}
// 构造函数
MyObject = function () {}
// 公有和特权方法
MyObject.prototype.publicMethod = function () {
privateVariable++
return privateFunction()
}
})()
在这个模式中,匿名函数表达式创建了一个包含构造函数及其方法的私有作用域。首先定义的是私有变量和私有函数,然后又定义了构造函数和公有方法。公有方法定义在构造函数的原型上,与典型的原型模式一样。注意,这个模式定义的构造函数没有使用函数声明,使用的是函数表达式。函数声明会创建内部函数,在这里并不是必需的。基于同样的原因(但操作相反),这里声明 MyObject 并没有使用任何关键字。因为不使用关键字声明的变量会创建在全局作用域中,所以 MyObject 变成了全局变量,可以在这个私有作用域外部被访问。注意在严格模式下给未声明的变量赋值会导致错误。
这个模式与前一个模式的主要区别就是,私有变量和私有函数是由实例共享的。因为特权方法定义在原型上,所以同样是由实例共享的。特权方法作为一个闭包,始终引用着包含它的作用域。来看下面的例子:
(function () {
let name = ''
Person = function (value) {
name = value
}
Person.prototype.getName = function () {
return name
}
Person.prototype.setName = function (value) {
name = value
}
})()
const person1 = new Person('Nicholas')
console.log(person1.getName()) // 'Nicholas'
person1.setName('Matt')
console.log(person1.getName()) // 'Matt'
const person2 = new Person('Michael')
console.log(person1.getName()) // 'Michael'
console.log(person2.getName()) // 'Michael'
这里的 Person 构造函数可以访问私有变量 name,跟 getName() 和 setName() 方法一样。使用这种模式,name 变成了静态变量,可供所有实例使用。这意味着在任何实例上调用 setName() 修改这个变量都会影响其他实例。调用 setName() 或创建新的 Person 实例都要把 name 变量设置为一个新值。而所有实例都会返回相同的值。
像这样创建静态私有变量可以利用原型更好地重用代码,只是每个实例没有了自己的私有变量。最终,到底是把私有变量放在实例中,还是作为静态私有变量,都需要根据自己的需求来确定。
注意:使用闭包和私有变量会导致作用域链变长,作用域链越长,则查找变量所需的时间也越多。
16.2 模块模式
前面的模式通过自定义类型创建了私有变量和特权方法。而下面要讨论的 Douglas Crockford 所说的模块模式,则在一个单例对象上实现了相同的隔离和封装。单例对象(singleton)就是只有一个实例的对象。按照惯例,JavaScript 是通过对象字面量来创建单例对象的,如下面的例子所示:
const singleton = {
name: value,
method () {
// 方法的代码
}
}
模块模式是在单例对象基础上加以扩展,使其通过作用域链来关联私有变量和特权方法。模块模式的样板代码如下:
const singleton = (function () {
// 私有变量和私有函数
let privateVariable = 10
function privateFunction () {
return false
}
// 特权/公有方法和属性
return {
publicProperty: true,
publicMethod () {
privateVariable++
return privateFunction()
}
}
})()
模块模式使用了匿名函数返回一个对象。在匿名函数内部,首先定义私有变量和私有函数。之后,创建一个要通过匿名函数返回的对象字面量。这个对象字面量中只包含可以公开访问的属性和方法。因为这个对象定义在匿名函数内部,所以它的所有公有方法都可以访问同一个作用域的私有变量和私有函数。本质上,对象字面量定义了单例对象的公共接口。如果单例对象需要进行某种初始化,并且需要访问私有变量时,那就可以采用这个模式:
const application = (function () {
// 私有变量和私有函数
const components = new Array()
// 初始化
components.push(new BaseComponent())
// 公共接口
return {
getComponentCount () {
return components.length
},
registerComponent (component) {
if (typeof component === 'object') {
components.push(component)
}
}
}
})()
在 Web 开发中,经常需要使用单例对象管理应用程序级的信息。上面这个简单的例子创建了一个 application 对象用于管理组件。在创建这个对象之后,内部就会创建一个私有的数组 components,然后将一个 BaseComponent 组件的新实例添加到数组中。(BaseComponent 组件的代码并不重要,在这里用它只是为了说明模块模式的用法。)对象字面量中定义的 getComponentCount() 和 registerComponent() 方法都是可以访问 components 私有数组的特权方法。前一个方法返回注册组件的数量,后一个方法负责注册新组件。
在模块模式中,单例对象作为一个模块,经过初始化可以包含某些私有的数据,而这些数据又可以通过其暴露的公共方法来访问。以这种方式创建的每个单例对象都是 Object 的实例,因为最终单例都由一个对象字面量来表示。不过这无关紧要,因为单例对象通常是可以全局访问的,而不是作为参数传给函数的,所以可以避免使用 instanceof 操作符确定参数是不是对象类型的需求。
16.3 模块增强模式
另一个利用模块模式的做法是在返回对象之前先对其进行增强。这适合单例对象需要是某个特定类型的实例,但又必须给它添加额外属性或方法的场景。来看下面的例子:
const singleton = (function () {
// 私有变量和私有函数
let privateVariable = 10
function privateFunction () {
return false
}
// 创建对象
const object = new CustomType()
// 添加特权/公有属性和方法
object.publicProperty = true
object.publicMethod = function () {
privateVariable++
return privateFunction()
}
// 返回对象
return object
})()
如果前一节的 application 对象必须是 BaseComponent 的实例,那么就可以使用下面的代码来创建它:
const application = (function () {
// 私有变量和私有函数
const components = new Array()
// 初始化
components.push(new BaseComponent())
// 创建局部变量保存实例
const app = new BaseComponent()
// 公共接口
app.getComponentCount = function () {
return components.length
}
app.registerComponent = function (component) {
if (typeof component === 'object') {
components.push(component)
}
}
// 返回实例
return app
})()
在这个重写的 application 单例对象的例子中,首先定义了私有变量和私有函数,跟之前例子中一样。主要区别在于这里创建了一个名为 app 的变量,其中保存了 BaseComponent 组件的实例。这是最终要变成 application 的那个对象的局部版本。在给这个局部变量 app 添加了能够访问私有变量的公共方法之后,匿名函数返回了这个对象。然后,这个对象被赋值给 application。
十七、小结
函数是 JavaScript 编程中最有用也最通用的工具。ECMAScript 6 新增了更加强大的语法特性,从而让开发者可以更有效地使用函数。
- 函数表达式与函数声明是不一样的。函数声明要求写出函数名称,而函数表达式并不需要。没有名称的函数表达式也被称为匿名函数。
- ES6 新增了类似于函数表达式的箭头函数语法,但两者也有一些重要区别。
- JavaScript 中函数定义与调用时的参数极其灵活。arguments 对象,以及 ES6 新增的扩展操作符,可以实现函数定义和调用的完全动态化。
- 函数内部也暴露了很多对象和引用,涵盖了函数被谁调用、使用什么调用,以及调用时传入了什么参数等信息。
- JavaScript 引擎可以优化符合尾调用条件的函数,以节省栈空间。
- 闭包的作用域链中包含自己的一个变量对象,然后是包含函数的变量对象,直到全局上下文的变量对象。
- 通常,函数作用域及其中的所有变量在函数执行完毕后都会被销毁。
- 闭包在被函数返回之后,其作用域会一直保存在内存中,直到闭包被销毁。
- 函数可以在创建之后立即调用,执行其中代码之后却不留下对函数的引用。
- 立即调用的函数表达式如果不在包含作用域中将返回值赋给一个变量,则其包含的所有变量都会被销毁。
- 虽然 JavaScript 没有私有对象属性的概念,但可以使用闭包实现公共方法,访问位于包含作用域中定义的变量。
- 可以访问私有变量的公共方法叫作特权方法。
- 特权方法可以使用构造函数或原型模式通过自定义类型中实现,也可以使用模块模式或模块增强模式在单例对象上实现。