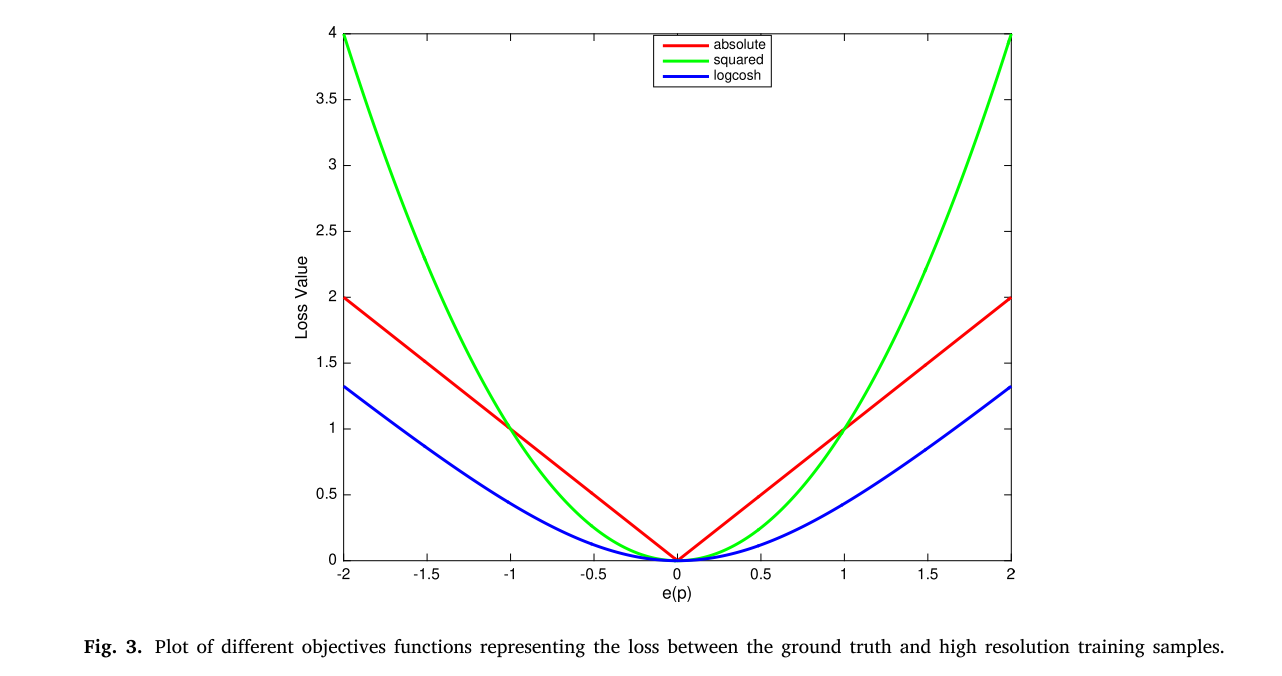
目录
一、选择题
1、
2、
3、
4、
5、
6、
7、
8、
9、
10、
二、编程题
1、排序子序列
2、倒置字符串
一、选择题
1、
使用printf函数打印一个double类型的数据,要求:输出为10进制,输出左对齐30个字符,4位精度。以下哪个选项是正确的?
A 、%-30.4e
B 、%4.30e
C、 %-30.4f
D 、%-4.30f
答案:C
解析:
%e 是按指数类型输出,排除
.4 为4位精度,%30.4f 默认是右对齐的,左对齐要加上 ‘-’,即 %-30.4f,所以答案选C
2、
请找出下面程序中有哪些错误()
int main(){
int i = 10;
int j = 1;
const int *p1;//(1)
int const *p2 = &i; //(2)
p2 = &j;//(3)
int *const p3 = &i;//(4)
*p3 = 20;//(5)
*p2 = 30;//(6)
p3 = &j;//(7)
return 0;
}A 、1,2,3,4,5,6,7
B、 1,3,5,6
C、 6,7
D 、3,5
答案:C
解析:
先复习知识点
- 常量指针:指针所指空间的值不能发生改变,不能通过指针解引用修改指针所指空间的值,但是指针的指向可以发生改变
- 指针常量:指针本身是一个常量,指针的指向不能发生改变,但是指针指向的值是可以发生改变,即可以通过指针解引用改变指针所指空间的值
区别方法:const* 的相对位置
- const 在 * 的左边:是常量指针
- const 在 * 的右边:是指针常量
由题可知:p1、p2是常量指针,p3是指针常量,(6)修改p2所指向的内容,错误,(7)修改指针的指向,错误,所以答案选C
3、
下面叙述错误的是()
char acX[]="abc";
char acY[]={'a','b','c'};
char *szX="abc";
char *szY="abc";A、 acX与acY的内容可以修改
B 、szX与szY指向同一个地址
C、 acX占用的内存空间比acY占用的大
D、 szX的内容修改后,szY的内容也会被更改
答案:D
解析:
- A、acX 和 acY都是在栈上开辟的,可以修改;
- B、szX 和 szY都是指针,指向的是同一个字符串,这里指针所指的字符串在常量区,指向的是同一个地址;
- C、acX 是字符串初始化,后面自带 ‘\0’,即“abc\0”,所以 acX 大小是4,acY 只有 “abc”,acY大小为3,所以acX占用的内存空间比acY占用的大;
- D、szX是一个指针,内容改变也就是 szX 的指向改变 ,并不会改变 “abc”,szY 指向的内容还是一样
所以选择D
4、
在头文件及上下文均正常的情况下,下列代码的运行结果是()
int a[] = {1, 2, 3, 4};
int *b = a;
*b += 2;
*(b + 2) = 2;
b++;
printf("%d,%d\n", *b, *(b + 2));A 、1,3
B、 1,2
C 、2,4
D、 3,2
答案:C
解析:
指针 +1 是跳过一个指针类型,*b = 2,*(b+2) = 4,所以选择C

5、
下列关于C/C++的宏定义,不正确的是()
A、 宏定义不检查参数正确性,会有安全隐患
B、 宏定义的常量更容易理解,如果可以使用宏定义常量的话,要避免使用const常量
C 、宏的嵌套定义过多会影响程序的可读性,而且很容易出错
D 、相对于函数调用,宏定义可以提高程序的运行效率
答案:B
解析:
宏定义没有安全类型检测,所以会有安全隐患,在预处理阶段进行了替换,所以应该是尽量使用
const常量,所以选B
6、
有以下定义:
int a[10];
char b[80];函数声明为:
void sss(char[],int[]);则正确的函数调用形式是()
A、 sss(a,b);
B、 sss(char b[],int a[]);
C、 sss(b[],a[]);
D、 sss(b,a)
答案:D
解析:
函数调用的时候,参数如果是数组,直接传入数组名即可,数组名也是地址,所以选D
7、
用变量a给出下面的定义:一个有10个指针的数组,该指针指向一个函数,该函数有一个整形参数并返回一个整型数()
A 、int *a[10];
B、 int (*a)[10];
C、 int (*a)(int);
D、 int (*a[10])(int);
答案:D
解析:
- A、int *a[10],[] 的运算符优先级高于 *,所以 a 先跟 [] 结合,表明是一个数组,再与 * 结合,说明数组里面的元素是是指针类型,所以 a 是一个指针数组
- B、int (*a)[10],a 先和 * 结合,表明是一个指针,再与 [] 结合,说明指针里面的元素是int类型,所以 a 是一个数组指针
- C、int (*a)(int),a先和*结合,表明是一个指针,指针指向的是(int),是一个函数,表明 a 是一个函数指针,返回值为 int
- D、int (*a[10])(int),a先和 [] 结合,表示是一个数组,再和 * 结合,为指针数组,指针指向的是(int),是一个函数,表明 a 是一个函数指针数组,返回值为 int
所以综上选D
8、
以下 C++ 函数的功能是统计给定输入中每个大写字母的出现次数(不需要检查输入合法性,所有字母都为大写),则应在横线处填入的代码为()
void AlphabetCounting(char a[], int n) {
int count[26] = {}, i, kind = 10;
for (i = 0; i < n; ++i)
_________________;
for (i = 0; i < 26; ++i) {
printf("%c=%d", _____, _____);
}
}A、 ++count[a[i]-'Z'] 'Z'-i count['Z'-i]
B、 ++count['A'-a[i]] 'A'+i count[i]
C、 ++count[i] i count[i]
D、 ++count['Z'-a[i]] 'Z'-i count[i]
答案:D
解析:
无,结合代码分析即可
9、
在32位cpu上选择缺省对齐的情况下,有如下结构体定义:
struct A{
unsigned a : 19;
unsigned b : 11;
unsigned c : 4;
unsigned d : 29;
char index;
};则sizeof(struct A)的值为()
A、 9
B、 12
C、 16
D、 20
答案:C
解析:
:后面的数字是所占用的字节,下面进行分析
- unsigned类型,开辟4字节(32): 19 + 11(a+b)
- 4字节(32): 4(c)
- 4字节(32):29(d)
- char类型,开辟1字节(8):1(index)
最后还要考虑内存对齐,上面最大宽度是 int,4个字节,上面加起来一共是 13,内存对齐后是 16,所以选C
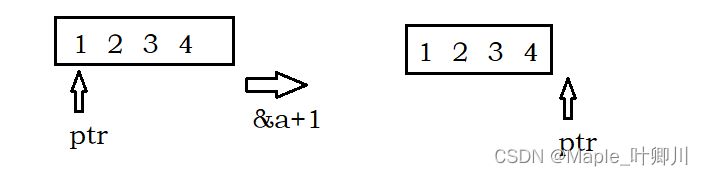
10、
下面代码会输出()
int main(){
int a[4]={1,2,3,4};
int *ptr=(int*)(&a+1);
printf("%d",*(ptr-1));
}A、 4
B、 1
C、 2
D、 3
答案:A
解析:
&a,对数组名进行取地址,指针 ptr 指向首元素的地址,&a+1 会向后偏移整个数组大小,因此指针 ptr 指4的后一个位置;ptr 是int类型指针,(ptr-1)是向前偏移一个 int 类型的大小,所以最后指向4,再解引用获得4,所以选A
二、编程题
1、排序子序列
题目链接:排序子序列
思路分析:
首先要看懂题目,什么是非递增序列和非递减序列....
1 2 3 4 5 递增序列 5 4 3 2 1 递减序列 1 2 4 4 4 5 6 6 7 非递减序列(可以出现相同的数) 9 7 7 5 3 2 2 1 非增减序列(可以出现相同的数)
- 非递减:arr[i] <= arr[i+1]
- 非递增:arr[i] >= arr[i+1]
进行遍历数组有三种情况:
- arr[i] < arr[i+1] 进入非递减序列
- arr[i] == arr[i+1] 两数相等,直接 ++i
- arr[i] >= arr[i+1] 进入非递增序列
定义一个计数器记录子序列
注意:注意越界问题,这里牛客测试用例不全,建议多开一个空间置成 0 ,不影响题目正确性,输入的数都是大于0的
代码如下(C++):
#include <iostream>
#include <vector>
using namespace std;
int main()
{
int n = 0;
cin >> n;
vector<int> arr;
// 注意这里多给了一个值,是处理越界的情况的比较
arr.resize(n + 1);
//这里有个坑,这个题越界了牛客测不出来,给n,并且不写a[n] = 0;不会报错,但是最好写上
//比如 123221 ,走读一遍代码就会发现会越界
arr[n] = 0;
//读入数组
for(int i = 0; i < arr.size(); ++i)
{
cin >> arr[i];
}
int i = 0;
int count = 0;
while(i < arr.size())
{
//非递减子序列
if(i < arr.size() && arr[i] < arr[i+1])
{
while(i < arr.size() && arr[i] < arr[i+1])
++i;
//计数+1
++count;
++i;
}
else if(i < arr.size() && arr[i] == arr[i+1])
{
++i;
}
//非递增子序列
else
{
while(i < arr.size() && arr[i] >= arr[i+1])
++i;
//计数+1
++count;
++i;
}
}
cout << count;
return 0;
}2、倒置字符串
题目链接:倒置字符串
思路分析:
先将整个字符串逆置过来,再遍历字符串,再逆置每个单词
代码如下(C++):
#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
int main()
{
string str;
getline(cin, str);
//逆置整体字符串
reverse(str.begin(), str.end());
//string::iterator start = str.begin();
auto start = str.begin();
while(start != str.end())
{
auto end = start;
while(end != str.end() && *end != ' ')
{
++end;
}
//逆置单词
reverse(start, end);
if(end != str.end())//不是字符串结束
{
start = end + 1;
}
else //字符串结束
{
start = end;
}
}
cout << str << endl;
return 0;
}----------------我是分割线---------------
Day_02完结,下篇即将更新







![[Java安全]—Shiro回显内存马注入](https://img-blog.csdnimg.cn/65d8d72cb8734d3999f3388cc274848b.png#pic_center)